Компонент Full-text Search
Область применения:![]() SQL Server
SQL Server![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure ![]()
Полнотекстовый поиск в SQL Server и Базе данных SQL Azure позволяет приложениям и пользователям выполнять полнотекстовые запросы к символьным данным в таблицах SQL Server.
Основные задачи
В этой статье представлен обзор полнотекстового поиска и описаны его компоненты и архитектура. Если вы хотите немедленно приступить к работе, здесь вы найдете простые примеры задач.
- Начало работы с компонентом Full-Text Search
- Создание и управление полнотекстовыми каталогами
- Создание полнотекстовых индексов и управление ими
- Заполнение полнотекстовых индексов
- Запросы с полнотекстовым поиском
Полнотекстовый поиск является необязательным компонентом ядро СУБД SQL Server. Если при установке SQL Server полнотекстовый поиск не был выбран, запустите программу установки SQL Server повторно, чтобы добавить его.
Обзор
В полнотекстовый индекс включается один или несколько символьных столбцов таблицы. Эти столбцы могут содержать любой из следующих типов данных: char, varchar, nchar, nvarchar, text, ntext, image, xmlили varbinary(max) и FILESTREAM. Каждый полнотекстовый индекс индексирует один или несколько столбцов таблицы, а каждому столбцу может соответствовать определенный язык.
Полнотекстовые запросы выполняют лингвистические поиски по текстовым данным в полнотекстовых индексах, работая с словами и фразами на основе правил определенного языка, таких как английский или японский. Полнотекстовые запросы могут включать простые слова и фразы или несколько форм слова или фразы. Полнотекстовый запрос возвращает все документы, которые содержат как минимум одно совпадение (известное также как попадание). Совпадение возникает в том случае, когда целевой документ содержит все термины, указанные в полнотекстовом запросе, и соответствует всем остальным условиям поиска, например расстояние между совпадающими терминами.
Запросы полнотекстового поиска
После добавления столбцов в полнотекстовый индекс пользователи и приложения могут выполнять полнотекстовые запросы на текст в столбцах. Эти запросы могут выполнять поиск любого из следующих условий:
- Одно или несколько конкретных слов или фраз (простое выражение)
- Слова, начинающиеся заданным текстом, или фразы с такими словами (префиксные выражения)
- Словоформы конкретного слова (производное выражение)
- Слова или фразы, находящиеся рядом с другими словами или фразами (выражения с учетом расположения)
- Синонимические формы конкретного слова (тезаурус)
- Слова или фразы со взвешенными значениями (взвешенное выражение)
Полнотекстовые запросы не учитывает регистр. Например, поиск Aluminum или aluminum возврат одинаковых результатов.
Полнотекстовые запросы используют небольшой набор предикатов Transact-SQL (CONTAINSи) и функций (CONTAINSTABLEиFREETEXTTABLEFREETEXT). Однако точная структура полнотекстовых запросов определяется целями поиска данного бизнес-сценария. Например:
Поиск продукта на веб-сайте электронной коммерции:
SELECT product_id FROM products WHERE CONTAINS (product_description, '"Snap Happy 100EZ" OR FORMSOF(THESAURUS,"Snap Happy") OR "100EZ"') AND product_cost < 200;Сценарий подбора кандидатов на работу, имеющих опыт работы с SQL Server:
SELECT candidate_name, SSN FROM candidates WHERE CONTAINS (candidate_resume, '"SQL Server"') AND candidate_division = 'DBA';
Дополнительные сведения см. в разделе Запросы с полнотекстовым поиском.
Сравнение запросов полнотекстового поиска с предикатом LIKE
В отличие от полнотекстового поиска, предикат LIKE Transact-SQL работает только в шаблонах символов. Кроме того, нельзя использовать LIKE предикат для запроса отформатированных двоичных данных. Кроме того, LIKE запрос к большому количеству неструктурированных текстовых данных гораздо медленнее, чем эквивалентный полнотекстовый запрос к тем же данным. Запрос LIKE к миллионам строк текстовых данных может занять несколько минут, в то время как полнотекстовый запрос может занять только секунды или меньше, в зависимости от количества возвращаемых строк.
