Что бы вы хотели узнать о Service Fabric?
Azure Service Fabric — это платформа распределенных систем, которая дает возможность не только легко упаковывать и развертывать масштабируемые и надежные микрослужбы, но и управлять ими. Service Fabric имеет большую контактную зону и вы можете многому научиться. Здесь представлен краткий обзор Service Fabric и описаны основные понятия, модели программирования, жизненный цикл приложения, тестирование, кластеры и мониторинг работоспособности. Обзор и сведения о том, как создавать микрослужбы с помощью Service Fabric, см. в статьях Общие сведения о Service Fabric и Разработка приложений с использованием микрослужб. Эта статья не содержит полный список связанной документации, но предоставляет ссылки на руководства по началу работы для каждой области Service Fabric.
Основные понятия
Разделы Терминология Service Fabric, Модель приложения и Поддерживаемые модели программирования содержат дополнительные понятия и их описание, но основы приведены в этой статье.
- Кластер Service Fabric. Проверьте эту ссылку на обучающее видео, чтобы получить общие сведения об архитектуре Service Fabric и ее основных понятиях и изучить множество функций Service Fabric.
- Основные понятия среды выполнения. Проверьте эту ссылку для обучающего видео, чтобы понять понятия среды выполнения и рекомендации Service Fabric.
- Основные понятия типа конструктора: проверьте эту ссылку для обучения видео, чтобы понять, что приложение, упаковка и развертывание; ключевые термины Service Fabric, абстракции и понятия.
Время разработки: тип службы, пакет службы и манифест, тип приложения, пакет приложения и манифест
Тип службы — имя и версия, назначенные пакетам кода, пакетам данных и пакетам конфигурации службы. Он определяется в файле ServiceManifest.xml. Тип службы состоит из исполняемого кода и параметров конфигурации службы, которые загружаются во время выполнения, а также статических данных, которые используются этой службой.
Пакет службы — каталог на диске, содержащий файл ServiceManifest.xml типа службы, который ссылается на код, статические данные и пакеты конфигурации для типа службы. Например, в пакете службы могут быть указаны ссылки на пакеты кода, статических данных и конфигураций, определяющие службу баз данных.
Тип приложения — имя и версия, назначенные коллекции типов служб. Он определяется в файле ApplicationManifest.xml.
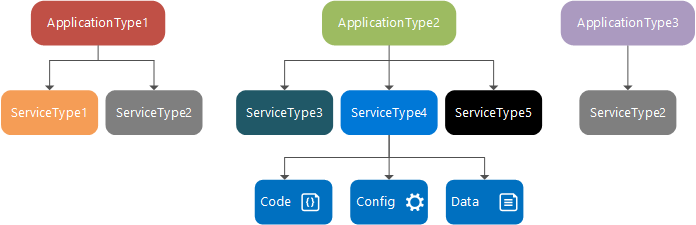
Пакет приложения — это каталог на диске, содержащий файл ApplicationManifest.xml типа приложения, который ссылается на пакеты службы для каждого типа службы, входящего в тип приложения. Например, пакет почтового приложения может содержать ссылки на пакет службы очередей, пакет службы внешнего интерфейса и пакет службы базы данных.
Файлы в каталоге пакета приложения копируются в хранилище образов кластера Service Fabric. Вы сможете создать именованное приложение этого типа для запуска в кластере. Создав именованное приложение, вы можете создать именованную службу, используя для этого один из типов служб соответствующего типа приложения.
Время выполнения: кластеры и узлы, именованные приложения, именованные службы, секции и реплики
Кластер Service Fabric — это подключенный к сети набор виртуальных машин или физических компьютеров, в котором вы развертываете микрослужбы и управляете ими. Кластеры можно масштабировать до нескольких тысяч машин.
Узлом называется компьютер или виртуальная машина, которая входит в состав кластера. Каждому узлу назначается имя (строка). Узлы имеют свои характеристики, в частности свойства размещения. Каждый компьютер или виртуальная машина имеет автоматически запускаемую службу Windows, FabricHost.exe. Она запускается после загрузки системы и запускает два исполняемых файла: Fabric.exe и FabricGateway.exe. Эти два файла формируют узел. В сценариях разработки или тестирования на одном компьютере или виртуальной машине можно разместить несколько узлов, запустив несколько экземпляров Fabric.exe и FabricGateway.exe.
