Мастеры импорта в поиске ИИ Azure
Служба "Поиск ИИ Azure" имеет два мастера импорта, которые автоматизируют индексирование и определения объектов, чтобы начать запрос немедленно. Если вы не знакомы с поиском ИИ Azure, эти мастера являются одним из самых мощных функций в вашем распоряжении. С минимальными усилиями можно создать конвейер индексирования или обогащения, который выполняет большую часть функциональных возможностей поиска ИИ Azure.
Мастер импорта данных поддерживает невекторные рабочие процессы. Вы можете извлечь буквенно-цифровой текст из необработанных документов. Вы также можете настроить примененные навыки ИИ и встроенные навыки, которые определяют структуру и создают содержимое для поиска текста из файлов изображений и неструктурированных данных.
Мастер импорта и векторизации данных поддерживает векторизацию. Необходимо указать существующее развертывание модели внедрения, но мастер делает подключение, сформулирует запрос и обрабатывает ответ. Он создает векторное содержимое из текста или изображения.
Если вы используете мастер для проверки концепции, в этой статье объясняется внутренние работы мастеров, чтобы их можно было использовать более эффективно.
Эта статья не является пошаговой. Сведения об использовании мастера со встроенными примерами данных см. в следующих примерах:
- Краткое руководство. Создание индекса поиска
- Краткое руководство. Создание набора навыков перевода текста и сущностей
- Краткое руководство. Создание векторного индекса
- Краткое руководство. Поиск изображений (векторы)
Запуск мастеров
На портале Azure откройте страницу службы поиска на панели мониторинга или найдите свою службу в списке служб.
На странице "Обзор службы" в верхней части выберите "Импорт данных" или "Импорт и векторизация данных".
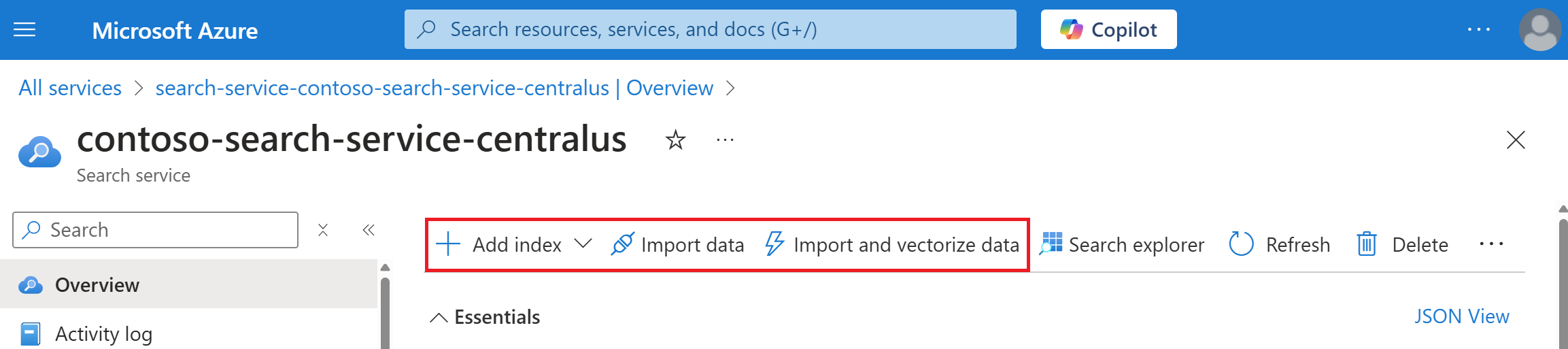
Мастера открываются полностью развернуты в окне браузера, чтобы иметь больше места для работы.
Если вы выбрали импорт данных, можно выбрать вариант "Примеры", чтобы использовать предварительно созданный пример данных из поддерживаемого источника данных.
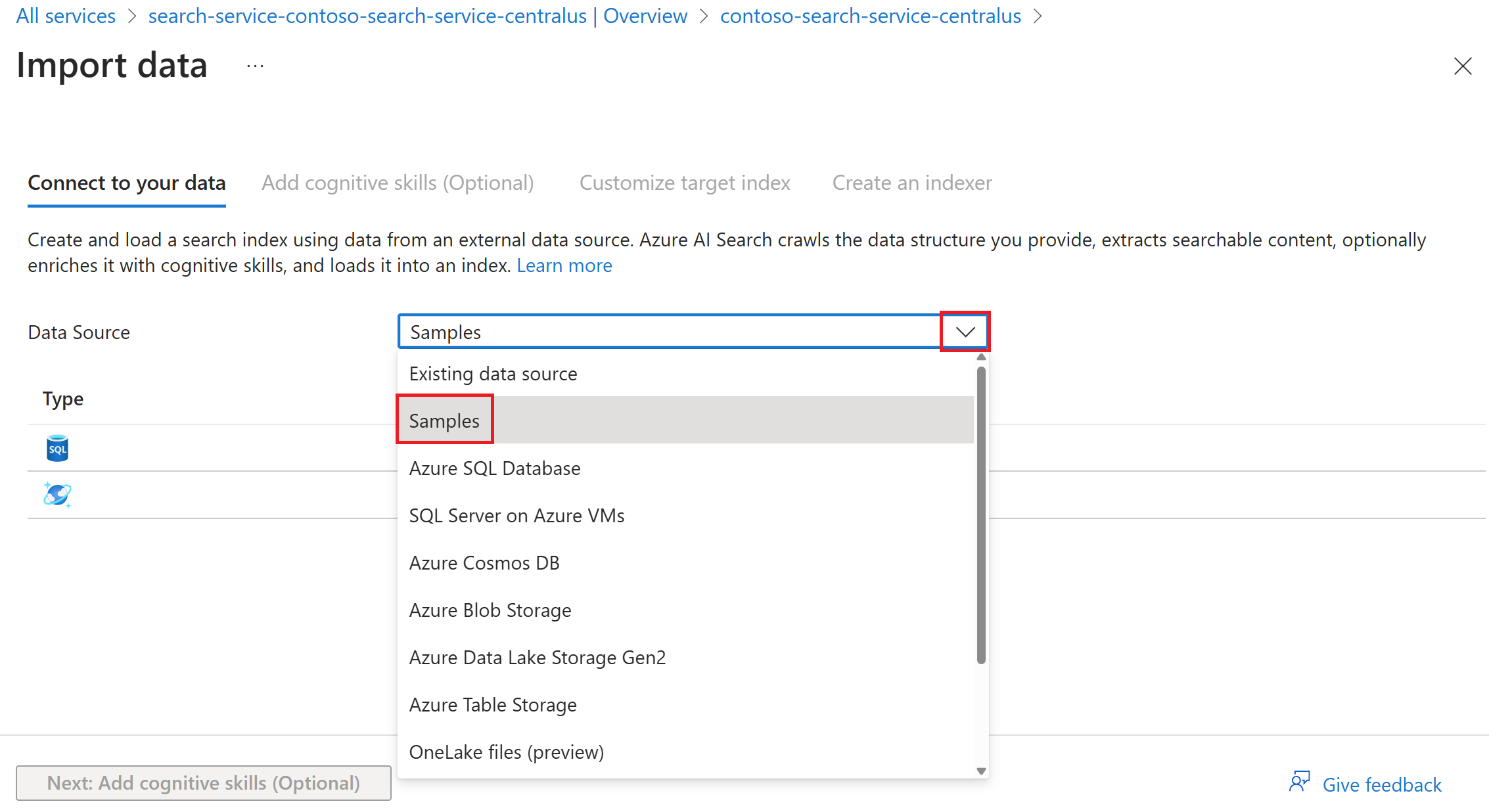
Выполните оставшиеся действия мастера, чтобы создать индекс и индексатор.
Импорт данных можно запустить из других служб Azure, включая Azure Cosmos DB, Базу данных SQL Azure, Управляемый экземпляр SQL и хранилище BLOB-объектов Azure. Найдите добавление службы "Поиск ИИ Azure" в области навигации слева на странице обзора службы.
