Миграция из Batch AI в Службу машинного обучения Azure
Служба Azure Batch AI прекращает работу в марте. Возможности обучения и оценки службы Batch AI для масштабных развертываний теперь доступны в Службе машинного обучения Azure, которая стала общедоступной 4 декабря 2018 года.
Помимо множества других возможностей машинного обучения, Служба машинного обучения Azure включает облачный управляемый целевой объект вычислений для обучения, развертывания и оценки моделей машинного обучения. Этот целевой объект вычислений называется Вычислительная среда Машинного обучения Azure. Начните миграцию и перейдите к использованию уже сегодня. Вы можете взаимодействовать со Службой машинного обучения Azure через пакеты SDK для Python, интерфейс командной строки и портал Azure.
Обновление с предварительной версии Batch AI до общедоступной службы машинного обучения Azure обеспечивает улучшенные условия работы благодаря более простым в использовании принципам, таким как механизмы оценки и хранилища данных. При этом также гарантируется Соглашение об уровне обслуживания службы Azure и поддержка пользователей на уровне общедоступной версии.
Служба машинного обучения Azure также предоставляет новые функции, такие как автоматическое машинное обучение, настройка гиперпараметров, конвейеры машинного обучения, которые полезны в большинстве крупномасштабных рабочих нагрузок искусственного интеллекта. Способность развернуть обученную модель без перехода к отдельной службе позволяет завершить полный цикл обработки и анализа данных, начиная с подготовки данных (с помощью пакета SDK для подготовки данных) вплоть до ввода в эксплуатацию и мониторинга модели.
Запуск миграции
Чтобы избежать нарушений в работе приложений и использовать преимущества новейших функций, выполните следующие действия до 31 марта 2019 г.:
Создайте рабочую область Службы машинного обучения Azure и начните работу:
Установите пакет SDK для Машинного обучения Azure и пакет SDK для подготовки данных.
Настройте Вычислительную среду Машинного обучения Azure для обучения моделей.
Обновите скрипты для использования Вычислительной среды Машинного обучения Azure. В следующих разделах показано, как общий код, который вы используете для Batch AI, сопоставляется с кодом для Машинного обучения Azure.
Создание рабочих областей
Принцип инициализации рабочей области с помощью файла configuration.json в Azure Batch AI аналогичным образом сопоставляется с принципом использования файла конфигурации в Службе машинного обучения Azure.
Для Batch AI это выполняется следующим образом:
sys.path.append('../../..')
import utilities as utils
cfg = utils.config.Configuration('../../configuration.json')
client = utils.config.create_batchai_client(cfg)
utils.config.create_resource_group(cfg)
_ = client.workspaces.create(cfg.resource_group, cfg.workspace, cfg.location).result()
В Службе машинного обучения Azure попробуйте следующее:
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
print('Workspace name: ' + ws.name,
'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
Кроме того, вы также можете создать рабочую область непосредственно, указав такие параметры конфигурации:
from azureml.core import Workspace
# Create the workspace using the specified parameters
ws = Workspace.create(name = workspace_name,
subscription_id = subscription_id,
resource_group = resource_group,
location = workspace_region,
create_resource_group = True,
exist_ok = True)
ws.get_details()
# write the details of the workspace to a configuration file to the notebook library
ws.write_config()
Дополнительные сведения о классе рабочей области машинного обучения Azure см. в справочной документации для пакета SDK.
Создание вычислительных кластеров
Машинное обучение Azure поддерживает несколько целевых объектов вычислений, некоторыми из которых управляет служба и другие пользователи, которые можно подключить к рабочей области (например, кластер HDInsight или удаленную виртуальную машину). Дополнительные сведения о различных целевых объектах вычислений см. в этой статье. Принцип создания вычислительного кластера Azure Batch AI сопоставляется с принципом создания кластера AmlCompute в Службе машинного обучения Azure. При создании Amlcompute конфигурация вычислений принимается аналогично тому, как передаются параметры в Azure Batch AI. Следует отметить, что автоматическое масштабирование включено в кластере AmlCompute по умолчанию, в то время как оно по умолчанию отключено в Azure Batch AI.
Для Batch AI это выполняется следующим образом:
nodes_count = 2
cluster_name = 'nc6'
parameters = models.ClusterCreateParameters(
vm_size='STANDARD_NC6',
scale_settings=models.ScaleSettings(
manual=models.ManualScaleSettings(target_node_count=nodes_count)
),
user_account_settings=models.UserAccountSettings(
admin_user_name=cfg.admin,
admin_user_password=cfg.admin_password or None,
admin_user_ssh_public_key=cfg.admin_ssh_key or None,
)
)
_ = client.clusters.create(cfg.resource_group, cfg.workspace, cluster_name, parameters).result()
В Службе машинного обучения Azure попробуйте:
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# Choose a name for your CPU cluster
gpu_cluster_name = "nc6"
# Verify that cluster does not exist already
try:
gpu_cluster = ComputeTarget(workspace=ws, name=gpu_cluster_name)
print('Found existing cluster, use it.')
except ComputeTargetException:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_NC6',
vm_priority='lowpriority',
min_nodes=1,
max_nodes=2,
idle_seconds_before_scaledown='300',
vnet_resourcegroup_name='<my-resource-group>',
vnet_name='<my-vnet-name>',
subnet_name='<my-subnet-name>')
gpu_cluster = ComputeTarget.create(ws, gpu_cluster_name, compute_config)
gpu_cluster.wait_for_completion(show_output=True)
Дополнительные сведения о классе AMLCompute см. в справочной документации для пакета SDK. Обратите внимание, что в приведенной выше конфигурации только свойства vm_size и max_nodes являются обязательными, а остальные свойства, такие как виртуальные сети, предназначены только для расширенной установки кластера.
Мониторинг состояния кластера
Как можно будет увидеть ниже, осуществлять мониторинг в Службе машинного обучения Azure гораздо проще.
Для Batch AI это выполняется следующим образом:
cluster = client.clusters.get(cfg.resource_group, cfg.workspace, cluster_name)
utils.cluster.print_cluster_status(cluster)
В Службе машинного обучения Azure попробуйте:
gpu_cluster.get_status().serialize()
Получение ссылки на учетную запись хранения
Понятие хранилища данных, такого как большой двоичный объект, упрощено в Службе машинного обучения Azure с помощью объекта DataStore. По умолчанию рабочая область Службы машинного обучения Azure создает учетную запись хранения, но вы можете также подключить собственное хранилище в ходе создания рабочей области.
Для Batch AI это выполняется следующим образом:
azure_blob_container_name = 'batchaisample'
blob_service = BlockBlobService(cfg.storage_account_name, cfg.storage_account_key)
blob_service.create_container(azure_blob_container_name, fail_on_exist=False)
В Службе машинного обучения Azure попробуйте:
ds = ws.get_default_datastore()
print(ds.datastore_type, ds.account_name, ds.container_name)
Подробнее о регистрации дополнительных учетных записей хранения или получении ссылки на другое зарегистрированное хранилище данных см. в документации по Службе машинного обучения Azure.
Загрузка и отправка данных
С помощью любой из этих служб вы можете легко отправить данные в учетную запись хранения с помощью ссылки на хранилище данных выше. В Azure Batch AI мы также развертываем обучающий скрипт как часть общей папки, хотя вы увидите, что в случае со Службой машинного обучения Azure его можно указать при конфигурации задания.
Для Batch AI это выполняется следующим образом:
mnist_dataset_directory = 'mnist_dataset'
utils.dataset.download_and_upload_mnist_dataset_to_blob(
blob_service, azure_blob_container_name, mnist_dataset_directory)
script_directory = 'tensorflow_samples'
script_to_deploy = 'mnist_replica.py'
blob_service.create_blob_from_path(azure_blob_container_name,
script_directory + '/' + script_to_deploy,
script_to_deploy)
В Службе машинного обучения Azure попробуйте:
import os
import urllib
os.makedirs('./data', exist_ok=True)
download_url = 'https://s3.amazonaws.com/img-datasets/mnist.npz'
urllib.request.urlretrieve(download_url, filename='data/mnist.npz')
ds.upload(src_dir='data', target_path='mnist_dataset', overwrite=True, show_progress=True)
path_on_datastore = ' mnist_dataset/mnist.npz' ds_data = ds.path(path_on_datastore) print(ds_data)
Создание экспериментов
Как упоминалось выше, в Службе машинного обучения Azure, как и в Azure Batch AI, используется понятие эксперимента. Каждый эксперимент выполняется отдельно, аналогично тому, как выполняются задания в Azure Batch AI. При каждом родительском выполнении в Службе машинного обучения Azure также разрешены иерархии для отдельных дочерних выполнений.
Для Batch AI это выполняется следующим образом:
experiment_name = 'tensorflow_experiment'
experiment = client.experiments.create(cfg.resource_group, cfg.workspace, experiment_name).result()
В Службе машинного обучения Azure попробуйте:
from azureml.core import Experiment
experiment_name = 'tensorflow_experiment'
experiment = Experiment(ws, name=experiment_name)
Отправка заданий
Создав эксперимент, вы можете запустить выполнение несколькими разными способами. В этом примере предпринимается попытка создания модели глубокого обучения с помощью TensorFlow, для этого будет использоваться механизм оценки Службы машинного обучения Azure. Механизм оценки — это просто функция оболочки базовой конфигурации выполнения, упрощающая отправку выполнений, и в настоящее время поддерживается только для Pytorch и TensorFlow. Ознакомившись с понятием хранилища данных, вы также увидите, как легко указать пути подключения.
Для Batch AI это выполняется следующим образом:
azure_file_share = 'afs'
azure_blob = 'bfs'
args_fmt = '--job_name={0} --num_gpus=1 --train_steps 10000 --checkpoint_dir=$AZ_BATCHAI_OUTPUT_MODEL --log_dir=$AZ_BATCHAI_OUTPUT_TENSORBOARD --data_dir=$AZ_BATCHAI_INPUT_DATASET --ps_hosts=$AZ_BATCHAI_PS_HOSTS --worker_hosts=$AZ_BATCHAI_WORKER_HOSTS --task_index=$AZ_BATCHAI_TASK_INDEX'
parameters = models.JobCreateParameters(
cluster=models.ResourceId(id=cluster.id),
node_count=2,
input_directories=[
models.InputDirectory(
id='SCRIPT',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, script_directory)),
models.InputDirectory(
id='DATASET',
path='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}/{1}'.format(azure_blob, mnist_dataset_directory))],
std_out_err_path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
output_directories=[
models.OutputDirectory(
id='MODEL',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Models'),
models.OutputDirectory(
id='TENSORBOARD',
path_prefix='$AZ_BATCHAI_JOB_MOUNT_ROOT/{0}'.format(azure_file_share),
path_suffix='Logs')
],
mount_volumes=models.MountVolumes(
azure_file_shares=[
models.AzureFileShareReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
azure_file_url='https://{0}.file.core.windows.net/{1}'.format(
cfg.storage_account_name, azure_file_share_name),
relative_mount_path=azure_file_share)
],
azure_blob_file_systems=[
models.AzureBlobFileSystemReference(
account_name=cfg.storage_account_name,
credentials=models.AzureStorageCredentialsInfo(
account_key=cfg.storage_account_key),
container_name=azure_blob_container_name,
relative_mount_path=azure_blob)
]
),
container_settings=models.ContainerSettings(
image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.8.0-gpu')),
tensor_flow_settings=models.TensorFlowSettings(
parameter_server_count=1,
worker_count=nodes_count,
python_script_file_path='$AZ_BATCHAI_INPUT_SCRIPT/'+ script_to_deploy,
master_command_line_args=args_fmt.format('worker'),
worker_command_line_args=args_fmt.format('worker'),
parameter_server_command_line_args=args_fmt.format('ps'),
)
)
Отправка задания в Azure Batch AI выполняется с помощью функции создания.
job_name = datetime.utcnow().strftime('tf_%m_%d_%Y_%H%M%S')
job = client.jobs.create(cfg.resource_group, cfg.workspace, experiment_name, job_name, parameters).result()
print('Created Job {0} in Experiment {1}'.format(job.name, experiment.name))
Полные сведения для этого фрагмента кода для обучения (в том числе файл mnist_replica.py, который мы отправляли в общую папку выше) можно найти в репозитории GitHub с примером записной книжки Azure Batch AI.
В Службе машинного обучения Azure попробуйте:
from azureml.train.dnn import TensorFlow
script_params={
'--num_gpus': 1,
'--train_steps': 500,
'--input_data': ds_data.as_mount()
}
estimator = TensorFlow(source_directory=project_folder,
compute_target=gpu_cluster,
script_params=script_params,
entry_script='tf_mnist_replica.py',
node_count=2,
worker_count=2,
parameter_server_count=1,
distributed_backend='ps',
use_gpu=True)
Полные сведения для этого фрагмента кода для обучения (в том числе файл mnist_replica.py) можно найти в репозитории GitHub с примером записной книжки Службы машинного обучения Azure. Само хранилище данных можно установить на отдельных узлах, или же данные для обучения можно скачать на сам узел. Дополнительные сведения о ссылках на хранилище данных механизма оценки см. в документации Службы машинного обучения Azure.
Отправка выполнения в Службе машинного обучения Azure осуществляется с помощью функции отправки.
run = experiment.submit(estimator)
print(run)
Есть еще один способ указания параметров для выполнения — с помощью выполнения конфигурации. Это особенно полезно для определения пользовательской обучающей среды. Дополнительные сведения см. в этом примере записной книжки AmlCompute.
Отслеживание выполнений
После отправки выполнения вы можете или дождаться выполнения, или отслеживать его в Службе машинного обучения Azure с помощью мини-приложений Jupyter, которые можно вызывать непосредственно из кода. Вы также можете извлекать контекст из любого предыдущего выполнения путем различных экспериментов с рабочей областью и отдельных выполнений в рамках каждого эксперимента.
Для Batch AI это выполняется следующим образом:
utils.job.wait_for_job_completion(client, cfg.resource_group, cfg.workspace,
experiment_name, job_name, cluster_name, 'stdouterr', 'stdout-wk-0.txt')
files = client.jobs.list_output_files(cfg.resource_group, cfg.workspace, experiment_name, job_name,
models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr'))
for f in list(files):
print(f.name, f.download_url or 'directory')
В Службе машинного обучения Azure попробуйте:
run.wait_for_completion(show_output=True)
from azureml.widgets import RunDetails
RunDetails(run).show()
Ниже приведен snapshot того, как мини-приложение будет загружаться в записную книжку для просмотра журналов в режиме реального времени: 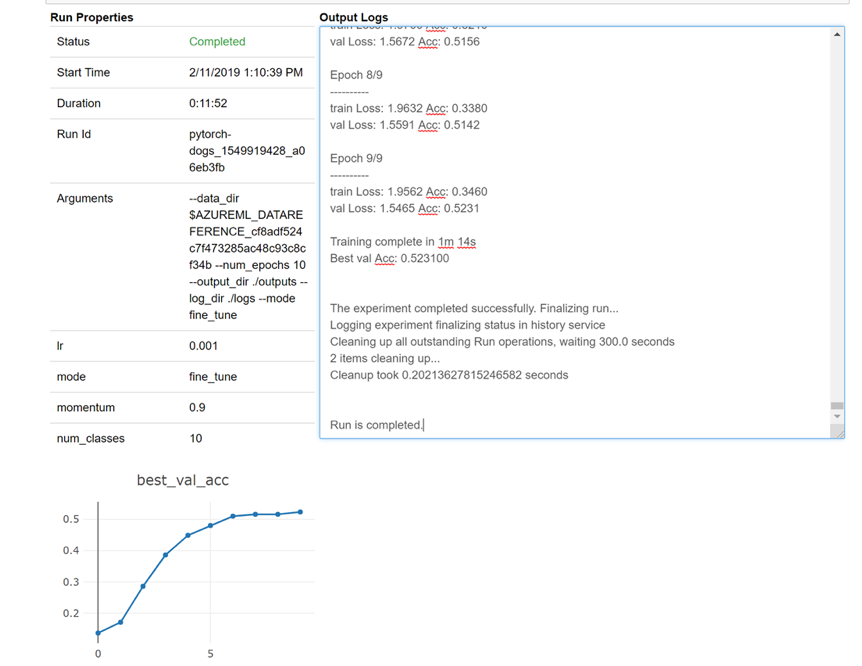
Изменение кластеров
Кластер можно легко удалить. Кроме того, Служба машинного обучения Azure позволяет обновить кластер в рамках записной книжки, если вы хотите масштабировать его на большее количество узлов или увеличить время ожидания простоя перед уменьшением масштаба кластера. Изменять размер кластера виртуальной машины запрещено, так как для этого в серверной части потребуется новое развертывание.
Для Batch AI это выполняется следующим образом:
_ = client.clusters.delete(cfg.resource_group, cfg.workspace, cluster_name)
В Службе машинного обучения Azure попробуйте:
gpu_cluster.delete()
gpu_cluster.update(min_nodes=2, max_nodes=4, idle_seconds_before_scaledown=600)
Техническая поддержка
Пакетный ИИ планируется прекратить поддержку 31 марта и уже блокирует регистрацию новых подписок в службе, если она не включена в список разрешенных, вызвав исключение через поддержку. Свяжитесь с нами на сайте предварительной версии обучения Azure Batch AI, чтобы задать любые вопросы или чтобы оставить отзывы о миграции в Службу машинного обучения Azure.
Выпущена общедоступная версия Службы машинного обучения Azure. Это означает, что она поставляется с зафиксированным Соглашением об уровне обслуживания и различными планами поддержки на выбор.
Цены на использование инфраструктуры Azure с помощью службы пакетная служба Azure ИИ или службы машинного обучения Azure не должны меняться, так как в обоих случаях плата взимается только за базовые вычислительные ресурсы. Дополнительные сведения см. на странице калькулятора цен.
Сведения о региональной доступности двух служб см. на портале Azure.
Дальнейшие действия
Ознакомьтесь со статьей Что такое Служба машинного обучения Azure.
Настройте целевой объект вычислений для обучения моделей с помощью Службы машинного обучения Azure.
Просмотрите стратегию развития Azure, чтобы узнать о других обновлениях служб Azure.