Именованное приложение представляет собой коллекцию составляющих его именованных служб, которые выполняют определенные функции. Служба выполняет завершенную и отдельную функцию (она может запускаться и работать независимо от других служб) и состоит из кода, конфигурации и данных. Когда пакет приложения будет скопирован в хранилище образов, вы сможете создать в кластере экземпляр приложения. Для этого нужно указать тип приложения в пакете приложения (имя и версию). Каждому экземпляру приложения этого типа назначается универсальный код ресурса (URI), который выглядит следующим образом: fabric:/MyNamedApp. Из одного типа приложения в кластере можно создать несколько именованных приложений. Именованные приложения можно также создавать из разных типов приложений. Для каждого именованного приложения управление и контроль версий выполняются отдельно.
Создав именованное приложение, вы можете создать в кластере экземпляр одной из его служб определенного типа (именованную службу), используя для этого соответствующий тип службы (имя и версию). Каждому экземпляру службы определенного типа назначается код URI, частью которого будет URI именованного приложения. Например, если в именованном приложении MyNamedApp вы создадите именованную службу MyDatabase, ее универсальный код ресурса (URI) будет выглядеть так: fabric:/MyNamedApp/MyDatabase. В именованном приложении можно создать одну или несколько именованных служб. У каждой именованной службы может быть своя схема секционирования и свое количество реплик и экземпляров.
Существуют два типа службы: с отслеживанием состояния и без него. В службах без отслеживания состояния данные состояния не сохраняются. В службах без отслеживания состояния либо вообще нет постоянного хранилища, либо данные устойчивого состояния сохраняются во внешней службе хранилища, например в службе хранилища Azure, Базе данных SQL Azure или Azure Cosmos DB. В службе с отслеживанием данные состояния сохраняются. Для управления ими используются модели программирования "Надежная коллекция" или Reliable Actors.
При создании именованной службы указывается схема секционирования. Службы с большим количеством состояний разделяют данные по секциям. Каждая секция отвечает за часть полного состояния службы. Эти секции распределены между узлами кластера.
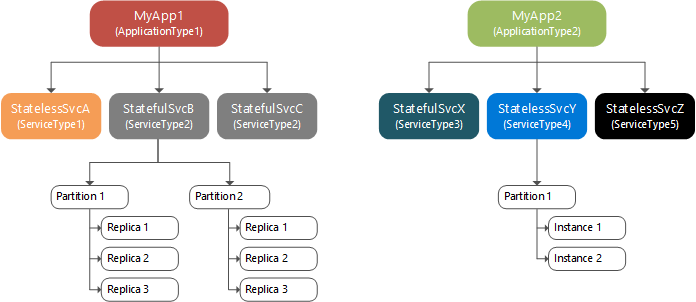
На следующей диаграмме отображается отношение между приложениями и экземплярами службы, разделами и репликами.
Секционирование, масштабирование и доступность
Секционирование не является уникальной особенностью Service Fabric. Распространенный пример секционирования — это секционирование данных или сегментирование. Службы с отслеживанием состояния с большим количеством состояний разделяют данные по секциям. Каждая секция отвечает за часть полного состояния службы.
Реплики каждой секции распределяются по узлам в кластере. Это позволяет состоянию именованной службы масштабироваться. По мере роста объема данных размер секций увеличивается, и Service Fabric перераспределяет секции между узлами для максимально эффективного использования аппаратных ресурсов. Если вы добавите новые узлы в кластер, реплики секции подвергнутся повторной балансировке с учетом этих узлов. Общая производительность приложения улучшится, а конфликт доступа к памяти уменьшится. При неэффективном использовании узлов в кластере вы можете уменьшить их количество. Service Fabric снова перераспределит реплики секции по меньшему количеству узлов, чтобы эффективно использовать оборудование на каждом узле.
В пределах одной секции именованные службы без отслеживания состояния хранят экземпляры, а именованные службы с отслеживанием состояния — реплики. Как правило, именованные службы без отслеживания состояния используют только одну секцию, так как у них нет внутреннего состояния, хотя имеются и исключения. Экземпляры в секциях обеспечивают доступность. Если один экземпляр выходит из строя, другие продолжают работать обычным образом, а Service Fabric создает новый экземпляр. Именованные службы с отслеживанием состояния хранят сведения о своем состоянии в репликах, и у каждой секции есть свой набор реплик. Операции чтения и записи выполняются в одной реплике (которая называется первичной). Изменения в состоянии, вызванные операциями записи, реплицируются на множество других реплик (которые называются активными вторичными репликами). Если в реплике возникает сбой, Service Fabric создает новую реплику из существующих.
Микрослужбы Service Fabric с отслеживанием и без отслеживания состояния
Service Fabric позволяет создавать приложения, состоящие из микрослужб или контейнеров. Микрослужбы без отслеживания состояния (протоколы шлюзов, веб-прокси и т. д.) не поддерживают изменяемые состояния без обработки запроса службой. К службам без отслеживания состояния можно отнести рабочие роли в облачных службах Azure. Микрослужбы с отслеживанием состояния (учетные записи пользователей, базы данных, устройства, корзины интернет-магазинов, очереди и т. д.) поддерживают изменяемые достоверные состояния без обработки запроса службой. Современные веб-приложения могут одновременно содержать микрослужбы с отслеживанием состояния и без него.
Ключевое отличие Service Fabric — основной акцент на создание служб с отслеживанием состояния на основе встроенных моделей программирования или контейнерных служб с отслеживанием состояния. В сценариях приложений описаны ситуации, в которых используются службы с отслеживанием состояния.
Зачем существуют микрослужбы с отслеживанием состояния наряду с микрослужбами без отслеживания состояния? Основных преимуществ два.
- Вы можете создавать службы оперативной обработки транзакций (OLTP) с высокой пропускной способностью, низкой задержкой и хорошей отказоустойчивостью, размещая программы и данные рядом на одной виртуальной машине. В качестве примеров таких служб можно привести онлайн-магазины, службы поиска, системы Интернета вещей, торговые системы, системы обработки кредитных карт и обнаружения мошенничества, а также службы управления персональными данными.
- Вы можете упростить разработку приложений. Микрослужбы с отслеживанием состояния устраняют необходимость в дополнительных очередях и кэшах, которые обычно требуются для обеспечения доступности и минимизации задержек в приложениях без отслеживания состояния. Для служб с отслеживанием состояния изначально характерны высокая доступность и минимальные задержки, поэтому приложением в целом будет проще управлять.
Поддерживаемые модели программирования
Service Fabric предлагает несколько способов записи и управления службами. Службы могут использовать API-интерфейсы платформы Service Fabric, чтобы в полной мере использовать компоненты платформы и платформы приложений. Службы также могут представлять любую скомпилированную исполняемую программу, написанную на любом языке и размещенную в кластере Service Fabric. Дополнительные сведения см. в разделе Поддерживаемые модели программирования.
Контейнеры
По умолчанию Service Fabric развертывает и активирует службы как процессы. Service Fabric также позволяет развертывать службы в контейнерах. Главное, что вы можете объединять эти два подхода, используя в одном приложении службы с процессами и контейнерами. Service Fabric поддерживает развертывание контейнеров Linux и контейнеров Windows на Windows Server 2016. В контейнерах можно развернуть имеющиеся приложения, службы без отслеживания состояния или службы с отслеживанием состояния.
Reliable Services
Reliable Services — это облегченная платформа для записи служб, которые интегрируются с платформой Service Fabric и используют весь набор функций платформы. Службы Reliable Services могут быть без отслеживания состояния, как и большинство платформ служб, таких как веб-серверы или рабочие роли в облачных службах Azure. При этом состояние сохраняется во внешнем решении, таком как база данных Azure или хранилище таблиц Azure. Службы Reliable Services могут также быть с отслеживанием состояния. При этом состояние сохраняется прямо в службу с использованием Reliable Collections. Состояние становится высокодоступным за счет репликации и распределения путем секционирования, которыми автоматически управляет Service Fabric.
Reliable Actors
Платформа Reliable Actor, построенная на базе Reliable Services, представляет собой платформу приложений, реализующую модель Virtual Actor на основе шаблона проектирования субъектов. Платформа надежных субъектов использует независимые единицы вычислений и состояний с однопоточным выполнением, которые называются субъектами. Платформа надежных субъектов обеспечивает встроенное взаимодействие для субъектов, а также предустановленное сохранение состояния и масштабируемые конфигурации.
ASP.NET Core
Service Fabric интегрируется с ASP.NET Core в качестве модели программирования первого класса для создания веб-приложений и приложений API. ASP.NET Core можно использовать двумя различными способами в Service Fabric:
- Разместить в виде гостевого исполняемого файла. В основном это используется для запуска существующих приложений ASP.NET Core в Service Fabric без изменения кода.
- Выполнить в службе Reliable Service. Это обеспечивает более эффективную интеграцию со средой выполнения Service Fabric и позволяет использовать службы ASP.NET Core с отслеживанием состояния.
Гостевые исполняемые файлы
Гостевой исполняемый файл — это произвольный существующий исполняемый файл (написанный на любом языке), который размещен в кластере Service Fabric среди других служб. Гостевые исполняемые файлы не интегрируются с интерфейсами API Service Fabric напрямую. Однако они по-прежнему используют преимущества предлагаемых платформой функций, такие как настраиваемые отчеты о работоспособности и загрузке, а также возможности обнаружения службы путем вызова REST API. Они также имеют поддержку полного жизненного цикла приложения.
Жизненный цикл приложения
Как и в случае с другими платформами, приложение в Service Fabric обычно проходит следующие фазы: проектирование, разработка, тестирование, развертывание, обновление, техническое обслуживание и удаление. Service Fabric предоставляет первоклассную поддержку полного жизненного цикла приложений в облаке: от разработки, развертывания, ежедневного управления и технического обслуживания до вывода приложения из эксплуатации. Модель службы использует несколько различных ролей для независимого участия в жизненном цикле приложения. Жизненный цикл приложения в Service Fabric представляет обзор интерфейсов API, а также их использование различными ролями на протяжении всех фаз жизненного цикла приложения в Service Fabric.
Всем жизненным циклом приложения можно управлять с помощью командлетов PowerShell, команд CLI, C# APIs, API Java и REST API. Вы также можете настроить конвейеры непрерывной интеграции и разработки с помощью средств Azure Pipelines или Jenkins.
По этой ссылке вы найдете обучающее видео о том, как управлять жизненным циклом приложения:
Тестирование приложений и служб
Чтобы создать службы именно в масштабах облака, очень важно, чтобы приложения и службы были устойчивы к реальным сбоям. Служба анализа сбоев предназначена для проверки служб, созданных на платформе Service Fabric. Вместе с Fault Analysis Service она позволяет вызывать значимые ошибки и запускать в приложениях тестовые сценарии. Вызываемые ошибки и сценарии позволяют воспроизвести и проверить в контролируемых, безопасных и согласованных условиях разные состояния и переходы, происходящие со службой в течение ее жизненного цикла.
Действия выполняются в службе для ее тестирования с использованием отдельных ошибок. Разработчик службы может использовать их в качестве стандартных блоков для создания сложных сценариев. Ниже приведены примеры моделирования ошибок.
- Перезапустите узел для моделирования любого количества ситуаций, в которых выполняется перезагрузка компьютера или виртуальной машины.
- Переместите реплики службы с отслеживанием состояния для имитации балансировки нагрузки, отработки отказа или обновления приложения.
- Вызовите потерю кворума в службе с отслеживанием состояния, чтобы создать ситуацию, в которой операции записи невозможны, так как отсутствуют "резервные" или "вторичные" реплики, необходимые для приема новых данных.
- Вызовите потерю данных в службе с отслеживанием состояния, чтобы создать ситуацию, в которой все данные о состоянии в памяти полностью уничтожаются.
Сценарии — это сложные операции, состоящие из одного или нескольких действий. Служба анализа сбоев включает два полных встроенных сценария:
- Сценарий хаотического тестирования моделирует в кластере непрерывные сбои, чередуя как нормальные, так и ненормальные ошибки, на протяжении долгого периода времени.
- Сценарий отработки отказа — это версия сценария хаотического тестирования, предназначенная для конкретной секции службы, при котором другие службы не затрагиваются.
Кластеры
Кластер Service Fabric — это подключенный к сети набор виртуальных машин или физических компьютеров, в котором вы развертываете микрослужбы и управляете ими. Кластеры можно масштабировать до нескольких тысяч машин. Узлом кластера называется компьютер или виртуальная машина, которая входит в состав кластера. Каждому узлу назначается имя (строка). Узлы имеют свои характеристики, в частности свойства размещения. У каждого компьютера или виртуальной машины есть автоматически запускаемая служба FabricHost.exe. Она запускается после загрузки системы и запускает два исполняемых файла: Fabric.exe и FabricGateway.exe. Эти два файла формируют узел. В целях тестирования на одном компьютере или виртуальной машине можно разместить несколько узлов, запустив несколько экземпляров Fabric.exe и FabricGateway.exe.
Кластеры Service Fabric можно создать на виртуальных или физических компьютерах под управлением Windows Server или Linux. Вы можете развертывать и запускать приложения Service Fabric в любой среде с набором подключенных друг к другу компьютеров под управлением Windows Server или Linux как локально, так и в облаке Microsoft Azure или другого поставщика облачных служб.
Кластеры в Azure
Выполнение кластеров Service Fabric в Azure обеспечивает интеграцию с другими функциями и службами Azure, благодаря чему эксплуатировать кластер и управлять им проще и надежнее. Так как кластер является ресурсом Azure Resource Manager, вы можете моделировать его, как и любой другой ресурс в Azure. Resource Manager также предоставляет простое управление всеми ресурсами, которые кластер использует как единое целое. В Azure возможна интеграция кластеров с системой диагностики Azure и журналами Azure Monitor. Типы узлов кластера являются масштабируемыми наборами виртуальных машин, поэтому функция автомасштабирования является встроенной.
Вы можете создать кластер в Azure на портале Azure с помощью шаблона или Visual Studio.
Service Fabric для Linux дает возможность создавать, развертывать высокодоступные приложения с высокой масштабируемостью и управлять ими в Linux так же, как и в Windows. Платформы Service Fabric (Reliable Services и Reliable Actors) в Linux доступны для программирования на языках Java и C# (.NET Core). Также можно создавать гостевые исполняемые службы , используя любой язык или платформу. Также поддерживается оркестрация контейнеров Docker. В контейнерах Docker могут выполняться гостевые исполняемые файлы или собственные службы Service Fabric, использующие платформы Service Fabric. Чтобы узнать больше, прочитайте о Service Fabric в Azure.
Некоторые функции Service Fabric поддерживаются в Windows, но не поддерживаются в Linux. Дополнительные сведения см. в статье Различия между Service Fabric для Linux (предварительная версия) и Windows (общедоступная версия).
Изолированные кластеры
Для Service Fabric предусмотрен пакет установки, с помощью которого можно создать автономный кластер Service Fabric в локальной среде и у любого поставщика облачных служб. Автономные кластеры можно размещать в любом расположении. Если данные ограничены нормативными требованиями или вы хотите хранить их локально, вы можете разместить собственный кластер и приложения. Приложения Service Fabric можно запускать в различных средах размещения без изменений, так что знания о создании приложений сохраняют свою актуальность при переходе из одной среды размещения в другую.
Создание первого изолированного кластера Service Fabric
Автономные кластеры Linux пока не поддерживаются.
Безопасность кластера
Кластеры должны быть защищены для предотвращения подключения к ним неавторизованных пользователей, особенно в тех случаях, когда на кластере выполняются рабочие нагрузки в рабочей среде. Существует возможность создания незащищенного кластера, однако стоит учитывать, что это позволит анонимным пользователям подключаться к нему, если конечные точки управления общедоступны через Интернет. Вы не сможете включить безопасность для незащищенного кластера через некоторое время, так как ее можно включить только в процессе создания кластера.
Сценарии обеспечения безопасности кластера:
- безопасность обмена данными между узлами;
- безопасность обмена данными между клиентами и узлами;
- Управление доступом на основе ролей Service Fabric
Дополнительные сведения см. в статье Сценарии защиты кластера Service Fabric.
Масштабирование
Если вы добавите новые узлы в кластер, реплики секции подвергнутся повторной балансировке Service Fabric с учетом этих узлов. Общая производительность приложения улучшится, а конфликт доступа к памяти уменьшится. При неэффективном использовании узлов в кластере вы можете уменьшить их количество. Service Fabric снова перераспределит реплики и экземпляры секции по меньшему количеству узлов, чтобы эффективно использовать оборудование на каждом узле. Кластеры в Azure можно масштабировать вручную или программным способом. Автономные кластеры можно масштабировать вручную.
Обновления кластера
Периодически выпускаются новые версии среды выполнения Service Fabric. При запуске среды выполнения или Service Fabric кластер обновляется, так что вы всегда используете поддерживаемую версию. Кроме обновлений Service Fabric вы можете также обновить конфигурацию кластера, например сертификаты или порты приложения.
Кластер Service Fabric представляет собой ресурс, который принадлежит вам, но частично управляется корпорацией Майкрософт. Корпорация Майкрософт отвечает за исправления базовой операционной системы и обновления Service Fabric в кластере. Вы можете настроить для кластера автоматическое обновление Service Fabric по мере выпуска новых версий корпорацией Майкрософт или же выбрать нужную версию в списке поддерживаемых. Обновления Service Fabric и конфигурации можно настроить с помощью портала Azure или Resource Manager. Дополнительные сведения см. в статье Обновление кластера Azure Service Fabric.
Автономный кластер является ресурсом, который полностью принадлежит вам. Вы отвечаете за исправления базовой операционной системы и запуск обновлений Service Fabric. Если кластер может подключиться к странице https://www.microsoft.com/download, вы можете настроить автоматическое скачивание и подготовку нового пакета среды выполнения Service Fabric. Затем можно инициировать само обновление. Если же кластер не может получить доступ к странице https://www.microsoft.com/download, вы можете вручную скачать новый пакет среды выполнения, используя компьютер с доступом к Интернету, а затем запустить обновление. Дополнительные сведения см. в статье Обновление автономного кластера Azure Service Fabric в Windows Server.
Мониторинг работоспособности
В Service Fabric представлена модель работоспособности, которая предназначена для обозначения условий неработоспособности кластеров или приложений в отдельных сущностях (например, узлах кластера и репликах служб). В этой модели используются информаторы о работоспособности (системные компоненты и устройства наблюдения). Их целью является простая и быстрая диагностика и восстановление. Создатели службы должны предупреждать проблемы работоспособности и создавать отчеты о состоянии. Любые условия, которые могут повлиять на работоспособность, должны регистрироваться, особенно в случаях, если это может помочь выяснить причину возникновения проблем. Когда система будет настроена и запущена в рабочей среде, получаемая информация о работоспособности позволит сэкономить время и усилия, требуемые для анализа и отладки.
Докладчики Service Fabric отслеживают определенные условия. Они сообщают об этих условиях на основе своего локального представления. В хранилище данных о работоспособности собираются данные о работоспособности, отправленные всеми информаторами, что помогает определять глобальную работоспособность сущностей. Модель оптимизирована, она гибкая и простая в использовании. Качество отчетов о работоспособности определяет точность представления данных о работоспособности кластера. Ложные положительные результаты, которые неправильно отображают проблемы работоспособности, могут отрицательно повлиять на обновления или другие службы, использующие данные о работоспособности. В качестве примеров можно вспомнить службы восстановления и механизмы предупреждений. Поэтому нужно тщательно обдумать, как получить отчеты с отображением только нужных условий.