Архитектура полнотекстового поиска
Архитектура полнотекстового поиска состоит из следующих процессов.
Процесс SQL Server (
sqlservr.exe).Процесс узла управляющей программы фильтра (
fdhost.exe).По соображениям безопасности фильтры загружаются отдельными процессами, которые называются узлами управляющей программы фильтрации.
fdhost.exeПроцессы создаются службой запуска FDHOST (MSSQLFDLauncher), и они выполняются под учетными данными безопасности учетной записи службы запуска FDHOST. Следовательно, чтобы работало полнотекстовое индексирование и выполнялись полнотекстовые запросы, должна быть запущена служба FDHOST. Сведения о настройке учетной записи службы для этой службы см. в разделе Настройка учетной записи службы средства запуска управляющей программы полнотекстовой фильтрации.
Эти два процесса содержат компоненты архитектуры полнотекстового поиска. Эти компоненты и их связи приведены на следующей иллюстрации. Описание компонентов приведено после иллюстрации.
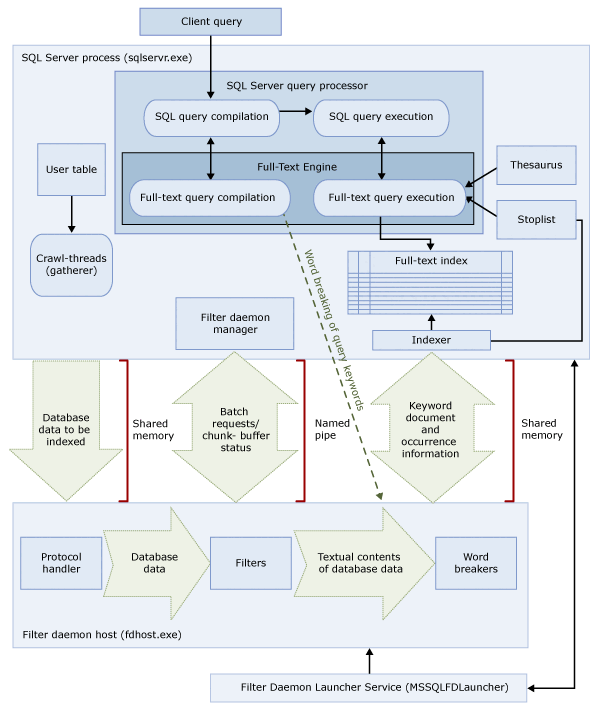
Процесс SQL Server
В процессе SQL Server используются следующие компоненты для полнотекстового поиска:
| Компонент | Description |
|---|---|
| Пользовательские таблицы | В этих таблицах содержатся данные, по которым осуществляется полнотекстовое индексирование. |
| Полнотекстовый сборщик | Средство сбора полнотекстовых данных работает с потоками полнотекстового сканирования. Он отвечает за планирование и управление населением полнотекстовых индексов, а также для мониторинга полнотекстовых каталогов. |
| Файлы Тезауруса | Эти файлы содержат синонимы искомых терминов. Дополнительные сведения см. в разделе Настройка файлов тезауруса для полнотекстового поиска и управление ими. |
| Объекты списка стоп-слов | Объекты списка стоп-слов содержат список распространенных слов, которые не полезны для поиска. Дополнительные сведения см. в разделе Настройка стоп-слов и списков стоп-слов для полнотекстового поиска и управление ими. |
| Обработчик запросов SQL Server | Обработчик запросов компилирует и выполняет SQL-запросы. Если SQL-запрос включает запрос полнотекстового поиска, то запрос направляется в средство полнотекстового поиска как в процессе компиляции, так и при выполнении. Результат запроса сопоставляется с полнотекстовым индексом. |
| Полнотекстовый модуль | Подсистема полнотекстового текста в SQL Server полностью интегрирована с обработчиком запросов. Средство полнотекстового поиска компилирует и выполняет полнотекстовые запросы. Как часть выполнения запроса средство полнотекстового поиска может получать входные данные из тезауруса и списка стоп-слов. |
| Модуль записи индексов (индексатор) | Модуль записи индекса строит структуру, используемую для хранения индексированных токенов. |
| Диспетчер управляющей программы фильтрации | Диспетчер управляющей программы фильтрации отвечает за наблюдение за состоянием узла управляющей программы фильтрации для полнотекстового поиска. |
Фильтрация процесса узла управляющей программы
Узел управляющей программы фильтрации представляет собой процесс, запускаемый средством полнотекстового поиска. Он запускает следующие компоненты полнотекстового поиска, которые отвечают за доступ, фильтрацию и разбиение по словам данных из таблиц, а также разбиение по словам и морфологический поиск во входных данных запроса.
