SQL и данные NoSQL
Совет
Это содержимое является фрагментом из электронной книги, архитектора облачных собственных приложений .NET для Azure, доступных в .NET Docs или в виде бесплатного скачиваемого PDF-файла, который можно прочитать в автономном режиме.

Реляционные (SQL) и нереляционные (NoSQL) — это два типа систем баз данных, которые обычно реализуются в облачных приложениях. Они создаются по-разному, хранят данные по-разному и обращаются по-разному. В этом разделе мы рассмотрим оба. Далее в этой главе мы рассмотрим новую технологию базы данных с именем NewSQL.
Реляционные базы данных были распространенной технологией на протяжении десятилетий. Они зрелые, проверенные и широко реализованы. Конкурирующие продукты базы данных, инструменты и опыт входящего трафика. Реляционные базы данных предоставляют хранилище связанных таблиц данных. Эти таблицы имеют фиксированную схему, используйте SQL (язык SQL) для управления данными и поддержки гарантий ACID: атомарность, согласованность, изоляция и устойчивость.
Базы данных NoSQL ссылаются на высокопроизводительные нереляционные хранилища данных. Они отличаются своими характеристиками удобства использования, масштабируемости, устойчивости и доступности. Вместо объединения таблиц нормализованных данных NoSQL хранит неструктурированные или частично структурированные данные, часто в парах "ключ-значение" или в документах JSON. Базы данных NoSQL обычно не предоставляют гарантии ACID за пределами одной секции базы данных. Службы с большим объемом, для которых требуется время ответа в секунду, предпочитают хранилища данных NoSQL.
Влияние технологий NoSQL для распределенных облачных систем невозможно переоценить. Распространение новых технологий данных в этом пространстве нарушило решения, которые когда-то использовались исключительно реляционными базами данных.
Базы данных NoSQL включают несколько различных моделей для доступа к данным и управления ими, каждый из которых подходит для конкретных вариантов использования. На рис. 5-9 представлены четыре распространенные модели.
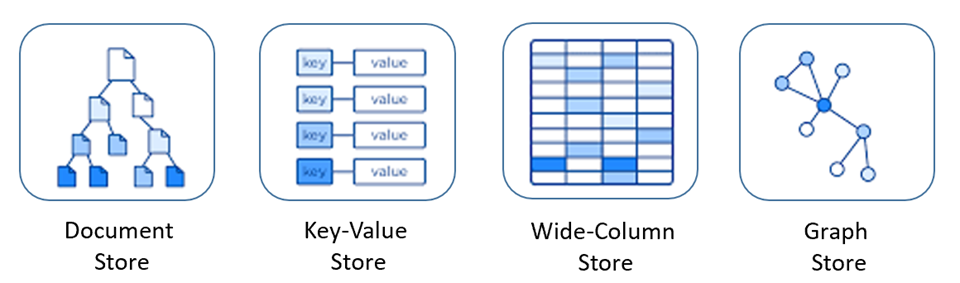
Рис. 5-9. Модели данных для баз данных NoSQL
| Модель | Характеристики |
|---|---|
| Хранилище документов | Данные и метаданные хранятся иерархически в документах на основе JSON внутри базы данных. |
| Хранилище "ключ-значение" | Самая простая из баз данных NoSQL, данные представляют собой коллекцию пар "ключ-значение". |
| Хранилище широких столбцов | Связанные данные хранятся в виде набора вложенных пар "ключ-значение" в одном столбце. |
| Графовое хранилище | Данные хранятся в структуре графа в виде свойств узлов, ребер и данных. |
теорема Брюера
Как способ понять различия между этими типами баз данных, рассмотрим теорему CAP, набор принципов, применяемых к распределенным системам, которые хранят состояние. На рисунке 5-10 показаны три свойства теоремы CAP.
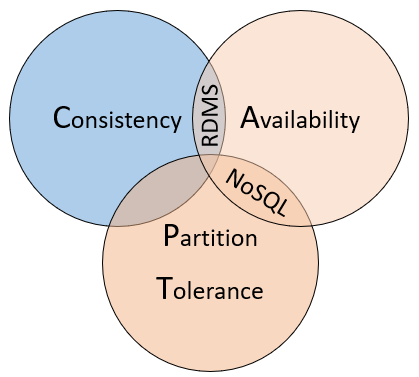
Рис. 5-10. теорема Брюера
Теорема утверждает, что распределенные системы данных обеспечивают компромисс между согласованностью, доступностью и терпимостью к секциям. И что любая база данных может гарантировать только два из трех свойств:
Согласованность. Каждый узел в кластере отвечает с последними данными, даже если система должна блокировать запрос до обновления всех реплик. Если вы запрашиваете "согласованную систему" для элемента, который в настоящее время обновляется, вы будете ожидать, пока все реплики не будут успешно обновлены. Однако вы получите самые актуальные данные. Следует понимать, что термин "согласованность", используемый в контексте теоремы CAP, имеет техническое значение, отличное от способа определения "согласованности" в контексте гарантий ACID.
Доступность Каждый запрос, полученный неисправным узлом в системе, должен привести к ответу. Проще говоря, если вы запрашиваете "доступную систему" для обновляемого элемента, вы получите лучший ответ на то, что служба может предоставить в этот момент. Но обратите внимание, что "доступность", определяемая теоремой CAP, технически отличается от "высокой доступности", так как она обычно известна для распределенных систем.
Отказоустойчивость секций. Гарантирует, что система продолжает работать, даже если реплицированный узел данных завершается сбоем или теряет подключение к другим реплицированным узлам данных.
Теорема CAP объясняет компромиссы, связанные с управлением согласованности и доступностью во время сетевой секции; однако компромиссы в отношении согласованности и производительности также существуют с отсутствием сетевой секции. Теорема CAP часто расширяется в PACELC , чтобы объяснить компромиссы более комплексно.
Примечание.
Даже если выбрать доступность по согласованности, во время секции сети доступность будет страдать. Доступная система CAP является более доступной для некоторых своих клиентов, но это не обязательно "высокодоступная" для всех своих клиентов.
Реляционные базы данных обычно обеспечивают согласованность и доступность, но не отказоустойчивость к секциям. Обычно они подготавливаются к одному серверу и масштабируются по вертикали путем добавления дополнительных ресурсов на компьютер.
Многие реляционные системы баз данных поддерживают встроенные функции репликации, в которых копии базы данных-источника могут быть сделаны в другие экземпляры сервера-получателя. Операции записи выполняются в основной экземпляр и реплицируются на каждый из вторичных файлов. При сбое основной экземпляр может выполнить отработку отказа вторичному экземпляру, чтобы обеспечить высокий уровень доступности. Вторичные файлы также можно использовать для распространения операций чтения. Хотя операции записи всегда выполняются против основной реплики, операции чтения можно направлять в любой из вторичных файлов, чтобы уменьшить системную нагрузку.
Данные также могут быть горизонтально секционированы по нескольким узлам, например с сегментированием. Но сегментирование резко увеличивает операционные издержки путем плюгирования данных во многих фрагментах, которые не могут легко взаимодействовать. Это может быть дорогостоящим и трудоемким для управления. Реляционные функции, включающие соединения таблиц, транзакции и целостность ссылок, требуют резких штрафов производительности в сегментированных развертываниях.
Цели согласованности репликации и точки восстановления можно настроить, настроив ли репликацию синхронно или асинхронно. Если реплики данных должны были потерять сетевое подключение в кластере с высокой согласованности или синхронной реляционной базой данных, вы не сможете записывать данные в базу данных. Система отклонит операцию записи, так как она не может реплицировать изменения в другую реплику данных. Каждая реплика данных должна обновиться до завершения транзакции.
Базы данных NoSQL обычно поддерживают высокий уровень доступности и отказоустойчивость к секциям. Они масштабируются горизонтально, часто на сырьевых серверах. Такой подход обеспечивает огромную доступность как в пределах, так и в разных географических регионах с меньшими затратами. Вы секционируете и реплицируете данные на этих компьютерах или узлах, обеспечивая избыточность и отказоустойчивость. Согласованность обычно настраивается с помощью протоколов консенсуса или механизмов кворума. Они обеспечивают больше контроля при переходе между настройкой синхронной и асинхронной репликации в реляционных системах.
Если реплики данных были потеряны для подключения в кластере базы данных NoSQL с высоким уровнем доступности, вы все равно можете завершить операцию записи в базу данных. Кластер базы данных разрешает операцию записи и обновляет каждую реплику данных по мере его доступности. Базы данных NoSQL, поддерживающие несколько записываемых реплик, могут повысить уровень доступности, избегая необходимости отработки отказа при оптимизации цели времени восстановления.
Современные базы данных NoSQL обычно реализуют возможности секционирования в качестве функции их системного проектирования. Управление секциями часто встроено в базу данных, и маршрутизация достигается с помощью подсказок размещения — часто называемых ключами секций. Гибкие модели данных позволяют базам данных NoSQL снизить нагрузку на управление схемами и повысить доступность при развертывании обновлений приложений, требующих изменения модели данных.
Высокий уровень доступности и масштабируемость часто более важны для бизнеса, чем соединения реляционных таблиц и целостность ссылочных таблиц. Разработчики могут реализовать такие методы и шаблоны, как Sagas, CQRS и асинхронное обмен сообщениями, чтобы обеспечить конечную согласованность.
В настоящее время необходимо учитывать ограничения теоремы CAP. Появился новый тип базы данных, называемый NewSQL, который расширяет реляционный ядро СУБД для поддержки горизонтальной масштабируемости и масштабируемости систем NoSQL.
Рекомендации по реляционным системам и системам NoSQL
В зависимости от конкретных требований к данным микрослужба на основе облака может реализовать реляционное хранилище данных NoSQL или оба.
| Рассмотрите хранилище данных NoSQL, когда: | Рассмотрим реляционную базу данных, когда: |
|---|---|
| У вас есть большие рабочие нагрузки, требующие прогнозируемой задержки в большом масштабе (например, задержка, измеряемая в миллисекундах при выполнении миллионов транзакций в секунду) | Объем рабочей нагрузки обычно соответствует тысячам транзакций в секунду |
| Ваши данные являются динамическими и часто изменяются | Данные очень структурированы и требуют ссылочной целостности |
| Связи могут быть денормализованными моделями данных | Связи выражаются путем объединения таблиц в нормализованных моделях данных |
| Извлечение данных является простым и выраженным без соединения таблиц | Вы работаете с сложными запросами и отчетами |
| Данные обычно реплицируются в географических регионах и требуют более точного контроля над согласованностью, доступностью и производительностью. | Данные обычно централизованны или могут быть реплицированы асинхронно |
| Приложение будет развернуто на сырьевых оборудованиях, таких как с общедоступными облаками | Приложение будет развернуто на большом оборудовании высокого уровня |
В следующих разделах мы рассмотрим варианты, доступные в облаке Azure для хранения и управления облачными данными.
База данных как услуга
Чтобы начать, можно подготовить виртуальную машину Azure и установить базу данных для каждой службы. Хотя у вас будет полный контроль над средой, вы забыли множество встроенных функций облачной платформы. Вы также несете ответственность за управление виртуальной машиной и базой данных для каждой службы. Этот подход может быстро стать трудоемким и дорогостоящим.
Вместо этого облачные приложения предпочитают службы данных, предоставляемые как база данных как услуга (DBaaS). Полностью управляемая поставщиком облачных служб, эти службы обеспечивают встроенную безопасность, масштабируемость и мониторинг. Вместо владения службой вы просто используете ее в качестве резервной службы. Поставщик управляет ресурсом в масштабе и несет ответственность за производительность и обслуживание.
Их можно настроить в зонах доступности облака и регионах, чтобы обеспечить высокий уровень доступности. Все они поддерживают JIT-емкость и модель оплаты по мере использования. Azure предоставляет различные виды параметров управляемой службы данных, каждый из которых имеет определенные преимущества.
Сначала мы рассмотрим реляционные службы DBaaS, доступные в Azure. Вы увидите, что флагманская база данных SQL Server Майкрософт доступна вместе с несколькими вариантами с открытым исходным кодом. Затем мы поговорим о службах данных NoSQL в Azure.
Реляционные базы данных Azure
Для облачных микрослужб, требующих реляционных данных, Azure предлагает четыре управляемых реляционных баз данных в качестве службы (DBaaS), показанные на рис. 5-11.

Рис. 5-11. Управляемые реляционные базы данных, доступные в Azure
На предыдущем рисунке обратите внимание, что каждая из них находится на общей инфраструктуре DBaaS, которая предоставляет ключевые возможности без дополнительных затрат.
Эти функции особенно важны для организаций, которые подготавливают большое количество баз данных, но имеют ограниченные ресурсы для их администрирования. Вы можете подготовить базу данных Azure в минутах, выбрав объем ядер обработки, памяти и базового хранилища. Вы можете масштабировать базу данных на лету и динамически настраивать ресурсы без простоя.
База данных SQL Azure
Группы разработчиков с опытом в Microsoft SQL Server должны рассмотреть База данных SQL Azure. Это полностью управляемая реляционная база данных как услуга (DBaaS) на основе ядро СУБД Microsoft SQL Server. Служба использует множество функций, найденных в локальной версии SQL Server, и запускает последнюю стабильную версию SQL Server ядро СУБД.
Для использования с облачной микрослужбой База данных SQL Azure доступны три варианта развертывания:
Отдельная база данных представляет полностью управляемую База данных SQL, запущенную на сервере База данных SQL Azure в облаке Azure. База данных считается содержащейся , так как она не имеет зависимостей конфигурации на базовом сервере базы данных.
Управляемый экземпляр — это полностью управляемый экземпляр ядро СУБД Microsoft SQL Server, обеспечивающий почти 100% совместимость с локальным SQL Server. Этот параметр поддерживает более крупные базы данных, до 35 ТБ и помещается в azure виртуальная сеть для более эффективной изоляции.
База данных SQL Azure бессерверный — это уровень вычислений для одной базы данных, которая автоматически масштабируется по требованию рабочей нагрузки. Он выставляет счета только за объем вычислительных ресурсов, используемых в секунду. Служба хорошо подходит для рабочих нагрузок с периодическими, непредсказуемыми шаблонами использования, чередуются с периодами бездействия. Уровень бессерверных вычислений также автоматически приостанавливает базы данных в неактивные периоды, чтобы выставлялись только расходы на хранение. Он автоматически возобновляется при возвращении действия.
Помимо традиционного стека Microsoft SQL Server, Azure также включает управляемые версии трех популярных баз данных с открытым исходным кодом.
Базы данных с открытым кодом в Azure
Реляционные базы данных с открытым исходным кодом стали популярным выбором для облачных приложений. Многие предприятия предпочитают их по сравнению с продуктами коммерческой базы данных, особенно для экономии затрат. Многие команды разработчиков наслаждаются своей гибкостью, развитием сообщества и экосистемой инструментов и расширений. Базы данных с открытым кодом можно развертывать в нескольких облачных поставщиках, что помогает свести к минимуму озабоченность по поводу "блокировки поставщика".
Разработчики могут легко размещать любую базу данных с открытым исходным кодом на виртуальной машине Azure. При обеспечении полного контроля этот подход помещает вас в перехватчик для управления, мониторинга и обслуживания базы данных и виртуальной машины.
Однако Корпорация Майкрософт продолжает свою приверженность поддержанию "открытой платформы" Azure, предлагая несколько популярных баз данных с открытым исходным кодом в качестве полностью управляемых служб DBaaS.
База данных Azure для MySQL
MySQL — это реляционная база данных с открытым исходным кодом и основа для приложений, созданных на основе стека программного обеспечения LAMP. Широко выбран для чтения тяжелых рабочих нагрузок, он используется многими крупными организациями, включая Facebook, Twitter и YouTube. Выпуск сообщества доступен бесплатно, в то время как для корпоративного выпуска требуется покупка лицензии. Первоначально созданный в 1995 году продукт был приобретен Sun Microsystems в 2008 году. Oracle приобрел Sun и MySQL в 2010 году.
База данных Azure для MySQL — это управляемая служба реляционной базы данных на основе ядра сервера MySQL с открытым исходным кодом. В нем используется выпуск Сообщества MySQL. Сервер Azure MySQL — это административная точка для службы. Это тот же механизм сервера MySQL, используемый для локальных развертываний. Модуль может создать одну базу данных на сервер или несколько баз данных на сервере, которые совместно используют ресурсы. Вы можете продолжать управлять данными с помощью одних и того же средства с открытым исходным кодом, не изучая новые навыки или управляя виртуальными машинами.
База данных Azure для MariaDB
MariaDB Server — это другой популярный сервер базы данных с открытым кодом. Он был создан в качестве вилки MySQL, когда Oracle приобрел Sun Microsystems, который владел MySQL. Цель заключается в том, чтобы MariaDB оставался открытым исходным кодом. Так как MariaDB является вилкой MySQL, определения данных и таблиц совместимы, а клиентские протоколы, структуры и API, тесно связаны.
MariaDB имеет сильное сообщество и используется многими крупными предприятиями. Хотя Oracle продолжает поддерживать, улучшать и поддерживать MySQL, фонд MariaDB управляет MariaDB, позволяя публичный вклад продукту и документации.
База данных Azure для MariaDB — это полностью управляемая реляционная база данных как услуга в облаке Azure. Служба основана на подсистеме сервера сообщества MariaDB. Он может обрабатывать критически важные рабочие нагрузки с прогнозируемой производительностью и динамической масштабируемостью.
База данных Azure для PostgreSQL
PostgreSQL — это реляционная база данных с открытым исходным кодом с более чем 30 лет активной разработки. PostgreSQL имеет сильную репутацию надежности и целостности данных. Она имеет широкие возможности, совместимые с SQL, и считаются более производительными, чем MySQL, особенно для рабочих нагрузок с сложными запросами и интенсивными записью. Многие крупные предприятия, включая Apple, Red Hat и Fujitsu, создали продукты с помощью PostgreSQL.
База данных Azure для PostgreSQL — это полностью управляемая служба реляционных баз данных на основе ядра СУБД Postgres с открытым исходным кодом. Служба поддерживает множество платформ разработки, включая C++, Java, Python, Node, C#и PHP. Базы данных PostgreSQL можно перенести в него с помощью средства интерфейса командной строки или Azure Data Migration Service.
