Руководство. Очистка данных с помощью функциональных зависимостей
В этом руководстве вы используете функциональные зависимости для очистки данных. Функциональная зависимость существует, если один столбец в семантической модели (набор данных Power BI) является функцией другого столбца. Например, столбец zip-кода может определять значения в столбце города . Функциональная зависимость манифестирует себя как связь "один ко многим" между значениями в двух или нескольких столбцах в кадре данных. В этом руководстве используется набор данных Synthea , чтобы показать, как функциональные связи могут помочь обнаружить проблемы с качеством данных.
В этом руководстве описано следующее:
- Применение знаний домена для формирования гипотез о функциональных зависимостях в семантической модели.
- Ознакомьтесь с компонентами библиотеки Python семантической ссылки (SemPy), которые помогают автоматизировать анализ качества данных. К этим компонентам относятся:
- FabricDataFrame — структура, похожая на pandas, улучшена с дополнительной семантической информацией.
- Полезные функции, которые автоматизируют оценку гипотез о функциональных зависимостях и определяют нарушения связей в семантических моделях.
Необходимые компоненты
Получение подписки Microsoft Fabric. Или зарегистрируйте бесплатную пробную версию Microsoft Fabric.
Войдите в Microsoft Fabric.
Используйте переключатель интерфейса в левой части домашней страницы, чтобы перейти на интерфейс Synapse Обработка и анализ данных.
- Выберите рабочие области в области навигации слева, чтобы найти и выбрать рабочую область. Эта рабочая область становится текущей рабочей областью.
Следуйте инструкциям в записной книжке
Записная книжка data_cleaning_functional_dependencies_tutorial.ipynb сопровождается этим руководством.
Чтобы открыть сопровождающую записную книжку для этого руководства, следуйте инструкциям в статье "Подготовка системы для обработки и анализа данных", чтобы импортировать записную книжку в рабочую область.
Если вы хотите скопировать и вставить код на этой странице, можно создать новую записную книжку.
Перед запуском кода обязательно подключите lakehouse к записной книжке .
Настройка записной книжки
В этом разделе описана настройка среды записной книжки с необходимыми модулями и данными.
- Для Spark 3.4 и более поздних версий семантическая ссылка доступна в среде выполнения по умолчанию при использовании Fabric и не требуется устанавливать ее. Если вы используете Spark 3.3 или ниже или хотите обновить до последней версии семантической ссылки, можно выполнить следующую команду:
python %pip install -U semantic-link
Выполните необходимые импорты модулей, которые потребуются вам позже:
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata from sempy.samples import download_syntheaИзвлеките примеры данных. В этом руководстве вы используете набор данных Synthea синтетических медицинских записей (небольшая версия для простоты):
download_synthea(which='small')
Изучение данных
Инициализировать
FabricDataFrameсодержимое файла providers.csv :providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()Проверьте наличие проблем с качеством данных с функцией SemPy
find_dependencies, настроив граф автоопределенных функциональных зависимостей:deps = providers.find_dependencies() plot_dependency_metadata(deps)
График функциональных зависимостей показывает, что
IdопределяетNAMEиORGANIZATION(указано сплошными стрелками), что ожидается, так какIdэто уникально:Убедитесь, что
Idэто уникально:providers.Id.is_uniqueКод возвращается
Trueдля подтверждения уникальностиId.

Подробное анализ функциональных зависимостей
График функциональных зависимостей также показывает, что ORGANIZATION определяет ADDRESS и ZIP, как ожидалось. Однако может потребоваться ZIP также определить CITY, но тиреная стрелка указывает, что зависимость является только приблизительной, указывая на проблему качества данных.
В графе существуют и другие особенности. Например, NAME не определяет GENDER, IdSPECIALITYили ORGANIZATION. Каждое из этих особенностей может быть стоит исследовать.
Более подробно рассмотрим приблизительную связь между
ZIPиCITYс помощью функции SemPylist_dependency_violations, чтобы просмотреть табличный список нарушений:providers.list_dependency_violations('ZIP', 'CITY')Рисование графа
plot_dependency_violationsс помощью функции визуализации SemPy. Этот график полезен, если количество нарушений невелико:providers.plot_dependency_violations('ZIP', 'CITY')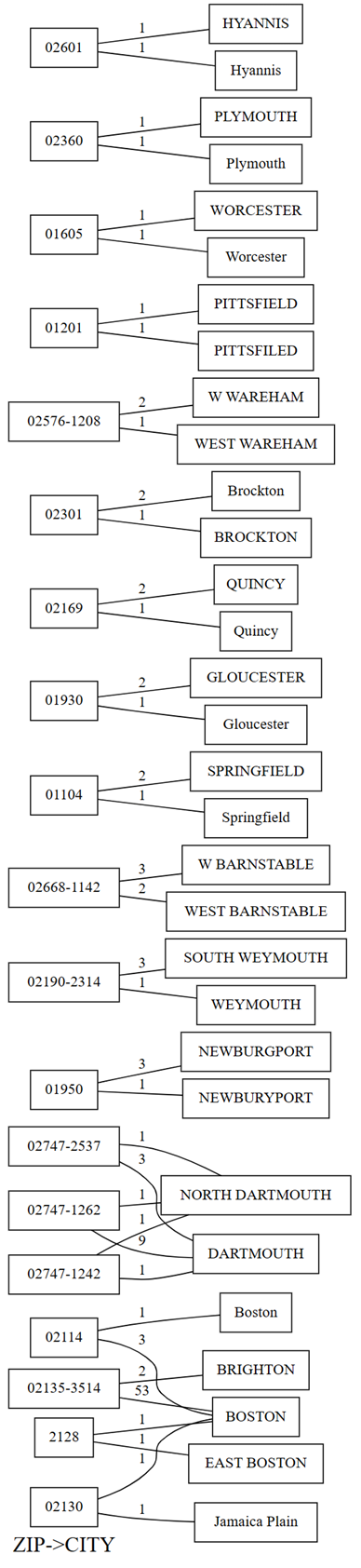
На графике нарушений зависимостей отображаются значения на
ZIPлевой стороне и значения дляCITYправой стороны. Ребра подключает zip-код слева от графика с городом справа, если есть строка, содержащая эти два значения. Края аннотированы с количеством таких строк. Например, есть две строки с почтовым кодом 02747-1242, одна строка с городом "NORTH DARTHMOUTH" и другой с городом "DARTHMOUTH", как показано в предыдущем графике и следующем коде:Проверьте предыдущие наблюдения, сделанные с помощью графика нарушений зависимостей, выполнив следующий код:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()На графике также показано, что среди строк, имеющих
CITYзначение "DARTHMOUTH", девять строк имеютZIPзначение 02747-1262; одна строка имеетZIPзначение 02747-1242; а одна строка имеетZIPзначение 02747-2537. Подтверждает эти наблюдения с помощью следующего кода:providers[providers.CITY == 'DARTMOUTH'].ZIP.value_counts()Существуют другие zip-коды, связанные с DARTMOUTH, но эти zip-коды не отображаются в графе нарушений зависимостей, так как они не указывают на проблемы с качеством данных. Например, почтовый индекс "02747-4302" однозначно связан с DARTMOUTH и не отображается в графе нарушений зависимостей. Подтвердите, выполнив следующий код:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
Сводка проблем с качеством данных, обнаруженных с помощью SemPy
Вернитесь к графу нарушений зависимостей, вы увидите, что в этой семантической модели существует несколько интересных проблем с качеством данных:
- Некоторые имена городов — это все прописные буквы. Эта проблема легко устранить с помощью строковых методов.
- Некоторые имена городов имеют квалификаторы (или префиксы), такие как "Север" и "Восток". Например, почтовый индекс "2128" сопоставляется с "East BOSTON" один раз и "БОСТОН" один раз. Аналогичная проблема возникает между "NORTH DARTHMOUTH" и "DARTHMOUTH". Вы можете попытаться удалить эти квалификаторы или сопоставить zip-коды с городом с наиболее распространенным вхождением.
- В некоторых городах есть опечатки, такие как "PITTSFIELD" и "PITTSFILED" и "NEWBURGPORT против NEWBURYPORT". Для "NEWBURGPORT" этот опечаток можно исправить с помощью наиболее распространенного вхождения. Для "PITTSFIELD", имея только одно вхождение, делает его гораздо сложнее для автоматической диамбигуации без внешних знаний или использования языковой модели.
- Иногда префиксы, такие как "Запад", сокращены до одной буквы "W". Эта проблема может быть исправлена с помощью простой замены, если все вхождения "W" стоят для "Запад".
- Почтовый индекс "02130" сопоставляется с "БОСТОН" один раз и "Ямайка равнина" один раз. Эта проблема не легко исправить, но если было больше данных, сопоставление с наиболее распространенным вхождением может быть потенциальным решением.
Очистка данных
Исправьте проблемы с заглавной буквы, изменив все буквы на заголовок:
providers['CITY'] = providers.CITY.str.title()Запустите обнаружение нарушений еще раз, чтобы увидеть, что некоторые из неоднозначности исчезли (число нарушений меньше):
providers.list_dependency_violations('ZIP', 'CITY')На этом этапе можно уточнить данные вручную, но одна из потенциальных задач очистки данных заключается в том, чтобы удалить строки, которые нарушают функциональные ограничения между столбцами в данных, используя функцию SemPy
drop_dependency_violations.Для каждого значения детерминированной переменной можно выбрать наиболее распространенное значение зависимой переменной
drop_dependency_violationsи удалить все строки с другими значениями. Эту операцию следует применять только в том случае, если вы уверены, что эта статистическая эвристика приведет к правильным результатам для данных. В противном случае необходимо написать собственный код для обработки обнаруженных нарушений по мере необходимости.Запустите функцию
drop_dependency_violationsвZIPстолбцах иCITYстолбцах:providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')Перечисление любых нарушений зависимостей между
ZIPиCITY:providers_clean.list_dependency_violations('ZIP', 'CITY')Код возвращает пустой список, указывающий на отсутствие нарушений функционального ограничения CITY —> ZIP.
Связанный контент
Ознакомьтесь с другими руководствами по семантической ссылке / SemPy:
- Руководство. Анализ функциональных зависимостей в примере семантической модели
- Руководство. Извлечение и вычисление мер Power BI из записной книжки Jupyter
- Руководство. Обнаружение связей в семантической модели с помощью семантической связи
- Руководство. Обнаружение связей в наборе данных Synthea с помощью семантической ссылки
- Руководство по проверке данных с помощью SemPy и больших ожиданий (GX)