Объекты, созданные мастером
Мастер выводит объекты в следующей таблице. После создания объектов можно просмотреть определения JSON на портале или вызвать их из кода.
| Объект | Description |
|---|---|
| Индексатор | Объект конфигурации, указывающий источник данных, целевой индекс, дополнительный набор знаний, необязательное расписание и необязательные параметры конфигурации для обработки ошибок и кодировки Base-64. |
| Источник данных | Сохраняет сведения о подключении к поддерживаемму источнику данных в Azure. Объект источника данных используется исключительно с индексаторами. |
| Указатель | Физическая структура данных, используемая для полнотекстового поиска и других запросов. |
| Набор навыков | Необязательно. Полный набор инструкций по управлению, преобразованию и формированию содержимого, включая анализ и извлечение данных из файлов изображений. Наборы навыков также используются для интегрированной векторизации. Если объем работы не попадает под ограничение 20 транзакций на индексатор в день, набор навыков должен включать ссылку на ресурс многослужб Azure AI, который обеспечивает обогащение. Для интегрированной векторизации можно использовать azure AI Vision или модель внедрения в каталог моделей Azure AI Studio. |
| Хранилище знаний | Необязательно. Сохраняет выходные данные из таблиц и БОЛЬШИХ двоичных объектов в служба хранилища Azure для независимого анализа или последующей обработки в сценариях, отличных от поиска. |
Льготы
Перед написанием кода можно использовать мастера для прототипирования и проверки концепции. Мастера подключаются к внешним источникам данных, примеры данных для создания начального индекса, а затем импортируют и при необходимости векторизируют данные в виде документов JSON в индекс в поиске ИИ Azure.
Если вы оцениваете наборы навыков, мастер обрабатывает сопоставления полей выходных данных и добавляет вспомогательные функции для создания доступных объектов. Разделение текста добавляется при указании режима синтаксического анализа. Слияние текста добавляется, если выбран анализ изображений, чтобы мастер смог объединить текстовые описания с содержимым изображения. Навыки фигуры, добавленные для поддержки допустимых проекций, если выбран вариант хранилища знаний. Все перечисленные выше задачи приходят с кривой обучения. Если вы не знакомы с обогащением, способность обрабатывать эти шаги для вас позволяет измерять ценность навыка, не тратя много времени и усилий.
Выборка — это процесс, с помощью которого выводится схема индекса, и она имеет некоторые ограничения. При создании источника данных мастер выбирает случайный образец документов, чтобы определить, какие столбцы являются частью источника данных. Не все файлы считываются, так как это потенциально может занять несколько часов для очень больших источников данных. При наличии выбора документов исходные метаданные, такие как имя поля или тип, используются для создания коллекции полей в схеме индекса. В зависимости от сложности исходных данных может потребоваться изменить исходную схему для достижения точности или расширить ее для полноты. Вы можете внести свои изменения на странице определения индекса.
В целом преимущества использования мастера понятны: если выполнены требования, можно создать запрашиваемый индекс в течение нескольких минут. Некоторые сложности индексирования, такие как сериализация данных в виде документов JSON, обрабатываются мастером.
Ограничения
Мастер не без ограничений. Ограничения приведены ниже.
Мастер не поддерживает итерацию или повторное использование. Каждый проход по мастеру создает новый индекс, набор навыков и конфигурацию индексатора. В мастере могут сохраняться и повторно использоваться только источники данных. Чтобы изменить или уточнить другие объекты, удалите объекты и запустите их или используйте REST API или пакет SDK для .NET для изменения структур.
Исходное содержимое должно находиться в поддерживаемом источнике данных.
Выборка находится над подмножеством исходных данных. В случае крупных источников данных мастер может пропускать поля. Возможно, потребуется расширить схему или исправить выводимые типы данных, если выборка недостаточна.
Обогащение ИИ, предоставляемое на портале, ограничено подмножеством встроенных навыков.
Хранилище знаний, которое можно создать мастером, ограничено несколькими проекциями по умолчанию и использует соглашение об именовании по умолчанию. Если вы хотите настроить имена или проекции, необходимо создать хранилище знаний с помощью REST API или пакетов SDK.
Защита подключений
Мастеры импорта делают исходящие подключения с помощью контроллера портала и общедоступных конечных точек. Не удается использовать мастеры, если к ресурсам Azure обращаются через частное подключение или через общую приватную ссылку.
