Повышение производительности общих папок Azure NFS
В этой статье объясняется, как повысить производительность сетевых файловых систем (NFS) общих папок Azure.
Применяется к
| Тип общей папки | SMB | NFS |
|---|---|---|
| Стандартные общие папки (GPv2), LRS/ZRS | ||
| Стандартные общие папки (GPv2), GRS/GZRS | ||
| Общие папки уровня "Премиум" (FileStorage), LRS/ZRS |
Увеличьте размер перед чтением, чтобы повысить пропускную способность чтения
Параметр read_ahead_kb ядра в Linux представляет объем данных, которые должны быть "прочитаны заранее" или предварительно возвращены во время последовательной операции чтения. Версии ядра Linux до версии 5.4 задают значение перед чтением эквивалентно 15 раз подключенной файловой системе rsize, которая представляет параметр подключения на стороне клиента для размера буфера чтения. Это задает достаточно высокое значение для чтения, чтобы повысить пропускную способность последовательного чтения клиента в большинстве случаев.
Однако начиная с ядра Linux версии 5.4 клиент Linux NFS использует значение по умолчанию read_ahead_kb 128 КиБ. Это небольшое значение может уменьшить объем пропускной способности чтения для больших файлов. Клиенты, обновляющие выпуски Linux с большим значением для чтения до выпусков с 128 КиБ по умолчанию, могут снизить производительность последовательного чтения.
Для ядер Linux версии 5.4 или более поздней версии рекомендуется постоянно устанавливать read_ahead_kb значение 15 МиБ для повышения производительности.
Чтобы изменить это значение, задайте размер перед чтением, добавив правило в udev, диспетчер устройств ядра Linux. Выполните следующие действия:
В текстовом редакторе создайте файл /etc/udev/rules.d/99-nfs.rules , введя и сохраняя следующий текст:
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"В консоли примените правило udev, выполнив команду udevadm в качестве суперпользователя и перезагрузив файлы правил и другие базы данных. Эту команду необходимо выполнить только один раз, чтобы udev знал о новом файле.
sudo udevadm control --reload
Nconnect
Nconnect — это параметр подключения Linux на стороне клиента, который повышает производительность в масштабе, позволяя использовать дополнительные подключения протокола TCP между клиентом и службой файлов Azure Premium для NFSv4.1.
Преимущества nconnect
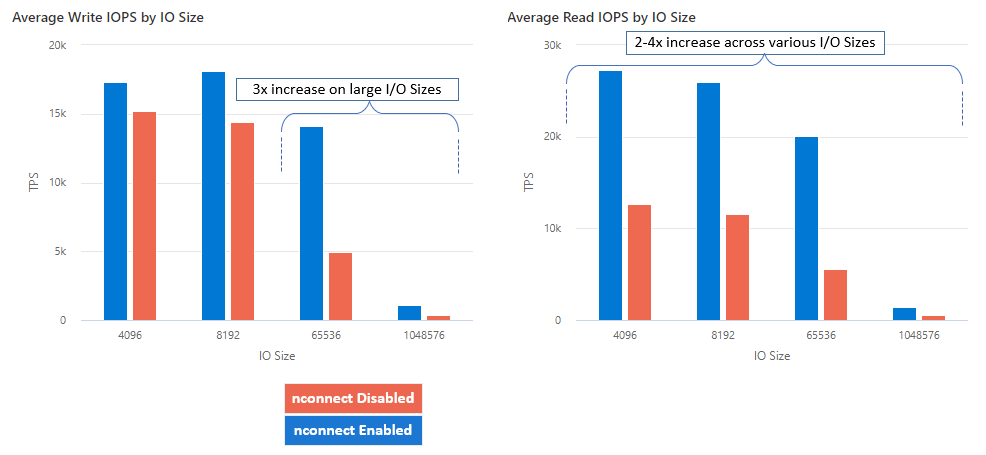
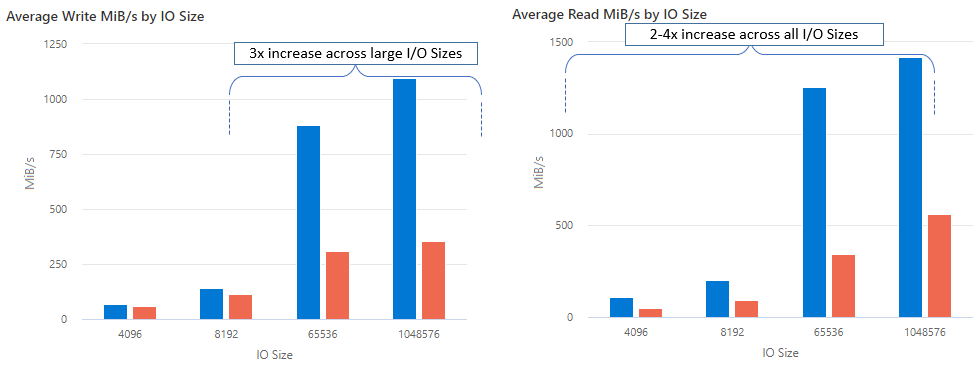
С помощью nconnectэтого можно увеличить производительность в масштабе, используя меньше клиентских компьютеров, чтобы снизить общую стоимость владения (TCO). Nconnect повышает производительность с помощью нескольких TCP-каналов на одном или нескольких сетевых адаптерах с помощью одного или нескольких клиентов. Без nconnectэтого вам потребуется примерно 20 клиентских компьютеров для достижения ограничений масштаба пропускной способности (10 ГиБ/с), предлагаемых наибольшим размером подготовки файлового ресурса Azure уровня "Премиум". С nconnectпомощью этих ограничений можно достичь только 6-7 клиентов, что снижает затраты на вычисления почти на 70 % при обеспечении значительных улучшений операций ввода-вывода в секунду (IOPS) и пропускной способности в масштабе. См. следующую таблицу.
| Метрика (операция) | Объем ввода-вывода | Улучшение производительности |
|---|---|---|
| Операции ввода-вывода в секунду (запись) | 64K, 1024K | В 3 раза |
| Операции ввода-вывода в секунду (чтение) | Все размеры операций ввода-вывода | 2-4x |
| Пропускная способность (запись) | 64K, 1024K | В 3 раза |
| Пропускная способность (чтение) | Все размеры операций ввода-вывода | 2-4x |
Необходимые компоненты
- Последние дистрибутивы Linux полностью поддерживают
nconnect. Для старых дистрибутивов Linux убедитесь, что версия ядра Linux — 5.3 или более поздняя. - Конфигурация подключения поддерживается только в том случае, если одна общая папка используется для каждой учетной записи хранения через частную конечную точку.
Влияние производительности nconnect
Мы достигли следующих результатов производительности при использовании nconnect параметра подключения с общими папками NFS Azure на клиентах Linux в масштабе. Дополнительные сведения о том, как мы достигли этих результатов, см . в разделе конфигурации теста производительности.
Рекомендации для nconnect
Следуйте этим рекомендациям, чтобы получить наилучшие результаты.nconnect
Задайте значение nconnect=4.
Хотя Файлы Azure поддерживает nconnect настройку до максимального значения 16, рекомендуется настроить параметры подключения с оптимальным параметромnconnect=4. В настоящее время для реализации Файлы Azure реализацию Файлы Azure нет никаких достижений, превышающих nconnectчетыре канала. На самом деле превышение четырех каналов к одной общей папке Azure из одного клиента может негативно повлиять на производительность из-за насыщенности сети TCP.
Тщательное создание размера виртуальных машин
В зависимости от требований к рабочей нагрузке важно правильно масштабировать клиентские виртуальные машины , чтобы избежать ограничения ожидаемой пропускной способности сети. Для достижения ожидаемой пропускной способности сети не требуется несколько сетевых контроллеров (сетевых адаптеров). Хотя обычно используются виртуальные машины общего назначения с Файлы Azure, различные типы виртуальных машин доступны в зависимости от потребностей рабочей нагрузки и доступности региона. Дополнительные сведения см. в разделе "Селектор виртуальных машин Azure".
Сохранение глубины очереди меньше или равно 64
Глубина очереди — это количество ожидающих запросов ввода-вывода, которые может обслуживать ресурс хранилища. Мы не рекомендуем превышать оптимальную глубину очереди 64, так как вы не увидите больше повышения производительности. Дополнительные сведения см. в разделе "Глубина очереди".
Nconnect Конфигурация для подключения
Если для рабочей нагрузки требуется подключение нескольких общих папок с одной или несколькими учетными записями хранения с разными nconnect параметрами одного клиента, то эти параметры будут сохраняться при подключении через общедоступную конечную точку. Конфигурация подключения поддерживается только в том случае, если одна общая папка Azure используется для каждой учетной записи хранения через частную конечную точку, как описано в сценарии 1.
Сценарий 1. nconnect Конфигурация подключения через частную конечную точку с несколькими учетными записями хранения (поддерживается)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Сценарий 2. nconnect Конфигурация подключения через общедоступную конечную точку (не поддерживается)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Примечание.