Отчет можно создать с помощью приведенных ниже компонентов.
- Отслеживаемая реплика службы Service Fabric или ее экземпляр.
- Внутренние устройства наблюдения, развернутые как служба Service Fabric (например, служба без отслеживания состояния Service Fabric, которая проверяет условия и формирует отчеты). Модули наблюдения можно развернуть на всех узлах или сгруппировать с отслеживаемой службой.
- Внутренние устройства наблюдения, которые запускаются на узлах Service Fabric, но не реализованы как службы Service Fabric.
- Внешние устройства наблюдения, которые зондируют ресурс за пределами кластера Service Fabric (например, служба отслеживания Gomez и другие).
Готовые к использованию компоненты Service Fabric поддерживают создание отчетов о работоспособности по всем сущностям в кластере. В отчетах о работоспособности системы отражаются показатели функциональности кластеров и приложений, а также отмечаются проблемы с работоспособностью. Что касается приложений и служб, отчеты о работоспособности системы проверяют правильность реализации и поведения сущностей на уровне среды выполнения Service Fabric. Отчеты не обеспечивают наблюдение за работоспособностью бизнес-логики службы или обнаружение процессов, которые перестали отвечать. Чтобы добавить сведения о работоспособности конкретно для логики вашей службы, ознакомьтесь со статьей о добавлении настраиваемых отчетов о работоспособности Service Fabric.
Service Fabric предоставляет несколько способов просмотра отчетов о работоспособности, объединенных в хранилище данных о работоспособности.
- Service Fabric Explorer или другие средства визуализации;
- запросы о работоспособности (с помощью PowerShell, CLI, API C# FabricClient и API Java FabricClient или REST APIs);
- общие запросы, возвращающие перечень сущностей, среди свойств которых есть работоспособность (с помощью PowerShell, CLI, API или REST).
Мониторинг и диагностика
Мониторинг и диагностика крайне важны для разработки, тестирования и развертывания приложений и служб в любой среде. Оптимальная работа решений Service Fabric зависит от эффективного планирования и реализации мониторинга и диагностики, которые помогают обеспечить правильную работу приложений и служб в локальной среде разработки или в производственной среде.
Основные цели мониторинга и диагностики:
- обнаружение и диагностика проблем с оборудованием и инфраструктурой;
- выявление проблем с программным обеспечением и приложениями, а также сокращение времени простоя служб;
- анализ потребления ресурсов и помощь в принятии решений, связанных с выполнением операций;
- оптимизация производительности приложений, служб и инфраструктуры;
- создание бизнес-аналитики и определение областей для оптимизации.
Общий рабочий процесс мониторинга и диагностики состоит из трех этапов.
- Создание событий. Сюда входят события (журналы, трассировки, пользовательские события) на уровне инфраструктуры (кластера), платформы и приложения или службы.
- Агрегирование событий. Создаваемые события должны быть собраны и агрегированы до их отображения.
- Анализ. События должны быть доступными для просмотра и использования в определенном формате, обеспечивающем возможность анализа и отображения.
Доступны разные продукты с поддержкой этих трех областей, и вы можете использовать разные инструменты для реализации каждого из этапов. См. дополнительные сведения о мониторинге и диагностике в Azure Service Fabric.
Следующие шаги
- Узнайте, как создать кластер в Azure или автономный кластер в Windows.
- Попробуйте создать службу с помощью модели программирования Reliable Services или Reliable Actors.
- Узнайте, как выполнять миграцию из облачных служб.
- Научитесь отслеживать и диагностировать состояние служб.
- Узнайте о тестировании приложений и служб.
- Ознакомьтесь со сведениями об оркестрации ресурсов кластера и управлении ими.
- Просмотрите примеры кода для Service Fabric.
- Узнайте о вариантах поддержки Service Fabric.
- Просматривайте статьи и обновления в блоге группы разработчиков.