Руководство по Lakehouse. Подготовка и преобразование данных в Lakehouse
В этом руководстве вы используете записные книжки с средой выполнения Spark для преобразования и подготовки необработанных данных в lakehouse.
Необходимые компоненты
Если у вас нет озера, содержащего данные, необходимо:
Подготовка данных
На предыдущих шагах руководства мы получили необработанные данные из источника в раздел "Файлы " в lakehouse. Теперь вы можете преобразовать эти данные и подготовить его к созданию таблиц Delta.
Скачайте записные книжки из папки Source Code в Lakehouse.
В переключателе, расположенном в нижней левой части экрана, выберите Инжиниринг данных.

Выберите "Импортировать записную книжку " из раздела "Создать " в верхней части целевой страницы.
Выберите " Отправить" в области состояния импорта, которая откроется справа от экрана.
Выберите все записные книжки, скачанные на первом шаге этого раздела.

Выберите Открыть. Уведомление, указывающее состояние импорта, отображается в правом верхнем углу окна браузера.
После успешного импорта перейдите к представлению элементов рабочей области и просмотрите только что импортированные записные книжки. Выберите wwilakehouse lakehouse , чтобы открыть его.

После открытия wwilakehouse lakehouse выберите "Открыть записную книжку>" в верхнем меню навигации.
В списке существующих записных книжек выберите 01 — создать записную книжку Delta Tables и нажмите кнопку "Открыть".
В открытой записной книжке в lakehouse Обозреватель вы увидите, что записная книжка уже связана с открытым lakehouse.
Примечание.
Fabric предоставляет возможность для записи оптимизированных файлов Delta Lake с помощью V-order . V-order часто улучшает сжатие на три до четырех раз и до 10 раз, ускорение производительности над файлами Delta Lake, которые не оптимизированы. Spark в Fabric динамически оптимизирует секции при создании файлов с размером по умолчанию 128 МБ. Размер целевого файла можно изменить для каждой рабочей нагрузки с помощью параметров.
Благодаря возможности оптимизации записи подсистема Apache Spark уменьшает количество записанных файлов и стремится увеличить размер отдельных файлов записанных данных.
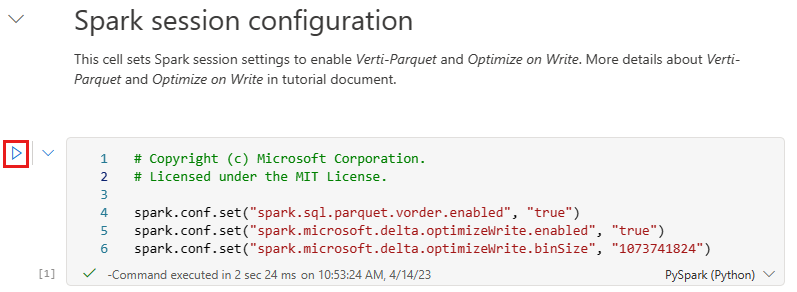
Перед записью данных в виде таблиц Delta lake в разделе "Таблицы " в lakehouse вы используете две функции Fabric (V-order и Optimize Write) для оптимизированной записи данных и повышения производительности чтения. Чтобы включить эти функции в сеансе, задайте эти конфигурации в первой ячейке записной книжки.
Чтобы запустить записную книжку и выполнить все ячейки последовательности, выберите "Выполнить все " на верхней ленте (в разделе "Главная"). Или, чтобы выполнить код только из определенной ячейки, выберите значок выполнения , который отображается слева от ячейки при наведении указателя мыши, или нажмите клавиши SHIFT+ ВВОД на клавиатуре, пока элемент управления находится в ячейке.
При запуске ячейки не нужно указывать базовый пул Spark или сведения о кластере, так как Структура предоставляет их через динамический пул. Каждая рабочая область Fabric поставляется с пулом Spark по умолчанию с именем Live Pool. Это означает, что при создании записных книжек вам не нужно беспокоиться об указании конфигураций Spark или сведений о кластере. При выполнении первой команды записной книжки динамический пул выполняется в течение нескольких секунд. И сеанс Spark устанавливается и запускает выполнение кода. Последующее выполнение кода почти мгновенно выполняется в этой записной книжке, пока сеанс Spark активен.
Затем вы считываете необработанные данные из раздела "Файлы " в lakehouse и добавляете дополнительные столбцы для разных частей даты в рамках преобразования. Наконец, вы используете секционирование API Spark для секционирования данных перед записью в виде формата таблицы Delta на основе только что созданных столбцов части данных (год и квартал).
from pyspark.sql.functions import col, year, month, quarter table_name = 'fact_sale' df = spark.read.format("parquet").load('Files/wwi-raw-data/full/fact_sale_1y_full') df = df.withColumn('Year', year(col("InvoiceDateKey"))) df = df.withColumn('Quarter', quarter(col("InvoiceDateKey"))) df = df.withColumn('Month', month(col("InvoiceDateKey"))) df.write.mode("overwrite").format("delta").partitionBy("Year","Quarter").save("Tables/" + table_name)После загрузки таблиц фактов можно перейти к загрузке данных для остальных измерений. Следующая ячейка создает функцию для чтения необработанных данных из раздела "Файлы " озера для каждого из имен таблиц, переданных в качестве параметра. Затем создается список таблиц измерений. Наконец, он циклит по списку таблиц и создает разностную таблицу для каждого имени таблицы, считываемой из входного параметра. Обратите внимание, что скрипт удаляет столбец с именем
Photoв этом примере, так как столбец не используется.from pyspark.sql.types import * def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/wwi-raw-data/full/' + table_name) df = df.drop("Photo") df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_city', 'dimension_date', 'dimension_employee', 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)Чтобы проверить созданные таблицы, щелкните правой кнопкой мыши и выберите обновление в wwilakehouse lakehouse . Отображаются таблицы.
Снова перейдите в представление элементов рабочей области и выберите wwilakehouse lakehouse , чтобы открыть его.
Теперь откройте вторую записную книжку. В представлении Lakehouse выберите "Открыть существующую записную книжку>" на ленте.
В списке существующих записных книжек выберите 02 — Преобразование данных — бизнес-записная книжка, чтобы открыть ее.
В открытой записной книжке в lakehouse Обозреватель вы увидите, что записная книжка уже связана с открытым lakehouse.
В организации могут быть инженеры данных, работающие с Scala/Python и другими инженерами данных, работающими с SQL (Spark SQL или T-SQL), все работают над одной копией данных. Структура позволяет этим различным группам, с различным опытом и предпочтениями работать и сотрудничать. Два различных подхода преобразуются и создают бизнес-агрегаты. Вы можете выбрать подходящий для вас или смешивать и соответствовать этим подходам на основе ваших предпочтений, не компрометируя производительность:
Подход #1 . Использование PySpark для объединения и агрегирования данных для создания бизнес-агрегатов. Этот подход предпочтителен для кого-то с фоном программирования (Python или PySpark).
Подход 2 . Использование Spark SQL для объединения и агрегирования данных для создания бизнес-агрегатов. Этот подход предпочтительнее для кого-то с фоном SQL, переход в Spark.
Подход 1 (sale_by_date_city) — использование PySpark для объединения и статистической обработки данных для создания бизнес-статистических выражений. В следующем коде вы создаете три разных кадра данных Spark, каждый из которых ссылается на существующую таблицу Delta. Затем вы присоединяетесь к этим таблицам с помощью кадров данных, группируйте их путем создания агрегирования, переименования нескольких столбцов и, наконец, записи в виде таблицы в разделе таблиц озера, чтобы сохранить данные.
В этой ячейке создается три разных кадра данных Spark, каждый из которых ссылается на существующую таблицу Delta.
df_fact_sale = spark.read.table("wwilakehouse.fact_sale") df_dimension_date = spark.read.table("wwilakehouse.dimension_date") df_dimension_city = spark.read.table("wwilakehouse.dimension_city")В этой ячейке вы присоединяетесь к этим таблицам с помощью кадров данных, созданных ранее, группируйте их путем создания агрегирования, переименования нескольких столбцов и, наконец, записи в виде таблицы в разделе таблиц озера.
sale_by_date_city = df_fact_sale.alias("sale") \ .join(df_dimension_date.alias("date"), df_fact_sale.InvoiceDateKey == df_dimension_date.Date, "inner") \ .join(df_dimension_city.alias("city"), df_fact_sale.CityKey == df_dimension_city.CityKey, "inner") \ .select("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory", "sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .groupBy("date.Date", "date.CalendarMonthLabel", "date.Day", "date.ShortMonth", "date.CalendarYear", "city.City", "city.StateProvince", "city.SalesTerritory")\ .sum("sale.TotalExcludingTax", "sale.TaxAmount", "sale.TotalIncludingTax", "sale.Profit")\ .withColumnRenamed("sum(TotalExcludingTax)", "SumOfTotalExcludingTax")\ .withColumnRenamed("sum(TaxAmount)", "SumOfTaxAmount")\ .withColumnRenamed("sum(TotalIncludingTax)", "SumOfTotalIncludingTax")\ .withColumnRenamed("sum(Profit)", "SumOfProfit")\ .orderBy("date.Date", "city.StateProvince", "city.City") sale_by_date_city.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_city")Подход 2 (sale_by_date_employee) — использование Spark SQL для объединения и агрегирования данных для создания бизнес-агрегатов. В следующем коде создается временное представление Spark путем объединения трех таблиц, группирования путем создания агрегирования и переименования нескольких столбцов. Наконец, вы считываете из временного представления Spark и, наконец, записываете его в виде таблицы Delta в разделе таблиц озера, чтобы сохранить данные.
В этой ячейке создается временное представление Spark путем объединения трех таблиц, группирования путем создания агрегирования и переименования нескольких столбцов.
%%sql CREATE OR REPLACE TEMPORARY VIEW sale_by_date_employee AS SELECT DD.Date, DD.CalendarMonthLabel , DD.Day, DD.ShortMonth Month, CalendarYear Year ,DE.PreferredName, DE.Employee ,SUM(FS.TotalExcludingTax) SumOfTotalExcludingTax ,SUM(FS.TaxAmount) SumOfTaxAmount ,SUM(FS.TotalIncludingTax) SumOfTotalIncludingTax ,SUM(Profit) SumOfProfit FROM wwilakehouse.fact_sale FS INNER JOIN wwilakehouse.dimension_date DD ON FS.InvoiceDateKey = DD.Date INNER JOIN wwilakehouse.dimension_Employee DE ON FS.SalespersonKey = DE.EmployeeKey GROUP BY DD.Date, DD.CalendarMonthLabel, DD.Day, DD.ShortMonth, DD.CalendarYear, DE.PreferredName, DE.Employee ORDER BY DD.Date ASC, DE.PreferredName ASC, DE.Employee ASCВ этой ячейке вы считываете временное представление Spark, созданное в предыдущей ячейке, и, наконец, записываете его в виде таблицы в разделе таблиц озера.
sale_by_date_employee = spark.sql("SELECT * FROM sale_by_date_employee") sale_by_date_employee.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save("Tables/aggregate_sale_by_date_employee")Чтобы проверить созданные таблицы, щелкните правой кнопкой мыши и выберите "Обновить " в wwilakehouse lakehouse . Отображаются статистические таблицы.

Два подхода дают аналогичный результат. Чтобы свести к минимуму потребность в изучении новой технологии или компромисса по производительности, выберите подход, который лучше всего подходит для вашего фона и предпочтений.
Возможно, вы заметите, что вы записываете данные в виде файлов Delta Lake. Функция автоматического обнаружения и регистрации таблиц Fabric выбирает и регистрирует их в хранилище метаданных. Вам не нужно явно вызывать CREATE TABLE инструкции для создания таблиц для использования с SQL.