Даже если учетная запись хранения разрешается в другой IP-адрес, мы не можем гарантировать, что адрес будет сохранен, так как общедоступные конечные точки не являются статическими.
Сценарий 3. nconnect Конфигурация подключения через частную конечную точку с несколькими общими папками в одной учетной записи хранения (не поддерживается)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
Конфигурация для теста производительности
Мы использовали следующие ресурсы и средства тестирования для достижения и измерения результатов, описанных в этой статье.
- Один клиент: виртуальная машина Azure (DSv4-Series) с одним сетевым адаптером
- ОС: Linux (Ubuntu 20.40)
- Хранилище NFS: Файлы Azure общий файловый ресурс класса Premium (подготовлен 30 ТиБ, набор
nconnect=4)
| Размер | Виртуальные ЦП | Память | Временное хранилище (SSD) | Максимальное количество дисков данных | Максимальное число сетевых адаптеров | Ожидаемая пропускная способность сети |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 ГиБ | Только удаленное хранилище | 32 | 8 | 12500 Мбит/с |
Средства и тесты для тестирования тестов
Мы использовали гибкий средство тестирования ввода-вывода (FIO), бесплатное средство ввода-вывода с открытым исходным кодом, используемое как для проверки производительности, так и для проверки нагрузки и оборудования. Чтобы установить FIO, следуйте разделу "Двоичные пакеты" в файле FIO README, чтобы установить для выбранной платформы.
Хотя эти тесты сосредоточены на случайных шаблонах доступа ввода-вывода, вы получаете аналогичные результаты при использовании последовательного ввода-вывода.
Высокий уровень операций ввода-вывода в секунду: 100 % операций чтения
Размер ввода-вывода 4k — случайное чтение — глубина очереди 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Размер ввода-вывода 8k — случайное чтение — глубина очереди 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Высокая пропускная способность: 100 % операций чтения
Размер ввода-вывода 64k — случайное чтение — глубина очереди 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Размер ввода-вывода 1024k — 100 % случайного чтения — глубина очереди 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Высокий уровень операций ввода-вывода в секунду: 100 % операций записи
Размер ввода-вывода 4k — 100 % случайной записи — 64 глубины очереди
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Размер ввода-вывода 8k — 100 % случайной записи — 64 глубины очереди
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Высокая пропускная способность: 100 % операций записи
Размер ввода-вывода 64k — 100 % случайной записи — 64 глубины очереди
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Размер ввода-вывода 1024k — 100 % случайной записи — 64 глубины очереди
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Рекомендации по производительности nconnect
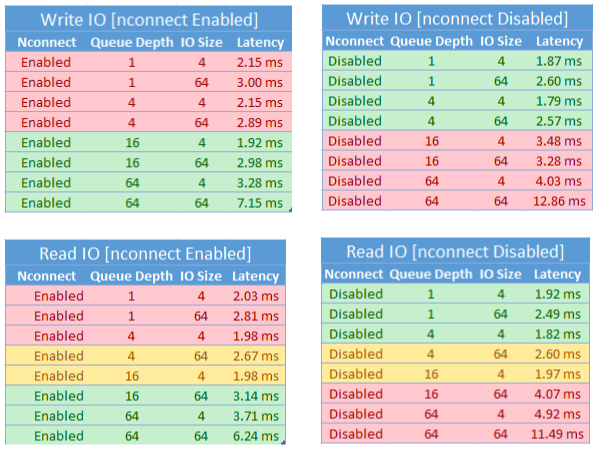
При использовании nconnect параметра подключения следует внимательно оценивать рабочие нагрузки, имеющие следующие характеристики:
- Задержка конфиденциальных рабочих нагрузок записи, которые являются одним потоком и /или используют низкую глубину очереди (менее 16)
- Задержка конфиденциальных рабочих нагрузок чтения, которые являются одним потоком и /или используют низкую глубину очереди в сочетании с меньшими размерами операций ввода-вывода
Не все рабочие нагрузки требуют высокомасштабируемых операций ввода-вывода в секунду или на протяжении всей производительности. Для небольших масштабируемых рабочих nconnect нагрузок может не быть смысла. Используйте следующую таблицу, чтобы решить, является ли nconnect ваша рабочая нагрузка выгодной. Сценарии, выделенные зеленым цветом, рекомендуется, а сценарии, выделенные красным цветом, не являются. Сценарии, выделенные желтым цветом, нейтральны.