База данных Azure для PostgreSQL доступно с двумя вариантами развертывания:
Вариант развертывания с одним сервером — это центральная административная точка для нескольких баз данных, в которых можно развернуть множество баз данных. Цены структурированы на сервере на основе ядер и хранилища.
Параметр Гипермасштабирования (Citus) используется технологией Citus Data. Это обеспечивает высокую производительность путем горизонтального масштабирования одной базы данных на сотнях узлов для обеспечения быстрой производительности и масштабирования. Этот параметр позволяет подсистеме помещать больше данных в память, параллелизировать запросы на сотни узлов и быстрее индексировать данные.
Данные NoSQL в Azure
Cosmos DB — это полностью управляемая, глобально распределенная служба базы данных NoSQL в облаке Azure. Он был принят многими крупными компаниями по всему миру, включая Coca-Cola, Skype, ExxonMobil и Liberty Mutual.
Если службам требуется быстрый ответ от любого места в мире, высокий уровень доступности или эластичная масштабируемость, Cosmos DB — отличный выбор. На рисунке 5-12 показана Cosmos DB.
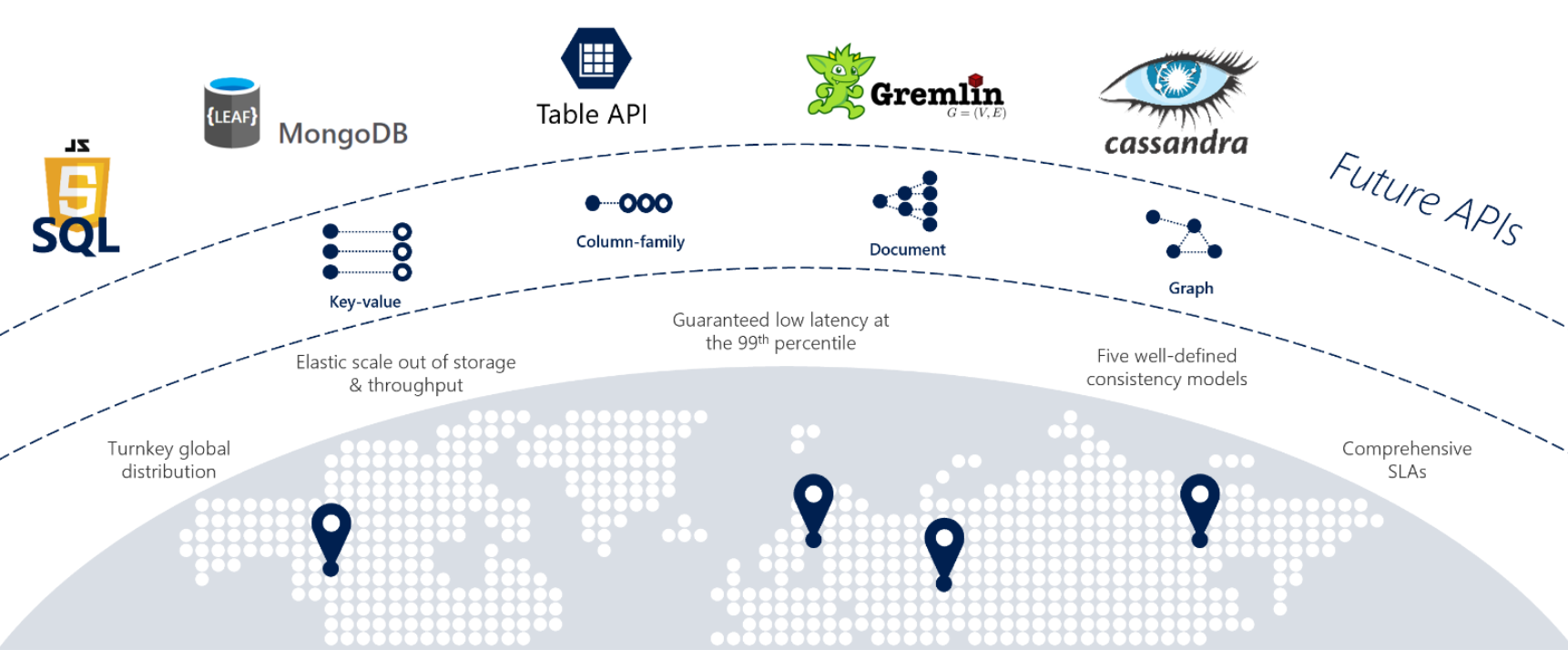
Рис. 5-12. Обзор Azure Cosmos DB
На предыдущем рисунке представлено множество встроенных возможностей в облаке, доступных в Cosmos DB. В этом разделе мы рассмотрим их более подробно.
Глобальная поддержка
Облачные приложения часто имеют глобальную аудиторию и требуют глобального масштаба.
Базы данных Cosmos можно распределять по регионам или по всему миру, размещать данные близко к пользователям, улучшать время отклика и уменьшать задержку. Вы можете добавлять или удалять базу данных из региона без приостановки или повторного развертывания служб. В фоновом режиме Cosmos DB прозрачно реплицирует данные в каждый из настроенных регионов.
Cosmos DB поддерживает активное и активное кластеризация на глобальном уровне, что позволяет настроить любой из регионов базы данных для поддержки операций записи и чтения.
Протокол записи в нескольких регионах является важной функцией в Cosmos DB, которая обеспечивает следующие функции:
неограниченная эластичная масштабируемость операций записи и чтения;
доступность для чтения и записи на 99,999 % по всему миру;
гарантированные операции чтения или записи, обслуживаемые менее чем за 10 миллисекунд в 99-м процентиле.
При использовании API-интерфейсов Cosmos DB с несколькими хомингами микрослужба автоматически знает ближайший регион Azure и отправляет запросы в него. Ближайший регион определяется Cosmos DB без каких-либо изменений конфигурации. Если регион станет недоступным, функция Multi-Homing автоматически направляет запросы к следующему ближайшему доступному региону.
Поддержка нескольких моделей
При переплатформировке монолитных приложений в облачную архитектуру команды разработчиков иногда должны перенести хранилища данных NoSQL с открытым кодом. Cosmos DB поможет вам сохранить инвестиции в эти хранилища данных NoSQL с помощью платформы данных с несколькими моделями . В следующей таблице показаны поддерживаемые API совместимости NoSQL.
| Provider | Description |
|---|---|
| API NoSQL | API для NoSQL сохраняет данные в формате документа |
| Mongo DB API | Поддерживает API-интерфейсы Mongo и документы JSON |
| API Gremlin | Поддерживает API Gremlin с узлами на основе графов и представлениями пограничных данных |
| API Cassandra | Поддерживает API Casandra для представления данных в широком столбце |
| API таблиц | Поддержка хранилища таблиц Azure с усовершенствованиями уровня "Премиум" |
| PostgreSQL API | Управляемая служба для запуска PostgreSQL в любом масштабе |
Команды разработчиков могут перенести существующие базы данных Mongo, Gremlin или Cassandra в Cosmos DB с минимальными изменениями данных или кода. Для новых приложений команды разработчиков могут выбирать варианты с открытым исходным кодом или встроенную модель API SQL.
Внутри Cosmos хранит данные в простом формате структуры, состоящем из примитивных типов данных. Для каждого запроса ядро СУБД преобразует примитивные данные в выбранное представление модели.
В предыдущей таблице обратите внимание на параметр API таблиц. Этот API является эволюцией хранилища таблиц Azure. Оба используют одну и ту же базовую модель таблицы, но API таблиц Cosmos DB добавляет улучшения класса "Премиум", недоступные в API служба хранилища Azure. В следующей таблице сравниваются функции.
| Функция | Хранилище таблиц Azure | Azure Cosmos DB |
|---|---|---|
| Задержка | Быстро | Задержка в миллисекундах с одной цифрой для операций чтения и записи в любом месте мира |
| Пропускная способность | Ограничение в 20 000 операций на таблицу | Неограниченные операции на таблицу |
| Глобальное распределение | Один регион с необязательным дополнительным регионом чтения | Распределение по ключу для всех регионов с автоматической отработкой отказа |
| Индексирование | Доступно только для свойств ключа секции и строки | Автоматическое индексирование всех свойств |
| Цены | Оптимизировано для холодных рабочих нагрузок (низкая пропускная способность: соотношение хранилища) | Оптимизировано для горячих рабочих нагрузок (высокая пропускная способность: коэффициент хранения) |
Микрослужбы, использующие хранилище таблиц Azure, могут легко перенестися в API таблиц Cosmos DB. Изменения кода не требуются.
Настраиваемая согласованность
Ранее в разделе "Реляционная и NoSQL " мы обсудили тему согласованности данных. Согласованность данных относится к целостности данных. Облачные службы с распределенными данными зависят от репликации и должны обеспечить фундаментальный компромисс между согласованность чтения, доступностью и задержкой.
Большинство распределенных баз данных позволяют разработчикам выбирать между двумя моделями согласованности: строгой согласованности и конечной согласованности. Надежная согласованность — это золотой стандарт программирования данных. Он гарантирует, что запрос всегда возвращает самые текущие данные, даже если система должна повлечь задержку, ожидающая репликации обновления во всех копиях базы данных. Хотя база данных, настроенная для конечной согласованности , немедленно возвращает данные, даже если эти данные не являются самой текущей копией. Последний вариант позволяет повысить доступность, увеличить масштаб и повысить производительность.
