Руководство по архитектуре и разработке индексов SQL Server и Azure SQL
Применимо: ![]() SQL Server
SQL Server ![]() База данных SQL Azure Управляемый экземпляр SQL Azure
База данных SQL Azure Управляемый экземпляр SQL Azure![]()
![]() azure Synapse Analytics Analytics
azure Synapse Analytics Analytics ![]() Platform System (PDW)
Platform System (PDW)
Плохо спроектированные индексы и их недостаточное количество — основной источник узких мест в приложениях баз данных. Проектирование эффективных индексов имеет первостепенную важность для достижения высокой производительности баз данных и приложений. Это руководство по проектированию индексов содержит сведения об архитектуре индексов и рекомендации, руководствуясь которыми, вы сможете создавать эффективные индексы, удовлетворяющие потребностям ваших приложений.
Предполагается, что читатель обладает общими знаниями доступных типов индексов. Общее описание типов индексов см. в разделе "Индексы".
В этом руководстве рассматриваются следующие типы индексов:
| Формат основного хранилища | Тип индекса |
|---|---|
| Rowstore на диске | |
| кластеризация. | |
| Некластеризованный | |
| Уникальный | |
| Отфильтровано | |
| Columnstore | |
| Кластеризованный индекс columnstore | |
| Некластеризованный индекс columnstore | |
| Оптимизированные по памяти | |
| Hash | |
| Некластеризованный индекс, оптимизированный для памяти |
Сведения о XML-индексах см. в статьях XML-индексов (SQL Server) и выборочных XML-индексов (SXI).
Сведения о пространственных индексах см. в разделе Общие сведения о пространственных индексах.
Сведения о полнотекстовых индексах см. в разделе "Заполнение полнотекстовых индексов".
Основы проектирования индексов
Подумайте о обычной книге: в конце книги есть индекс, который помогает быстро найти информацию в книге. Указатель представляет собой отсортированный список ключевых слов, а рядом с ключевым словом — номера страниц, где можно найти каждое ключевое слово.
Индекс rowstore не отличается: это упорядоченный список значений и для каждого значения есть указатели на страницы данных, где находятся эти значения. Сам индекс хранится на страницах, называемых страницами индекса. В обычной книге, если индекс охватывает несколько страниц, и вам нужно найти указатели на все страницы, содержащие слово SQL , например, вам придется листывать до тех пор, пока не найдите страницу индекса, содержащую ключевое слово SQL. После этого можно следовать указателям на все страницы книги. Этот процесс можно оптимизировать, если в самом начале индекса создать одну страницу, содержащую алфавитный список расположения каждой буквы. Например: "A-D - страница 121", "E-g - страница 122" и т. д. Эта дополнительная страница исключит шаг листы индекса, чтобы найти начальную место. Такая страница не существует в обычных книгах, но она существует в индексе rowstore. Эта единственная страница называется корневой страницей индекса. Корневая страница — это начальная страница древовидной структуры, используемой индексом rowstore. Следуя аналогии дерева, конечные страницы, содержащие указатели на реальные данные, называются "листьями" дерева.
Индекс является структурой на диске или в памяти, которая связана с таблицей или представлением и ускоряет получение строк из таблицы или представления. Индекс rowstore содержит ключи, построенные из одного или нескольких столбцов в таблице или представлении. Для индексов rowstore эти ключи хранятся в виде структуры сбалансированного дерева, которая поддерживает быстрый поиск строк по значениям ключей в ядре СУБД.
Данные индекса rowstore логически упорядочиваются в виде таблицы по строкам и столбцам, а физически хранятся в строковом формате, который называется rowstore 1, или в столбчатом формате, который называется columnstore.
Выбор правильных индексов для базы данных и ее рабочей нагрузки — это решение сложной задачи о соотношении скорости обработки запроса и стоимости обновления. Узкие индексы rowstore на диске, то есть индексы, в ключе которых мало столбцов, требуют меньше места на диске и меньше текущих издержек. С другой стороны, широкие индексы охватывают больше запросов. Перед поиском наиболее эффективного индекса может потребоваться поэкспериментировать с несколькими различными проектами. Добавление, изменение и удаление индексов не влияет на схему базы данных или конструкцию приложений. Поэтому вы не должны стесняться экспериментировать с различными индексами.
Оптимизатор запросов в ядро СУБД надежно выбирает наиболее эффективный индекс в большинстве случаев. Общая стратегия проектирования индекса должна предоставлять различные индексы для оптимизатора запросов, чтобы выбрать и доверять ему, чтобы принять правильное решение. Это уменьшит время анализа и обеспечит высокую производительность в различных ситуациях. Чтобы узнать, какие индексы использует оптимизатор запросов для определенного запроса в СРЕДЕ SQL Server Management Studio, в меню "Запрос " выберите "Включить фактический план выполнения".
Не всегда приравнивайте использование индекса с хорошей производительностью и хорошей производительностью с эффективным использованием индекса. Если бы использование индекса всегда способствовало производительности, то работа оптимизатора запросов была бы очень простой. На самом деле, неверный выбор индекса может привести к неоптимальной производительности. Таким образом, задача оптимизатора запросов заключается в выборе индекса или сочетании индексов, только если он повышает производительность, и чтобы избежать индексированного извлечения, когда это препятствует производительности.
1 Rowstore — это традиционный способ хранения реляционных данных таблиц. Rowstore ссылается на таблицу, в которой базовый формат хранилища данных — куча, дерево B+ (кластеризованный индекс) или оптимизированная для памяти таблица. Хранилище строк на основе дисков исключает оптимизированные для памяти таблицы.
Задачи проектирования индексов
Рекомендуемая стратегия проектирования индексов включает в себя следующие задачи:
Прежде всего следует понять характеристики самой базы данных.
- Например, будет ли это база данных OLTP с часто изменяющимися данными, которая должна поддерживать высокую пропускную способность. Таблицы, оптимизированные для памяти, и индексы особенно хорошо подходят для такого сценария, обеспечивая работу без кратковременных блокировок. Дополнительные сведения см. в разделе Индексы для таблиц, оптимизированных для памяти, или рекомендации по проектированию некластеризованных индексов и рекомендации по проектированию хэш-индекса в этом руководстве.
- Либо это может быть база данных системы поддержки решений (DDS) или хранилища данных (OLAP), которая должна быстро обрабатывать большие объемы данных. Индексы columnstore особенно хорошо подходят для типовых наборов данных хранилища данных. Индексы columnstore могут изменить работу пользователей с хранилищем данных, обеспечивая более высокую производительность для таких стандартных запросов хранилища данных, как фильтрация, статистическая обработка, группирование и запросы соединения типа «звезда». Дополнительные сведения см. в разделе "Индексы Columnstore: обзор" или "Рекомендации по проектированию индекса Columnstore" в этом руководстве.
Определите наиболее часто используемые запросы. Например, зная, что часто используемый запрос присоединяется к двум или нескольким таблицам, помогает определить лучший тип индексов для использования.
Выясните характеристики столбцов, используемых в запросах. Например, индекс идеально подходит для столбцов, имеющих целый тип данных, а также являются уникальными или ненулевыми столбцами. Для столбцов с четко определенными подмножествами данных можно использовать отфильтрованный индекс в SQL Server 2008 (10.0.x) и более поздних версиях. Дополнительные сведения см . в руководстве по проектированию отфильтрованного индекса.
Определите, какие параметры индекса могут повысить производительность при создании или обслуживании индекса. Например, при создании кластеризованного индекса для существующей большой таблицы выгодно будет использовать параметр
ONLINE. ЭтотONLINEпараметр позволяет продолжать параллельное действие в базовых данных во время создания или перестроения индекса. Дополнительные сведения см. в разделе Установка параметров индекса.Определите оптимальное расположение для хранения индекса.
Некластеризованный индекс может храниться в той же файловой группе, что и базовая таблица, или в другой группе. Правильный выбор расположения для хранения индексов может повысить производительность запросов за счет повышения скорости дискового ввода-вывода. Например, если некластеризованный индекс хранится в файловой группе не на том диске, на котором расположены файловые группы таблицы, то производительность может повыситься, поскольку это позволяет одновременно обращаться к нескольким дискам. Кластеризованные и некластеризованные индексы могут использовать схему секционирования, которая охватывает несколько файловых групп. При выборе секционирования определите, требуется ли выравнивание индекса, то есть должен ли индекс быть секционирован точно так же, как и таблицы, или он может быть секционирован иным образом. Дополнительные сведения см. в разделе Размещение индекса в файловых группах или схемах секций этой статьи.
При выявлении отсутствующих индексов с динамическими административными представлениями (динамическими административными представлениями), такими как sys.dm_db_missing_index_details и sys.dm_db_missing_index_columns, можно предложить аналогичные варианты индексов в одной таблице и столбцах. Чтобы предотвратить создание повторений, изучите существующие индексы в таблице, а также предложения отсутствующих индексов. Дополнительные сведения см. в разделе Настройка некластеризованных индексов с предложениями отсутствующих индексов.
Общие рекомендации по проектированию индексов
Опытный администратор базы данных может спроектировать хороший набор индексов, но эта задача сложна, требует много времени и сопряжена с ошибками даже для рабочих нагрузок и баз данных средней сложности. В разработке оптимальных индексов может помочь понимание характеристик базы данных, запросов и столбцов данных.
Рекомендации по базе данных
При проектировании индекса следует учитывать следующие рекомендации:
Большое количество индексов в таблице снижает производительность инструкций
INSERT,UPDATE,DELETEиMERGE, потому что при изменении данных в таблице все индексы должны быть скорректированы соответствующим образом. Например, если столбец используется в нескольких индексах и выполняется инструкцияUPDATE, которая изменяет данные из этого столбца, каждый индекс, содержащий этот столбец, должен быть обновлен, как и столбец в базовой таблице (куча или кластеризованный индекс).Избегайте использования чрезмерного количества индексов для интенсивно обновляемых таблиц и следите, чтобы индексы были узкими, то есть содержали как можно меньше столбцов.
Используйте большое количество индексов, чтобы улучшить производительность запросов для таблиц с низкими требованиями к обновлениям, но большими объемами данных. Большое количество индексов может помочь в производительности запросов, которые не изменяют данные, такие как инструкции, так как
SELECTоптимизатор запросов имеет больше индексов, чтобы выбрать один из способов быстрого доступа.
Индексирование небольших таблиц может быть не оптимальным, так как оптимизатор запросов может занять больше времени для обхода индекса поиска данных, чем для выполнения базовой проверки таблицы. Следовательно, для маленьких таблиц индексы могут вообще не использоваться, но тем не менее их необходимо поддерживать при изменении данных в таблице.
Индексы представлений могут дать значительное улучшение производительности, если представление содержит агрегаты, соединения таблиц или сочетание того и другого. Представление не должно быть явно указано в запросе оптимизатора запросов для его использования.
Базы данных на первичных репликах в Базе данных SQL Azure автоматически создают рекомендации по производительности Помощника по базам данных для индексов. При необходимости можно включить автоматическую настройку индекса.
хранилище запросов помогает выявлять запросы с неоптимальной производительностью и предоставляет журнал планов выполнения запросов, индексов которых индексирует оптимизатор.
Рекомендации по запросам
При проектировании индекса следует принимать во внимание следующие рекомендации, связанные с обработкой запросов.
Следует создавать некластеризованные индексы для столбцов, которые часто используются в предикатах и условиях соединения в запросах. В нашем примере это столбцы SARGable1. Однако следует избегать добавления столбцов без необходимости. Добавление слишком большого числа индексных столбцов может отрицательно повлиять на количество свободного места на диске и на производительность поддержания индекса.
Покрывающие индексы могут повысить производительность запросов, так как данные, необходимые для удовлетворения требований запроса, присутствуют в самом индексе. Таким образом, для получения запрашиваемых данных требуются только страницы индекса, а не страницы данных таблицы или кластеризованного индекса. Следовательно, уменьшается общий объем операций дискового ввода-вывода. Например, запрос по столбцам
AиBтаблицы, у которой есть составной индекс, созданный на основе столбцовA,BиC, может найти нужные данные, пользуясь только этим индексом.Покрывающими индексами называются некластеризованные индексы, которые разрешают один или несколько схожих результатов запроса напрямую, без доступа к базовой таблице и без уточняющих запросов.
Такие индексы имеют на конечном уровне все необходимые столбцы, отличные от SARGable. Это означает, что столбцы, возвращаемые
SELECTпредложением, и всеWHEREJOINаргументы охватываются индексом.Существует гораздо меньше операций ввода-вывода для выполнения запроса, если индекс достаточно узкий по сравнению с строками и столбцами в самой таблице, то есть это реальное подмножество общих столбцов.
Используйте покрывающие индексы, при обращении к небольшому фрагменту большой таблицы, который определяется фиксированным предикатом, например разреженными столбцами с малым числом непустых значений.
Запросы следует составлять так, чтобы они вставляли или изменяли как можно больше строк одной инструкцией, вместо того, чтобы использовать для обновления тех же строк нескольких запросов. Используя только одну инструкцию, можно воспользоваться возможностями, которые обеспечивает поддержание оптимизированного индекса.
Определите тип запроса и то, как в нем используются столбцы. Например: столбец, который используется в запросе с точным соответствием, может оказаться подходящим кандидатом для создания кластеризованного или некластеризованного индекса.
1 Термин SARGable в реляционных базах данных относится к предикату S earch ARG, который может использовать индекс для ускорения выполнения запроса.
Вопросы работы со столбцами
При проектировании индекса, следует принимать во внимание следующие рекомендации, относящиеся к столбцам.
Нужно следить, чтобы длина ключа для кластеризованных индексов была небольшой. Кроме того, кластеризованные индексы получают преимущество создания на уникальных или ненулевом столбцах.
Столбцы, типы данных ntext, text, image, varchar(max), nvarchar(max)и varbinary(max) нельзя указывать в качестве ключевых столбцов индекса. Однако типы данных varchar(max), nvarchar(max), varbinary(max)и xml могут участвовать в некластеризованных индексах в качестве их неключевых столбцов индекса. Дополнительные сведения см. в разделе " Индекс" с включенными столбцами в этом руководстве.
Столбцы типа xml могут быть ключевым столбцом только в XML-индексе. Дополнительные сведения см. в разделе XML-индексов (SQL Server). С пакетом обновления 1 (SP1) в SQL Server 2012 появился новый тип XML-индекса — выборочный XML-индекс. Этот новый индекс может повысить производительность запросов по данным, хранящимся в формате XML, ускорить индексирование больших рабочих нагрузок XML-данных и повысить масштабируемость за счет снижения затрат на хранение самого индекса. Дополнительные сведения см. в разделе "Выборочные XML-индексы" (SXI).
Проверьте уникальность столбцов. Замена неуникального индекса уникальным для той же комбинации столбцов обеспечивает оптимизатору запросов дополнительные сведения, что делает индекс более полезным. Дополнительные сведения см . в руководстве по проектированию уникальных индексов.
Проверьте распределение данных в столбце. Часто длительное выполнение запроса обусловлено индексированием столбца, в котором мало уникальных значений, или присоединением такого столбца. Это основная проблема с данными и запросами, и, как правило, не может быть решена без выявления этой ситуации. Например, физический телефонный каталог отсортирован по алфавиту по имени семьи не ускоряет поиск человека, если все люди в городе называются Смитом или Джонсом. Дополнительные сведения о распределении данных см. в разделе Statistics.
Рекомендуется использовать отфильтрованные индексы для столбцов с хорошо определенными подмножествами, например разреженными столбцами, столбцами с главным
NULLобразом значениями, столбцами с категориями значений и столбцами с различными диапазонами значений. Правильно составленный отфильтрованный индекс может увеличить скорость выполнения запроса, уменьшить стоимость обслуживания индекса и стоимость хранения.Рассмотрим порядок столбцов, если индекс содержит несколько столбцов. Столбец, используемый в
WHEREпредложении, равный (=), больше (>), меньше (<) илиBETWEENусловие поиска или участвует в соединении, должен быть помещен в первую очередь. Дополнительные столбцы должны быть упорядочены по уровню различимости, то есть от наиболее четкого к наименее четкому.Например, если индекс определен как
LastName,FirstNameиндекс полезен при наличии критерияWHERE LastName = 'Smith'поиска илиWHERE LastName = Smith AND FirstName LIKE 'J%'. Однако оптимизатор запросов не будет использовать индекс для запроса, который искал только вFirstName (WHERE FirstName = 'Jane').Следует рассмотреть возможность индексирования вычисляемых столбцов. Дополнительные сведения см. в разделе "Индексы" для вычисляемых столбцов.
Характеристики индекса
После определения того, что индекс подходит для запроса, можно выбрать тип индекса, который лучше всего подходит для вашей ситуации. Характеристики индекса включают следующий список:
- кластеризованный или некластеризованный;
- уникальный или неуникальный;
- с одним или несколькими столбцами;
- порядок по возрастанию или по убыванию в столбцах индекса;
- полнотабличные или фильтруемые некластеризованные индексы.
- columnstore или rowstore;
- Хэш и некластеризованные для таблиц, оптимизированных для памяти
Вы также можете настроить начальные характеристики хранилища индекса, чтобы оптимизировать его производительность или обслуживание, задав такой параметр, как FILLFACTOR. Чтобы оптимизировать производительность, можно также определить место хранения индекса с помощью файловых групп или схем секционирования.
Размещение индекса в файловых группах или схемах секций
Во время разработки стратегии индексирования следует обратить внимание на помещение индексов в файловые группы, связанные с базой данных. Аккуратный выбор схемы файловой группы или секционирования может улучшить производительность.
По умолчанию индексы хранятся в той же файловой группе, что и базовая таблица, для которой создается индекс. Несекционированный некластеризованный индекс и базовая таблица всегда находятся в одной файловой группе. Однако можно выполнить следующие действия.
- Создайте некластеризованные индексы в файловой группе, отличной от файловой группы базовой таблицы или кластеризованного индекса.
- Секционировать кластеризованные и некластеризованные индексы, чтобы они размещались в нескольких файловых группах.
- Перемещение таблицы из одной файловой группы в другую путем удаления кластеризованного индекса и указания новой файловой группы или схемы секционирования в
MOVE TOпредложении инструкцииDROP INDEXили с помощьюCREATE INDEXинструкции сDROP_EXISTINGпредложением.
Создав некластеризованный индекс в другой файловой группе, можно достичь прироста производительности, если файловые группы находятся на разных физических дисках с собственными контроллерами. Сведения о данных и индексе могут считываться параллельно несколькими головками. Например, если таблица Table_A в файловой группе f1 и индекс Index_A в файловой группе f2 используются в одном и том же запросе, производительность увеличится, так как обе файловые группы используются полностью, не состязаясь между собой. Однако если Table_A запрос сканируется, но Index_A не ссылается, используется только файловая группа f1 . В этом случае нет никакого выигрыша в производительности.
Так как вы не можете предсказать, какой тип доступа происходит и когда это происходит, это может быть лучшее решение для распространения таблиц и индексов во всех файловых группах. Это гарантирует, что доступ будет осуществляться ко всем дискам, так как все данные и индексы равномерно распределены по ним, независимо от способа доступа к данным. Для системных администраторов этот подход также более прост.
Секции во многих файловых группах
Можно рассмотреть возможность секционирования кластеризованных и некластеризованных индексов на диске по нескольким файловым группам. Секционированные индексы разбиваются горизонтально или построчно, в зависимости от функции секционирования. Функция секционирования определяет, как каждая строка сопоставляется с набором секций на основе значений определенных столбцов — столбцов секционирования. Схема секционирования определяет сопоставление секций набору файловых групп.
Секционирование индекса может предоставить следующие преимущества.
Система становится более масштабируемой, а управление большими индексами в ней упрощается. Например, в системах OLTP можно реализовать приложения, учитывающие секционирование и работающие с большими индексами.
Запросы выполняются быстрее и эффективнее. Когда запросы обращаются к нескольким секциям индекса, оптимизатор запросов может одновременно обрабатывать отдельные секции и исключать секции, не затронутые запросом.
Дополнительные сведения см. в разделах Секционированные таблицы и индексы.
Рекомендации по проектированию порядка сортировки индексов
При определении индексов следует иметь в виду, что данные ключевых столбцов индекса сохраняются в порядке возрастания или убывания. По возрастанию используется значение по умолчанию и поддерживается совместимость с более ранними версиями ядро СУБД. Синтаксис CREATE INDEXоператоров и CREATE TABLEALTER TABLE операторов ASC поддерживает ключевые слова (возрастание) и DESC (убывание) для отдельных столбцов в индексах и ограничениях.
Указание порядка хранения значений ключей в индексе полезно, если запросы, ссылающиеся на таблицу, имеют ORDER BY предложения, указывающие различные направления для ключевого столбца или столбцов в этом индексе. В таких случаях индекс может удалить необходимость SORT оператора в плане запроса, поэтому это делает запрос более эффективным. Например, покупатели в отделе приобретения Adventure Works Cycles должны оценить качество продуктов, которые они покупают у поставщиков. Больше всего его интересуют товары тех поставщиков, которые имеют набольшую частоту отказов.
Как показано в следующем запросе к образцу базы данных AdventureWorks, получение данных по соответствию этому критерию требует, чтобы столбец RejectedQty в таблице Purchasing.PurchaseOrderDetail был отсортирован в порядке убывания (от большего значения к меньшему), а столбец ProductID — в порядке возрастания (от меньшего к большему).
SELECT RejectedQty, ((RejectedQty/OrderQty)*100) AS RejectionRate,
ProductID, DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
GO
Следующий план выполнения для этого запроса показывает, что оптимизатор запросов использовал SORT оператор для возврата результирующий набор в порядке, указанном предложениемORDER BY.

Если индекс rowstore на основе диска создается с ключевыми столбцами, соответствующими ORDER BY предложению в запросе, SORT оператор может быть устранен в плане запроса, а план запроса является более эффективным.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
GO
После повторного выполнения запроса в следующем плане выполнения показано, что SORT оператор был устранен и используется только что созданный некластеризованный индекс.
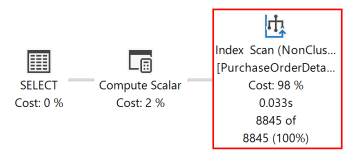
Ядро СУБД может одинаково эффективно перемещаться в любом направлении. Индекс, определенный как (RejectedQty DESC, ProductID ASC) можно использовать для запроса, в котором направление сортировки столбцов в ORDER BY предложении обратно. Например, запрос с предложением ORDER BY ORDER BY RejectedQty ASC, ProductID DESC может использовать индекс.
Порядок сортировки может быть указан только для ключевых столбцов в индексе. Представление каталога sys.index_columns и INDEXKEY_PROPERTY отчет о том, хранится ли столбец индекса в порядке возрастания или убывания.
Если вы используете примеры кода в примере базы данных AdventureWorks, вы можете удалить IX_PurchaseOrderDetail_RejectedQty следующие примеры кода Transact-SQL:
DROP INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail;
GO
Метаданные
Используйте приведенные ниже представления метаданных, чтобы увидеть атрибуты индексов. В некоторых из этих представлений содержатся дополнительные сведения об архитектуре.
Все столбцы в индексах columnstore хранятся в метаданных как включенные столбцы. Индекс columnstore не имеет ключевых столбцов.
- sys.column_store_dictionaries
- sys.column_store_row_groups
- sys.column_store_segments
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
- sys.dm_db_index_operational_stats
- sys.dm_db_index_physical_stats.
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.hash_indexes
- sys.index_columns
- sys.indexes
- sys.internal_partitions
- sys.memory_optimized_tables_internal_attributes
- sys.partitions
рекомендации по структуре кластеризованного индекса
Кластеризованные индексы сортируют и хранят строки данных в таблице, основываясь на их ключевых значениях. Может быть только один кластеризованный индекс на таблицу, потому что сами строки данных могут быть отсортированы только в одном порядке. При некоторых исключениях каждая таблица должна иметь кластеризованный индекс, определенный в столбце или столбцах, который предлагает следующее:
Может применяться для часто используемых запросов.
Обеспечивает высокую степень уникальности.
Примечание.
При создании
PRIMARY KEYограничения создается уникальный индекс столбца или столбцов. По умолчанию этот индекс кластеризован; однако при создании ограничения можно указать некластеризованный индекс.Может использоваться в диапазонных запросах.
Если кластеризованный индекс не создается со UNIQUE свойством, ядро СУБД автоматически добавляет в таблицу столбец с 4 байтами уникальности. При необходимости ядро СУБД автоматически добавляет уникальное значение в строку, чтобы сделать каждый ключ уникальным. Этот столбец и его значения используются внутренне и не могут просматриваться пользователями или получать к ней доступ.
Архитектура кластеризованного индекса
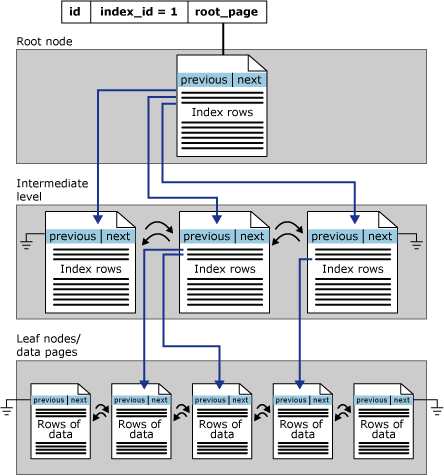
Индексы rowstore организованы в виде сбалансированных деревьев. Каждая страница в B⁺-дереве индекса называется узлом индекса. Верхний узел B⁺-дерева называется корневым. Узлы нижнего уровня индекса называются конечными. Все уровни индекса между корневыми и конечными узлами называются промежуточными. В кластеризованном индексе конечные узлы содержат страницы данных базовой таблицы. На страницах индекса корневого и промежуточного узлов находятся строки индекса. Каждая строка индекса содержит ключевое значение и указатель либо на страницу промежуточного уровня B⁺-дерева, либо на строку данных на конечном уровне индекса. Страницы на каждом уровне индекса связаны в двудвоем связанном списке.
Кластеризованные индексы имеют одну строку в sys.partitions, причем index_id = 1 для каждой секции, используемой индексом. По умолчанию, кластеризованный индекс занимает одну секцию. Если кластеризованный индекс занимает несколько секций, каждая секция содержит древовидную структуру (B⁺-дерево), содержащее данные этой секции. Например, если кластеризованный индекс занимает четыре секции, будут доступными четыре B⁺-дерева: по одному в каждой секции.
В зависимости от типов данных в кластеризованном индексе каждая кластеризованная структура индекса имеет одну или несколько единиц выделения, в которых следует хранить данные для определенной секции и управлять ими. Как минимум, каждый кластеризованный индекс имеет одну IN_ROW_DATA единицу выделения на секцию. Кластеризованный индекс также имеет одну единицу выделения LOB_DATA на секцию, если она содержит столбцы больших объектов (LOB). Он также имеет одну единицу выделения ROW_OVERFLOW_DATA на секцию, если она содержит столбцы переменной длины, превышающие ограничение размера строки размером 8 060 байтов.
Страницы в цепочке данных и строки, которые они содержат, упорядочены по значению ключа кластеризованного индекса. Все строки вставляются так, чтобы значение ключа составляло вместе с существующими строками упорядоченную последовательность.
На следующем рисунке изображена структура кластеризованного индекса для одной секции.
Рекомендации по запросам
Прежде чем создавать кластеризованные индексы, понять, как осуществляется доступ к данным. Рассмотрим использование кластеризованного индекса для запросов, которые выполняют следующее:
Возвращает диапазон значений с помощью таких операторов, как
BETWEEN,>, ,>=<и<=.После того как строка с первым значением будет найдена с помощью кластеризованного индекса, строки с последующими индексированными значениями гарантированно окажутся физически смежными с этой строкой. Например, если запрос получает записи из диапазона порядковых номеров продаж, кластеризованный индекс по столбцу
SalesOrderNumberможет быстро определить расположение строки, содержащей стартовый порядковый номер продаж, и затем извлечь все последующие строки из таблицы, пока не будет достигнут последний порядковый номер продаж.Возвращают большие результирующие наборы.
Используют предложения
JOIN; обычно в них участвуют внешние ключевые столбцы.Используют предложения
ORDER BYилиGROUP BY.Индекс столбцов, указанных в предложении или
GROUP BY,ORDER BYможет удалить необходимость сортировки данных ядро СУБД, так как строки уже отсортированы. Это улучшает производительность запроса.
Вопросы работы со столбцами
В общем случае надо так определить ключ кластеризованного индекса, чтобы в него вошло как можно меньше столбцов. Рассмотрите столбцы, которым присущ один или несколько следующих атрибутов:
Являются уникальными или содержат много различных значений.
Например, идентификатор сотрудника уникально идентифицирует служащих. Кластеризованный индекс или ограничение PRIMARY KEY на столбец
EmployeeIDулучшило бы производительность запросов, которые производят поиск сведений о сотруднике, основываясь на номере идентификатора сотрудника. В качестве альтернативы кластеризованный индекс мог бы быть создан по столбцамLastName,FirstNameиMiddleName, потому что записи сотрудников часто группируются и запрашиваются именно таким образом, так что сочетание этих столбцов обеспечивало бы высокую степень различия.Совет
Если не указано по-другому, при создании ограничения PRIMARY KEY ядро СУБД создает кластеризованный индекс для поддержки этого ограничения.
Несмотря на то, что для обеспечения уникальности можно использовать уникальность
PRIMARY KEY, но это не эффективный ключ кластеризации.При использовании уникального идентификатора как рекомендуется создать его как некластеризованный
PRIMARY KEYиндекс и использовать другой столбец, напримерIDENTITYдля создания кластеризованного индекса.Обращение к ним происходит последовательно.
Например, код продукта уникально идентифицирует продукты в таблице
Production.Productв базе данныхAdventureWorks2022. Запросы, в которых указан последовательный поиск, напримерWHERE ProductID BETWEEN 980 and 999, извлекут заметную выгоду из кластеризованного индекса поProductID. Это происходит потому, что строки будут храниться в отсортированном порядке по этому ключевому столбцу.Определен как
IDENTITY.Часто используются для сортировки данных, полученных из таблицы.
Рекомендуется кластерировать (физически сортировать) таблицу в этом столбце, чтобы сэкономить затраты на операцию сортировки при каждом запросе столбца.
Кластеризованные индексы не являются хорошим выбором для следующих атрибутов:
столбцов, которые подвергаются частым изменениям;
Это приводит к перемещению всей строки, так как ядро СУБД должны хранить значения данных строки в физическом порядке. Это важно при работе в крупномасштабных системах обработки транзакций, в которых данные обычно быстро меняются.
широких ключей.
Широкие ключи составлены из нескольких столбцов или нескольких столбцов большого размера. Ключевые значения из кластеризованного индекса используются всеми некластеризованными индексами как уточняющие запросы. Все некластеризованные индексы, определенные в той же таблице, значительно больше, так как некластеризованные записи индекса содержат ключ кластеризации, а также ключевые столбцы, определенные для этого некластеризованного индекса.
Рекомендации по проектированию некластеризованных индексов
Некластеризованный индекс rowstore на диске содержит значения ключей индекса и указатели строк, которые указывают на место хранения табличных данных. Можно создать несколько некластеризованных индексов для таблицы или индексированного представления. Как правило, некластеризованные индексы должны быть разработаны для повышения производительности часто используемых запросов, которые не охватывают кластеризованный индекс.
Подобно тому, как читатель использует индекс в книге, оптимизатор запросов выискивает значение типа данных, просматривая некластеризованный индекс. Там он находит место расположения интересующего его значения в таблице и затем получает данные непосредственно из этого места. Благодаря этому некластеризованные индексы считаются оптимальным выбором для запросов с точным соответствием, поскольку такие индексы содержат записи, описывающие точное расположение в таблице значений типов данных, которые задаются в подобных запросах. К примеру, чтобы выбрать в таблице HumanResources.Employee всех сотрудников, подчиняющихся тому или иному менеджеру, оптимизатор запросов может воспользоваться некластеризованным индексом IX_Employee_ManagerID; ключевым столбцом в нем является ManagerID . Оптимизатор запросов может быстро обнаружить в индексе все записи, соответствующие указанному значению ManagerID. Каждый элемент указателя ссылается на конкретную страницу и строку в таблице или на кластеризованный индекс, в котором можно найти соответствующие данные. После того как оптимизатор запросов обнаружит все записи в индексе, он может переходить непосредственно к нужной странице и строке, откуда он будет получать требуемые данные.
Архитектура некластеризованного индекса
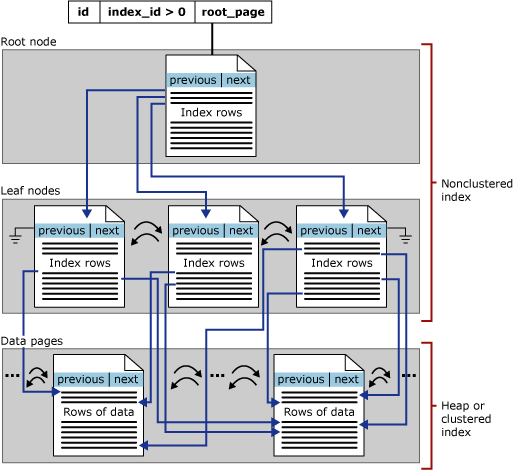
Некластеризованные индексы rowstore на диске имеют ту же структуру сбалансированного дерева, что и кластеризованные индексы; существуют только следующие различия:
Строки данных базовой таблицы не отсортированы и хранятся в порядке на основе некластеризованных ключей.
конечный уровень некластеризованного индекса состоит из страниц индекса вместо страниц данных. Страницы индекса на конечном уровне некластеризованного индекса содержат ключевые столбцы и включенные столбцы.
Указатели строк на строках некластеризованных индексов являются либо указателем на строку, либо ключом кластеризованного индекса для строки, как описано ниже.
Если таблица является кучей, то есть у нее нет кластеризованного индекса, указатель строки является указателем на строку. Указатель строится на основе идентификатора файла (ID), номера страницы и номера строки на странице. Весь указатель целиком называется идентификатором строки (RID).
Если для таблицы имеется кластеризованный индекс или индекс построен на индексированном представлении, то указатель строки — это ключ кластеризованного индекса для строки.
Указатели строк также обеспечивают уникальность для строк некластеризованного индекса. В следующей таблице описывается, как ядро СУБД добавляет указатели строк в некластеризованные индексы:
| Тип таблицы | Тип некластеризованного индекса | Указатель строки |
|---|---|---|
| Куча | ||
| Nonunique | RID добавлен в ключевые столбцы | |
| Уникальный | RID добавлен во включенные столбцы | |
| Уникальный кластеризованный индекс | ||
| Nonunique | Ключи кластеризованного индекса, добавленные в ключевые столбцы | |
| Уникальный | Ключи кластеризованного индекса, добавленные во включенные столбцы | |
| Неуникальный кластеризованный индекс | ||
| Nonunique | Ключи кластеризованного индекса и уникальный идентификатор (при наличии) добавлены в ключевые столбцы | |
| Уникальный | Ключи кластеризованного индекса и уникальный идентификатор (при наличии) добавлены во включенные столбцы |
Ядро СУБД никогда не сохраняет заданный столбец дважды в некластеризованном индексе. Порядок ключа индекса, заданный пользователем при создании некластеризованного индекса, всегда учитывается: все столбцы указателя строк, которые необходимо добавить в ключ некластеризованного индекса, добавляются в конце ключа после столбцов, указанных в определении индекса. Оптимизатор запросов может использовать указатели строк на основе ключей кластеризованного индекса в некластеризованном индексе, независимо от того, были ли они явно заданы в определении индекса.
В следующих примерах показано, как указатели строк реализуются в некластеризованных индексах:
| Кластеризованный индекс | Определение некластеризованного индекса | Определение некластеризованного индекса с указателями строк | Описание |
|---|---|---|---|
Уникальный кластеризованный индекс с ключевыми столбцами (A, B, C) |
Неуниковый некластеризованный индекс с ключевыми столбцами (B, A) и включенными столбцами (E, G) |
Ключевые столбцы (B, A, C) и включенные столбцы (E, G) |
Некластеризованный индекс неуникален, поэтому указатель строк должен присутствовать в ключах индекса. Столбцы B и A из указателя строки уже существуют, поэтому добавляется только столбец c. Столбец c добавляется в конец списка ключевых столбцов. |
Уникальный кластеризованный индекс с ключевым столбцом (A) |
Неуниковый некластеризованный индекс с ключевыми столбцами (B, C) и включенными столбцами (A) |
Ключевые столбцы (B, C, A) |
Некластеризованный индекс неуникален, поэтому указатель строки добавляется в ключ. Столбец A еще не указан в качестве ключевого столбца, поэтому он добавляется в конец списка ключевых столбцов. Столбец A теперь находится в ключе, поэтому не нужно хранить его как включенный столбец. |
Уникальный кластеризованный индекс с ключевым столбцом (A, B) |
Уникальный некластеризованный индекс с ключевым столбцом (C) |
Ключевой столбец (C) и включенные столбцы (A, B) |
Некластеризованный индекс уникален, поэтому указатель строки добавляется во включенные столбцы. |
Некластеризованные индексы имеют одну строку в sys.partitions с index_id > 1 каждой секцией, используемой индексом. По умолчанию некластеризованный индекс включает одну секцию. Если некластеризованный индекс состоит из нескольких секций, каждая секция имеет структуру B⁺-дерева, в которой содержатся индексные строки для этой конкретной секции. Например, если некластеризованный индекс состоит из четырех секций, будут доступными четыре структуры B⁺-дерева, по одной на каждую секцию.