Существуют следующие компоненты узла управляющей программы фильтрации.
| Компонент | Description |
|---|---|
| Обработчик протокола | Этот компонент запрашивает данные из памяти для дальнейшей обработки и обращается к данным из пользовательской таблицы в указанной базе данных. Одной из ее обязанностей является сбор данных из столбцов с полнотекстовой индексированием и передача его в узел управляющей программы фильтра, который применяет фильтрацию и разбиение слов по мере необходимости. |
| Фильтры | Для некоторых типов данных требуется фильтрация перед полнотекстовой индексацией данных в документе, в том числе для данных в столбцах varbinary, varbinary(max), imageили xml . Фильтр, используемый для данного документа, зависит от типа этого документа. Например, для документов Microsoft Word () используются различные фильтры, документы Microsoft Excel (.doc.xls) и XML (.xmlдокументы). Затем фильтр выделяет из документа фрагменты данных, при этом удаляется внедренное форматирование, остается текст и, возможно, сведения о положении текста. Результатом является поток текстовых данных. Дополнительные сведения см. в разделе Настройка фильтров для поиска и управление ими. |
| Средства разбиения по словам и стемперы | Работа средства разбиения по словам зависит от конкретного языка: компонент находит границы слов в соответствии с лексическими правилами данного языка (разбиение по словам). Каждое средство разбиения по словам связано с зависящим от языка компонентом парадигматического модуля, который спрягает глаголы и добавляет флексии. Во время индексирования узел управляющей программы фильтрации использует средство разбиения по словам и парадигматический модуль для выполнения лингвистического анализа текстовых данных из указанного столбца таблицы. Язык, связанный со столбцом таблицы в полнотекстовом индексе, определяет, какое средство разбиения по словам и какой парадигматический модуль будут использоваться для индексирования столбца. Дополнительные сведения см. в статье "Настройка и управление средствами разбиения слов" и "стволовые модули" для поиска (SQL Server). |
SQL Server 2012 (11.x) устанавливает новую версию средств разбиения слов и стеммеров для английского языка США (LCID 1033) и английского языка Великобритании (LCID 2057). Однако можно переключиться на предыдущую версию этих компонентов, если требуется сохранить предыдущий режим работы. Дополнительные сведения см. в статье Изменение средства разбиения по словам, используемого для английского (США) и английского (Британского).
Обработка полнотекстового поиска
Полнотекстовый поиск работает на базе средства полнотекстового поиска. Подсистема полнотекстового текста имеет две роли: поддержка индексирования и поддержка запросов.
Процесс полнотекстового индексирования
При инициации заполнения полнотекстового индекса (который также называют «сканированием») средство полнотекстового поиска помещает большие пакеты данных в память и оповещает управляющую программу полнотекстовой фильтрации. Узел фильтрует и разбивает данные и преобразует преобразованные данные в инвертированные списки слов. Затем средство полнотекстового поиска запрашивает конвертированные данные из списка слов, удаляет стоп-слова и сохраняет списки слов в виде пакета в один или несколько инвертированных индексов.
При индексировании данных, хранящихся в столбце varbinary(max) или image , фильтр, реализующий IFilter интерфейс, извлекает текст на основе указанного формата файлов для этих данных (например, Microsoft Word). В некоторых случаях компоненты фильтра требуют , чтобы данные varbinary(max)или изображения записывались filterdata в папку вместо отправки в память.
Одним из этапов обработки собранных текстовых данных является их анализ средством разбиения по словам, которое разделяет текст на отдельные токены, или ключевые слова. Язык, используемый при разметке, задается на уровне столбца или может быть определен компонентом-фильтром по данным типа varbinary(max), imageили xml .
Для удаления стоп-слов можно выполнить дополнительную обработку и нормализовать маркеры перед их сохранением в полнотекстовом индексе или фрагменте индекса.
После завершения совокупности запускается окончательный процесс слияния, который объединяет фрагменты индекса в один главный полнотекстовый индекс. Это приводит к повышению производительности запросов, так как для ранжирования релевантности может использоваться только главный индекс, а не несколько фрагментов индекса, а более эффективная статистика оценки.
Обработка полнотекстовых запросов
Обработчик запросов передает для обработки полнотекстовые части запроса средству полнотекстового поиска. Средство полнотекстового поиска выполняет разбиение по словам и при необходимости расширения тезауруса, морфологический поиск и обработку стоп-слов (пропускаемых слов). Затем полнотекстовые части запроса представляются в форме операторов SQL, в основном как потоковые функции, возвращающие табличные значения. Во время выполнения запроса эти потоковые функции для получения правильных результатов обращаются к инвертированному индексу. Результаты возвращаются клиенту в данный момент или обрабатываются до возвращения клиенту.
Архитектура полнотекстового индекса
Данные полнотекстовых индексов используются средством полнотекстового поиска для компиляции полнотекстовых запросов, способных быстро находить таблицу с теми или иными словами или словосочетаниями. В полнотекстовом индексе хранятся данные о значимых для поиска словах и их расположении в одном или нескольких столбцах таблицы базы данных. Полнотекстовый индекс — это специальный тип функционального индекса на основе токенов, который создается и поддерживается подсистемой полнотекстового текста для SQL Server. Процесс создания полнотекстового индекса отличается от создания индексов других типов. Вместо создания сбалансированного дерева на основе значения, хранящегося в конкретной строке, служба полнотекстового поиска создает инвертированную стековую сжатую структуру индекса на основе отдельных токенов индексируемого текста. Размер полнотекстового индекса ограничен только доступными ресурсами памяти компьютера, на котором выполняется экземпляр SQL Server.
Начиная с SQL Server 2008 (10.0.x), полнотекстовые индексы интегрируются с ядро СУБД вместо того, чтобы находиться в файловой системе, как в предыдущих версиях SQL Server. Для новой базы данных полнотекстовый каталог теперь является виртуальным объектом, который не принадлежит какой-либо файловой группе; это просто логическая концепция, которая ссылается на группу полнотекстовых индексов. Обратите внимание, что во время обновления базы данных SQL Server 2005 (9.x) создается любой полнотекстовый каталог, содержащий файлы данных, создается новая файловая группа; Дополнительные сведения см. в разделе "Обновление полнотекстового поиска".
На одну таблицу может приходиться только один полнотекстовый индекс. Для создания полнотекстового индекса в таблице таблица должна иметь один уникальный ненулевой столбец. Можно создать полнотекстовый индекс на столбцах типа char, varchar, nchar, nvarchar, text, ntext, image, xmlи varbinary, а также для полнотекстового поиска может индексироваться varbinary(max) . Для создания полнотекстового индекса на столбце, тип данных которого varbinary, varbinary(max), imageили xml , необходимо указать столбец типов. Столбец типа — это столбец таблицы, в котором хранится расширение файла (.doc, .pdfи .xlsт. д.) документа в каждой строке.
Структура полнотекстового индекса
Хорошее понимание структуры полнотекстового индекса помогает понять, как работает полнотекстовый модуль. В этой статье используется следующий фрагмент Document таблицы в AdventureWorks2022 качестве примера таблицы. В этом фрагменте показаны только два столбца DocumentID , столбец и Title столбец, а также три строки из таблицы.
В этом примере предполагается, что в столбце Title создан полнотекстовый индекс.
| DocumentID | Заголовок |
|---|---|
1 |
Crank Arm and Tire Maintenance |
2 |
Front Reflector Bracket and Reflector Assembly 3 |
3 |
Front Reflector Bracket Installation |
Например, в следующей таблице, в которой показан фрагмент 1, отображается содержимое полнотекстового индекса, созданного в Title столбце Document таблицы. Полнотекстовые индексы содержат больше данных, чем представлено в этой таблице. Таблица является логическим представлением полнотекстового индекса, она предоставляется только с целью демонстрации. Строки хранятся в сжатом формате для оптимизации использования диска.
