Руководство по разработке моделей на облачной рабочей станции
Узнайте, как разработать скрипт обучения с записной книжкой на облачной рабочей станции Машинное обучение Azure. В этом руководстве рассматриваются основные принципы, которые необходимо приступить к работе:
- Настройка и настройка облачной рабочей станции. Облачная рабочая станция работает на базе Машинное обучение Azure вычислительного экземпляра, который предварительно настроен в средах для поддержки различных потребностей разработки моделей.
- Используйте облачные среды разработки.
- Используйте MLflow для отслеживания метрик модели, все из записной книжки.
Необходимые компоненты
Чтобы использовать Машинное обучение Azure, вам нужна рабочая область. Если у вас нет ресурсов, выполните инструкции по созданию рабочей области и узнайте больше об использовании.
Внимание
Если в рабочей области Машинное обучение Azure настроена управляемая виртуальная сеть, может потребоваться добавить правила для исходящего трафика, чтобы разрешить доступ к общедоступным репозиториям пакетов Python. Дополнительные сведения см. в статье "Сценарий: доступ к общедоступным пакетам машинного обучения".
Начните с вычислений
Раздел "Вычисления " в рабочей области позволяет создавать вычислительные ресурсы. Вычислительный экземпляр — это облачная рабочая станция, полностью управляемая Машинное обучение Azure. В этом руководстве используется вычислительный экземпляр. Его также можно использовать для запуска собственного кода, а также для разработки и тестирования моделей.
- Войдите в Студию машинного обучения Azure.
- Выберите рабочую область, если она еще не открыта.
- В области навигации слева выберите "Вычисления".
- Если у вас нет вычислительного экземпляра, вы увидите новое в середине экрана. Выберите "Создать " и заполните форму. Вы можете использовать все значения по умолчанию.
- Если у вас есть вычислительный экземпляр, выберите его из списка. Если он остановлен, нажмите кнопку "Пуск".
Открытие Visual Studio Code (VS Code)
После запуска вычислительного экземпляра вы можете получить доступ к нему различными способами. В этом руководстве показано использование вычислительного экземпляра из VS Code. VS Code предоставляет полную интегрированную среду разработки (IDE) с возможностями Машинное обучение Azure ресурсов.
В списке вычислительных экземпляров выберите ссылку VS Code (Web) или VS Code (Desktop) для используемого вычислительного экземпляра. Если вы выберете VS Code (Desktop), появится всплывающее окно с просьбой открыть приложение.

Этот экземпляр VS Code подключен к вычислительному экземпляру и файловой системе рабочей области. Даже если открыть его на рабочем столе, файлы, которые отображаются в рабочей области, являются файлами.
Настройка новой среды для создания прототипов (необязательно)
Чтобы скрипт выполнялся, необходимо работать в среде, настроенной с зависимостями и библиотеками, которые ожидает код. В этом разделе показано, как создать среду, адаптированную к коду. Чтобы создать новое ядро Jupyter, к которому подключается записная книжка, вы будете использовать YAML-файл, определяющий зависимости.
Отправка файла.
Отправленные файлы хранятся в общей папке Azure, и эти файлы подключены к каждому вычислительному экземпляру и совместно используются в рабочей области.
Скачайте этот файл среды conda, workstation_env.yml на компьютер с помощью кнопки "Скачать необработанный файл " в правом верхнем углу.
Перетащите файл с компьютера в окно VS Code. Файл передается в рабочую область.
Переместите файл в папку имени пользователя.
Выберите этот файл, чтобы просмотреть его, и просмотрите зависимости, которые он указывает. Вы увидите следующее содержимое:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibСоздайте ядро.
Теперь используйте терминал для создания нового ядра Jupyter на основе файла workstation_env.yml .
В верхней строке меню выберите терминал > "Новый терминал".

