Файлы и файловые группы базы данных
Область применения:![]() SQL Server Управляемый экземпляр SQL Azure
SQL Server Управляемый экземпляр SQL Azure ![]()
Как минимум, каждая база данных SQL Server имеет два файла операционной системы: файл данных и файл журнала. Файлы данных содержат данные и объекты, такие как таблицы, индексы, хранимые процедуры и представления. Файлы журнала содержат сведения, необходимые для восстановления всех транзакций в базе данных. Файлы данных могут быть объединены в файловые группы для удобства распределения и администрирования.
Файлы баз данных
Базы данных SQL Server имеют три типа файлов, как показано в следующей таблице.
| Файл | Description |
|---|---|
| Основной | Содержит сведения, необходимые для запуска базы данных, и ссылки на другие файлы в базе данных. В каждой базе данных имеется один первичный файл данных. Рекомендуется .mdfиспользовать расширение имени файла для основных файлов данных. |
| Вторичные | Необязательные определяемые пользователем файлы данных. Данные могут быть распределены на несколько дисков, в этом случае каждый файл записывается на отдельный диск. Рекомендуемое расширение имени файла для вторичных файлов .ndfданных. |
| Журнал транзакций | Журнал содержит информацию для восстановления базы данных. Для каждой базы данных должен существовать хотя бы один файл журнала. Рекомендуется .ldfиспользовать расширение имени файла для журналов транзакций. |
Например, простая база данных с именем Sales содержит один первичный файл, содержащий все данные и объекты, а также файл журнала, содержащий сведения журнала транзакций. Можно создать более сложную базу данных Orders , содержащую один первичный файл и пять вторичных файлов. Данные и объекты внутри базы данных распределяются по всем шести файлам, а четыре файла журнала содержат сведения журнала транзакций.
По умолчанию и данные, и журналы транзакций помещаются на один и тот же диск и имеют один и тот же путь для обработки однодисковых систем. Этот выбор может быть не оптимальным для рабочих сред. Рекомендуется помещать данные и файлы журнала на разные диски.
Логические и физические имена файлов
Файлы SQL Server имеют два типа имен файлов:
logical_file_name:Этоlogical_file_nameимя, используемое для ссылки на физический файл во всех инструкциях Transact-SQL. Логическое имя файла должно соответствовать правилам для идентификаторов SQL Server и быть уникальным среди логических имен файлов в соответствующей базе данных.os_file_name:Имяos_file_nameфизического файла, включая путь к каталогу. Оно должно соответствовать правилам для имен файлов операционной системы.
Дополнительные сведения о файле и аргументе NAME FILENAME ALTER DATABASE File and Filegroup Options (Transact-SQL) см. в разделе ALTER DATABASE File and Filegroup Options (Transact-SQL).
Совет
Файлы данных и файлы журналов SQL Server могут использоваться как в файловой системе FAT, так и в системе NTFS. В системах Windows корпорация Майкрософт рекомендует использовать файловую систему NTFS, так как аспекты безопасности NTFS.
Предупреждение
Файловые группы, доступные как для чтения, так и для записи, а также файлы журналов не поддерживаются со сжатой файловой системой NTFS. В сжатую файловую систему NTFS разрешено помещать лишь доступные только для чтения базы данных и доступные только для чтения вторичные файловые группы. Для экономии места настоятельно рекомендуется использовать сжатие данных вместо сжатия файловой системы.
Если на одном компьютере запущено несколько экземпляров SQL Server, каждый экземпляр получает другой каталог по умолчанию для хранения файлов для баз данных, созданных в экземпляре. Дополнительные сведения см. в разделе Расположение файлов для экземпляра по умолчанию и именованных экземпляров SQL Server.
Страницы файлов данных
Страницы файлов данных SQL Server нумеруются последовательно; первая страница файла получает нулевой номер (0). Каждый файл базы данных имеет уникальный цифровой идентификатор. Чтобы уникальным образом определить страницу базы данных, необходимо использовать как идентификатор файла, так и номер этой страницы. В следующем примере показаны номера страниц базы данных, содержащей первичный файл данных объемом в 4 МБ и вторичный файл данных объемом в 1 МБ.
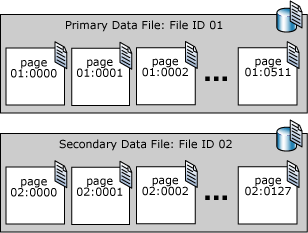
Страница заголовка файла — это первая, содержащая сведения об атрибутах данного файла. Некоторые другие страницы, расположенные в начале файла, тоже содержат системные сведения, например карты размещения. Одна из системных страниц, хранимых как в первичном файле данных, так и в первом файле журнала, представляет собой загрузочную страницу базы данных, которая содержит сведения об атрибутах этой базы данных.
Размер файла
Файлы SQL Server могут автоматически увеличиваться в размерах, превосходя первоначально заданные показатели. При определении файла пользователь может указывать требуемый шаг роста. Каждый раз при заполнении файла его размер увеличивается на указанный шаг роста. Если в файловой группе имеется несколько файлов, их автоматический рост начинается лишь по заполнении всех файлов.
Дополнительные сведения о страницах и их типах см. в разделе Руководство по архитектуре страниц и экстентов.
Кроме того, можно указать максимальный размер каждого файла. Если максимальный размер файла не указан, файл может продолжать увеличиваться в размерах, пока не займет все доступное место на диске. Эта функция особенно полезна, если SQL Server используется в качестве базы данных, внедренной в приложение, где у пользователя нет удобного доступа к системным администраторам. По мере необходимости пользователь может предоставить файлам возможность увеличиваться в размерах автоматически, тем самым снимая с администратора часть забот по наблюдению за свободным пространством базы данных и по распределению дополнительного пространства вручную.
Дополнительные сведения об управлении файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Файлы моментальных снимков базы данных
Вид файла, используемый для хранения копируемых во время записи данных моментального снимка базы данных, зависит от того, создается ли моментальный снимок пользователем или используется внутренними механизмами.
- Данные моментального снимка базы данных, созданного пользователем, хранятся в одном или нескольких разреженных файлах. Технология разреженных файлов является свойством файловой системы NTFS. Изначально разреженный файл не содержит данных пользователя, и место на диске под него не выделяется. Общие сведения об использовании разреженных файлов в моментальных снимках базы данных и о том, как растут моментальные снимки базы данных, см. в разделе Просмотр размера разреженного файла моментального снимка базы данных.
- Моментальные снимки базы данных могут использоваться внутренними механизмами при выполнении определенных команд DBCC. К этим командам относятся
DBCC CHECKDB,DBCC CHECKTABLEиDBCC CHECKFILEGROUPDBCC CHECKALLOC. Внутренним моментальным снимком базы данных используются разреженные дополнительные потоки данных исходных файлов базы данных. Подобно разреженным файлам, дополнительные потоки данных являются свойством файловой системы NTFS. Использование разреженных дополнительных потоков данных позволяет связать несколько расположений данных с одним файлом или папкой, не затрагивая при этом размер файла или статистику тома.
Файловые группы
- Основная файловая группа содержит первичный файл данных и все вторичные файлы, которые не помещают в другие файловые группы.
- Пользовательские файловые группы могут создаваться для удобства администрирования, распределения и размещения данных.
Например, Data1.ndf, Data2.ndf и Data3.ndf могут быть созданы на трех дисках соответственно и отнесены к файловой группе fgroup1. В этом случае можно создать таблицу на основе файловой группы fgroup1. Запросы данных из таблицы будут распределены по трем дискам, и это улучшит производительность. Подобного улучшения производительности можно достичь и с помощью одного файла, созданного на чередующемся наборе дискового массива RAID. Тем не менее файлы и файловые группы позволяют без труда добавлять новые файлы на новые диски.
Все файлы данных хранятся в файловых группах, перечисленных в следующей таблице.
| Файловая группа | Description |
|---|---|
| Основной | Файловая группа, содержащая первичный файл. Все системные таблицы являются частью первичной файловой группы. |
| Данные, оптимизированные для памяти | В основе оптимизированной для памяти файловой группы лежит файловая группа файлового потока. |
| Файловый поток | |
| Пользовательский | Любая файловая группа, созданная пользователем при создании или изменении базы данных. |
Файловая группа по умолчанию (основная)
Если в базе данных создаются объекты без указания файловой группы, к которой они относятся, они назначаются файловой группе по умолчанию. В любом случае только одна файловая группа создается как файловая группа по умолчанию. Файлы в файловой группе по умолчанию должны быть достаточно большими, чтобы вмещать новые объекты, не назначенные другим файловым группам.
Файловая группа PRIMARY является группой по умолчанию, если только она не была изменена инструкцией ALTER DATABASE. Системные объекты и таблицы распределяются внутри первичной файловой группы, а не новой файловой группой по умолчанию.
Файловая группа данных, оптимизированная для памяти
Дополнительные сведения об оптимизированных для памяти файловых группах см. в разделе Оптимизированные для памяти файловые группы.
Файловая группа FILESTREAM
Дополнительные сведения о файловых группах FILESTREAM см. в разделе FILESTREAM и создание базы данных с поддержкой FILESTREAM.
Пример файлов и файловой группы
В следующем примере создается база данных на основе экземпляра SQL Server. База данных содержит первичный файл данных, пользовательскую файловую группу и файл журнала. Первичный файл данных входит в состав первичной файловой группы, а пользовательская файловая группа состоит из двух вторичных файлов данных. Оператор ALTER DATABASE делает определяемую пользователем файловую группу по умолчанию. Затем создается таблица, определяющая пользовательскую файловую группу. (В этом примере используется универсальный путь к c:\Program Files\Microsoft SQL Server\MSSQL.1 , чтобы не указывать версию SQL Server.)
USE master;
GO
-- Create the database with the default data
-- filegroup, filestream filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILENAME=
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE=4MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Dat1',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
( NAME = 'MyDB_FG1_Dat2',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
( NAME = 'MyDB_FG_FS',
FILENAME = 'c:\Data\filestream1')
LOG ON
( NAME='MyDB_log',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE=1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB);
GO
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
GO
-- Create a table in the user-defined filegroup.
USE MyDB;
CREATE TABLE MyTable
( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1;
GO
-- Create a table in the filestream filegroup
CREATE TABLE MyFSTable
(
cola int PRIMARY KEY,
colb VARBINARY(MAX) FILESTREAM NULL
)
GO
Данная иллюстрация обобщает все вышесказанное (кроме данных файлового потока).

Стратегия заполнения файлов и файловой группы
В файловых группах для каждого файла используется стратегия пропорционального заполнения. Так как данные записываются в файловую группу, SQL Server ядро СУБД записывает количество пропорционально свободного места в файле каждому файлу в файловой группе, а не записывает все данные в первый файл до полного. Затем запись производится в следующий файл. Например, если файл f1 имеет 100 МБ бесплатно и файл f2 имеет 200 МБ бесплатно, один экстент предоставляется из файла f1, два экстента из файла f2и т. д. Таким образом, оба файла будут заполнены примерно в одно и то же время, и достигается простейшее распределение данных между хранилищами.
Например, файловая группа состоит из трех файлов, для всех разрешено автоматическое увеличение. Когда свободное пространство во всех файлах группы закончится, будет расширен только первый файл. Когда заполнится первый файл и в файловую группу снова нельзя будет записывать новые данные, будет расширен второй файл. Когда заполнится второй файл и в файловую группу опять нельзя будет записывать новые данные, будет расширен третий файл. Когда заполнится третий файл и в файловую группу нельзя будет записывать новые данные, будет снова расширен первый файл и т. д.
Правила проектирования файлов и файловых групп
Для файлов и файловых групп действуют следующие правила:
- файл или файловая группа не могут использоваться несколькими базами данных. Например, файл
sales.mdfиsales.ndf, содержащий данные и объекты из базы данных продаж, не может использоваться любой другой базой данных. - файл может быть элементом только одной файловой группы;
- файлы журнала транзакций не могут входить ни в какие файловые группы.
Рекомендации
Рекомендации при работе с файлами и файловыми группами:
- Для большинства баз данных достаточно использовать один файл данных и один файл журнала транзакций.
- При использовании множества файлов данных создайте вторую файловую группу с дополнительным файлом и сделайте ее файловой группой по умолчанию. Тогда в первичном файле будут храниться только системные таблицы и объекты.
- Чтобы увеличить производительность, по возможности разнесите файлы и файловые группы по нескольким доступным дискам. Объекты, активно конкурирующие за свободное пространство, поместите в разные файловые группы.
- Используйте файловые группы для целенаправленного размещения объектов на конкретных физических дисках.
- Помещайте разные таблицы, использующиеся в одних и тех же запросах с соединениями, в разные файловые группы. Этот этап увеличит производительность, так как для поиска соединяемых данных можно будет использовать параллельный ввод-вывод.
- Часто используемые таблицы и некластеризованные индексы, относящиеся к ним, помещайте в разные файловые группы. Использование разных групп файлов увеличит производительность, так как можно будет использовать параллельный ввод и вывод, если файлы находятся на разных жестких дисках.
- Не помещайте файлы журнала транзакций на тот же физический диск, где находятся другие файлы и файловые группы.
- Если необходимо расширить том или секцию, в которой находятся файлы базы данных с помощью таких средств, как Diskpart, необходимо сначала создать резервную копию всех системных и пользовательских баз данных и остановить службы SQL Server. Кроме того, после успешного расширения томов дисков рекомендуется выполнить команду
DBCC CHECKDB, чтобы обеспечить физическую целостность всех баз данных в томе.
Дополнительные рекомендации по управлению файлами журнала транзакций см. в разделе Управление размером файла журнала транзакций.
Связанный контент
- CREATE DATABASE (SQL Server Transact-SQL)
- Параметры инструкции ALTER DATABASE для файлов и файловых групп (Transact-SQL)
- Отсоединение базы данных и подключение (SQL Server)
- Руководство по архитектуре журнала транзакций SQL Server и управлению им
- Руководство по архитектуре страниц и экстентов
- Управление размером файла журнала транзакций