Руководство. Создание приложения Apache Spark с помощью IntelliJ с помощью рабочей области Synapse
В этом руководстве показано, как с помощью подключаемого модуля Azure Toolkit for IntelliJ разрабатывать приложения Apache Spark на языке Scala и отправлять их в бессерверный пул Apache Spark напрямую из интегрированной среды разработки (IDE) IntelliJ. С помощью подключаемого модуля можно выполнять следующие действия:
- разрабатывать и отправлять приложения Spark на Scala в пул Spark.
- получать доступ к ресурсам пулов Spark.
- разрабатывать и запускать приложения Scala Spark в локальной среде.
В этом руководстве описано следующее:
- Использование подключаемого модуля Azure Toolkit for IntelliJ
- Разработка приложений Apache Spark
- Отправка приложения в пулы Spark
Необходимые компоненты
подключаемый модуль Azure Toolkit 3.27.0-2019.2 — установите из репозитория подключаемого модуля IntelliJ;
подключаемый модуль Scala — установите из репозитория подключаемого модуля IntelliJ.
Приведенное ниже предварительное требование предназначено только для пользователей Windows.
При запуске локального приложения Spark Scala на компьютере с Windows может возникнуть исключение, описанное в статье о SPARK-2356. Это исключение возникает, так как в Windows отсутствует файл WinUtils.exe. Чтобы устранить эту ошибку, скачайте этот исполняемый файл WinUtils, например, в папку C:\WinUtils\bin. После этого добавьте переменную среды HADOOP_HOME и присвойте ей значение C\WinUtils.