Azure Cosmos DB предлагает пять четко определенных моделей согласованности, показанных на рис. 5-13.

Рис. 5-13. Уровни согласованности Cosmos DB
Эти параметры позволяют выполнять точные выборы и детализированные компромиссы по согласованности, доступности и производительности данных. Уровни представлены в следующей таблице.
| Уровень согласованности | Description |
|---|---|
| В конечном счете | Нет гарантии заказа для операций чтения. Реплики в конечном итоге конвергентируются. |
| Префикс константы | Операции чтения по-прежнему возможны, но данные возвращаются в порядке записи. |
| Сеанс | Гарантирует, что вы можете считывать любые данные, записанные во время текущего сеанса. Это уровень согласованности по умолчанию. |
| Ограниченное устаревание | Считывает конечную запись по интервалу, который вы указали. |
| Строгие | Операции чтения гарантированно возвращают последнюю зафиксированную версию элемента. Клиент никогда не видит незафиксированного или частичного чтения. |
В статье "За 9-мячом: уровни согласованности Cosmos DB объяснили", Microsoft Program Manager Джереми Ликнесс предоставляет отличное объяснение пяти моделей.
Секционирование
Azure Cosmos DB включает автоматическое секционирование для масштабирования базы данных в соответствии с потребностями в производительности облачных служб.
Вы управляете данными Cosmos DB путем создания баз данных, контейнеров и элементов.
Контейнеры живут в базе данных Cosmos DB и представляют группирование элементов, не зависящих от схемы. Элементы — это данные, добавляемые в контейнер. Они представлены в виде документов, строк, узлов или ребер. Все элементы, добавленные в контейнер, автоматически индексируются.
Для секционирования контейнера элементы делятся на отдельные подмножества, называемые логическими секциями. Логические секции заполняются на основе значения ключа секции, связанного с каждым элементом в контейнере. На рисунке 5–14 показаны два контейнера с логическим разделом на основе значения ключа секции.
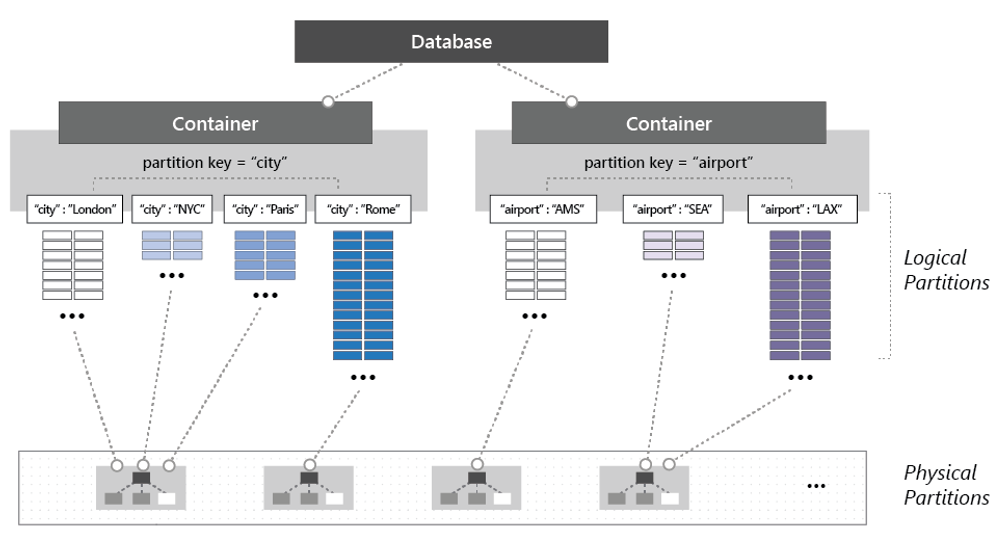
Рис. 5-14. Механика секционирования Cosmos DB
Обратите внимание на предыдущий рисунок, как каждый элемент содержит ключ секции "город" или "аэропорт". Ключ определяет логическую секцию элемента. Элементы с кодом города назначаются контейнеру слева, а элементы с кодом аэропорта — контейнеру справа. Объединение значения ключа секции со значением идентификатора создает индекс элемента, который однозначно идентифицирует элемент.
Внутри службы Cosmos DB автоматически управляет размещением логических секций на физических секциях для удовлетворения потребностей в масштабируемости и производительности контейнера. По мере увеличения пропускной способности приложения и требований к хранилищу Azure Cosmos DB распространяет логические секции по большему количеству серверов. Операции распространения управляются Cosmos DB и вызываются без прерывания или простоя.
Базы данных NewSQL
NewSQL — это новая технология базы данных, которая объединяет распределенную масштабируемость NoSQL с гарантиями ACID реляционной базы данных. Базы данных NewSQL важны для бизнес-систем, которые должны обрабатывать большие объемы данных в распределенных средах с полной поддержкой транзакций и соответствием ACID. Хотя база данных NoSQL может обеспечить массовую масштабируемость, она не гарантирует согласованность данных. Периодические проблемы с несогласованными данными могут поставить нагрузку на команду разработчиков. Разработчики должны создавать средства защиты в коде микрослужб для управления проблемами, вызванными несогласованными данными.
Cloud Native Computing Foundation (CNCF) включает несколько проектов базы данных NewSQL.
| Project | Характеристики |
|---|---|
| База данных таракана | Реляционная база данных, совместимая с ACID, масштабируемая глобально. Добавление нового узла в кластер и CockroachDB выполняет балансировку данных между экземплярами и географическими регионами. Он создает, управляет и распределяет реплики для обеспечения надежности. Это открытый код и свободно доступно. |
| TiDB | База данных с открытым кодом, поддерживающая рабочие нагрузки гибридной транзакционной и аналитической обработки (HTAP). Она совместима с MySQL и имеет горизонтальную масштабируемость, надежную согласованность и высокий уровень доступности. TiDB действует как сервер MySQL. Вы можете продолжать использовать существующие клиентские библиотеки MySQL, не требуя обширных изменений кода в приложении. |
| YugabyteDB | Открытый код, высокопроизводительная распределенная база данных SQL. Она поддерживает низкую задержку запросов, устойчивость к сбоям и глобальное распределение данных. YugabyteDB совместим с PostgreSQL и обрабатывает масштабируемые RDBMS и рабочие нагрузки OLTP в Интернете. Продукт также поддерживает NoSQL и совместим с Cassandra. |
| Vitess | Vitess — это решение базы данных для развертывания, масштабирования и управления большими кластерами экземпляров MySQL. Он может выполняться в архитектуре общедоступного или частного облака. Vitess объединяет и расширяет множество важных функций MySQL и функций вертикальной и горизонтальной сегментирования. Создано YouTube, Vitess обслуживает весь трафик базы данных YouTube с 2011 года. |
Проекты с открытым исходным кодом на предыдущем рисунке доступны из Cloud Native Computing Foundation. Три предложения являются полными продуктами базы данных, которые включают поддержку .NET. Другая, Vitess, — это система кластеризации баз данных, которая горизонтально масштабирует большие кластеры экземпляров MySQL.
Ключевой целью разработки баз данных NewSQL является работа в Kubernetes с учетом устойчивости и масштабируемости платформы.
Базы данных NewSQL предназначены для процветания в эфемерных облачных средах, где базовые виртуальные машины можно перезапустить или перепланировать на момент уведомления. Базы данных предназначены для выживания сбоев узлов без потери данных и простоя. Например, CockroachDB может пережить потерю компьютера, сохраняя три согласованных реплики любых данных на узлах в кластере.
Kubernetes использует конструкцию Служб, чтобы разрешить клиенту обращаться к группе идентичных баз данных NewSQL из одной записи DNS. Развязывая экземпляры базы данных от адреса службы, с которой она связана, можно масштабировать, не нарушая существующие экземпляры приложения. Отправка запроса в любую службу в определенное время всегда будет давать один и тот же результат.
В этом сценарии все экземпляры базы данных равны. Нет первичных или вторичных связей. Такие методы, как репликация консенсуса, найденная в CockroachDB, позволяют любому узлу базы данных обрабатывать любой запрос. Если узел, получающий запрос с балансировкой нагрузки, содержит необходимые данные локально, он немедленно отвечает. Если нет, узел становится шлюзом и перенаправляет запрос на соответствующие узлы, чтобы получить правильный ответ. С точки зрения клиента каждый узел базы данных совпадает: они отображаются как одна логическая база данных с гарантиями согласованности системы с одним компьютером, несмотря на наличие десятков или даже сотен узлов, работающих за кулисами.
Подробный обзор механики баз данных NewSQL см. в статье DASH: Четыре свойства собственных баз данных Kubernetes.
Миграция данных в облако
Одной из самых длительных задач является перенос данных из одной платформы данных в другую. Служба Azure Data Migration Service может помочь ускорить такие усилия. Он может перенести данные из нескольких внешних источников базы данных на платформы данных Azure с минимальным временем простоя. Целевые платформы включают следующие службы:
- База данных SQL Azure
- База данных Azure для MySQL
- База данных Azure для MariaDB
- База данных Azure для PostgreSQL
- Azure Cosmos DB
Служба предоставляет рекомендации, которые помогут вам выполнить миграцию, как небольшие, так и большие.