Рекомендации по объединению данных
При настройке правил объединения данных в профиль клиента примите во внимание следующие рекомендации:
Баланс времени на объединение и полное соответствие. Попытка охватить все возможные совпадения приводит к появлению множества правил, и унификация занимает много времени.
Добавляйте правила постепенно и отслеживайте результаты. Удалить правила, которые не улучшают результат матча.
Удалите дубликаты каждой таблицы , чтобы каждый клиент был представлен в одной строке.
Используйте нормализацию для стандартизации вариаций в способах ввода данных, например, Street vs. St vs. St. vs. st.
Используйте нечеткое соответствие стратегически для исправления опечаток и ошибок таких как bob@contoso.com и bob@contoso.cm. Нечеткие соответствия требуют больше времени для выполнения, чем точные соответствия. Всегда проверяйте, оправдывает ли дополнительное время, потраченное на нечеткое соответствие, дополнительную частоту совпадений.
Сузьте область совпадений с помощью точного соответствия. Убедитесь, что каждое правило с нечеткими условиями имеет хотя бы одно условие точного соответствия.
Не сопоставляйте столбцы, содержащие часто повторяющиеся данные. Убедитесь, что столбцы с нечетким соответствием не содержат часто повторяющихся значений, например, значение формы по умолчанию «Имя».
Унификация производительности
Для выполнения каждого правила требуется время. Такие шаблоны, как сравнение каждой таблицы с каждой другой таблицей или попытка охватить все возможные совпадения записей, могут привести к длительному времени обработки унификации. Он также возвращает очень мало совпадений, если вообще возвращает, по сравнению с планом, сравнивающим каждую таблицу с базовой таблицей.
Лучший подход — начать с базового набора правил, которые, как вы знаете, необходимы, например, сравнивая каждую таблицу с вашей основной таблицей. Ваша основная таблица должна содержать наиболее полные и точные данные. Эту таблицу следует расположить наверху в объединении правил сопоставления шаг.
Постепенно добавляйте несколько правил и наблюдайте, сколько времени потребуется для вступления изменений в силу и улучшатся ли результаты. Перейдите в раздел Настройки>Система>Состояние и выберите Сопоставление , чтобы увидеть, сколько времени заняли дедупликация и сопоставление для каждого запуска объединения.
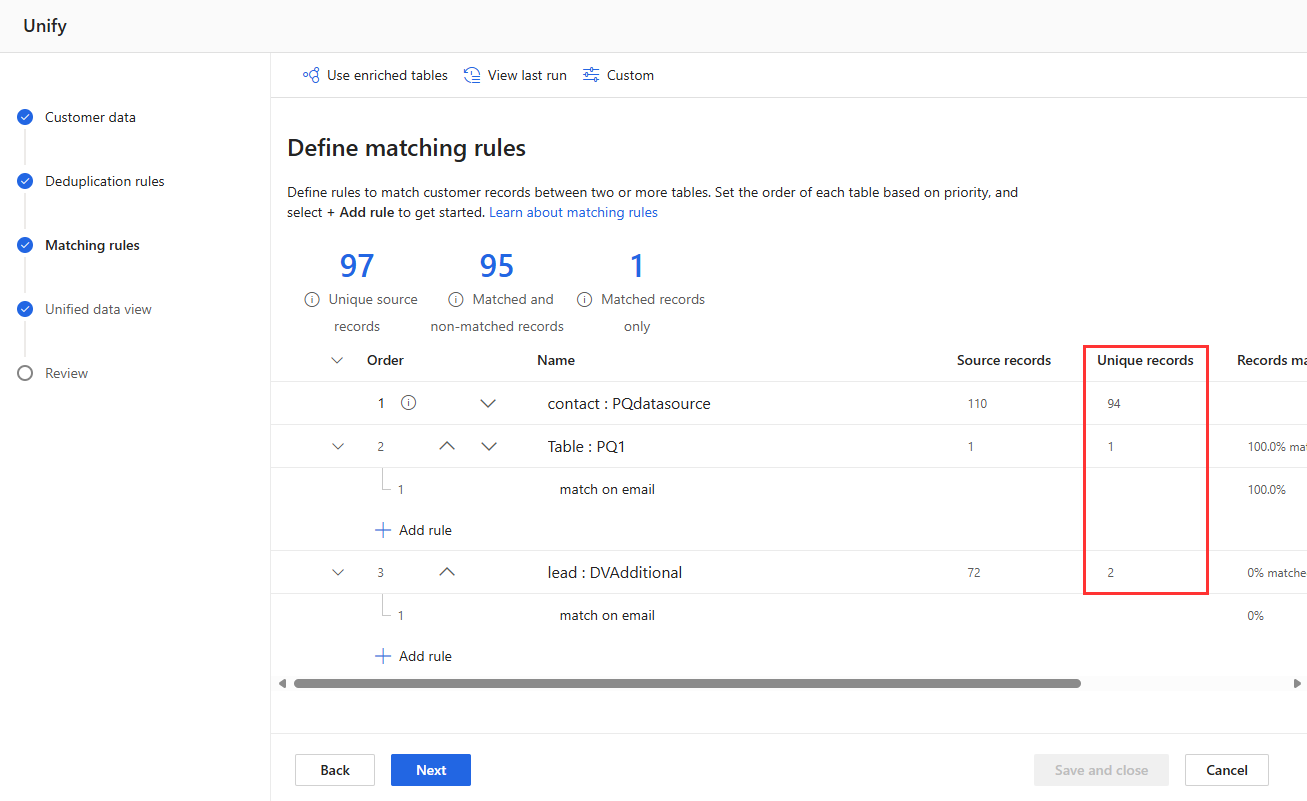
Просмотрите статистику правил на страницах Правила дедупликации и Правила соответствия , чтобы увидеть, изменилось ли количество Уникальных записей . Если новое правило соответствует некоторым записям, а уникальное количество записей не меняется, то предыдущее правило идентифицирует эти соответствия.
Дедупликация
Используйте правила дедупликации для удаления дублирующихся записей о клиентах в таблице, чтобы каждому клиенту была представлена отдельная строка в каждой таблице. Хорошее правило идентифицирует уникального клиента.
В этом простом примере записи 1, 2 и 3 имеют общий адрес электронной почты или номер телефона и представляют одного и того же человека.
| Идентификатор | Полное имя | Номер телефона | Электронное письмо |
|---|---|---|---|
| 1 | Пользователь 1 | (425) 555-1111 | AAA@A.com |
| 2 | Пользователь 1 | (425) 555-1111 | BBB@B.com |
| 3 | Пользователь 1 | (425) 555-2222 | BBB@B.com |
| 4 | Пользователь 2 | (206) 555-9999 | Person2@contoso.com |
Мы не хотим сопоставлять только имя, так как это будет соответствовать разным людям с одним и тем же именем.
Создайте правило 1, используя имя и телефон, которое соответствует записям 1 и 2.
Создайте правило 2, используя имя и адрес электронной почты, которое соответствует записям 2 и 3.
Комбинация правила 1 и правила 2 создает одну группу совпадений, поскольку они используют общую запись 2.
Вы определяете количество правил и условий, которые однозначно идентифицируют ваших клиентов. Точные правила зависят от имеющихся у вас данных для сопоставления, качества ваших данных и того, насколько исчерпывающим должен быть процесс дедупликации.
Победитель и альтернативные записи
После запуска правил и выявления дубликатов записей процесс дедупликации выбирает «строку-победитель». Строки, не являющиеся победителями, называются «альтернативными строками». Альтернативные строки используются в унификации правил сопоставления шаг для сопоставления записей из других таблиц со строкой-победителем. Строки сопоставляются с данными в альтернативных строках в дополнение к строке-победителю.
После добавления правила в таблицу вы можете настроить, какую строку выбрать в качестве победителя, с помощью параметров слияния. Параметры объединения устанавливаются для каждой таблицы. Независимо от выбранной политики слияния, если по строке-победителю есть два одинаковых значения, то в качестве решающего используется первая строка в порядке данных.
Нормализация
Используйте нормализацию для стандартизации данных и лучшего соответствия. Нормализация хорошо работает на больших наборах данных.
Нормализованные данные используются только в целях сравнения, чтобы более эффективно сопоставлять записи клиентов. Это не меняет данные в окончательном выводе единого профиля клиента.
| Нормализация | Примеры |
|---|---|
| Цифры | Преобразует множество символов Unicode, представляющих числа, в простые числа. Примеры: ❽ и Ⅷ оба нормализованы до числа 8. Примечание. Символы должны быть закодированы в формате точек Unicode. |
| Тикеры | Удаляет символы и специальные знаки. Примеры: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| Текст в нижний регистр | Преобразует символы верхнего регистра в нижний регистр. Пример: «ЭТО ПРИМЕР» преобразуется в «это пример» |
| Тип — телефон | Преобразует телефоны различных форматов в цифры и учитывает различия в представлении кодов стран и добавочных номеров. Пример: +01 425.555.1212 = 1 (425) 555-1212 |
| Тип — имя | Преобразует более 500 распространенных вариантов имен и названий. Примеры: «debby» —> «deborah», «профессор» и «проф» -> «Проф.» |
| Тип — адрес | Преобразует общие части адресов Примеры: «улица» -> «ул.» и «северо-запад» -> "СЗ" |
| Тип — Организация | Удаляет около 50 «шумящих слов» из названий компаний, таких как «co», «corp», «corporation» и «ltd». |
| Unicode в ASCII | Преобразует символы Unicode в эквивалентные буквы ASCII Пример: символы «à», «á», «â», «À», «Á», «Â», «Ã», «Ä», «Ⓐ», «A» преобразуются в «a». |
| Пробел | Удаляет все пробельные символы |
| Сопоставление псевдонима | Позволяет отправить пользовательский список пар строк, который затем можно использовать для обозначения строк, которые всегда следует считать точным совпадением. Используйте сопоставление псевдонимов, если у вас есть конкретные примеры данных, которые, по вашему мнению, должны совпадать, но не сопоставляются с использованием одного из других шаблонов нормализации. Пример: Скотт и Скутер или MSFT и Microsoft. |
| Пользовательский пропуск | Позволяет отправить пользовательский список строк, который затем можно использовать для обозначения строк, которые никогда не следует считать совпадением. Пользовательский обход полезен, когда у вас есть данные с общими значениями, которые следует игнорировать, например, фиктивный номер телефона или фиктивный адрес электронной почты. Пример: Никогда не сопоставляйте телефон 555-1212, или test@contoso.com |
Точное совпадение
Используйте точность, чтобы определить, насколько близки должны быть две строки, чтобы их можно было считать совпадением. Настройка точности по умолчанию требует точного совпадения. Любое другое значение включает нечеткое соответствие для этого условия.
Точность можно установить на низкую (совпадение 30%), среднюю (совпадение 60%) и высокую (совпадение 80%). Или вы можете настроить и установить точность с шагом в 1%.
Точные условия соответствия
Сначала выполняются условия точного соответствия, чтобы получить меньший набор значений для нечетких совпадений. Чтобы быть эффективными, условия точного совпадения должны иметь разумную степень уникальности. Например, если все ваши клиенты проживают в одной стране/регионе, то точное совпадение по стране/региону не поможет сузить область поиска.
Такие столбцы, как полное имя, адрес электронной почты, телефон или адрес, обладают хорошей уникальностью и прекрасно подходят для использования в качестве точного соответствия.
Убедитесь, что столбец, который вы используете для условия точного соответствия, не содержит часто повторяющихся значений, например, значения по умолчанию «Имя», зафиксированного в форме. Аналитика клиентов позволяет профилировать столбцы данных, чтобы получить представление о наиболее часто повторяющихся значениях. Вы можете включить профилирование данных в подключениях Azure Data Lake (с использованием Common Data Model или формата Delta) и Synapse. Профиль данных запускается при следующем обновлении источник данных. Для получения более подробной информации перейдите по ссылке Профилирование данных.
Нечеткое соответствие
Используйте нечеткое соответствие для сопоставления строк, которые близки, но не являются точными из-за опечаток или других небольших отклонений. Используйте нечеткое соответствие стратегически, поскольку оно медленнее точного соответствия. Убедитесь, что в любом правиле, имеющем нечеткие условия, есть хотя бы одно точное совпадение.
Нечеткое соответствие не предназначено для охвата таких вариаций имен, как Сьюзи и Сюзанна. Эти вариации лучше всего охватить с помощью шаблона нормализации Тип: Имя или пользовательского Соответствия псевдонима , где клиенты могут ввести свой список вариаций имен, которые они хотят рассматривать как совпадения.
В правило можно добавить условия, например сопоставление имени и телефона. Условия внутри данного правила являются условиями «И». Для того чтобы строки совпадали, должны совпадать все условия. Отдельные правила — это условия «ИЛИ». Если правило 1 не соответствует строкам, то строки сравниваются с правилом 2.
Заметка
Только столбцы строкового типа данных могут использовать нечеткое соответствие. Для столбцов с другими типами данных, такими как integer, double или datetime, поле точности доступно только для чтения и установлено на точное совпадение.
Расчеты нечеткого соответствия
Нечеткие совпадения определяются путем вычисления оценки расстояния редактирования между двумя строками. Если результат соответствует или превышает порог точности, строки считаются совпавшими.
Расстояние редактирования — это количество правок, необходимых для превращения одной строки в другую путем добавления, удаления или изменения символа.
Например, строки «Jacqueline» и «Jaclyne» имеют расстояние редактирования пять, если мы удалим символы q, u, e, i и e и вставим символ y.
Для расчета оценки расстояния редактирования используйте следующую формулу: (Базовая длина строки – Расстояние редактирования) / Базовая длина строки.
| Базовая строка | Строка сравнения | Балл |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10 = 0,6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0,857 |
| franklin | frank | (8-3) / 8 = 0,625 |