Памятка по выделенному пулу SQL (ранее Хранилище данных SQL) в Azure Synapse Analytics
В этой памятке предоставляются полезные советы и рекомендации по созданию решений выделенного пула SQL (ранее — Хранилище данных SQL).
На рисунке ниже показан процесс проектирования хранилища данных с помощью выделенного пула SQL (ранее — Хранилище данных SQL):
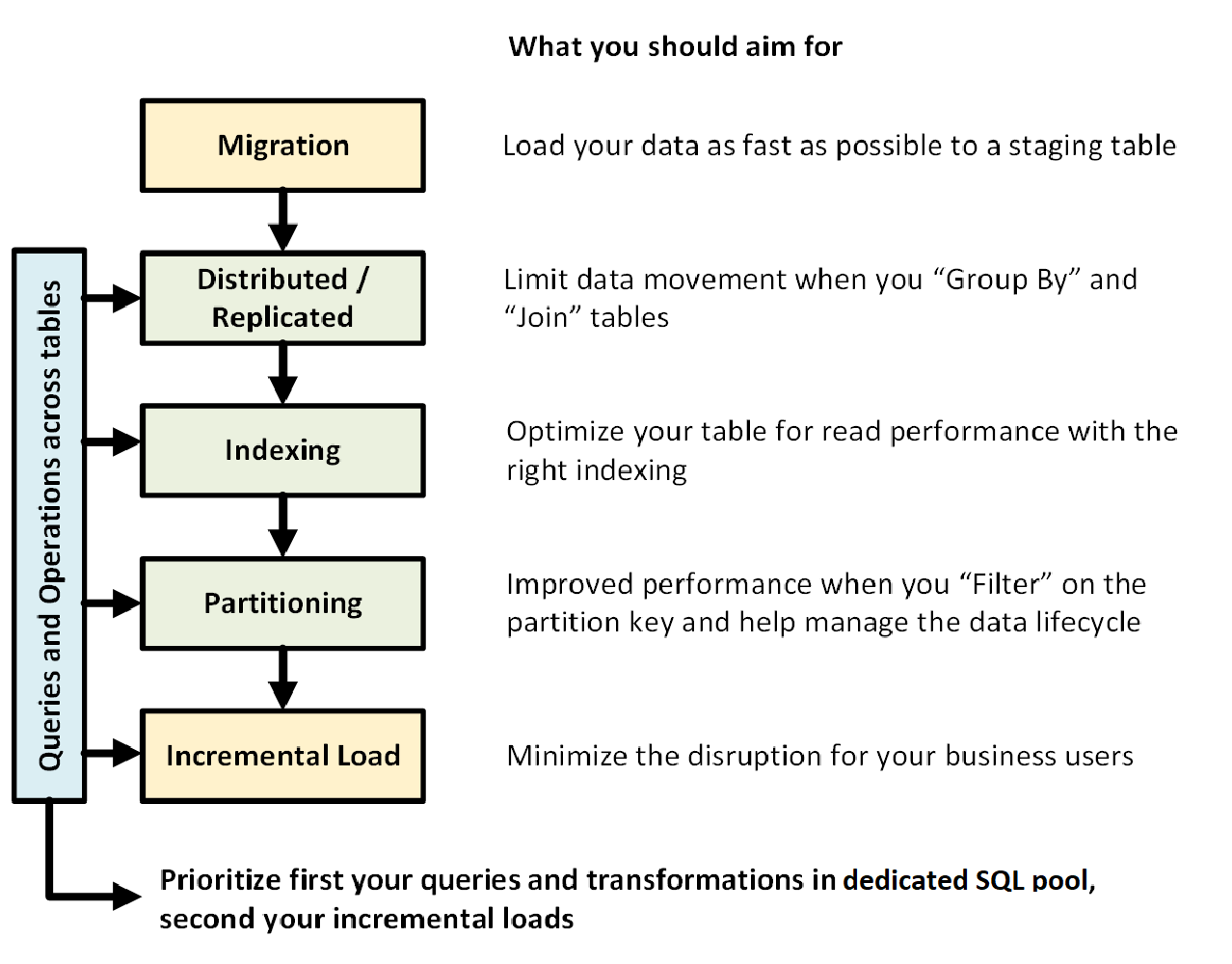
Запросы и операции для нескольких таблиц
Если заранее известно, какие основные операции и запросы будут выполняться в хранилище данных, можно разработать архитектуру хранилища данных с соответствующими приоритетами. Эти запросы и операции могут включать в себя:
- Соединение одной или двух таблиц фактов и таблиц измерений, фильтрацию объединенной таблицы с последующим добавлением результатов в киоск данных.
- Создание больших или маленьких обновлений с учетом продажи.
- Добавление только данных в таблицы.
Зная тип операций заранее, вы можете оптимизировать структуру таблицы.
Перенос данных
Сначала загрузите данные в Azure Data Lake Storage или в хранилище BLOB-объектов Azure. Затем воспользуйтесь инструкцией COPY, чтоб отправить данные в промежуточные таблицы. Используйте следующую конфигурацию:
| Конструирование | Рекомендация |
|---|---|
| Distribution | Циклический перебор |
| Индексация | Куча |
| Секционирование | None |
| Класс ресурсов | largerc или xlargerc |
Подробнее о переносе данных, загрузке данных, а также о процессе извлечения, загрузки и преобразования (ELT).
Распределенные или реплицируемые таблицы
В зависимости от свойств таблицы используйте следующие стратегии:
| Тип | Подходит... | Не подходит |
|---|---|---|
| Реплицированный | * Малые таблицы измерения в схеме типа "звезда" с хранилищем размером менее 2 ГБ после сжатия (приблизительно в 5 раз) | * Выполняется большое количество транзакций записей для таблицы (таких как вставка, операция upsert, удаление, обновление) * Часто меняется подготовка единиц использования хранилища данных (DWU) * Используются только 2–3 столбца, в то время как таблица содержит много столбцов * Индексируется реплицированная таблица |
| Циклический перебор (по умолчанию) | * Временная или промежуточная таблица * Нет очевидного ключа соединения или потенциального столбца |
* Производительность снижается из-за перемещения данных |
| Хэш | * Таблицы фактов * Большие таблицы измерений |
* Ключ распределения нельзя обновить |
Советы
- Начните с циклического перебора, но стремитесь к реализации стратегии распределения хэша, чтобы воспользоваться архитектурой массового параллелизма.
- Убедитесь, что общие ключи хэша имеют одинаковый формат данных.
- Не распределяйте в формате varchar.
- Таблицы измерений с общим ключом хэша к таблице фактов с частыми операциями объединения могут быть распределены по хэшу.
- С помощью sys.dm_pdw_nodes_db_partition_stats анализируйте любую асимметрию в данных.
- С помощью sys.dm_pdw_request_steps анализируйте перемещения данных по запросам, контролируйте время трансляции и операций смешения. Это помогает рассмотреть стратегию распределения.
Подробнее о реплицированных таблицах и распределенных таблицах.
Индексирование таблицы
Индексирование полезно для быстрого чтения таблицы. Существует уникальный набор технологий, которые можно использовать в зависимости от ваших потребностей.
| Тип | Подходит... | Не подходит |
|---|---|---|
| Куча | * Промежуточная или временная таблица * Маленькие таблицы с небольшой областью поиска |
* Любой поиск сканирует всю таблицу |
| Кластеризованный индекс | * Таблицы, содержащие не более 100 млн записей * Большие таблицы (более 100 млн записей) с 1–2 используемыми столбцами |
* Используется реплицированная таблица * Выполняются сложные запросы, включающие несколько операций присоединения и группирования * Создаются обновления в индексированных столбцах: это занимает память |
| Кластеризованный индекс columnstore (CCI) (по умолчанию) | * Большие таблицы (более 100 млн записей) | * Используется реплицированная таблица * Выполняются массовые операции обновления в таблице * Допущено избыточное секционирование таблицы: группы строк не охватывают разные узлы и секции распределения |
Советы
- Возможно, в дополнение к кластеризованному индексу в столбце, активно используемом для фильтрации, необходимо будет добавить некластеризованный индекс.
- Следите за управлением памятью для таблицы с CCI. Нужно, чтобы при загрузке пользователь (или запрос) использовал большой класс ресурсов. Убедитесь, что избежали обрезки и создания множества маленьких групп сжатых строк.
- На уровне Gen2 таблицы CCI таблиц кэшируются локально на вычислительных узлах, чтобы добиться максимальной производительности.
- При использовании CCI недостаточно эффективное сжатие групп может снизить производительность. В этом случае перестройте или реорганизуйте CCI. На сжатую группу строк потребуется не менее 100 000 строк. Идеальный вариант — 1 млн строк в каждой группе.
- С учетом того, как часто добавляется поэтапная нагрузка, а также ее размера при реорганизации и перестройке индексов можно автоматизировать процессы. Всегда можно использовать очистку Spring.
- Учитывайте различные факторы, когда необходимо обрезать группу строк. Каков размер открытых групп строк? Какой объем данных необходимо загрузить в течение нескольких дней?
Подробнее об индексах.
Секционирование
Большие таблицы фактов (более 1 млрд строк) можно разделить на секции. В 99 процентах случаев ключ секции должен быть основан на дате.
Использовать разделение можно для промежуточных таблиц, которым необходимо извлечение, загрузка и преобразование. Это упрощает управление жизненным циклом данных. Старайтесь не допустить избыточного секционирования таблиц фактов или промежуточных таблиц, особенно в кластеризованном индексе columnstore.
Подробнее о секциях.
Поэтапная загрузка
Если данные будут загружаться поэтапно, то сначала необходимо убедиться, что для загрузки данных выделены большие классы ресурсов. Это особенно важно при загрузке данных в таблицы с кластеризованными индексами columnstore. Дополнительные сведения см. в разделе о классах ресурсов.
Для автоматизации конвейеров извлечения, загрузки и преобразования в хранилище данных рекомендуем использовать PolyBase и ADF V2.
Для большого пакета обновлений устаревших данных попробуйте использовать CTAS, чтобы записать в таблицу данные, которые необходимо сохранить, вместо использования операций INSERT, UPDATE и DELETE.
Обеспечение статистики
Важно также обновлять статистику, так как данные могут быть существенно изменены. Просмотрите обновленную статистику, чтобы определить наличие значительных изменений. Обновленная статистика помогает оптимизировать планы запросов. Если ведение статистики занимает слишком много времени, нужно выбирать отдельные столбцы, для которых необходимо создавать статистику.
Кроме того, вы можете определить частоту обновлений. Например, можно ежедневно обновлять столбцы дат, в которые добавляются новые значения. Статистику рекомендуется вести в столбцах, которые являются частью объединения, используются в предложении WHERE или GROUP BY.
Подробнее о статистике.
Класс ресурсов
Чтобы выделить память для выполнения запросов, используются группы ресурсов. Если для повышения скорости запроса или загрузки вам требуется больше памяти, необходимо выделить более высокие классы ресурсов. С другой стороны, использование больших классов ресурсов влияет на параллелизм. Обратите на это внимание, прежде чем перемещать всех своих пользователей в большой класс ресурсов.
Если вы заметили, что запросы занимают слишком много времени, убедитесь, что пользователи не работают в больших классах ресурсов. Большие классы потребляют значительно количество слотов выдачи. Они могут создать дополнительные запросы в очереди.
Наконец, при использовании выделенного пула SQL уровня Gen2 (ранее —Хранилище данных SQL) каждый класс ресурсов получает в 2,5 раза больше памяти, чем на уровне Gen1.
Подробнее о работе с классами ресурсов и параллелизмом.
Сокращение расходов
Одна из основных функций Azure Synapse — возможность управлять вычислительными ресурсами. Вы можете приостанавливать работу выделенного пула SQL (ранее — Хранилище данных SQL), когда он не используется. Счет выставляется только за используемые вычислительные ресурсы. Вы можете масштабировать ресурсы в соответствии со своими требованиями к производительности. Приостановить выполнение можно на портале Azure или при помощи PowerShell. Для масштабирования используйте портал Azure, PowerShell, T-SQL или REST API.
Выполняйте автоматическое масштабирование с помощью службы "Функции Azure" в любое время.

Оптимизация архитектуры для производительности
Рекомендуем рассматривать базу данных SQL и Azure Analysis Services в звездообразной архитектуре. Это решение может обеспечить изоляцию рабочей нагрузки между различными группами пользователей наряду с использованием некоторых расширенных функций безопасности базы данных SQL и Azure Analysis Services. Это также поможет обеспечить неограниченный параллелизм для ваших пользователей.
Дополнительные сведения о стандартных архитектурах, использующих выделенный пул SQL (ранее — Хранилище данных SQL) в Azure Synapse Analytics.
Разверните периферийные зоны в базах данных SQL из выделенного пула SQL (ранее — Хранилище данных SQL) одним щелчком: