Руководство по Python. Создание модели для классификации клиентов с помощью машинного обучения SQL
Область применения: ![]() SQL Server 2017 (14.x) и более поздних
SQL Server 2017 (14.x) и более поздних ![]() версий Управляемый экземпляр SQL Azure
версий Управляемый экземпляр SQL Azure
В третьей части этого учебника из четырех частей вы создадите модель K-средних для кластеризации в Python. В следующей части данного цикла вы развернете эту модель в базе данных с использованием Служб машинного обучения SQL Server.
В третьей части этого учебника из четырех частей вы создадите модель K-средних для кластеризации в Python. В следующей части данного цикла вы развернете эту модель в базе данных с использованием Служб машинного обучения SQL Server.
В третьей части этого учебника из четырех частей вы создадите модель K-средних для кластеризации в Python. В следующей части из этой серии описывается, как развернуть эту модель в базе данных с помощью Служб машинного обучения в управляемом экземпляре SQL Azure.
В этой статье вы узнаете, как выполнять следующие задачи.
- Определение числа кластеров для алгоритма K-средних
- Выполнение кластеризации
- Анализ результатов
В первой части были установлены необходимые компоненты и восстановлена демонстрационная база данных.
Во второй части вы узнали, как подготовить данные из базы данных для выполнения кластеризации.
В четвертой части вы узнаете, как создать в базе данных хранимую процедуру, которая может выполнять кластеризацию в Python на основе новых данных.
Необходимые компоненты
- В третьей части этого учебника предполагается, что вы уже выполнили предварительные требования первой части, а также действия, указанные во второй части.
Определение числа кластеров
Для кластеризации данных клиентов будет использоваться алгоритм K-средних, который является одним из простейших и популярных способов группирования данных. Дополнительные сведения о нем см. в статье Полное руководство по алгоритму кластеризации на основе K-средних.
Алгоритм принимает два входных данных: сами данные и предопределенное число k, представляющее количество созданных кластеров. На выходе получается k кластеров, по которым разделяются входные данные.
Алгоритм K-средних группирует элементы в заданное количество кластеров (k) таким образом, чтобы элементы в одном кластере были максимально схожи друг с другом и максимально отличались от элементов других кластеров.
Чтобы определить число кластеров для алгоритма, используется график значений сумм квадратов внутри групп по числу извлеченных кластеров. Необходимое число кластеров будет находиться на изгибе графика.
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
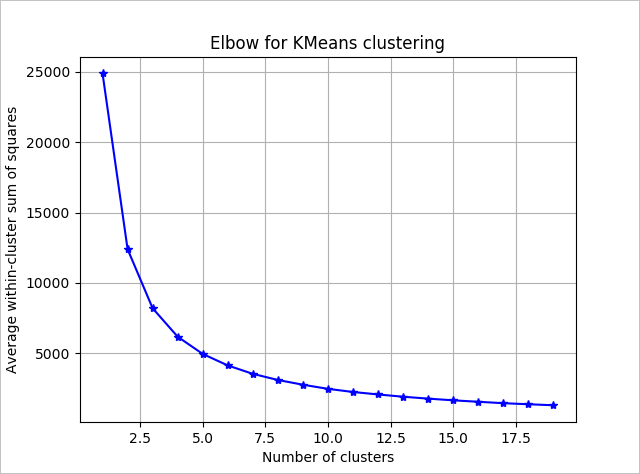
На этом графике оптимальным является значение k = 4. При таком значении k клиенты будут группироваться по четырем кластерам.
Выполнение кластеризации
В следующем скрипте Python вы будете использовать функцию KMeans из пакета sklearn.
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
Анализ результатов
После выполнения кластеризации по методу K-средних можно провести анализ результатов и определить наличие практически полезной информации.
Изучите средние значения кластеризации и размеры кластеров, выводимые предыдущим скриптом.
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
Значения кластеров задаются с помощью переменных, определенных в первой части:
- orderRatio = коэффициент возвратов заказов (отношение числа частично или полностью возвращенных заказов к общему числу заказов)
- itemsRatio = коэффициент возврата единицы товара (отношение возвращенных единиц товара к общему числу проданных единиц товара)
- monetaryRatio = коэффициент возврата в денежном выражении (отношение общего объема возвратов к общему объему покупок в денежном выражении)
- frequency = частота возвратов
Для интеллектуального анализа данных по методу K-средних часто требуется проведение дополнительного анализа результатов, а также выполнение других действий для лучшего понимания каждого кластера. Тем не менее, такой метод может дать полезные начальные результаты. Интерпретировать результаты можно несколькими способами:
- Кластер 0 скорее всего определяет группу неактивных клиентов (все значения равны нулю).
- Кластер 3 определяет группу с отличным от других поведением.
Кластер 0 объединяет клиентов, которые не демонстрируют активность. Возможно, вам стоит сосредоточить маркетинговую деятельность именно на этой группе, чтобы стимулировать интерес ее участников к покупке. На следующем шаге вы запрашиваете из базы данных адреса электронной почты клиентов, включенных в кластер 0, чтобы отправить им маркетинговые материалы.
Очистка ресурсов
Если вы не собираетесь продолжать работу с этим учебником, удалите базу данных tpcxbb_1gb.
Следующие шаги
В третьей части этого учебника вы выполнили следующие действия:
- Определение числа кластеров для алгоритма K-средних
- Выполнение кластеризации
- Анализ результатов
Чтобы развернуть созданную модель машинного обучения, перейдите к четвертой части этого учебника: