Разработка, оценка и оценка модели прогнозирования для продаж суперstore
В этом руководстве представлен полный пример рабочего процесса Synapse Обработка и анализ данных в Microsoft Fabric. Сценарий создает модель прогнозирования, которая использует исторические данные о продажах для прогнозирования продаж категории продуктов в суперstore.
Прогнозирование является важным активом в продажах. Он объединяет исторические данные и прогнозные методы для предоставления аналитических сведений о будущих тенденциях. Прогнозирование может анализировать прошлые продажи, чтобы определить закономерности и узнать о поведении потребителей для оптимизации инвентаризации, производства и маркетинговых стратегий. Этот упреждающий подход повышает адаптируемость, скорость реагирования и общую производительность предприятий в динамической marketplace.
В этом руководстве рассматриваются следующие действия.
- Загрузка данных
- Использование анализа аналитических данных для понимания и обработки данных
- Обучение модели машинного обучения с помощью пакета программного обеспечения с открытым исходным кодом и отслеживание экспериментов с помощью MLflow и функции автологирования Fabric
- Сохранение конечной модели машинного обучения и прогнозирование
- Отображение производительности модели с помощью визуализаций Power BI
Необходимые компоненты
Получение подписки Microsoft Fabric. Или зарегистрируйте бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой части домашней страницы, чтобы перейти на интерфейс Synapse Обработка и анализ данных.
- При необходимости создайте озеро Microsoft Fabric, как описано в разделе "Создание озера в Microsoft Fabric".
Следуйте инструкциям в записной книжке
Вы можете выбрать один из следующих вариантов для выполнения в записной книжке:
- Откройте и запустите встроенную записную книжку в интерфейсе Synapse Обработка и анализ данных
- Отправка записной книжки из GitHub в интерфейс Synapse Обработка и анализ данных
Открытие встроенной записной книжки
Пример записной книжки прогнозирования продаж сопровождается этим руководством.
Чтобы открыть встроенную записную книжку учебника в интерфейсе Synapse Обработка и анализ данных:
Перейдите на домашнюю страницу Synapse Обработка и анализ данных.
Выберите " Использовать пример".
Выберите соответствующий пример:
- На вкладке сквозных рабочих процессов (Python) по умолчанию, если пример предназначен для учебника по Python.
- На вкладке сквозных рабочих процессов (R), если пример предназначен для руководства по R.
- На вкладке "Краткие руководства", если пример предназначен для быстрого руководства.
Подключите lakehouse к записной книжке перед запуском кода.
Импорт записной книжки из GitHub
Записная книжка AIsample — Superstore Forecast.ipynb сопровождается этим руководством.
Чтобы открыть сопровождающую записную книжку для этого руководства, следуйте инструкциям в статье "Подготовка системы для обработки и анализа данных", чтобы импортировать записную книжку в рабочую область.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Перед запуском кода обязательно подключите lakehouse к записной книжке .
Шаг 1. Загрузка данных
Набор данных содержит 9995 экземпляров продаж различных продуктов. Он также включает 21 атрибутов. Эта таблица состоит из файла Superstore.xlsx, используемого в этой записной книжке:
| ИД строки | ИД заказа | Дата заказа | Дата отгрузки | Режим доставки | ИД клиента | Название клиента | Сегмент | Страна/регион | Город | Штат | Почтовый индекс | Регион | Код продукта | Категория | Подкатегория | Название продукта | Продажи | Количество | Скидка | Прибыль |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Стандартный класс | SO-20335 | Шон О'Доннелл | Потребители | Соединенные Штаты | Форт Лодердейл | Флорида | 33311 | South | FUR-TA-10000577 | Мебель | Таблицы | Бретфорд CR4500 серии Slim Rectangular Table | 957.5775 | 5 | 0,45 % | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Стандартный класс | Стандартный класс | Brosina Хоффман | Потребители | Соединенные Штаты | Лос-Анджелес | Калифорния | 90032 | Запад | FUR-TA-10001539 | Мебель | Таблицы | Прямоугольные таблицы конференций Chromcraft | 1706.184 | 9 | 0,2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Стандартный класс | ТБ-21520 | Трейси Блюмштейн | Потребители | Соединенные Штаты | Филадельфия | Пенсильвания | 19140 | Восток | OFF-EN-10001509 | Материалы Office | Оболочки | Конверты с многостроковыми галстуками | 3.264 | 2 | 0,2 | 1.1016 |
Определите эти параметры, чтобы использовать эту записную книжку с различными наборами данных:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
Скачайте набор данных и отправьте его в lakehouse
Этот код скачивает общедоступную версию набора данных, а затем сохраняет ее в Lakehouse Fabric:
Важно!
Перед запуском записной книжки обязательно добавьте lakehouse . В противном случае вы получите ошибку.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Настройка отслеживания экспериментов MLflow
Microsoft Fabric автоматически фиксирует значения входных параметров и выходных метрик модели машинного обучения при обучении. Это расширяет возможности автологирования MLflow. Затем данные записываются в рабочую область, где можно получить доступ и визуализировать его с помощью API MLflow или соответствующего эксперимента в рабочей области. Дополнительные сведения об автологе см. в статье "Автологирование" в Microsoft Fabric.
Чтобы отключить автоматическую запись Microsoft Fabric в сеансе записной книжки, вызовите mlflow.autolog() и установите:disable=True
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
Чтение необработанных данных из lakehouse
Чтение необработанных данных из раздела "Файлы " в lakehouse. Добавьте дополнительные столбцы для разных частей дат. Те же сведения используются для создания секционированных разностных таблиц. Так как необработанные данные хранятся в виде файла Excel, необходимо использовать pandas для его чтения:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Шаг 2. Выполнение анализа аналитических данных
Импорт библиотек
Перед любым анализом импортируйте необходимые библиотеки:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
Отображение необработанных данных
Просмотрите подмножество данных, чтобы лучше понять сам набор данных и использовать display функцию для печати кадра данных. Кроме того, Chart представления могут легко визуализировать подмножества набора данных.
display(df)
Эта записная книжка в основном ориентирована на прогнозирование Furniture продаж категорий. Это ускоряет вычисление и помогает показать производительность модели. Однако эта записная книжка использует адаптируемые методы. Эти методы можно расширить для прогнозирования продаж других категорий продуктов.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
Предварительная обработка данных
Реальные бизнес-сценарии часто требуют прогнозирования продаж в трех разных категориях:
- Определенная категория продукта
- Определенная категория клиента
- Определенная комбинация категории продуктов и категории клиентов
Сначала удалите ненужные столбцы для предварительной обработки данных. Некоторые из столбцов (Row ID, Order ID,Customer IDи Customer Name) не нужны, так как они не влияют. Мы хотим прогнозировать общие продажи по всему региону и состоянию для определенной категории продуктов (Furniture), чтобы мы могли удалить State, Regionи CountryCityPostal Code столбцы. Чтобы прогнозировать продажи для определенного расположения или категории, может потребоваться соответствующим образом настроить этап предварительной обработки.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
Набор данных структурирован ежедневно. Мы должны перезапустить столбец Order Date, так как мы хотим разработать модель для прогнозирования продаж ежемесячно.
Сначала группировать категорию Furniture по Order Date. Затем вычислите сумму столбца Sales для каждой группы, чтобы определить общее количество продаж для каждого уникального Order Date значения. Измените размер столбца Sales с MS частотой, чтобы агрегировать данные по месяцам. Наконец, вычислите среднее значение продаж за каждый месяц.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
Продемонстрировать влияние Order Date Sales на категорию Furniture :
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Перед любым статистическим анализом statsmodels необходимо импортировать модуль Python. Он предоставляет классы и функции для оценки многих статистических моделей. Он также предоставляет классы и функции для проведения статистических тестов и статистического исследования данных.
import statsmodels.api as sm
Выполнение статистического анализа
Временный ряд отслеживает эти элементы данных с заданными интервалами, чтобы определить вариант этих элементов в шаблоне временных рядов:
Уровень: фундаментальный компонент, представляющий среднее значение для определенного периода времени.
Тенденция: описывает, уменьшается ли временный ряд, остается ли константой или увеличивается с течением времени.
Сезонность: описывает периодический сигнал в временных рядах и ищет циклические вхождения, влияющие на увеличение или уменьшение шаблонов временных рядов.
Шум или остатки: относится к случайным колебаниям и изменчивости в данных временных рядов, которые модель не может объяснить.
В этом коде вы увидите эти элементы для набора данных после предварительной обработки:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
На графиках описываются сезонность, тенденции и шум в прогнозируемых данных. Вы можете записать базовые шаблоны и разработать модели, которые делают точные прогнозы, устойчивые к случайным колебаниям.
Шаг 3. Обучение и отслеживание модели
Теперь, когда у вас есть доступные данные, определите модель прогнозирования. В этой записной книжке примените модель прогнозирования, называемую сезонным авторегистративным интегрированным скользящей средой с экзогенными факторами (SARIMAX). SARIMAX объединяет компоненты авторегистрации (AR) и скользящее среднее значение (MA), сезонные различия и внешние прогнозаторы, чтобы сделать точные и гибкие прогнозы для данных временных рядов.
Для отслеживания экспериментов также используется автологирование MLflow и Fabric. Здесь загрузите разностную таблицу из озера. Вы можете использовать другие разностные таблицы, которые считают lakehouse источником.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Настройка гиперпараметров
SARIMAX учитывает параметры, участвующие в регулярном режиме автоматической регистрации интегрированной скользящей средней (pARIMAdq), и добавляет параметры сезонности (P, , D, ). sQ Эти аргументы модели SARIMAX называются порядком (, , ) qи сезонным порядком (P, D, соответственноQs). dp Поэтому для обучения модели необходимо сначала настроить семь параметров.
Параметры заказа:
p: порядок компонента AR, представляющий количество прошлых наблюдений в временных рядах, используемых для прогнозирования текущего значения.Как правило, этот параметр должен быть неотрицательное целое число. Общие значения находятся в диапазоне
03от , хотя возможны более высокие значения, в зависимости от конкретных характеристик данных.pБолее высокое значение указывает на длинную память прошлых значений в модели.d: различающийся порядок, представляющий количество раз, в течение которых временные ряды должны отличаться, чтобы добиться нестантовности.Этот параметр должен быть неотрицательное целое число. Общие значения находятся в диапазоне
0от2.dЗначение означает, что временные0ряды уже неустанно. Более высокие значения указывают количество разных операций, необходимых для того, чтобы сделать его стационарным.q: порядок компонента MA, представляющий число прошлых терминов ошибки белого шума, используемых для прогнозирования текущего значения.Этот параметр должен быть неотрицательное целое число. Общие значения находятся в диапазоне от, но для определенных временных
03рядов могут потребоваться более высокие значения.qБолее высокое значение указывает на более сильную зависимость от прошлых терминов ошибок для прогнозирования.