Просмотр текущих сред conda. Активная среда помечена как *.
conda env listcdв папку, в которой был отправлен файл workstation_env.yml . Например, если вы загрузили его в папку пользователя:cd Users/myusernameУбедитесь, что workstation_env.yml находится в этой папке.
lsСоздайте среду на основе предоставленного файла conda. Создание этой среды занимает несколько минут.
conda env create -f workstation_env.ymlАктивируйте новую среду.
conda activate workstation_envПримечание.
Если вы видите CommandNotFoundError, следуйте инструкциям по выполнению
conda init bash, закройте терминал и откройте новый. Затем повторитеconda activate workstation_envкоманду.Убедитесь, что правильная среда активна, снова ищет среду, помеченную как *.
conda env listСоздайте новое ядро Jupyter на основе активной среды.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Закройте окно терминала.
Теперь у вас есть новое ядро. Затем вы откроете записную книжку и используйте это ядро.
Создание записной книжки
- В верхней строке меню выберите "Файл > нового файла".
- Присвойте новому файлу имя develop-tutorial.ipynb (или введите предпочитаемое имя). Убедитесь, что вы используете расширение IPYNB .
Задание ядра
- В правом верхнем углу выберите " Выбрать ядро".
- Выберите вычислительный экземпляр Машинного обучения Azure (computeinstance-name).
- Выберите созданное ядро, на рабочей станции учебника Env. Если он не отображается, выберите средство "Обновить " в правом верхнем углу.
Разработка скрипта обучения
В этом разделе описан сценарий обучения Python, который прогнозирует платежи по умолчанию кредитной карты, используя подготовленные тестовые и обучающие наборы данных из набора данных UCI.
Этот код используется sklearn для обучения и MLflow для ведения журнала метрик.
Начните с кода, который импортирует пакеты и библиотеки, которые вы будете использовать в скрипте обучения.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitЗатем загрузите и обработайте данные для этого эксперимента. В этом руководстве вы считываете данные из файла в Интернете.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Получите данные, готовые к обучению:
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesДобавьте код для запуска автоматической записи
MLflow, чтобы отслеживать метрики и результаты. Благодаря итеративному характеру разработки моделей помогаетMLflowвыполнять журнал параметров и результатов модели. Вернитесь к этим запускам, чтобы сравнить и понять, как выполняется модель. Журналы также предоставляют контекст для перехода с этапа разработки на этап обучения рабочих процессов в Машинное обучение Azure.# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()обучение моделей.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Примечание.
Вы можете игнорировать предупреждения mlflow. Вы по-прежнему получите все результаты, необходимые для отслеживания.
Выполнение итерации
Теперь, когда у вас есть результаты модели, может потребоваться изменить что-то и повторить попытку. Например, попробуйте использовать другой метод классификатора:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Примечание.
Вы можете игнорировать предупреждения mlflow. Вы по-прежнему получите все результаты, необходимые для отслеживания.
Изучение результатов
Теперь, когда вы пробовали две разные модели, используйте результаты, отслеживаемые MLFfow , чтобы решить, какая модель лучше. Вы можете ссылаться на такие метрики, как точность, или другие индикаторы, которые наиболее важны для ваших сценариев. Вы можете более подробно ознакомиться с этими результатами, просмотрев задания, созданные MLflow.
Вернитесь в рабочую область в Студия машинного обучения Azure.
В области навигации слева выберите "Задания".
Выберите ссылку для разработки в облаке.
Показаны два разных задания, по одному для каждой из пробных моделей. Эти имена создаются автоматически. При наведении указателя мыши на имя используйте средство карандаша рядом с именем, если вы хотите переименовать его.
Выберите ссылку для первого задания. Имя отображается в верхней части окна. Вы также можете переименовать его здесь с помощью инструмента карандаша.
На странице отображаются сведения о задании, таких как свойства, выходные данные, теги и параметры. В разделе "Теги" вы увидите estimator_name, в котором описывается тип модели.