Мастера можно использовать через ограниченные общедоступные подключения, но не все функциональные возможности.
В службе поиска импорт встроенных примеров данных требуется общедоступная конечная точка и нет правил брандмауэра.
Примеры данных размещаются корпорацией Майкрософт в определенных ресурсах Azure. Контроллер портала подключается к этим ресурсам через общедоступную конечную точку. Если вы поместите службу поиска за брандмауэром, при попытке получить встроенные примеры данных
Import configuration failed, error creating Data Source, а затем выполните"An error has occured."следующую ошибку.В поддерживаемых источниках данных Azure, защищенных брандмауэрами, можно получить данные, если есть правильные правила брандмауэра.
Ресурс Azure должен признать сетевые запросы с IP-адреса устройства, используемого в подключении. Вы также должны перечислить поиск Azure AI в качестве доверенной службы в конфигурации сети ресурса. Например, в служба хранилища Azure можно перечислить
Microsoft.Search/searchServicesкак надежную службу.При подключении к учетной записи многослужб Azure AI или подключениям к моделям внедрения, развернутым в Azure AI Studio или Azure OpenAI, необходимо включить общедоступный доступ к Интернету. Эти ресурсы Azure вызываются при использовании встроенных навыков в мастере импорта данных или интегрированной векторизации в мастере импорта и векторизации данных .
В мастере импорта и векторизации данных ошибка
"Access denied due to Virtual Network/Firewall rules."В мастере импорта данных нет ошибок, но набор навыков не будет создан.
Если параметры брандмауэра препятствуют успешному выполнению рабочих процессов мастера, рассмотрите вместо этого сценарии или программные подходы.
Рабочий процесс
Мастер организован на четыре основных шага:
Подключитесь к поддерживаемму источнику данных Azure.
Создайте схему индекса, выводимую данными источника выборки.
При необходимости добавьте примененный ИИ для извлечения или создания содержимого и структуры. Входные данные для создания хранилища знаний собираются на этом шаге.
Запустите мастер для создания объектов, при необходимости векторизации данных, загрузки данных в индекс, задания расписания и других параметров конфигурации.
Рабочий процесс представляет собой конвейер, поэтому это один из способов. Вы не можете использовать мастер для редактирования любых созданных объектов, но для допустимых обновлений можно использовать другие средства портала, такие как конструктор индексов или индексатора или редакторы JSON.
Настройка источника данных в мастере
Мастера подключаются к внешнему поддерживаемому источнику данных с помощью внутренней логики, предоставленной индексаторами службы "Поиск ИИ Azure", которые оснащены для выборки источника, чтения метаданных, взлома документов для чтения содержимого и структуры, а также сериализации содержимого в формате JSON для последующего импорта в поиск ИИ Azure.
Вы можете вставить подключение к поддерживаемму источнику данных в другой подписке или регионе, но для активной подписки задана область выбора существующего подключения .

Не все источники данных предварительной версии гарантированно доступны в мастере. Так как каждый источник данных имеет потенциал для внедрения других изменений ниже, предварительный просмотр источника данных будет добавлен только в список источников данных, если он полностью поддерживает все возможности мастера, такие как определение набора навыков и вывод схемы индекса.
Импорт можно выполнять только из одной таблицы, представления базы данных или эквивалентной структуры данных, однако структура может включать иерархические или вложенные структуры. Подробнее см. в статье Как моделировать сложные типы.
Настройка набора навыков в мастере
Конфигурация набора навыков возникает после определения источника данных, так как тип источника данных сообщает о доступности определенных встроенных навыков. В частности, если вы индексируете файлы из хранилища BLOB-объектов, выбор режима синтаксического анализа этих файлов определяет, доступен ли анализ тональности.
Мастер добавляет нужные навыки. Он также добавляет другие навыки, необходимые для достижения успешного результата. Например, если указать хранилище знаний, мастер добавляет навык фигуры для поддержки проекций (или физических структур данных).
Наборы навыков являются необязательными, и в нижней части страницы есть кнопка, чтобы пропустить вперед, если вы не хотите обогащения ИИ.
Конфигурация схемы индекса в мастере
Мастеры примеры источника данных для обнаружения полей и типа поля. В зависимости от источника данных также могут предлагаться поля для индексирования метаданных.
Так как выборка является непреднастойным упражнением, ознакомьтесь со следующими рекомендациями.
Является ли список полей точным? Если источник данных содержит поля, которые не были выбраны в выборке, вы можете вручную добавить новые поля, которые пропустили выборку, и удалить любые, которые не добавляют значение в интерфейс поиска или которые не будут использоваться в выражении фильтра или профиле оценки.
Подходит ли тип данных для входящих данных? Служба "Поиск ИИ Azure" поддерживает типы данных модели данных сущностей (EDM). Для данных SQL Azure существует диаграмма сопоставления, которая содержит эквивалентные значения. Дополнительные сведения см. в разделе Сопоставления полей и преобразования.
У вас есть одно поле, которое может использоваться в качестве ключа? Этим полем должно быть Edm.string, и оно должно однозначно идентифицировать документ. Для реляционных данных оно может быть сопоставлено с первичным ключом. Для больших двоичных объектов это может быть
metadata-storage-path. Если значения полей включают пробелы или дефисы, необходимо задать ключ шифрования Base-64 на этапе создания индексатора в разделе Дополнительные параметры, чтобы отключить проверку для этих символов.Задайте атрибуты, чтобы определить, как это поле используется в индексе.
Уделите время этому шагу, так как атрибуты определяют физическое выражение полей в индексе. Если вы хотите изменить атрибуты позже, даже программно, вам потребуется удалить и перестроить индекс. Основные атрибуты, такие как доступные для поиска и извлечения, оказывают незначительное влияние на хранилище. Включение фильтров и использование средств подбора повышает требования к хранилищу.
Доступный для поиска: позволяет использовать полнотекстовый поиск. Каждое поле, используемое в запросах произвольной формы или в выражениях запросов, должно иметь этот атрибут. Инвертированные индексы создаются для каждого поля с меткой Доступный для поиска.
Доступный для получения: возвращает поле в результатах поиска. Каждое поле с содержимым для результатов поиска должно иметь этот атрибут. Установка этого поля не влияет на размер индекса.
Фильтруемый: позволяет ссылаться на поле в выражениях фильтра. Все поля, используемые в выражении $filter, должны иметь этот атрибут. Выражения фильтра используются для точных совпадений. Так как текстовые строки остаются нетронутыми, для размещения подробного содержимого требуется больше хранилища.
Аспектируемый: позволяет использовать поле в фасетной навигации. Добавить метку Аспектируемый можно только к полям, также отмеченным как фильтруемые.
Сортируемый: позволяет использовать поле при сортировке. Все поля, используемые в выражении $Orderby, должны иметь этот атрибут.
Требуется ли лексический анализ? Для полей Edm.string, доступных для поиска, вы можете настроить анализатор, если требуется расширенное индексирование и запросы.
По умолчанию задано Standard Lucene, но вы можете выбрать Microsoft English, если нужно использовать анализатор Майкрософт для расширенной обработки лексики, например для разрешения неправильных форм существительных и глаголов. На портале можно указать только языковые анализаторы. Если вы используете пользовательский анализатор или неязыковый анализатор, например Keyword, Pattern и т. д., необходимо создать его программным способом. Подробнее об анализаторах см. в разделе Добавление анализаторов языка.
Требуются ли функции typeahead в виде автозаполнения или предлагаемых результатов? Установите флажок Средство подбора, чтобы включить предложения запросов typeahead и автозаполнение для выбранных полей. Средства подбора добавляют слова с маркерами в индексе и таким образом потребляют больше места для хранения.
Конфигурация индексатора в мастере
Последняя страница мастера собирает пользовательские входные данные для конфигурации индексатора. Можно указать расписание и задать другие параметры, которые будут отличаться по типу источника данных.
Во внутреннем режиме мастер также настраивает следующие определения, которые не отображаются в индексаторе до тех пор, пока он не будет создан:
- сопоставления полей между источником данных и индексом
- Сопоставления полей выходных данных между выходными данными навыка и индексом
Следующие шаги
Лучший способ понять преимущества и ограничения мастера — его пошаговое применение. Ниже приведено краткое руководство по каждому шагу.