Создание приложения Spark Scala для пула Spark
Запустите IntelliJ IDEA и выберите Create New Project (Создать проект), чтобы открыть окно New Project (Новый проект).
На панели слева выберите Azure Spark/HDInsight.
В главном окне выберите Spark Project with Samples(Scala) (Проект Spark с примерами (Scala)).
Из раскрывающегося списка Build tool (Инструмент сборки) выберите один из следующих вариантов:
- Maven для поддержки мастера создания проекта Scala.
- SBT для управления зависимостями и создания проекта Scala.

Выберите Далее.
В окне New Project (Новый проект) укажите следующую информацию:
Свойство Description Имя проекта Введите имя. В этом учебнике используется myApp.Расположение проекта Введите необходимое расположение для сохранения проекта. Project SDK (Пакет SDK проекта) Это поле может быть пустым при первом использовании IDEA. Выберите New... (Создать...) и перейдите к JDK. Версия Spark Мастер создания интегрирует правильную версию пакетов SDK для Spark и Scala. Здесь можно выбрать нужную версию Spark. 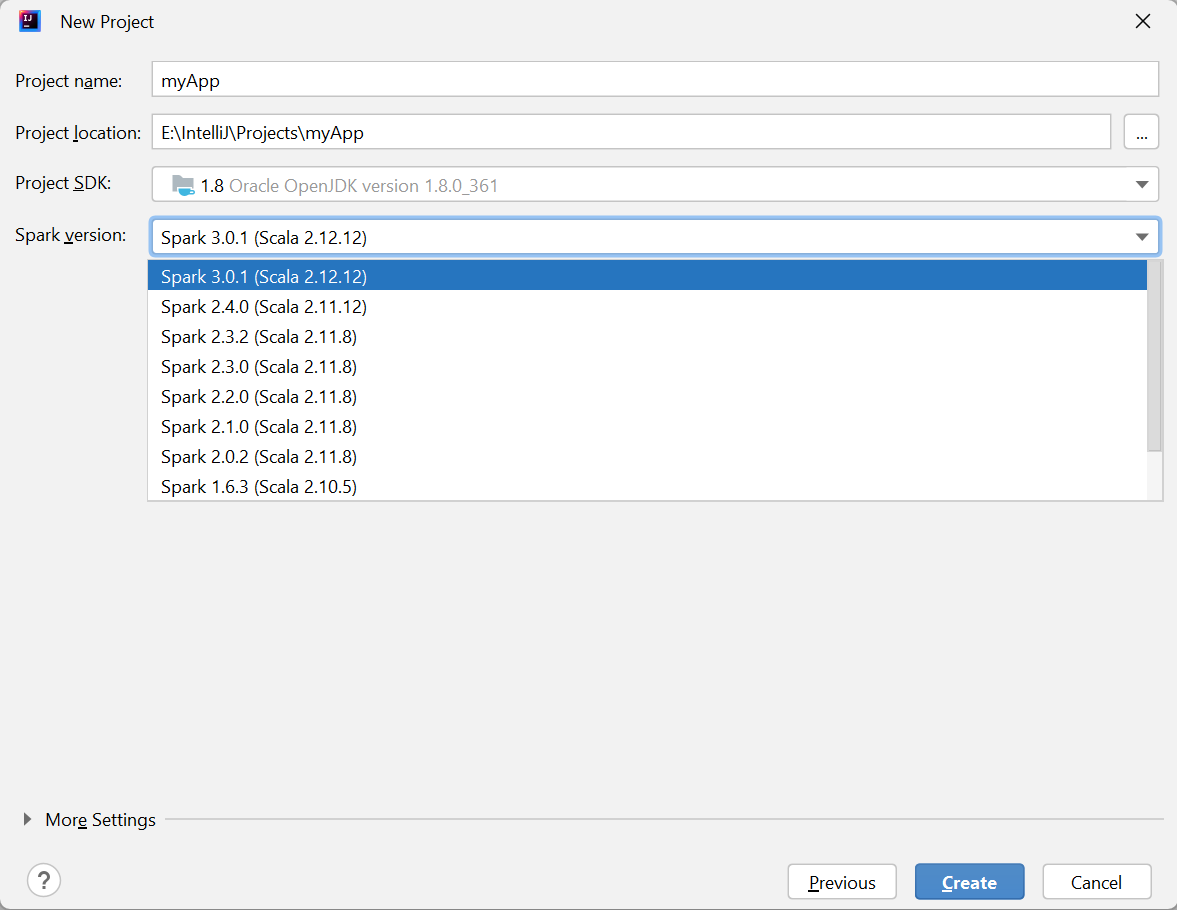
Выберите Готово. Может пройти несколько минут, прежде чем проект станет доступным.
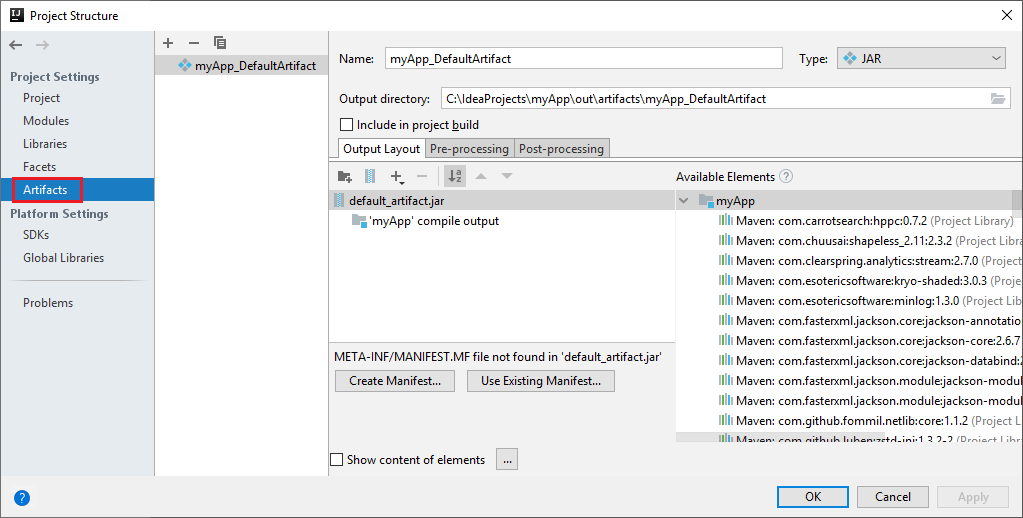
Проект Spark автоматически создает артефакт. Чтобы просмотреть артефакт, выполните указанные ниже действия.
a. В строке меню выберите File (Файл)>Project Structure... (Структура проекта…).
b. В окне структуры проекта щелкните Artifacts (Артефакты).
c. После просмотра артефакта щелкните Cancel (Отменить).