Перейдите на вкладку "Метрики" , чтобы просмотреть метрики, записанные в
MLflowжурнал. (Ожидается, что результаты будут отличаться, так как у вас есть другой набор обучения.)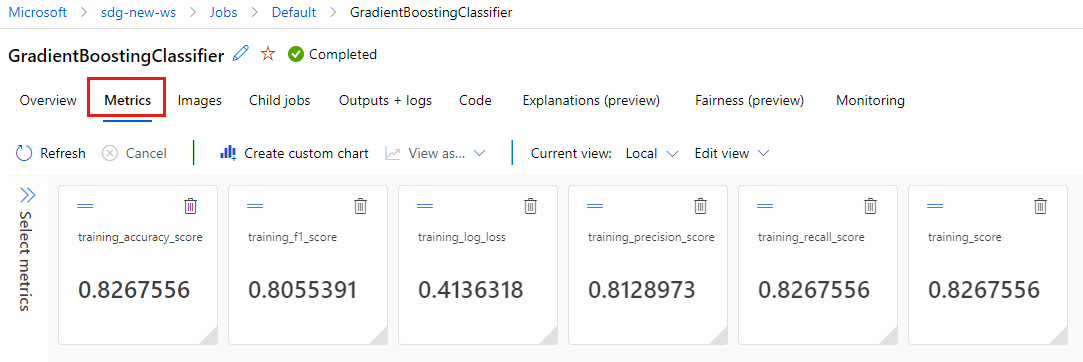
Выберите вкладку "Изображения", чтобы просмотреть изображения , созданные с помощью
MLflow.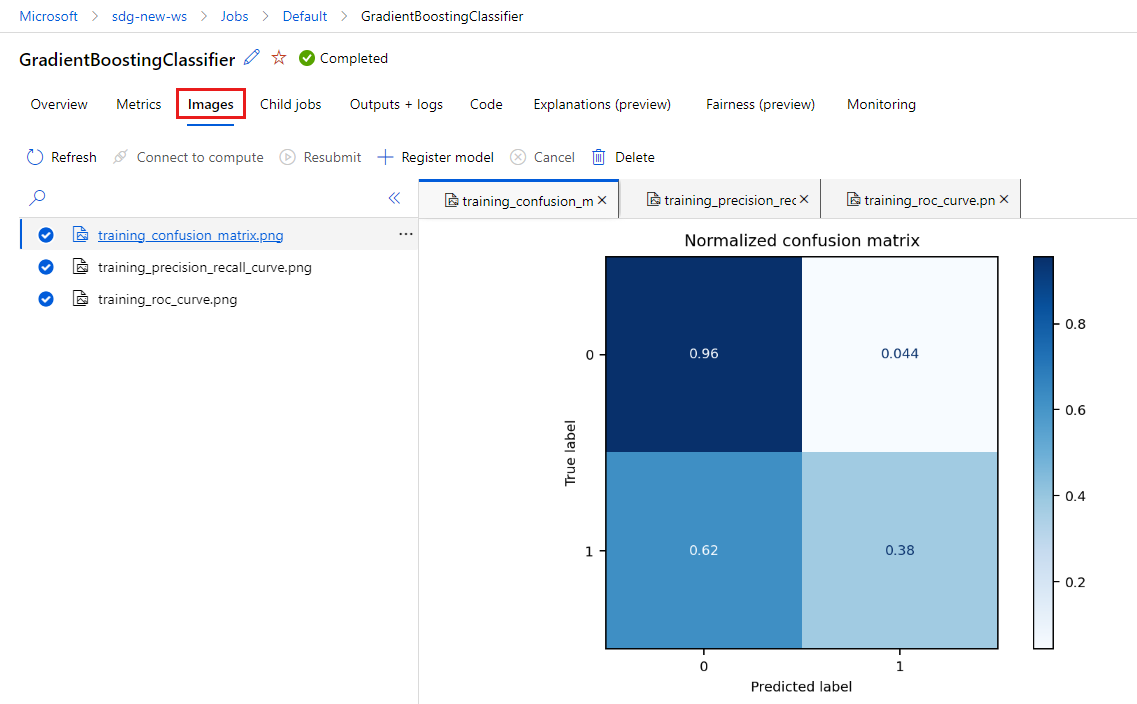
Вернитесь и просмотрите метрики и изображения для другой модели.