Данные преобразуются из исходных документов. Инверсия происходит, поскольку ключевые слова сопоставлены с идентификаторами документов. По этой причине полнотекстовый индекс часто называют инвертированным индексом.
Обратите внимание, что ключевое слово and удаляется из полнотекстового индекса. Это делается, так как and это стоп-слово, и удаление стоп-слов из полнотекстового индекса может привести к значительной экономии места на диске, что повышает производительность запросов. Дополнительные сведения о стоп-словах см. в разделе Настройка и управление стоп-словами и списками стоп-слов для полнотекстового поиска.
Фрагмент 1
| Ключевое слово | ColId | DocId | Вхождение |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Front |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Bracket |
1 | 3 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Installation |
1 | 3 | 4 |
Столбец Keyword содержит представление одного маркера, извлеченного во время индексирования. Токены определяются средствами разбиения по словам.
Столбец ColId содержит значение, соответствующее определенному столбцу, который является полнотекстовой индексирован.
Столбец DocId содержит значения для целого числа 8-байтов, которое сопоставляется с определенным значением полнотекстового ключа в полнотекстовой индексированной таблице. Это сопоставление необходимо, если полнотекстовый ключ не является целым типом данных. В таких случаях сопоставления значений и DocId значений полнотекстового ключа сохраняются в отдельной таблице, называемой таблицей DocId Mapping . Чтобы запросить эти сопоставления, используйте sp_fulltext_keymappings системную хранимую процедуру. Чтобы удовлетворить условие поиска, DocId значения из предыдущей таблицы необходимо объединить с DocId таблицей сопоставления, чтобы получить строки из базовой таблицы, запрашиваемой. Если значение полнотекстового ключа базовой таблицы является целым типом, значение непосредственно служит в качестве DocId значения, и сопоставление не требуется. Следовательно, использование целочисленных значений полнотекстового ключа может оптимизировать выполнение полнотекстовых запросов.
Столбец Occurrence содержит целочисленное значение. Для каждого значения DocId существует список значений вхождения, соответствующих относительным смещениям слов конкретного ключевого слова в этом DocId. С помощью значений частотности удобно определять фразовое или близкое совпадение; например, для фраз значения частотности находятся рядом. Они также полезны в оценках релевантности вычислений; например, количество вхождения ключевого слова в DocId может использоваться при оценке.
Фрагменты полнотекстового индекса
Логический полнотекстовый индекс обычно разбивается по нескольким внутренним таблицам. Каждая из внутренних таблиц называется фрагментом полнотекстового индекса. Некоторые из данных фрагментов могут содержать более свежие данные. Например, если пользователь обновляет следующую строку с DocId, равным 3, а в таблице выполняется автоматическое отслеживание изменений, то будет создан новый фрагмент.
| DocumentID | Заголовок |
|---|---|
3 |
Rear Reflector |
В следующем примере, в котором показан фрагмент 2, содержатся более новые данные о DocId 3, чем во фрагменте 1. Поэтому, когда пользователь запрашивает Rear Reflector данные из фрагмента 2, используется для DocId 3. Каждый из фрагментов имеет отметку времени создания, которую можно использовать в запросах с помощью представления каталога sys.fulltext_index_fragments .
Фрагмент 2
| Ключевое слово | ColId | DocId | Occ |
|---|---|---|---|
Rear |
1 | 3 | 1 |
Reflector |
1 | 3 | 2 |
Как можно увидеть во фрагменте 2, полнотекстовым запросам необходимо осуществить внутреннее обращение к каждому фрагменту. Более старые записи не учитываются. Следовательно, наличие слишком большого количества полнотекстовых фрагментов индекса в полнотекстовом индексе может привести к существенному уменьшению производительности запросов. Чтобы уменьшить количество фрагментов, переорганизуйте полнотекстовый каталог с помощью REORGANIZE параметра инструкции ALTER FULLTEXT CATALOGTransact-SQL. Данная инструкция выполняет слияние в единый файл, объединяя все фрагменты в единый большой фрагмент, и удаляет все устаревшие записи из полнотекстового индекса.
После выполнения реорганизации в образце индекса будут содержаться следующие строки.
| Ключевое слово | ColId | DocId | Occ |
|---|---|---|---|
Crank |
1 | 1 | 1 |
Arm |
1 | 1 | 2 |
Tire |
1 | 1 | 4 |
Maintenance |
1 | 1 | 5 |
Front |
1 | 2 | 1 |
Rear |
1 | 3 | 1 |
Reflector |
1 | 2 | 2 |
Reflector |
1 | 2 | 5 |
Reflector |
1 | 3 | 2 |
Bracket |
1 | 2 | 3 |
Assembly |
1 | 2 | 6 |
3 |
1 | 2 | 7 |
Различия между полнотекстовых индексами и обычными индексами SQL Server
| Полнотекстовые индексы | Обычные индексы SQL Server |
|---|---|
| Для одной таблицы разрешен только один полнотекстовой индекс. | Для одной таблицы разрешено несколько обычных индексов. |
| Добавление данных к полнотекстовым индексам (заполнение) может быть запрошено явно, выполняться по расписанию либо автоматически при добавлении новых данных в базу. | Обновляется автоматически при вставке, обновлении или удалении данных, на основе которых они основаны. |
| Группируются в той же базе данных в один или несколько полнотекстовых каталогов. | Не группируются. |
Лингвистические компоненты полнотекстового поиска и поддержка языка
Полнотекстовый поиск поддерживает почти 50 языков, в том числе английский, испанский, китайский, японский, арабский, бенгальский и хинди. Полный список поддерживаемых полнотекстовых языков см . в sys.fulltext_languages. Каждый из столбцов в полнотекстовом индексе связан с идентификатором локали Microsoft Windows, который соответствует языку, поддерживаемому полнотекстовым поиском. Например, код языка 1033 соответствует языку «Английский (США)», а код 2057 соответствует языку «Английский (Великобритания)». Для каждого поддерживаемого полнотекстового языка SQL Server предоставляет лингвистические компоненты, поддерживающие индексирование и запросы полнотекстовых данных, хранящихся на этом языке.
Компоненты, относящиеся к языку, включают следующие элементы:
| Компонент | Description |
|---|---|
| Средства разбиения по словам и стемперы | Средство разбиения по словам находит границы слов на основании лексических правил данного языка (разбиение по словам). Каждое средство разбиения по словам связано с парадигматическим модулем, который спрягает глаголы этого языка и т. п. Дополнительные сведения см. в статье "Настройка и управление средствами разбиения слов" и "стволовые модули" для поиска (SQL Server). |
| Списки стоп-слов | Предоставляется системный список стоп-слов, содержащий базовый набор стоп-слов (также известный как шумовые слова). Стоп-слово — это слово, которое не помогает поиску и игнорируется полнотекстовых запросов. Например, для слов английского языка, таких как a, and, isи the считаются стоп-словами. Как правило, необходимо настроить один или несколько файлов тезауруса и стоп-списков. Дополнительные сведения см. в разделе Настройка стоп-слов и списков стоп-слов для полнотекстового поиска и управление ими. |
| Файлы Тезауруса | SQL Server также устанавливает файл тезауруса для каждого полнотекстового языка и глобальный файл тезауруса. Установленные файлы тезауруса пусты, но их можно изменить, чтобы определить синонимы для определенного языка или бизнес-сценария. Подготовив тезаурус, ориентированный на пользовательские полнотекстовые данные, можно эффективно расширить область полнотекстовых запросов к этим данным. Дополнительные сведения см. в разделе Настройка файлов тезауруса для полнотекстового поиска и управление ими. |
| Фильтры (iFilters) | Индексирование документа в столбце типа данных varbinary(max), imageили xml требует наличия фильтра для выполнения дополнительной обработки. Фильтр должен соответствовать типу документа (.doc, , .pdfи .xls.xmlт. д.). Дополнительные сведения см. в разделе Настройка фильтров для поиска и управление ими. |
Средства разбиения по словам (и стволовые модули) и фильтры выполняются в процессе узла управляющей программы фильтра (fdhost.exe).