Параметры сезонного заказа:
P: сезонный порядок компонента AR, аналогичныйpсезонной частиD: сезонный порядок разности, аналогичный сезонной части, ноdдля сезонной частиQ: сезонный порядок компонента MA, аналогичныйqсезонной части, но для сезонной частиs: количество шагов времени на сезонный цикл (например, 12 для ежемесячных данных с ежегодной сезонностью)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX имеет другие параметры:
enforce_stationarity: следует ли применять модель к данным временных рядов, прежде чем приступить к модели SARIMAX.Если
enforce_stationarityзадано значениеTrue(по умолчанию), он указывает, что модель SARIMAX должна применять нестантовность к данным временных рядов. Затем модель SARIMAX автоматически применяет различные значения к данным, чтобы сделать его стационарным, как указаноdв инструкции иDзаказах, прежде чем приступить к модели. Это распространенная практика, так как многие модели временных рядов, включая SARIMAX, предполагают, что данные являются стационарными.Для нестационарных временных рядов (например, он демонстрирует тенденции или сезонность), рекомендуется установить
enforce_stationarityTrueзначение , и позволить модели SARIMAX обрабатывать различные возможности для достижения нестантности. Для стационных временных рядов (например, один без тенденций или сезонности), установите дляenforce_stationarityFalseпредотвращения ненужных отличий.enforce_invertibility: определяет, должна ли модель применять инвертируемость для предполагаемых параметров во время процесса оптимизации.Если
enforce_invertibilityзадано значениеTrue(по умолчанию), то она указывает, что модель SARIMAX должна принудительно применять неверуемость для предполагаемых параметров. Инвертируемость гарантирует, что модель хорошо определена, и что предполагаемые коэффициенты AR и MA приземлились в пределах диапазона станции.Принудительное применение инвертируемости помогает обеспечить соответствие модели SARIMAX теоретическим требованиям для стабильной модели временных рядов. Это также помогает предотвратить проблемы с оценкой модели и стабильностью.
По умолчанию используется AR(1) модель. Это относится к (1, 0, 0). Однако обычно рекомендуется попробовать различные сочетания параметров заказа и сезонных параметров порядка и оценить производительность модели для набора данных. Соответствующие значения могут отличаться от одного временных рядов к другому.
Определение оптимальных значений часто включает анализ функции автозамены (ACF) и частичной функции автозамены (PACF) данных временных рядов. Он также часто включает в себя использование критериев выбора модели, например критерия информации Akaike (AIC) или критерия информации Байеса (BIC).
Настройте гиперпараметры:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
После оценки предыдущих результатов можно определить значения для параметров заказа и сезонных параметров заказа. Выбор есть order=(0, 1, 1) и seasonal_order=(0, 1, 1, 12), которые предлагают самый низкий AIC (например, 279,58). Используйте эти значения для обучения модели.
Обучение модели
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Этот код визуализирует прогноз временных рядов для данных о продажах мебели. В диаграммах отображаются как наблюдаемые данные, так и прогноз на один шаг вперед, с затеняемой областью для доверительного интервала.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Используйте predictions для оценки производительности модели, сравнивая ее с фактическими значениями. Значение predictions_future указывает на будущее прогнозирование.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Шаг 4. Оценка модели и сохранение прогнозов
Интеграция фактических значений с прогнозируемыми значениями для создания отчета Power BI. Сохраните эти результаты в таблице в лейкхаусе.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Шаг 5. Визуализация в Power BI
В отчете Power BI показана средняя абсолютная процентная ошибка (MAPE) 16,58. Метрика MAPE определяет точность метода прогнозирования. Он представляет точность прогнозируемых значений в сравнении с фактическими значениями.
MAPE — это простая метрика. 10% MAPE представляет, что среднее отклонение между прогнозируемыми значениями и фактическими значениями составляет 10%, независимо от того, было ли отклонение положительным или отрицательным. Стандарты желательных значений MAPE различаются в разных отраслях.
Светлая синяя линия в этом графе представляет фактические значения продаж. Темно-синяя линия представляет прогнозируемые значения продаж. Сравнение фактических и прогнозируемых продаж показывает, что модель эффективно прогнозирует продажи для Furniture категории в течение первых шести месяцев 2023 года.
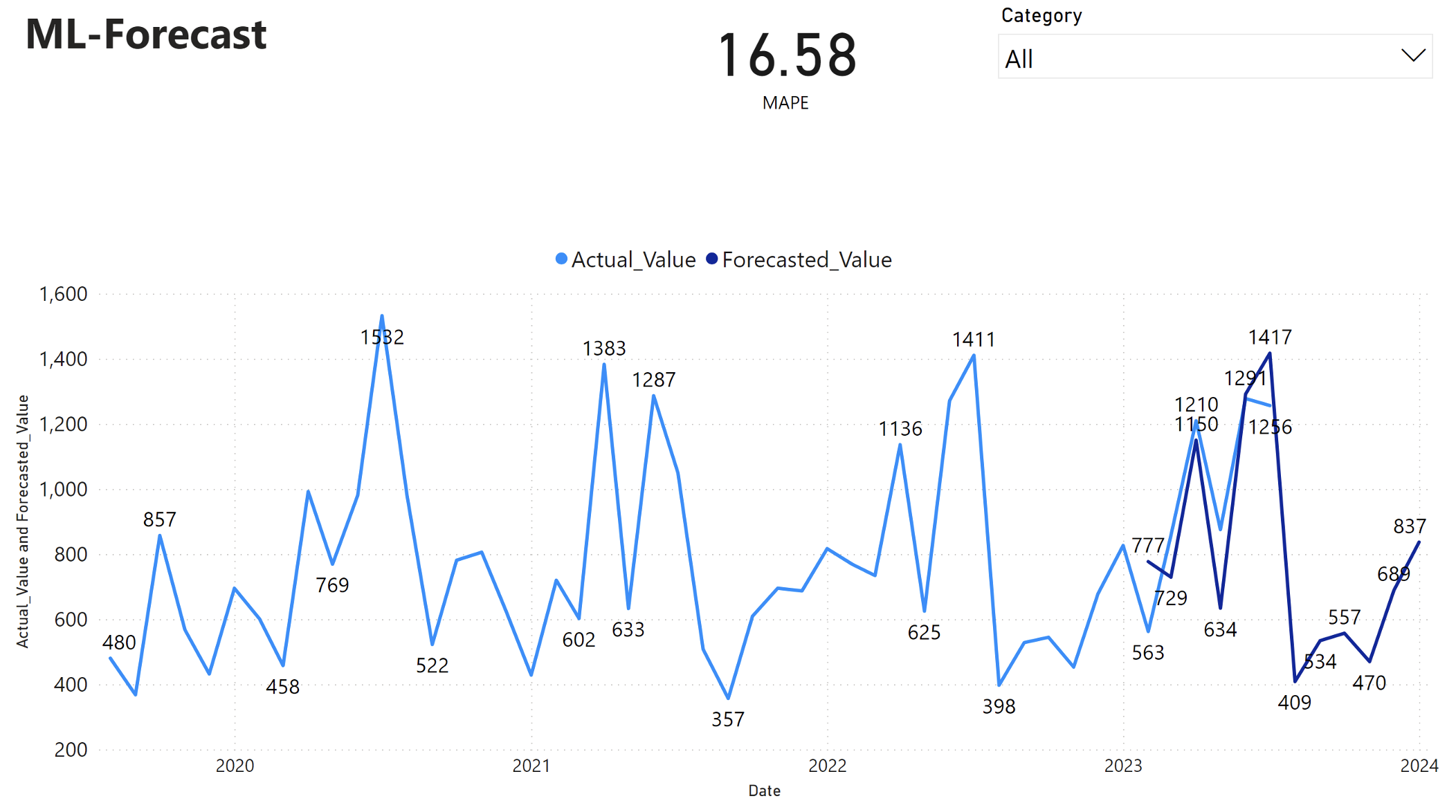
Основываясь на этом наблюдении, мы можем иметь уверенность в возможностях прогнозирования модели, для общих продаж за последние шесть месяцев 2023 года и расширения до 2024 года. Эта уверенность может сообщить стратегическим решениям по управлению запасами, закупкам сырья и другим вопросам, связанным с бизнесом.