Создание скрипта Python
Теперь создайте скрипт Python из записной книжки для обучения модели.
В окне VS Code щелкните правой кнопкой мыши имя файла записной книжки и выберите "Импортировать записную книжку в скрипт".
Сохраните этот новый файл скрипта с помощью меню "Сохранить > файл". Вызовите его train.py.
Просмотрите этот файл и удалите нужный код в скрипте обучения. Например, сохраните код для модели, которую вы хотите использовать, и удалите код для модели, которую вы не хотите.
- Убедитесь, что код запускает автозалогирование (
mlflow.sklearn.autolog()). - При интерактивном запуске скрипта Python (при выполнении здесь) можно сохранить строку, определяющую имя эксперимента (
mlflow.set_experiment("Develop on cloud tutorial")). Или даже присвойте ему другое имя, чтобы увидеть его как другую запись в разделе "Задания ". Но при подготовке скрипта для задания обучения эта строка не применяется и должна быть опущена. Определение задания включает имя эксперимента. - При обучении одной модели строки для запуска и завершения выполнения (
mlflow.start_run()иmlflow.end_run()) также не нужны (они не будут иметь эффекта), но могут быть оставлены, если вы хотите.
- Убедитесь, что код запускает автозалогирование (
Завершив редактирование, сохраните файл.
Теперь у вас есть скрипт Python для обучения предпочитаемой модели.
выполнение скрипта Python.
Теперь вы запускаете этот код в вычислительном экземпляре, который является вашей средой разработки Машинное обучение Azure. Руководство. Обучение модели показывает, как выполнять скрипт обучения более масштабируемым способом на более мощных вычислительных ресурсах.
Выберите среду, созданную ранее в этом руководстве, в качестве версии Python (workstations_env). В правом нижнем углу записной книжки вы увидите имя среды. Выберите ее, а затем выберите среду в середине экрана.

Теперь запустите скрипт Python. Используйте средство запуска файла Python в правом верхнем углу.

Примечание.
Вы можете игнорировать предупреждения mlflow. Вы по-прежнему получите все метрики и изображения из автологирования.
Проверка результатов скрипта
Вернитесь к заданиям в рабочей области в Студия машинного обучения Azure, чтобы просмотреть результаты скрипта обучения. Помните, что обучающие данные изменяются с каждым разделением, поэтому результаты также отличаются между запусками.
Очистка ресурсов
Если вы планируете перейти к другим руководствам, перейдите к следующим шагам.
Остановка вычислительного экземпляра
Если вы сейчас не планируете использовать вычислительный экземпляр, остановите его, выполнив следующие действия:
- В студии в левой области навигации выберите "Вычисления".
- Из вкладок вверху выберите Вычислительные экземпляры.
- Выберите вычислительный экземпляр из списка.
- В верхней панели инструментов выберите Остановить.
Удаление всех ресурсов
Внимание
Созданные вами ресурсы могут использоваться в качестве необходимых компонентов при работе с другими руководствами по Машинному обучению Azure.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы с вас не взималась плата:
В портал Azure в поле поиска введите группы ресурсов и выберите его из результатов.
Выберите созданную группу ресурсов из списка.
На странице "Обзор" выберите "Удалить группу ресурсов".
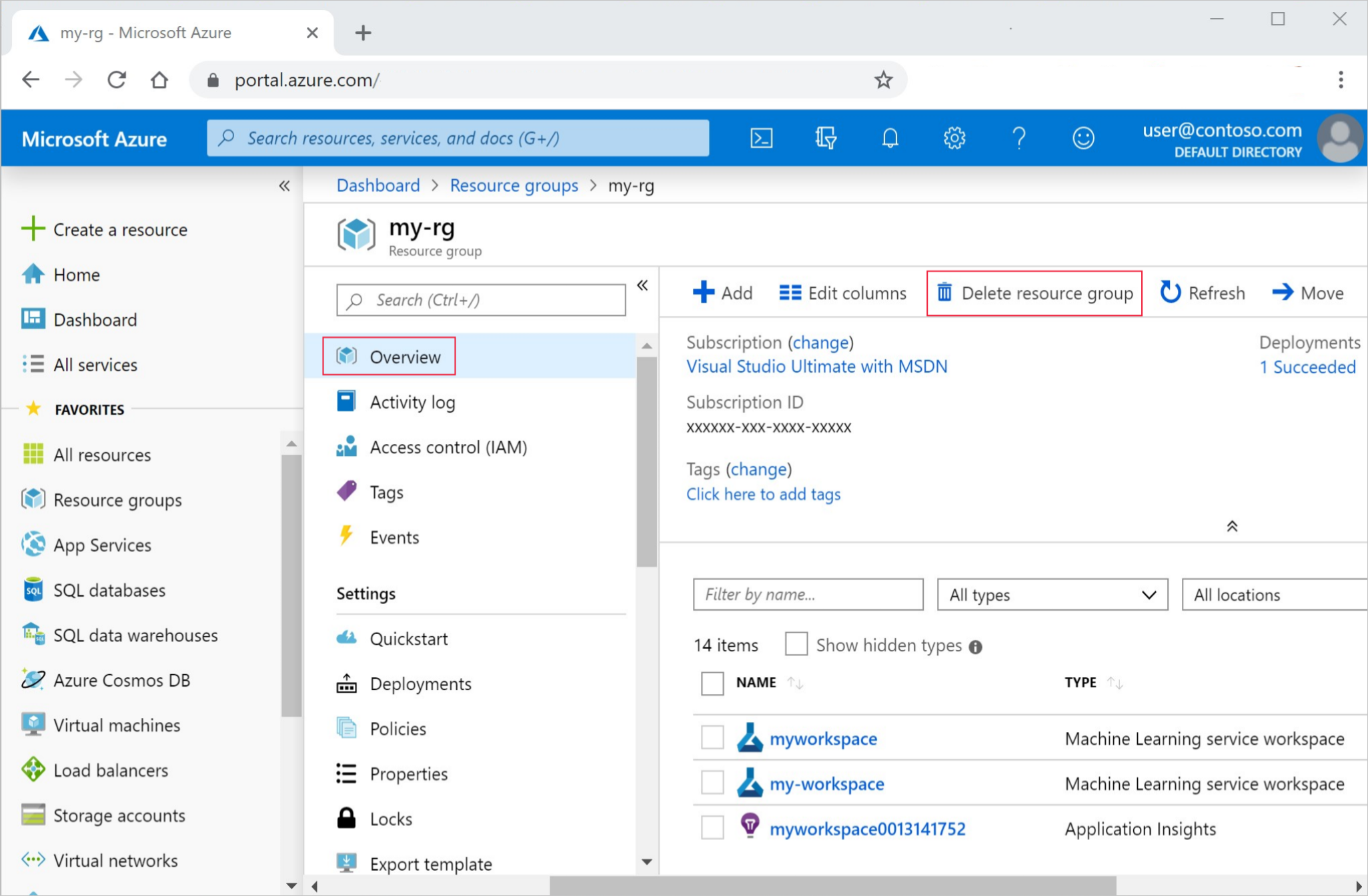
Введите имя группы ресурсов. Затем выберите Удалить.
Следующие шаги
Дополнительные сведения:
- От артефактов до моделей в MLflow
- Использование Git со службой "Машинное обучение Microsoft Azure".
- Запуск записных книжек Jupyter в рабочей области
- Работа с терминалом вычислительного экземпляра в рабочей области
- Управление сеансами записной книжки и терминала
В этом руководстве показано, как создать модель, прототип на том же компьютере, где находится код. В рабочей среде вы узнаете, как использовать этот скрипт обучения для более мощных удаленных вычислительных ресурсов: