Оператор summarize
Область применения: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Создает таблицу, которая объединяет содержимое входной таблицы.
Синтаксис
T [ SummarizeParameters ] [[Столбец=] Агрегирование [, ...]] [by Столбец =] GroupExpression [, ...]] | summarize
Дополнительные сведения о соглашениях синтаксиса.
Параметры
| Имя (название) | Type | Обязательно | Описание |
|---|---|---|---|
| Столбец | string |
Имя столбца результатов. По умолчанию это имя, получаемое из выражения. | |
| Агрегат | string |
✔️ | Вызов статистической функции, например count() или avg(), с именами столбцов в качестве аргументов. |
| GroupExpression | скаляр | ✔️ | Скалярное выражение, которое может ссылаться на входные данные. Выходные данные будут содержать такое количество записей, которое будет соответствовать количеству несовпадающих значений во всех выражениях групп. |
| Суммированиеparameters | string |
Ноль или более разделенных пробелами параметров в виде значения имени = , которое управляет поведением. См . поддерживаемые параметры. |
Примечание.
Если таблица входных данных пуста, выходные данные зависят от того, используется ли GroupExpression.
- Если свойство GroupExpression не предоставлено, вывод будет представлен одной (пустой) строкой.
- Если же свойство GroupExpression предоставлено, вывод не будет иметь строк.
Поддерживаемые параметры
| Имя | Описание |
|---|---|
hint.num_partitions |
Указывает количество секций, используемых для совместного использования нагрузки запроса на узлы кластера. См. запрос перемешивания |
hint.shufflekey=<key> |
Запрос shufflekey использует нагрузку запроса на узлы кластера, используя ключ для секционирования данных. См. запрос перемешивания |
hint.strategy=shuffle |
Запрос shuffle стратегии использует нагрузку запроса на узлы кластера, где каждый узел будет обрабатывать одну секцию данных. См. запрос перемешивания |
Возвраты
Входные строки объединяются в группы с одинаковыми значениями выражений by . Затем указанные агрегатные функции выполняют вычисления и создают строку для каждой группы. Результат содержит столбцы by и хотя бы один столбец для каждого вычисленного статистического выражения. (Некоторые агрегатные функции возвращают несколько столбцов).
Результат содержит столько строк, сколько существует несовпадающих комбинаций значений by (которые могут быть равны нулю). Если ключи группы не указаны, в результате будет содержаться одна запись.
Чтобы суммировать диапазоны числовых значений, можно ограничить диапазоны дискретными значениями с помощью bin().
Примечание.
- Для агрегатных выражений и выражений группирования допускаются произвольные выражения, но эффективнее использовать простые имена столбцов или функцию
bin()для числовых столбцов. - Автоматические почасовые объединения для столбцов "Дата и время" больше не поддерживаются. Вместо этого используйте явное группирование. Например,
summarize by bin(timestamp, 1h).
Значения агрегатов по умолчанию
В следующей таблице перечислены значения по умолчанию для агрегатов:
| Оператор | Default value |
|---|---|
count(), countif(), dcount()dcountif()count_distinct()sum()sumif()variance()varianceif()stdev()stdevif() |
0 |
make_bag(), , make_bag_if()make_list_if()make_list()make_set(),make_set_if() |
пустой динамический массив ([]) |
| Все остальные | null |
Примечание.
При применении этих агрегатов к сущностям, которые включают значения NULL, значения NULL игнорируются и не учитываются в вычислении. Примеры см. в разделе "Агрегаты значений по умолчанию".
Примеры
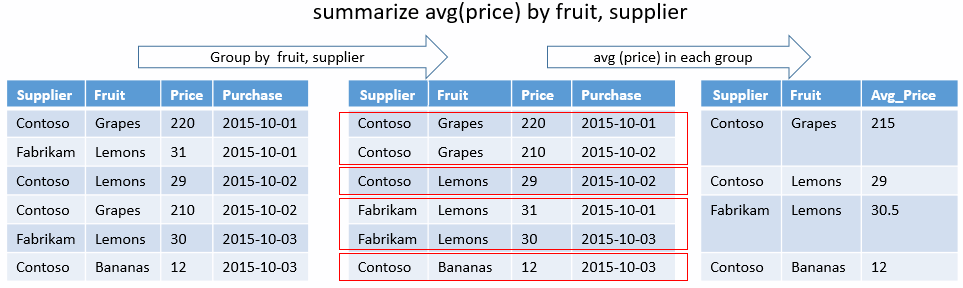
Уникальное сочетание
Следующий запрос определяет, какие уникальные сочетания и EventType существуют для штормовState, которые привели к прямой травме. Здесь нет статистических функций, только ключи group-by. Выходные данные будут отображать только столбцы для этих результатов.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Выходные данные
В следующей таблице показаны только первые 5 строк. Чтобы просмотреть полные выходные данные, выполните запрос.
| Штат | EventType |
|---|---|
| TEXAS | Ураганный ветер |
| TEXAS | Паводок |
| TEXAS | Холод |
| TEXAS | Очень сильный ветер |
| TEXAS | Наводнение |
| ... | ... |
Минимальная и максимальная метки времени
Находит минимальный и максимальный сильный дождь штормов на Гавайях. Нет предложения group-by, поэтому в выходных данных есть только одна строка.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Выходные данные
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
количество различных объектов
Следующий запрос вычисляет количество уникальных типов событий storm для каждого состояния и сортирует результаты по количеству уникальных типов штормов:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Выходные данные
В следующей таблице показаны только первые 5 строк. Чтобы просмотреть полные выходные данные, выполните запрос.
| Штат | ТипыOfStorms |
|---|---|
| TEXAS | 27 |
| CALIFORNIA | 26 |
| ПЕНСИЛЬВАНИЯ | 25 |
| ДЖОРДЖИЯ | 24 |
| ИЛЛИНОЙС | 23 |
| ... | ... |
Гистограмма
В следующем примере вычисляется типы событий шторма гистограммы, которые имели штормы продолжительностью более 1 дня. Поскольку Duration имеет много значений, используйте bin() для группировки его значений в 1-дневный интервал.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Выходные данные
| EventType | Length | EventCount |
|---|---|---|
| Засуха | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| Heat | 30.00:00:00 | 14 |
| Наводнение | 30.00:00:00 | 20 |
| Ливень | 29.00:00:00 | 42 |
| ... | ... | ... |
Значения по умолчанию для агрегатов
Если входные данные оператора имеют по крайней мере один пустой summarize ключ по группе, его результат также пуст.
Если входные данные оператора не имеют пустого summarize ключа по группе, результатом является значение по умолчанию агрегатов, используемых в summarize разделе "Дополнительные сведения", см . значения агрегатов по умолчанию.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Выходные данные
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Не число | 0 | 0 | 0 | 0 |
Результатом avg_x(x) является NaN деление на 0.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Выходные данные
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Выходные данные
| set_x | list_x |
|---|---|
| [] | [] |
Агрегатная средняя сумма суммирует все непустые значения и учитывает только те, которые участвовали в вычислении (не учитывают значения NULL).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Выходные данные
| sum_y | avg_y |
|---|---|
| 15 | 5 |
При обычном расчете значения NULL будут учитываться:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Выходные данные
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Выходные данные
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |