Сценарии вычислений таблиц и варианты использования
Существуют преимущества использования вычисляемых таблиц в потоке данных. В этой статье описываются варианты использования вычисляемых таблиц и описывается, как они работают за кулисами.
Что такое вычисляемая таблица?
Таблица представляет выходные данные запроса, созданного в потоке данных, после обновления потока данных. Он представляет данные из источника и, при необходимости, преобразования, которые были применены к нему. Иногда может потребоваться создать новые таблицы, которые являются функцией ранее приемной таблицы.
Хотя можно повторить запросы, которые создали таблицу и применить к ним новые преобразования, этот подход имеет недостатки: данные приемываются дважды, а нагрузка на источник данных удвоится.
Вычисляемая таблица решает обе проблемы. Вычисляемые таблицы похожи на другие таблицы, в которых они получают данные из источника, и вы можете применить дальнейшие преобразования для их создания. Но их данные исходят из используемого потока данных хранилища, а не исходного источника данных. То есть они были ранее созданы потоком данных, а затем повторно использовались.
Вычисляемые таблицы можно создать, ссылаясь на таблицу в одном потоке данных или ссылаясь на таблицу, созданную в другом потоке данных.

Зачем использовать вычисленную таблицу?
Выполнение всех шагов преобразования в одной таблице может быть медленным. Это может быть много причин замедления— источник данных может быть медленным, или преобразования, которые вы делаете, могут быть реплика в двух или более запросах. Может быть полезно сначала принять данные из источника, а затем повторно использовать их в одной или нескольких таблицах. В таких случаях можно создать две таблицы: одну, которая получает данные из источника данных, а другая — вычисляемая таблица, которая применяет дополнительные преобразования к данным, уже записанным в озеро данных, используемое потоком данных. Это изменение может повысить производительность и повторное использование данных, экономию времени и ресурсов.
Например, если две таблицы совместно используют даже часть логики преобразования без вычисляемой таблицы, преобразование должно выполняться дважды.
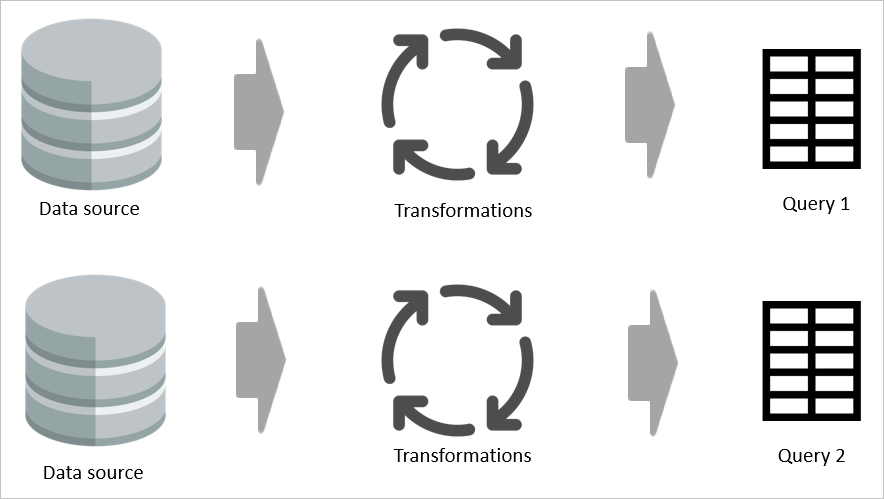
Однако если используется вычисленная таблица, общая (общая) часть преобразования обрабатывается один раз и сохраняется в Azure Data Lake служба хранилища. Затем остальные преобразования обрабатываются из выходных данных общего преобразования. В целом эта обработка гораздо быстрее.
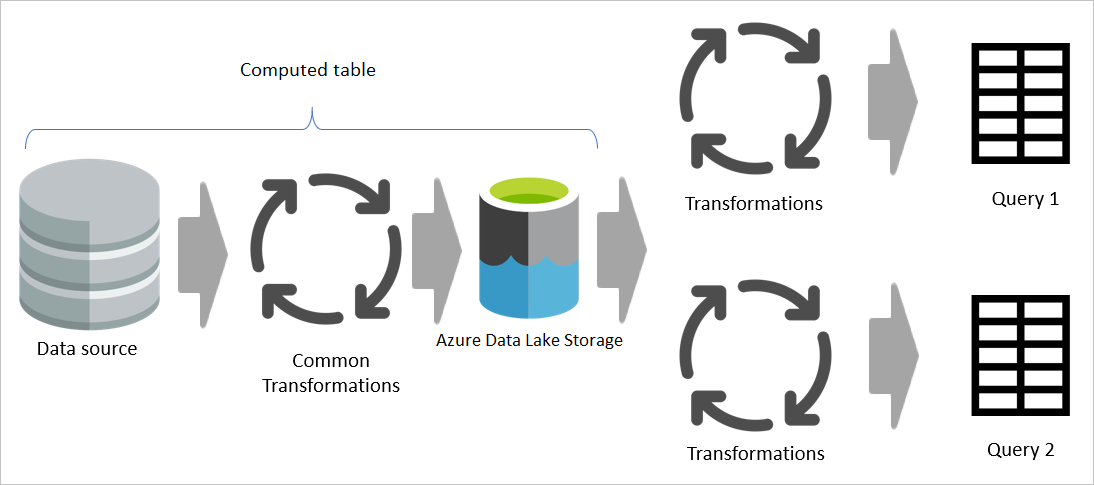
Вычисленная таблица предоставляет одно место в качестве исходного кода для преобразования и ускоряет преобразование, так как это необходимо сделать только один раз, а не несколько раз. Нагрузка на источник данных также уменьшается.
Пример сценария использования вычисляемой таблицы
Если вы создаете агрегированную таблицу в Power BI для ускорения модели данных, можно создать агрегированную таблицу, ссылаясь на исходную таблицу и применив к ней дополнительные преобразования. С помощью этого подхода вам не нужно реплика выполнять преобразование из источника (часть из исходной таблицы).
Например, на следующем рисунке показана таблица Orders.

Используя ссылку из этой таблицы, вы можете создать вычисленную таблицу.
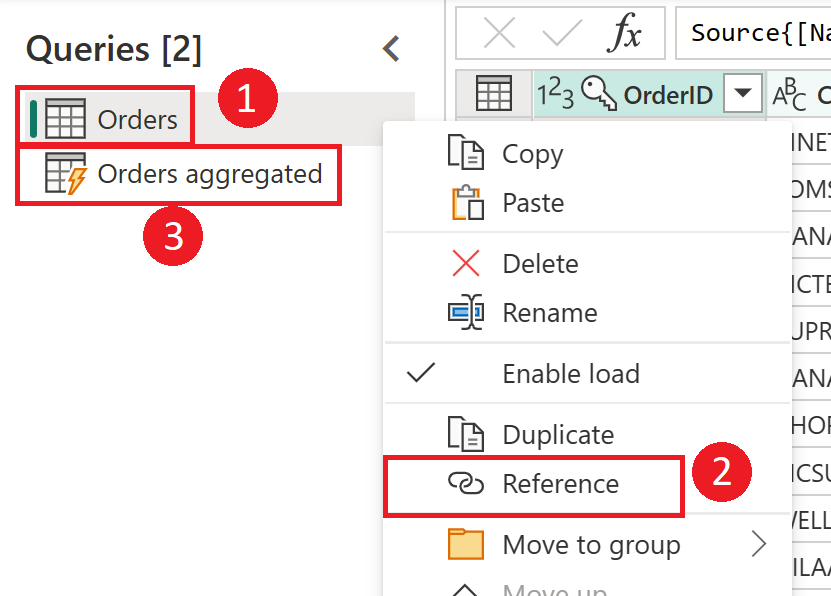
Снимок экрана: создание вычисляемой таблицы из таблицы Orders. Сначала щелкните правой кнопкой мыши таблицу "Заказы" в области "Запросы", выберите параметр "Ссылка" в раскрывающемся меню. Это действие создает вычисляемую таблицу, которая переименована здесь в "Заказы" с агрегированными данными.
Вычисляемая таблица может иметь дальнейшие преобразования. Например, можно использовать group By для агрегирования данных на уровне клиента.
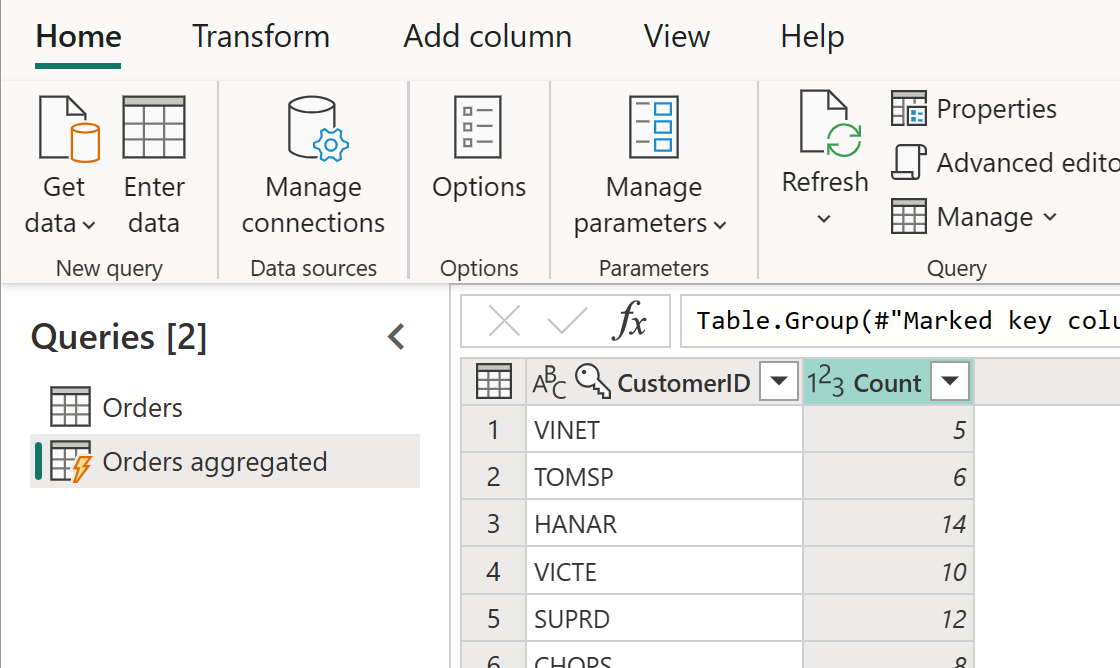
Это означает, что таблица "Агрегатные заказы" получает данные из таблицы "Заказы", а не из источника данных. Так как некоторые преобразования, которые необходимо выполнить, уже были выполнены в таблице "Заказы", производительность лучше, а преобразование данных выполняется быстрее.
Вычисляемая таблица в других потоках данных
Вы также можете создать вычисляемую таблицу в других потоках данных. Его можно создать, получив данные из потока данных с помощью соединителя потока данных Microsoft Power Platform.
Изображение подчеркивает соединитель потоков данных Power Platform из окна выбора источника данных Power Query. Также включается описание, которое указывает, что одна таблица потока данных может быть создана на основе данных из другой таблицы потока данных, которая уже сохраняется в хранилище.
Концепция вычисляемой таблицы заключается в сохранении таблицы в хранилище и других таблицах, полученных из нее, чтобы сократить время чтения из источника данных и предоставить общий доступ к некоторым общим преобразованиям. Это можно сделать, получая данные из других потоков данных через соединитель потока данных или ссылаясь на другой запрос в том же потоке данных.
Вычисляемая таблица: с преобразованиями или без нее?
Теперь, когда вы знаете, вычисляемые таблицы отлично подходят для повышения производительности преобразования данных, рекомендуется задать вопрос о том, следует ли всегда откладывать преобразования в вычисляемую таблицу или применять их к исходной таблице. То есть следует всегда принимать данные в одну таблицу, а затем преобразовывать в вычисляемую таблицу? Каковы плюсы и минусы?
Загрузка данных без преобразования для текстовых и CSV-файлов
Если источник данных не поддерживает свертывание запросов (например, текстовые или CSV-файлы), при получении данных из источника мало преимуществ, особенно если объемы данных большие. Исходная таблица должна просто загружать данные из текстового или CSV-файла без применения преобразований. Затем вычисляемые таблицы могут получать данные из исходной таблицы и выполнять преобразование поверх приема данных.
Вы можете спросить, каково значение создания исходной таблицы, которая использует только данные? Такая таблица по-прежнему может оказаться полезной, так как если данные из источника используются в нескольких таблицах, это снижает нагрузку на источник данных. Кроме того, теперь данные можно повторно использовать другими людьми и потоками данных. Вычисляемые таблицы особенно полезны в сценариях, когда объем данных велик или когда источник данных осуществляется через локальный шлюз данных, так как они снижают трафик из шлюза и нагрузку на источники данных за ними.
Выполнение некоторых распространенных преобразований для таблицы SQL
Если источник данных поддерживает свертывание запросов, то рекомендуется выполнить некоторые преобразования в исходной таблице, так как запрос сложен в источник данных, и из него извлекается только преобразованные данные. Эти изменения повышают общую производительность. Набор преобразований, распространенных в подчиненных вычисляемых таблицах, должен применяться в исходной таблице, поэтому их можно сложить в источник. Другие преобразования, которые применяются только к подчиненным таблицам, должны выполняться в вычисляемых таблицах.