Обнаружение аномалий в аналитике конечных точек
Примечание.
Эта возможность доступна как надстройка Intune. Дополнительные сведения см. в разделе Надстройки Intune.
В этой статье объясняется, как обнаружение аномалий в аналитике конечных точек работает в качестве системы раннего предупреждения.
Обнаружение аномалий отслеживает работоспособность устройств в организации для взаимодействия с пользователями и снижения производительности после изменения конфигурации. При возникновении сбоя аномалии сопоставляют соответствующие объекты развертывания, чтобы обеспечить быстрое устранение неполадок, предложить первопричины и исправить.
Администраторы могут полагаться на обнаружение аномалий, чтобы узнать о пользовательском интерфейсе, влияющего на проблемы, прежде чем он достигнет их через другие каналы. Первоначальное внимание для обнаружения аномалий уделяется зависаниям или сбоям приложения и перезапускам stop error.
Обзор
При обнаружении аномалий вы можете обнаружить потенциальные проблемы в системе, прежде чем они станут серьезной проблемой. Традиционно группы поддержки имеют ограниченный уровень видимости потенциальных проблем.
часто они получают только подмножество проблем, о которых сообщается или эскалация по каналу поддержки, который по-настоящему не представляет все, что происходит в вашей организации.
Они должны потратить бесчисленное количество часов на проверку пользовательских панелей мониторинга, пытаясь определить первопричину, устранить неполадки, создать настраиваемые оповещения, изменить пороговые значения и настроить параметры.
Обнаружение аномалий направлено на решение этих проблем путем предоставления ИТ-администраторам критически важной информации.
Помимо обнаружения аномалий, можно просмотреть группы корреляции устройств, чтобы изучить потенциальные первопричины аномалий средней и высокой серьезности. Эти когорты устройств позволяют просматривать шаблоны, выявленные между устройствами. Мы приняли упреждающий подход к управлению устройствами, также определяя устройства, подверженные риску, в этих когортах. Это устройства, которые попадают под выявленные шаблоны с высокой достоверностью, но еще не видели этих аномалий.
Примечание.
Когорты устройств идентифицируются только для аномалий средней и высокой степени серьезности.
Предварительные условия
Лицензирование и подписки. Дополнительные функции аналитики конечных точек включены в состав Intune в Microsoft Intune Suite и требуют дополнительных затрат для параметров лицензирования, включая Microsoft Intune.
Разрешения: обнаружение аномалий использует встроенные разрешения ролей
Вкладка "Аномалии"
Войдите в Центр администрирования Microsoft Intune.
Выберите Обзораналитики конечных> точек отчета>.
Выберите вкладку Аномалии . На вкладке "Аномалии " представлен краткий обзор аномалий, обнаруженных в вашей организации.
В этом примере на вкладке "Аномалии " показана аномалия со средним уровнем серьезности . Вы можете добавить фильтры для уточнения списка.

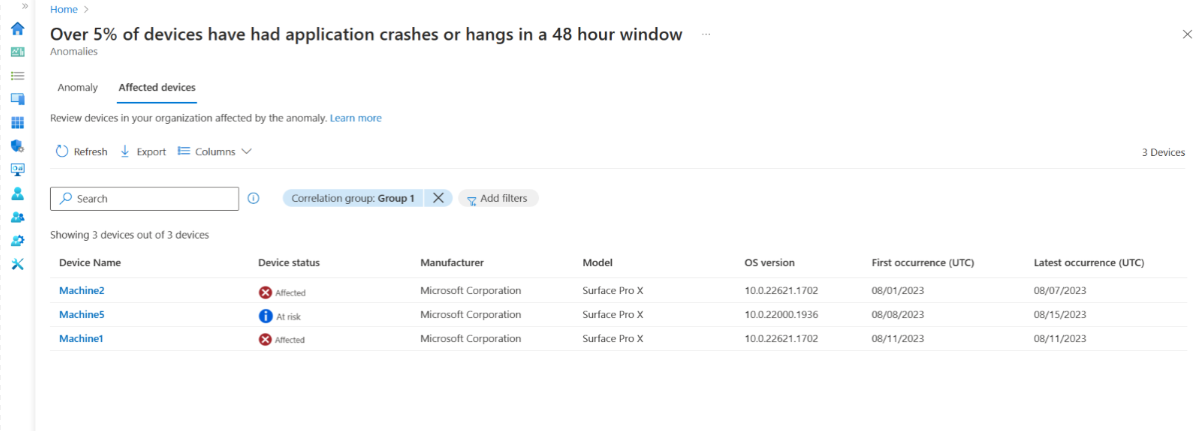
Чтобы просмотреть дополнительные сведения о конкретном элементе, выберите его в списке. Вы можете просмотреть такие сведения, как имя приложения, затронутые устройства, время первого обнаружения и последнего возникновения проблемы, а также группы устройств, которые могут способствовать возникновению проблемы.
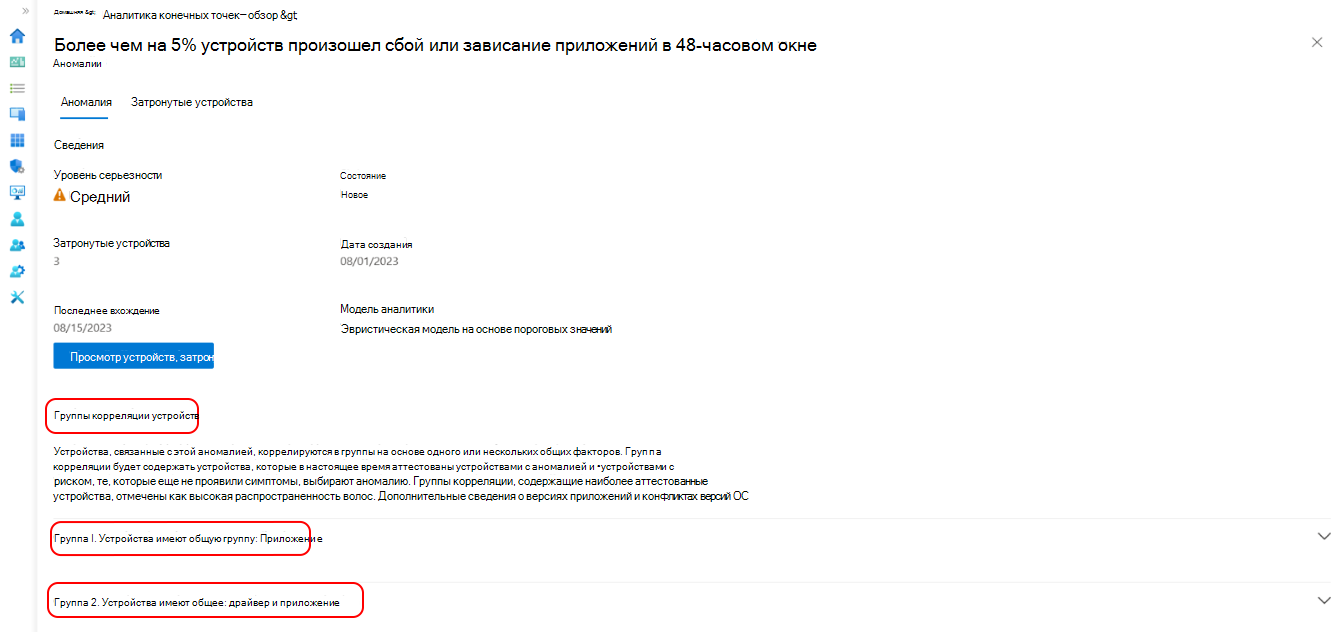
Выберите группу корреляции устройств в списке для подробного просмотра общих факторов устройств. Устройства сопоставляются на основе одного или нескольких общих атрибутов, таких как версия приложения, обновление драйвера, версия ОС и модель устройства. Вы можете увидеть количество устройств, затронутых аномалией в настоящее время, и устройств, подверженных риску возникновения аномалии. Коэффициент распространенности также показывает процент затронутых устройств из аномалии, которые являются членами группы корреляции.

Выберите Просмотреть затронутые устройства, чтобы отобразить список устройств с ключевыми атрибутами, относящимися к каждому устройству. Вы можете отфильтровать устройства в определенных группах корреляции или показать все устройства, затронутые этой аномалией в вашей организации. Кроме того, на временной шкале устройства отображаются более аномальные события.




Статистические модели для определения аномалий
Созданная аналитическая модель обнаруживает когорты устройств, сталкивающиеся с аномальным набором стоп-ошибок перезапусков и зависаний и сбоев приложений, которые требуют внимания администратора для устранения и устранения. Шаблоны, выявленные из журналов телеметрии и диагностики датчиков, определяют эти когорты устройств
Эвристическая модель на основе порогов. Эвристическая модель включает в себя установку одного или нескольких пороговых значений для зависания и сбоя приложения или остановки перезапусков ошибок. Устройства помечаются как аномальные, если в указанном выше пороговом значении есть нарушение. Модель проста, но эффективна; он подходит для устранения заметных или статических проблем с устройствами или их приложениями. В настоящее время пороговые значения предопределены без возможности настройки.
Модель парных T-тестов. Парные T-тесты — это математический метод, который сравнивает пары наблюдений в наборе данных и ищет статистически значимое расстояние между их средствами. Тесты используются для наборов данных, которые состоят из наблюдений, связанных друг с другом в некотором роде. Например, количество перезапусков stop error с того же устройства до и после изменения политики или аварийного завершения работы приложения на устройстве после обновления ОС (операционных систем).
Модель оценки населения Z. Статистические модели, основанные на оценке популяции Z, включают вычисление стандартного отклонения и среднего значения набора данных, а затем использование этих значений для определения аномальных точек данных. Стандартное отклонение и среднее используются для вычисления Z-оценки для каждой точки данных, которая представляет количество стандартных отклонений от среднего. Точки данных, которые выходят за пределы определенного диапазона, являются аномальными. Эта модель хорошо подходит для выделения выделяющихся устройств или приложений из более широких базовых показателей, но требует достаточно больших наборов данных, чтобы быть точными.
Модель оценки временных рядов Z. Модели оценки временных рядов Z являются разновидностью стандартной модели оценки Z, предназначенной для обнаружения аномалий в данных временных рядов. Данные временных рядов — это последовательность точек данных, собираемых через регулярные интервалы с течением времени, таких как совокупное число перезапусков stop error. Стандартное отклонение и среднее вычисляются для скользящего периода времени с использованием агрегированных метрик. Этот метод позволяет модели быть чувствительным к темпоральным шаблонам в данных и адаптироваться к изменениям в их распределении с течением времени.
Дальнейшие действия
Дополнительные сведения см. в статьях: