Сканирование и прием в Microsoft Purview
В этой статье приводятся общие сведения о функциях сканирования и приема в Microsoft Purview. Эти функции подключают учетную запись Microsoft Purview к источникам, чтобы заполнить карту данных и Единый каталог, чтобы вы могли приступить к изучению данных и управлению ими с помощью Microsoft Purview.
- Сканирование захватывает метаданные из источников данных и переносит их в Microsoft Purview.
-
Прием обрабатывает метаданные и сохраняет их в Единый каталог из обоих:
- Проверка источников данных — в Схема данных Microsoft Purview добавляются отсканированные метаданные.
- Связи происхождения. Ресурсы преобразования добавляют метаданные о своих источниках, выходных данных и действиях в Схема данных Microsoft Purview.
Сканирование
После регистрации источников данных в учетной записи Microsoft Purview следующим шагом будет проверка источников данных. Процесс сканирования устанавливает подключение к источнику данных и записывает технические метаданные, такие как имена, размер файла, столбцы и т. д. Он также извлекает схему для структурированных источников данных, применяет классификации к схемам и применяет метки конфиденциальности, если Схема данных Microsoft Purview подключен к Портал соответствия требованиям Microsoft Purview. Процесс сканирования можно запустить немедленно или запланировать периодический запуск для поддержания актуальности учетной записи Microsoft Purview.
Для каждой проверки существуют настройки, которые можно применить, чтобы проверять только необходимые сведения, а не весь источник.
Выбор метода проверки подлинности для проверок
По умолчанию Microsoft Purview защищен. Пароли или секреты не хранятся непосредственно в Microsoft Purview, поэтому вам нужно выбрать метод проверки подлинности для источников. Существует несколько способов проверки подлинности учетной записи Microsoft Purview, но для каждого источника данных поддерживаются не все методы.
- Управляемое удостоверение
- Субъект-служба
- Проверка подлинности SQL
- Проверка подлинности Windows
- Роль ARN
- Делегированная проверка подлинности
- Ключ потребителя
- Ключ учетной записи или обычная проверка подлинности
По возможности управляемое удостоверение является предпочтительным методом проверки подлинности, так как он устраняет необходимость хранения учетных данных и управления ими для отдельных источников данных. Это может значительно сократить время, затрачивается на настройку и устранение неполадок проверки подлинности для проверок. При включении управляемого удостоверения для учетной записи Microsoft Purview удостоверение создается в Microsoft Entra ID и привязано к жизненному циклу учетной записи.
Область сканирования
При сканировании источника можно выбрать весь источник данных или выбрать только определенные сущности (папки или таблицы). Доступные параметры зависят от источника, который вы сканируете, и могут быть определены как для однократных, так и для запланированных проверок.
Например, при создании и выполнении проверки базы данных Azure SQL можно выбрать таблицы для сканирования или выбрать всю базу данных.
Для каждой сущности (папки или таблицы) будет три состояния выделения: полностью выбрано, частично выбрано и не выбрано. В приведенном ниже примере при выборе "Отдел 1" в иерархии папок "Отдел 1" считается полностью выбранным. Родительские сущности для "Отдел 1", такие как "Компания" и "пример", считаются частично выбранными, так как в этом же родительском элементе не выбраны другие сущности, например "Отдел 2". Различные значки будут использоваться в пользовательском интерфейсе для сущностей с разными состояниями выделения.
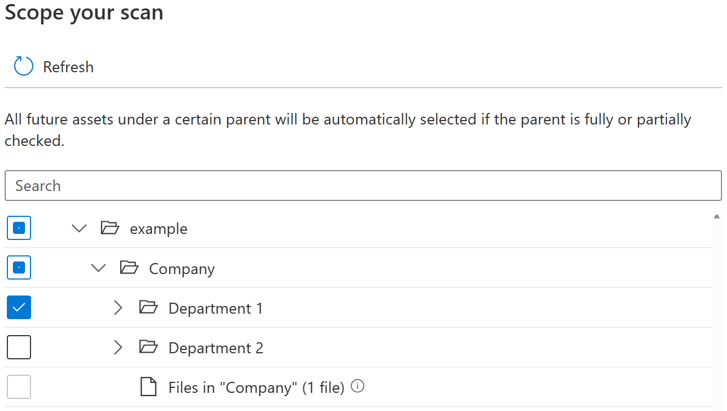
После выполнения проверки в исходной системе, скорее всего, будут добавлены новые ресурсы. По умолчанию будущие ресурсы под определенным родительским элементом будут выбраны автоматически, если родительский элемент выбран полностью или частично при повторном запуске проверки. В приведенном выше примере после выбора "Отдел 1" и выполнения проверки все новые ресурсы в папке "Отдел 1" или в разделе "Компания" и "Пример" будут включены при повторном запуске сканирования.
