Работа экземпляра отказоустойчивого кластера RHEL для SQL Server
Область применения:![]() SQL Server — Linux
SQL Server — Linux
В этом документе описывается выполнение следующих задач для SQL Server в отказоустойчивом кластере общих дисков с Red Hat Enterprise Linux.
- Отработка отказа кластера вручную
- Мониторинг службы отказоустойчивого кластера SQL Server
- Добавление узла кластера
- Удаление узла кластера
- Изменение частоты мониторинга ресурсов SQL Server
Описание архитектуры
Уровень кластеризации основан на надстройке высокого уровня доступности Red Hat Enterprise Linux (RHEL), созданной на базе Pacemaker. Corosync и Pacemaker координируют обмен данными и управление ресурсами. Экземпляр SQL Server активен либо в одном, либо в другом узле.
На следующей схеме показаны компоненты кластера Linux с SQL Server.
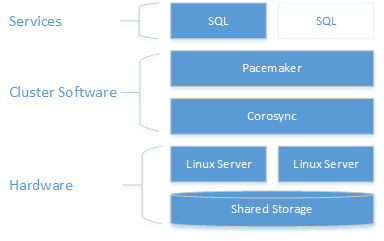
Дополнительные сведения о конфигурации кластера, параметрах агентов ресурсов и управлении см. в справочной документации по RHEL.
Отработка отказа кластера вручную
Команда resource move создает ограничение, принудительно запуская ресурс на целевом узле. После выполнения move команды выполнение ресурса clear приведет к удалению ограничения, поэтому можно снова переместить ресурс или автоматически выполнить отработку отказа ресурса.
sudo pcs resource move <sqlResourceName> <targetNodeName>
sudo pcs resource clear <sqlResourceName>
В следующем примере ресурс mssqlha перемещается на узел sqlfcivm2; затем ограничение удаляется, чтобы ресурс можно было переместить на другой узел позже.
sudo pcs resource move mssqlha sqlfcivm2
sudo pcs resource clear mssqlha
Мониторинг службы отказоустойчивого кластера SQL Server
Просмотр текущего состояния кластера:
sudo pcs status
Просмотр динамического состояния кластера и ресурсов:
sudo crm_mon
Просмотрите журналы агента ресурсов в /var/log/cluster/corosync.log.
Добавление узла в кластер
Проверьте IP-адрес для каждого узла. Для отображения IP-адреса текущего узла выполните следующий сценарий.
ip addr showНовому узлу нужно уникальное имя длиной не более 15 символов. По умолчанию в Red Hat Linux имя компьютера —
localhost.localdomain. Это имя по умолчанию не может быть уникальным и слишком длинным. Задайте имя компьютера на новом узле. Задайте имя компьютера, добавив его к/etc/hosts. Следующий сценарий позволяет изменить/etc/hostsс помощьюvi.sudo vi /etc/hostsВ следующем примере показан
/etc/hostsс дополнениями для трех узловsqlfcivm1,sqlfcivm2иsqlfcivm3.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 fcivm1 10.128.16.77 fcivm2 10.128.14.26 fcivm3Файл должен быть одинаковым на каждом узле.
Остановите службу SQL Server на новом узле.
Следуйте инструкциям по подключению каталога файлов базы данных к общему расположению:
На сервере NFS установите
nfs-utils.sudo yum -y install nfs-utilsОткройте брандмауэр в клиентах и на сервере NFS:
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadИзмените файл,
/etc/fstabчтобы включить команду подключения:<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrЧтобы изменения вступили в силу, выполните команду
mount -a.На новом узле создайте файл для хранения имени пользователя и пароля SQL Server для входа с помощью Pacemaker. Следующая команда создает и заполняет такой файл:
sudo touch /var/opt/mssql/passwd sudo echo "<loginName>" >> /var/opt/mssql/secrets/passwd sudo echo "<loginPassword>" >> /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/passwd sudo chmod 600 /var/opt/mssql/passwdВ брандмауэрах на новом узле откройте порты для Pacemaker. Чтобы открыть эти порты с помощью
firewalld, выполните следующую команду:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadЕсли вы используете другой брандмауэр, который не имеет встроенной конфигурации высокого уровня доступности, для связи с другими узлами в кластере необходимо открыть следующие порты:
- TCP: порты 2224, 3121, 21064
- UDP: порт 5405
Установите пакеты Pacemaker на новом узле.
sudo yum install pacemaker pcs fence-agents-all resource-agentsЗадайте пароль для пользователя по умолчанию, который создается при установке пакетов Pacemaker и Corosync. Используйте тот же пароль, что и для существующих узлов.
sudo passwd haclusterВключите и запустите службу
pcsdи Pacemaker. Это позволит новым узлам повторно подключаться к кластеру после перезагрузки. Выполните следующую команду на новом узле.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerУстановите агент ресурсов отказоустойчивого кластера для SQL Server. Выполните следующую команду на новом узле.
sudo yum install mssql-server-haНа существующем узле кластера выполните проверку подлинности нового узла и добавьте его в кластер:
sudo pcs cluster auth <nodeName3> -u hacluster sudo pcs cluster node add <nodeName3>В следующем примере в кластер добавляется узел с именем vm3.
sudo pcs cluster auth sudo pcs cluster start
Удаление узлов из кластера
Чтобы удалить узел из кластера, выполните следующую команду:
sudo pcs cluster node remove <nodeName>
Изменение частоты интервала мониторинга ресурсов sqlservr
sudo pcs resource op monitor interval=<interval>s <sqlResourceName>
В следующем примере интервал наблюдения для ресурса mssql устанавливается равным двум секундам:
sudo pcs resource op monitor interval=2s mssqlha
Устранение неполадок кластера общих дисков Red Hat Enterprise Linux для SQL Server
При устранении неполадок с кластером он помогает понять, как три управляющей программы работают вместе для управления ресурсами кластера.
| IoT Edge | Description |
|---|---|
| Corosync | Обеспечивает членство в кворуме и обмен сообщениями между узлами кластера. |
| Pacemaker | Работает поверх Corosync и предоставляет конечные автоматы для ресурсов. |
| PCSD | Управляет pacemaker и Corosync с помощью pcs средств. |
Для использования средств pcs необходимо запустить PCSD.
Текущее состояние кластера
sudo pcs status возвращает основные сведения о кластере, кворуме, узлах, ресурсах и состоянии управляющих программ для каждого узла.
Ниже приведен пример вывода для работоспособного кворума Pacemaker.
Cluster name: MyAppSQL
Last updated: Wed Oct 31 12:00:00 2016 Last change: Wed Oct 31 11:00:00 2016 by root via crm_resource on sqlvmnode1
Stack: corosync
Current DC: sqlvmnode1 (version 1.1.13-10.el7_2.4-44eb2dd) - partition with quorum
3 nodes and 1 resource configured
Online: [ sqlvmnode1 sqlvmnode2 sqlvmnode3 ]
Full list of resources:
mssqlha (ocf::sql:fci): Started sqlvmnode1
PCSD Status:
sqlvmnode1: Online
sqlvmnode2: Online
sqlvmnode3: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/enabled
В этом примере partition with quorum означает, что большая часть узлов кворума находится в оперативном режиме. Если кластер теряет кворум большинства узлов, pcs status возвращается partition WITHOUT quorum и все ресурсы остановлены.
online: [sqlvmnode1 sqlvmnode2 sqlvmnode3] возвращает имена всех узлов, которые сейчас участвуют в кластере. Если какие-либо узлы не участвуют, pcs status возвращается OFFLINE: [<nodename>].
PCSD Status показывает состояние кластера для каждого узла.
Причины, по которым узел может находиться в автономном режиме
Если узел находится в автономном режиме, проверьте следующие элементы.
Брандмауэр.
Чтобы Pacemaker мог обмениваться данными, на всех узлах должны быть открыты следующие порты.
- **TCP: 2224, 3121, 21064
Службы Pacemaker или Corosync работают
Связь между узлами
Сопоставления имен узлов