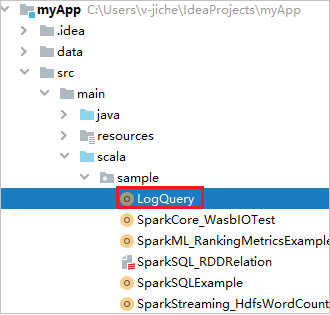
Найдите раздел LogQuery в каталоге myApp>src>main>scala>sample>LogQuery. В этом учебнике для запуска используется LogQuery.
Подключение к пулам Spark
Войдите в подписку Azure, чтобы подключиться к пулам Spark.
Войдите в подписку Azure.
В строке меню выберите Представление>Окно инструментов>Azure Explorer.
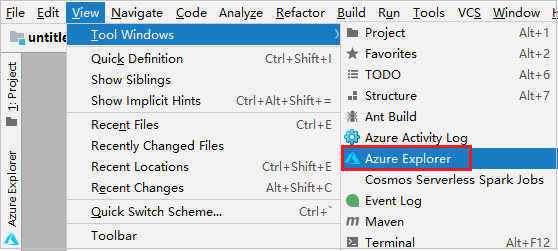
В Azure Explorer щелкните правой кнопкой мыши узел Azure, а затем выберите Войти.
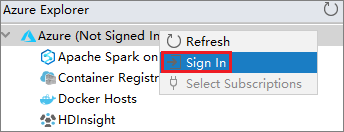
В диалоговом окне Вход в Azure выберите Имя пользователя устройства, а затем — Войти.

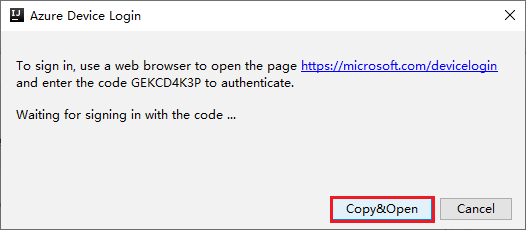
В диалоговом окне Azure Device Login (Вход в систему устройства Azure) щелкните Copy&Open (Копировать и открыть).
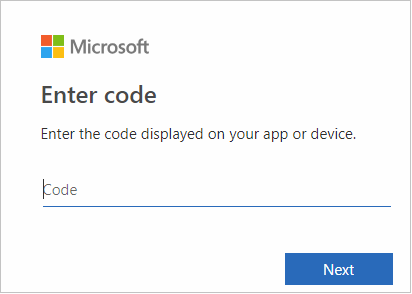
В интерфейсе браузера вставьте код и нажмите кнопку Далее.
Введите учетные данные Azure и закройте браузер.
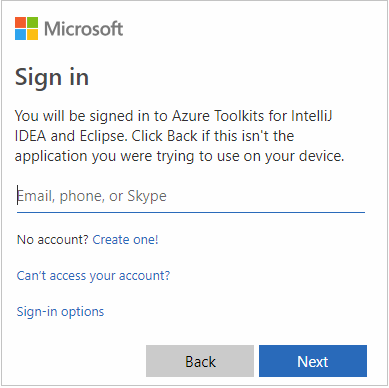
После входа в диалоговом окне Select Subscriptions (Выбор подписок) будут перечислены все подписки Azure, связанные с указанными учетными данными. Выберите свою подписку и нажмите кнопку Select (Выбрать).
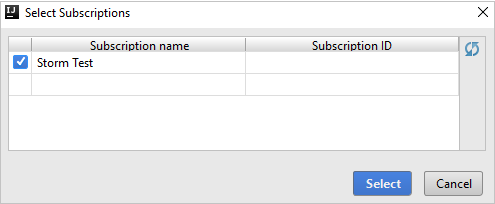
В Azure Explorer разверните узел Apache Spark on Synapse (Apache Spark в Synapse), чтобы просмотреть рабочие области в своей подписке.
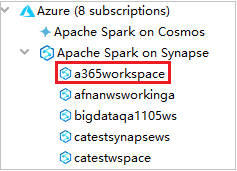
Для просмотра пулов Spark можно дополнительно развернуть рабочую область.

Удаленный запуск приложения Spark Scala в пуле Spark
После создания приложения Scala его можно запустить удаленно.
Откройте окно Run/Debug Configurations (Конфигурации запуска и отладки), щелкнув значок.

В диалоговом окне Run/Debug Configurations (Конфигурации запуска и отладки) щелкните +, а затем выберите Apache Spark on Synapse (Apache Spark в Synapse).

В окне Run/Debug Configurations (Конфигурации запуска и отладки) укажите следующие значения, а затем нажмите кнопку ОК.
Свойство Значение Пулы Spark Выберите пулы Spark, в которых хотите запустить приложение. Select an Artifact to submit (Выбор артефакта для запуска) Оставьте параметр по умолчанию. Имя главного класса значение по умолчанию — имя главного класса из выбранного файла. Класс можно изменить, нажав значок-многоточие (...) и выбрав другой класс. Job configurations (Конфигурация заданий) Вы можете изменить ключи или значения по умолчанию. Дополнительные сведения см. в статье Apache Livy REST API. Аргументы командной строки При необходимости можно ввести аргументы для основного класса, разделив их пробелом. Referenced Jars (Ссылки на JAR-файлы) и Referenced Files (Ссылки на файлы) можно ввести пути к используемым JAR и файлам, если они есть. Вы можете также просматривать файлы в виртуальной файловой системе Azure, которая сейчас поддерживает только кластер ADLS 2 поколения. Дополнительные сведения: конфигурация Apache Spark и отправка ресурсов в кластер. Job Upload Storage (Хранилище обновлений заданий) Разверните раздел, чтобы отобразить дополнительные параметры. Тип хранилища В раскрывающемся списке выберите Use Azure Blob to upload (Для отправки использовать BLOB-объект Azure) или Use cluster default storage account to upload (Для отправки использовать учетную запись хранения по умолчанию для кластера). Учетная запись хранения Введите имя своей учетной записи хранения. Storage Key (Ключ хранилища) Введите свой ключ к хранилищу данных. Контейнер хранилища Если вы ввели значения в поля Учетная запись хранения и Storage Key (Ключ хранилища), из раскрывающегося списка выберите контейнер хранилища. 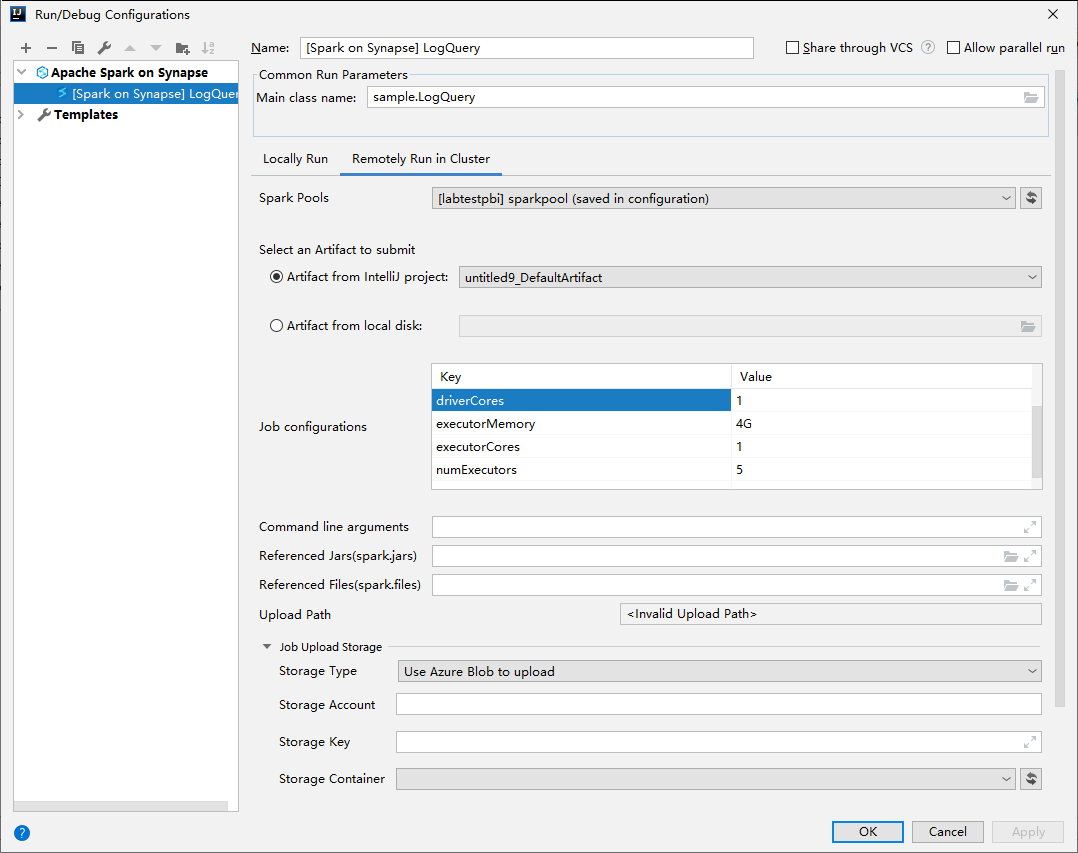
Щелкните значок SparkJobRun, чтобы отправить проект в выбранный пул Spark. На вкладке Remote Spark Job in Cluster (Удаленное задание Spark в кластере) внизу показан ход выполнения задания. Чтобы остановить работу приложения, нажмите красную кнопку.

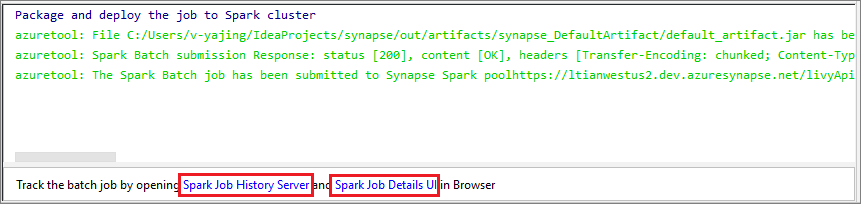
Локальные запуск и отладка приложений Apache Spark
Чтобы настроить локальные запуск и отладку для задания Apache Spark, следуйте приведенным ниже указаниям.
Сценарий 1. Выполнение локального запуска
В диалоговом окне Run/Debug Configurations (Конфигурации выполнения и отладки) щелкните значок плюса (+). Затем выберите вариант Apache Spark on Synapse (Apache Spark в Synapse). Введите сведения в полях Name (Имя) и Main class name (Имя основного класса).

- Переменные среды и расположение файла WinUtils.exe используются только для Windows.
- Переменные среды. Системная переменная среды может быть автоматически обнаружена, если она установлена раньше и не требуется вручную добавлять.
- WinUtils.exe расположение. Расположение WinUtils можно указать, щелкнув значок папки справа.
Затем нажмите кнопку локального выполнения.

После завершения локального выполнения, если скрипт содержит выходные данные, можно проверить выходной файл в папке data>default.
Сценарий 2. Выполнение локальной отладки
Откройте скрипт LogQuery и установите точки останова.
Щелкните значок Local debug (Локальная отладка), чтобы выполнить локальную отладку.

Доступ к рабочей области Synapse и управление ею
В Azure Explorer можно выполнять различные операции в Azure Toolkit для IntelliJ. В строке меню выберите Представление>Окно инструментов>Azure Explorer.
Создание рабочей области
В Azure Explorer перейдите в раздел Apache Spark on Synapse (Apache Spark в Synapse), а затем разверните его.
Щелкните правой кнопкой мыши рабочую область, а затем выберите команду Запуск рабочей области, после чего откроется веб-сайт.
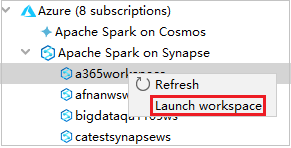

Консоль Spark
Вы можете запустить локальную консоль Spark (Scala) или консоль интерактивного сеанса Spark Livy (Scala).
Локальная консоль Spark (Scala)
Убедитесь в том, что есть необходимый файл WINUTILS.EXE.
В строке меню выберите Run (Запуск)>Edit Configurations... (Изменить конфигурации).
В левой области окна Run/Debug Configurations (Конфигурации запуска и отладки) выберите элементы Apache Spark on Synapse (Apache Spark в Synapse)>[Spark on Synapse] myApp (myApp [Spark в Synapse]).
В главном окне выберите вкладку Locally Run (Локальный запуск).
Укажите следующие значения и нажмите кнопку ОК:
Свойство Значение Переменные среды Проверьте правильность значения HADOOP_HOME. Расположение файла WINUTILS.exe Проверьте правильность пути. 
В проекте перейдите в myApp>src>main>scala>myApp.
В строке меню выберите Tools (Средства)>Spark Console (Консоль Spark)>Run Spark Local Console(Scala) (Запустить локальную консоль Spark (Scala)).
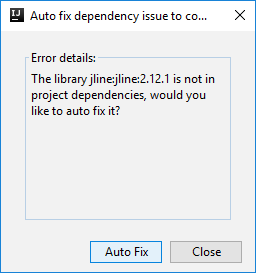
После этого могут появиться два диалоговых окна с запросом на автоматическое исправление зависимостей. Если нужно исправить их, выберите Auto Fix (Автоматическое исправление).

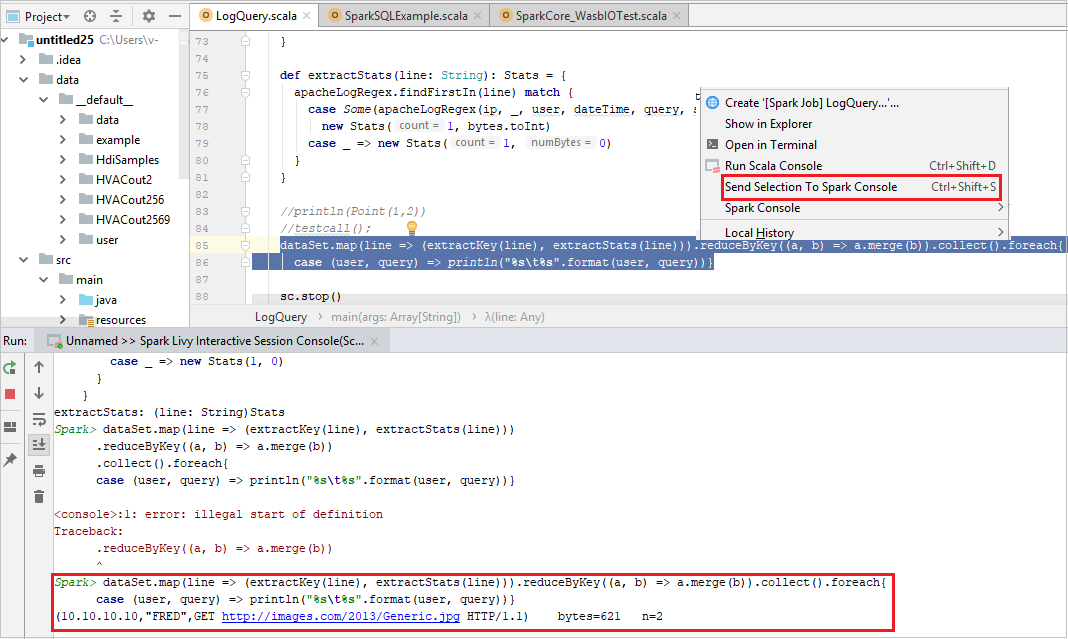
Консоль должна выглядеть примерно так, как показано ниже. В окне консоли введите
sc.appNameи нажмите клавиши CTRL+ВВОД. Отобразится результат. Чтобы закрыть локальную консоль, нажмите красную кнопку.
Консоль интерактивного сеанса Spark Livy (Scala)
Она поддерживается только в IntelliJ 2018.2 и 2018.3.
В строке меню выберите Run (Запуск)>Edit Configurations... (Изменить конфигурации).
В левой области окна Run/Debug Configurations (Конфигурации запуска и отладки) выберите элементы Apache Spark on Synapse (Apache Spark в Synapse)>[Spark on Synapse] myApp (myApp [Spark в Synapse]).
В главном окне выберите вкладку Remotely Run in Cluster (Удаленный запуск в кластере).
Укажите следующие значения и нажмите кнопку ОК:
Свойство Значение Имя главного класса Выберите имя класса main. Пулы Spark Выберите пулы Spark, в которых хотите запустить приложение. 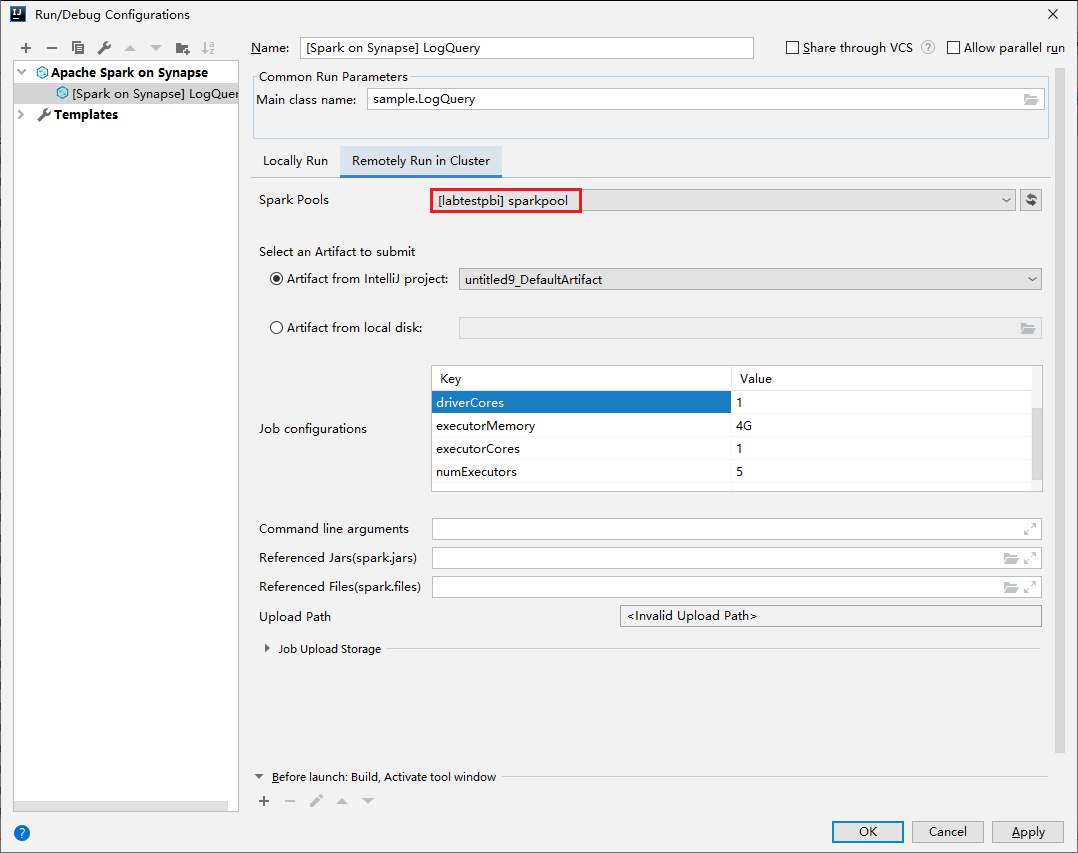
В проекте перейдите в myApp>src>main>scala>myApp.
В строке меню выберите Tools (Средства)>Spark Console (Консоль Spark)>Run Spark Livy Interactive Session Console(Scala) (Запустить консоль интерактивного сеанса Spark Livy (Scala)).
Консоль должна выглядеть примерно так, как показано ниже. В окне консоли введите
sc.appNameи нажмите клавиши CTRL+ВВОД. Отобразится результат. Чтобы закрыть локальную консоль, нажмите красную кнопку.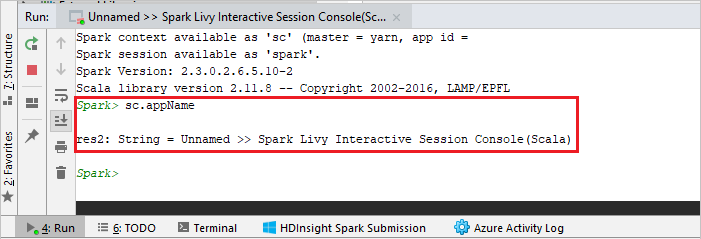
Отправка выбранного фрагмента кода в консоль Spark
Вы можете увидеть результат выполнения скрипта, отправив код в локальную консоль или консоль интерактивного сеанса Livy (Scala). Для этого выделите код в файле Scala, а затем в контекстном меню выберите команду Send Selection To Spark Console (Отправить выделенный фрагмент в консоль Spark). Выделенный код будет отправлен в консоль и выполнен. Результат отобразится в консоли после кода. Консоль проверит наличие ошибок.