Для пользователей появилась кнопка переключения, чтобы управлять автоматическим включением новых ресурсов под частично выбранным родительским элементом. По умолчанию переключатель будет отключен, а автоматическое включение для частично выбранного родительского элемента будет отключено. В том же примере с выключенным переключателем все новые ресурсы с частично выбранными родителями, такими как "Компания" и "пример", не будут включаться при повторном запуске сканирования, в будущем будут включены только новые ресурсы в разделе "Отдел 1".
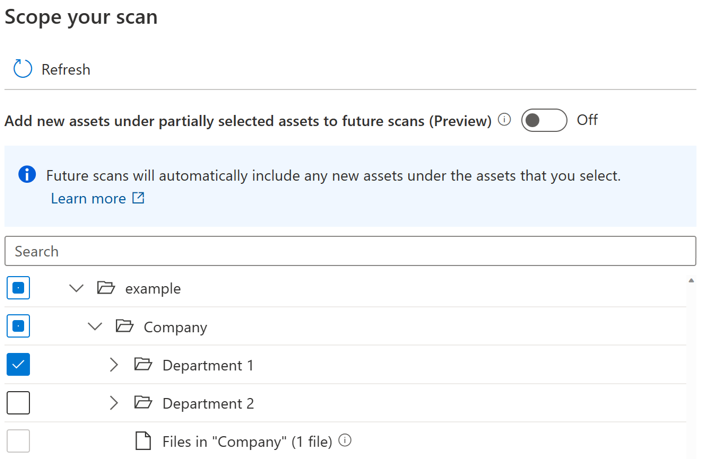
Если переключатель включен, при повторном запуске проверки будут автоматически выбраны новые ресурсы под определенным родительским элементом. Поведение включения такое же, как и перед вводом переключателя.
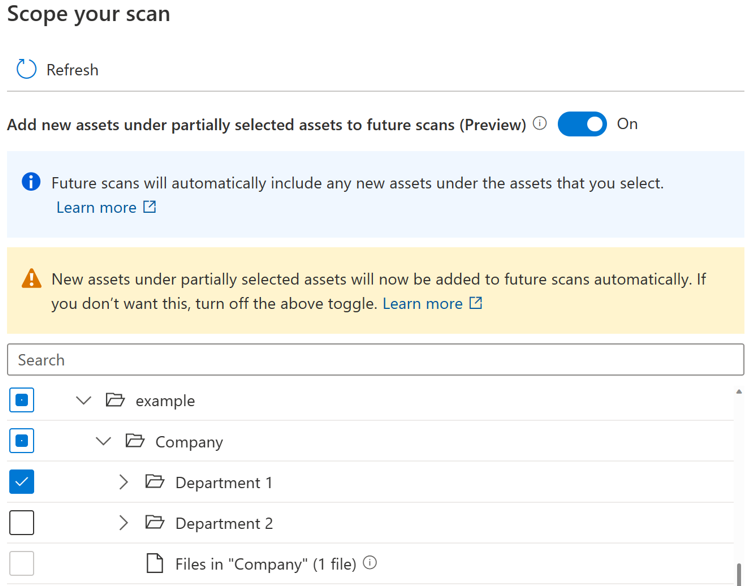
Примечание.
- Доступность переключателя зависит от типа источника данных. В настоящее время он доступен в общедоступной предварительной версии для источников, включая Хранилище BLOB-объектов Azure, Azure Data Lake Storage 1-го поколения, Azure Data Lake Storage 2-го поколения, Файлы Azure и выделенный пул SQL Azure (ранее — хранилище данных SQL).
- Для всех проверок, созданных или запланированных до появления переключателя, состояние переключателя устанавливается как включено и не может быть изменено. Для любых проверок, созданных или запланированных после ввода переключателя, состояние переключателя нельзя изменить после сохранения сканирования. Чтобы изменить состояние переключателя, необходимо создать новую проверку.
- Если кнопка переключения отключена, для источников типа хранилища, таких как Azure Data Lake Storage 2-го поколения, может потребоваться до 4 часов, прежде чем интерфейс просмотра по исходному типу станет полностью доступным после завершения задания сканирования.
Известные ограничения
Если переключатель отключен, выполните следующие действия:
- Сущности файлов в частично выбранном родительском элементе не будут проверяться.
- Если все существующие сущности в родительском элементе выбраны явным образом, родительский элемент считается полностью выбранным, а все новые ресурсы в родительском элементе будут включены при повторном запуске проверки.
Настройка уровня сканирования
В Схема данных Microsoft Purview терминологии существует три разных уровня сканирования в зависимости от область метаданных и функциональных возможностей:
- Проверка L1: извлекает основные сведения и метаданные, такие как имя файла, размер и полное имя.
- Проверка L2: извлекает схему для структурированных типов файлов и таблиц баз данных
- Проверка L3: извлекает схему, если это применимо, и подвергает выборку файла системным и пользовательским правилам классификации.
При настройке новой проверки или изменении существующей проверки можно настроить уровень сканирования для источников данных, которые уже поддерживали конфигурацию уровня сканирования.
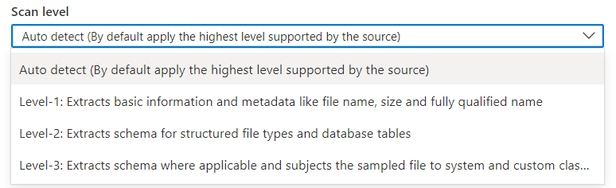
По умолчанию будет выбран параметр "Автоматическое обнаружение", что означает, что Microsoft Purview будет применять самый высокий уровень сканирования, доступный для этого источника данных. Возьмем Azure SQL базе данных в качестве примера, если проверка выполняется, так как источник данных уже поддерживает классификацию в Microsoft Purview, будет разрешаться как уровень 3. Уровень сканирования в подробных сведениях о выполнении проверки показывает фактический примененный уровень.
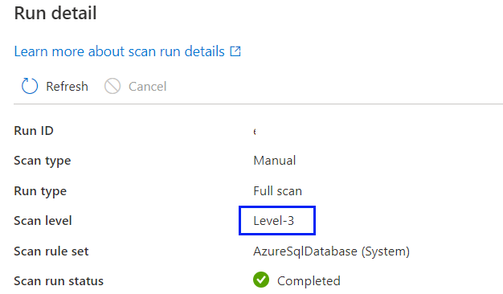
Для всех запусков сканирования в журнале сканирования, которые были завершены до настройки уровня сканирования по мере появления новой функции, по умолчанию уровень сканирования будет установлен и отображается как "Автоматическое обнаружение".
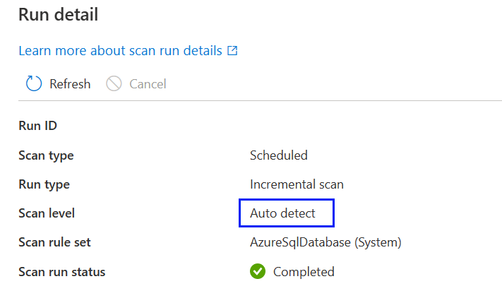
- Когда для источника данных становится доступен более высокий уровень сканирования, сохраненные или запланированные проверки, для которых задан уровень сканирования "Автоматическое обнаружение", автоматически применяют новый уровень сканирования. Например, если для данного источника данных включена классификация как новая функция, все существующие проверки этого источника данных будут применять классификацию автоматически.
- Параметр уровня сканирования отображается в интерфейсе мониторинга сканирования для каждого запуска сканирования.
- Если выбран параметр "Уровень 1", при проверке будут возвращены только базовые технические метаданные, такие как имя ресурса, размер ресурса, измененная метка времени и т. д., в зависимости от доступности метаданных определенного источника данных. Для базы данных Azure SQL сущности активов, такие как таблицы, будут создаваться в Схема данных Microsoft Purview но без извлечения схемы таблицы. (Примечание. Пользователи по-прежнему могут просматривать схему таблицы в режиме реального времени, если у них есть необходимые разрешения в исходной системе.
- Если выбран параметр "Уровень 2", при проверке будут возвращены схемы таблиц и базовые технические метаданные, но выборка и классификация данных не будут выполняться. Для базы данных Azure SQL сущности табличных активов имеют схему таблицы, записанную без сведений о классификации.)
- Если выбран "Уровень 3", при проверке будут выполняться выборка и классификация данных. Это стандартная конфигурация для Azure SQL проверки базы данных перед уровнем сканирования в качестве новой функции.
- Если запланированное сканирование задано на более низкий уровень, а затем изменено на более высокий уровень сканирования, то следующий запуск проверки автоматически выполнит полную проверку, а все существующие ресурсы данных из источника данных будут обновлены с помощью метаданных, введенных более высоким уровнем сканирования. Например, если запланированное сканирование с "Уровнем 2" в базе данных Azure SQL изменено на "Уровень 3", следующий запуск проверки будет полным, и все существующие ресурсы таблицы или представления базы данных Azure SQL будут обновлены с помощью сведений о классификации, а все проверки после этого будут возобновлены как добавочные проверки, заданные на уровне 3.
- Если запланированное сканирование задано на более высокий уровень, а затем изменено на более низкий уровень сканирования, то при следующем запуске будет по-прежнему выполняться добавочное сканирование, а все новые ресурсы данных из источника данных будут содержать только метаданные, представленные параметром более низкого уровня сканирования. Например, если запланированное сканирование с параметром "Уровень 3" в базе данных Azure SQL изменено на "Уровень-2", следующий запуск проверки будет добавочным, а все новые ресурсы таблицы и представления базы данных Azure SQL, добавленные в Схема данных Microsoft Purview, не будут содержать сведений о классификации. Все существующие ресурсы данных по-прежнему будут хранить сведения о классификации, созданные из предыдущего набора сканирования с уровнем 3.
Примечание.
- Настройка уровня сканирования в настоящее время доступна для следующих источников данных: Azure SQL Database, Управляемый экземпляр SQL Azure, Azure Cosmos DB для NoSQL, База данных Azure для PostgreSQL; База данных Azure для MySQL, Azure Data Lake Storage 2-го поколения, Хранилище BLOB-объектов Azure, Файлы Azure, Azure Synapse Analytics, выделенный пул SQL Azure (прежнее название — хранилище данных SQL), Azure Data Explorer, Dataverse, Azure Multiple (подписка Azure), Azure Multiple (группа ресурсов Azure), Snowflake, Каталог Azure Databricks Unity
- В настоящее время эта функция доступна только в Azure IR и Управляемой виртуальной сети IR версии 2.
Набор правил сканирования
Набор правил сканирования определяет типы сведений, которые поиск выполняется при выполнении проверки в одном из источников. Доступные правила зависят от типа проверяемого источника, но включают такие параметры, как типы файлов , которые следует сканировать, и необходимые типы классификаций .
Существуют наборы правил проверки системы , которые уже доступны для многих типов источников данных, но вы также можете создать собственные наборы правил проверки , чтобы адаптировать сканирование к вашей организации.
Планирование сканирования
Microsoft Purview предоставляет возможность ежедневного, еженедельного или ежемесячного сканирования в определенное время. Дополнительные сведения о поддерживаемых параметрах расписания. Ежедневное или еженедельное сканирование может подходить для источников данных со структурами, которые активно разрабатываются или часто изменяются. Ежемесячное сканирование лучше подходит для источников данных, которые изменяются нечасто. Рекомендуется работать с администратором источника, который вы хотите проверить, чтобы определить время, когда требования к вычислительным ресурсам для источника низкие.
Как сканирование обнаруживает удаленные ресурсы
Каталог Microsoft Purview знает о состоянии хранилища данных только при выполнении проверки. Чтобы каталог знал, был ли удален файл, таблица или контейнер, он сравнивает последние выходные данные сканирования с текущими выходными данными сканирования. Например, предположим, что при последнем сканировании учетной записи Azure Data Lake Storage 2-го поколения она включала папку с именем folder1. При повторном сканировании той же учетной записи папка 1 отсутствует. Таким образом, каталог предполагает, что папка была удалена.
Совет
Из-за обнаружения удаленных файлов для обнаружения и разрешения удаленных ресурсов может потребоваться несколько успешных проверок. Если Единый каталог не регистрирует удаления для сканирования с заданной областью, попробуйте выполнить несколько полных проверок, чтобы устранить проблему.
Обнаружение удаленных файлов
Логика обнаружения отсутствующих файлов работает для нескольких проверок одного и того же пользователя и разных пользователей. Например, предположим, что пользователь выполняет однократное сканирование в Data Lake Storage 2-го поколения хранилище данных в папках A, B и C. Позже другой пользователь в той же учетной записи выполняет разовую проверку папок C, D и E одного хранилища данных. Так как папка C сканировалась дважды, каталог проверяет ее на наличие возможных удалений. Однако папки A, B, D и E сканировались только один раз, и каталог не будет проверка их на наличие удаленных ресурсов.
Чтобы удалить удаленные файлы из каталога, важно выполнять регулярные проверки. Интервал сканирования важен, так как каталог не может обнаружить удаленные ресурсы, пока не будет выполнена другая проверка. Таким образом, при выполнении проверок раз в месяц в определенном хранилище каталог не сможет обнаружить удаленные ресурсы данных в этом хранилище, пока не будет выполнена следующая проверка через месяц.
При перечислении больших хранилищ данных, таких как Data Lake Storage 2-го поколения, существует несколько способов (включая ошибки перечисления и удаленные события) пропускать информацию. При определенной проверке может пропустить, что файл был создан или удален. Таким образом, если каталог не уверен, что файл был удален, он не удалит его из каталога. Эта стратегия означает, что могут возникнуть ошибки, если файл, который не существует в сканированном хранилище данных, по-прежнему существует в каталоге. В некоторых случаях хранилище данных может потребоваться проверить два или три раза, прежде чем оно перехватывает некоторые удаленные ресурсы.
Примечание.
- Ресурсы, помеченные для удаления, удаляются после успешной проверки. Удаленные ресурсы могут оставаться видимыми в каталоге в течение некоторого времени, прежде чем они будут обработаны и удалены.
- Обнаружение удаления поддерживается только для следующих источников в Microsoft Purview: рабочие области Azure Synapse Analytics, SQL Server с поддержкой Azure Arc, Хранилище BLOB-объектов Azure, Файлы Azure, Azure Cosmos DB, Azure Data Explorer. База данных Azure для MySQL, База данных Azure для PostgreSQL, выделенный пул SQL Azure, Машинное обучение Azure, база данных Azure SQL и Управляемый экземпляр Azure SQL. Для этих источников при удалении ресурса из источника данных последующие проверки автоматически удаляют соответствующие метаданные и происхождение в Microsoft Purview.
Проглатывание
Прием — это процесс, отвечающий за заполнение карты данных метаданными, собранными с помощью различных процессов.
Прием из сканирований
Затем технические метаданные или классификации, определенные процессом сканирования, отправляются в прием. При приеме анализируются входные данные из сканирования, применяются шаблоны набора ресурсов, заполняются доступные сведения о происхождении , а затем автоматически загружается карта данных. Ресурсы и схемы можно обнаружить или курировать только после завершения приема. Таким образом, если проверка завершена, но ресурсы не отображаются в схеме данных или каталоге, необходимо дождаться завершения процесса приема.
Прием данных из подключений к происхождению
Такие ресурсы, как Фабрика данных Azure и Azure Synapse, можно подключить к Microsoft Purview, чтобы перенести источник данных и сведения о происхождении данных в Схема данных Microsoft Purview. Например, когда конвейер копирования выполняется в Фабрика данных Azure, подключенном к Microsoft Purview, метаданные об источниках входных данных, действиях и выходных источниках помечаются в Microsoft Purview, а сведения добавляются в карту данных.
Если источник данных уже был добавлен в карту данных с помощью сканирования, сведения о происхождении данных о действии будут добавлены в существующий источник. Если источник данных еще не добавлен в карту данных, процесс приема данных добавляет его в корневую коллекцию со сведениями о происхождении.
Дополнительные сведения о доступных подключениях к происхождению данных см. в руководстве пользователя по происхождению данных.
Дальнейшие действия
Дополнительные сведения или инструкции по проверке источников см. по ссылкам ниже.
- Сведения о наборах ресурсов см. в нашей статье о наборах ресурсов.
- Управление базой данных Azure SQL
- Происхождение происхождения в Microsoft Purview