В зависимости от типов данных в некластеризованном индексе каждая некластеризованная структура индекса имеет одну или несколько единиц распределения, в которых следует хранить данные для определенной секции и управлять ими. Как минимум, каждый некластеризованный индекс имеет одну единицу выделения IN_ROW_DATA на секцию, в которой хранятся страницы дерева индекса B+ . Некластеризованный индекс также имеет одну единицу выделения LOB_DATA на секцию, если она содержит столбцы больших объектов (LOB). Кроме того, он имеет одну единицу выделения ROW_OVERFLOW_DATA на секцию, если она содержит столбцы переменной длины, превышающие ограничение размера строки в 8 060 байтов.
На следующей иллюстрации показана структура некластеризованного индекса, состоящего из одной секции.
Рекомендации по базе данных
При проектировании некластеризованных индексов следует принимать во внимание характеристики соответствующей базы данных.
В базах данных или таблицах, характеризующихся нечастыми обновлениями и большими объемами хранимых данных, запросы могут выполняться быстрее при использовании множества некластеризованных индексов. Рекомендуется создать отфильтрованные индексы для четко определенных подмножеств данных, что позволит повысить производительность запросов, а также снизить затраты на обслуживание и хранение индексов по сравнению с полнотабличными некластеризованными индексами.
Производительность приложений систем поддержки принятия решений, а также баз данных может быть увеличена за счет использования большого числа некластеризованных индексов. Оптимизатор запросов имеет больше индексов, чтобы выбрать один из способов быстрого доступа, и низкие характеристики обновления среднего обслуживания индекса базы данных не препятствуют производительности.
При работе с приложениями и базами данных обработки транзакций в сети (OLTP) следует избегать слишком большого числа индексов. Кроме того, индексы должны быть узкими, то есть содержать минимальное количество столбцов.
Большое количество индексов в таблице снижает производительность инструкций
INSERT,UPDATE,DELETEиMERGE, потому что при изменении данных в таблице все индексы должны быть скорректированы соответствующим образом.
Рекомендации по запросам
Прежде чем создавать некластеризованные индексы, необходимо понять, как осуществляется доступ к данным. Рассмотрите возможность использования некластеризованных индексов для запросов, обладающих следующими атрибутами:
Используют предложения
JOINилиGROUP BY.Создавайте многомерные некластеризованные индексы для столбцов, участвующих в операциях соединения и группирования, а кластеризованный индекс для внешних ключевых столбцов.
Запросы, не возвращающие большие результирующие наборы.
Создайте отфильтрованные индексы для использования с запросами, возвращающими четко определенные подмножества строк из большой таблицы.
Совет
Обычно
WHEREпредложение инструкцииCREATE INDEXсоответствуетWHEREпредложению охватываемого запроса.Содержат столбцы, часто участвующие в условиях поиска запроса, например
WHEREпредложение, возвращающее точные совпадения.Совет
Сравнивайте затраты и преимущества при добавлении новых индексов. Возможно, предпочтительнее консолидировать дополнительные потребности запроса в существующий индекс. Например, попробуйте добавить один или два столбца на конечный уровень существующего индекса, если он может покрыть сразу несколько важных запросов, а не создавать отдельный индекс для каждого конкретного запроса.
Вопросы работы со столбцами
Рассмотрите столбцы, обладающие одним или несколькими указанными ниже атрибутами:
Покрытие запроса.
Производительность повышается в тех случаях, когда индекс содержит все столбцы запроса. Оптимизатор запросов может найти все значения столбцов в индексе; Доступ к данным таблицы или кластеризованного индекса не приводит к меньшему объему операций ввода-вывода диска. Для расширения покрытия столбцов не следует создавать широкий ключ индекса. Используйте индекс с включенными столбцами.
Если таблица имеет кластеризованный индекс, то столбец или столбцы, определенные в этом кластеризованном индексе, автоматически добавляются в каждый некластеризованный индекс таблицы. Это может привести к возникновению покрытого запроса без указания столбцов кластеризованного индекса в определении некластеризованного индекса. Например, если в таблице есть кластеризованный индекс в столбце
C, неуниковый некластеризованный индекс для столбцов иAимеет его ключевые значения столбцовBBиAC. Дополнительные сведения см . в некластеризованной архитектуре индекса.Множество различных значений, таких как сочетание имени семейства и имени, если кластеризованный индекс используется для других столбцов.
Если существует очень мало разных значений, например только
1и0большинство запросов не будут использовать индекс, так как проверка таблицы, как правило, эффективнее. Для этого типа данных рекомендуется создать отфильтрованный индекс по отдельному значению, которое происходит только в нескольких строках. Например, если большинство значений являются0, оптимизатор запросов может использовать отфильтрованный индекс для строк данных, содержащих1.
Использование включенных столбцов для расширения некластеризованных индексов
Функциональность некластеризованных индексов можно расширить с помощью добавления неключевых столбцов к конечному уровню некластеризованного индекса. Добавление неключевых столбцов позволяет создавать некластеризованные индексы, покрывающие больше запросов. Это обусловлено следующими преимуществами неключевых столбцов.
Они могут содержать типы данных, не разрешенные для ключевых столбцов индекса.
Они не учитываются ядро СУБД при вычислении количества ключевых столбцов индекса или размера ключа индекса.
Индекс с включенными неключевыми столбцами может значительно повысить производительность запроса, когда все столбцы запроса включены в индекс как ключевые или неключевые. Повышение производительности достигается, так как оптимизатор запросов может найти все значения столбцов в индексе; Доступ к данным таблицы или кластеризованного индекса не приводит к меньшему объему операций ввода-вывода диска.
Примечание.
Если индекс содержит все столбцы, на которые ссылается запрос, обычно он называется покрытием запроса.
В то время как ключевые столбцы сохраняются на всех уровнях индекса, неключевые столбцы сохраняются только на конечном уровне.
Использование включенных столбцов для предотвращения ограничений размера
Можно включать неключевые столбцы в некластеризованный индекс, чтобы избежать превышения текущих ограничений на размер индекса (16 ключевых столбцов) и размер ключа индекса (900 байт). Ядро СУБД не учитывает неключевые столбцы при вычислении количества ключевых столбцов индекса или размера ключа индекса.
Например, нужно индексировать следующие столбцы в таблице Document :
Title NVARCHAR(50)
Revision NCHAR(5)
FileName NVARCHAR(400)
Поскольку для типов данных nchar и nvarchar необходимо 2 байта для каждого символа, индекс, содержащий эти три столбца, на 10 байт превысит ограничение на размер в 900 байт (455 * 2). Использование предложения INCLUDE в инструкции CREATE INDEX позволит определить ключ индекса как (Title, Revision), а FileName определить как неключевой столбец. Таким образом, размер ключа индекса будет 110 байт (55 * 2), а индекс по-прежнему будет содержать все необходимые столбцы. Следующая инструкция создает такой индекс:
CREATE INDEX IX_Document_Title
ON Production.Document (Title, Revision)
INCLUDE (FileName);
GO
Если вы используете примеры кода, вы можете удалить этот индекс с помощью этой инструкции Transact-SQL:
DROP INDEX IX_Document_Title
ON Production.Document;
GO
Правила для индекса с включенными столбцами
При проектировании некластеризованных индексов с включенными столбцами пользуйтесь следующими правилами.
Неключевые столбцы определяются в
INCLUDEпредложении инструкцииCREATE INDEX.Неключевые столбцы можно определять только для некластеризованных индексов по таблицам или индексированным представлениям.
Допускаются данные всех типов, за исключением text, ntextи image.
Вычисляемые столбцы, являющиеся детерминированными и точными или неточными, могут быть включенными столбцами. Дополнительные сведения см. в разделе "Индексы" для вычисляемых столбцов.
Как и ключевые столбцы, вычисляемые столбцы, полученные на основе типов данных image, ntextи text , могут быть неключевыми (включенными) столбцами, если тип данных этого вычисляемого столбца допустим в качестве неключевого столбца индекса.
Имена столбцов нельзя указывать как в списке,
INCLUDEтак и в списке ключевых столбцов.Имена столбцов не могут повторяться в списке
INCLUDE.
Требования к размеру столбцов
Должен быть определен как минимум один ключевой столбец. Максимальное число неключевых столбцов равно 1023 столбцам. Это на 1 меньше, чем максимальное количество столбцов таблицы.
Ключевые столбцы индекса, в отличие от неключевых, должны удовлетворять текущим ограничениям на максимальное количество столбцов (16) и общий размер ключа индекса (900 байт).
Общий размер всех неключевых столбцов ограничен только размером столбцов, указанных в
INCLUDEпредложении. Например, столбцы varchar(max) ограничены 2 ГБ.
Правила изменения столбца
При изменении столбца таблицы, определенного как включенный столбец, действуют следующие ограничения.
Некие столбцы нельзя удалить из таблицы, если индекс не удаляется в первую очередь.
Некие столбцы нельзя изменить, за исключением следующих действий.
Измените значение NULL столбца на
NOT NULLNULL.увеличение длины столбцов типов varchar, nvarcharи varbinary .
Примечание.
Эти ограничения на изменение столбца также применяются к ключевым столбцам индекса.
Рекомендации по проектированию
Переопределите некластеризованные индексы с большим размером ключа индекса, чтобы только столбцы, используемые для поиска и уточняющего запроса, были ключевыми. Все остальные столбцы, покрывающие запрос, сделайте включенными неключевыми столбцами. Таким образом, у вас есть все столбцы, необходимые для покрытия запроса, но сам ключ индекса является небольшим и эффективным.
Например, нужно спроектировать индекс, покрывающий следующий запрос:
SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
GO
Для покрытия запроса необходимо включить в индекс все его столбцы. Хотя можно определить все столбцы как ключевые, размер ключа составит 334 байт. Поскольку единственным столбцом, используемым в качестве условий поиска, является PostalCode столбец, длина которых составляет 30 байт, лучшее проектирование индекса определяется PostalCode как ключевой столбец и включает все остальные столбцы в качестве неключевых столбцов.
Следующая инструкция создает индекс с включенными столбцами, покрывающий данный запрос.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Чтобы проверить, что индекс охватывает запрос, создайте индекс, а затем отобразите предполагаемый план выполнения.
Если план выполнения показывает только SELECT оператор и оператор Index Seek для IX_Address_PostalCode индекса, запрос охватывается индексом.
Индекс можно удалить с помощью следующей инструкции:
DROP INDEX IX_Address_PostalCode
ON Person.Address;
GO
Замечания, связанные с быстродействием
Избегайте добавления неиспользуемых столбцов. Добавление слишком большого количества столбцов, ключевых или неключевых, может оказать следующее влияние на производительность.
Меньше строк индекса, помещаемых на страницу. Это может привести к увеличению количества операций ввода-вывода и снизить эффективность кэша.
Для хранения индекса требуется больше места на диске. В частности, добавление varchar(max), nvarchar(max), varbinary(max)или xml-типов данных в качестве столбцов неключевых индексов может значительно увеличить требования к дисковой области. Это обусловлено тем, что значения столбцов копируются на конечный уровень индекса. Поэтому они находятся и в индексе, и в базовой таблице.
Обслуживание индекса может увеличить время выполнения изменений, вставок, обновлений или удалений в базовую таблицу или индексированное представление.
Необходимо определить, перевешивает ли производительность запросов на производительность во время изменения данных и в дополнительных требованиях к месту на диске.
Рекомендации по проектированию уникальных индексов
Уникальный индекс гарантирует, что ключ индекса не будет содержать одинаковых значений, а значит, каждая строка в таблице будет уникальна. Создание уникального индекса имеет смысл, только если данные сами по себе могут быть уникальными. Например, если вы хотите убедиться, что значения в NationalIDNumber столбце таблицы HumanResources.Employee уникальны, если первичный ключ имеет EmployeeIDзначение, создайте UNIQUE ограничение для столбца NationalIDNumber . Если пользователь пытается ввести одно и то же значение в этом столбце для нескольких сотрудников, отображается сообщение об ошибке и не вводится повторяющееся значение.
В случае уникальных индексов по нескольким столбцам индекс гарантирует, что каждая комбинация значений в ключе индекса уникальна. Например, если уникальный индекс создан для комбинации столбцов LastName, FirstNameи MiddleName , то никакие две строки в таблице не могут образовывать одну и ту же комбинацию этих значений.
Как кластеризованные, так и некластеризованные индексы могут быть уникальными. Если данные в столбце уникальны, можно создать уникальный кластеризованный индекс и несколько уникальных некластеризованных индексов для одной и той же таблицы.
Уникальные индексы имеют следующие преимущества:
- Гарантируется целостность данных в определенных столбцах.
- Предоставляются дополнительные сведения, полезные оптимизатору запросов.
PRIMARY KEY Создание или UNIQUE ограничение автоматически создает уникальный индекс для указанных столбцов. Нет существенных различий UNIQUE между созданием ограничения и созданием уникального индекса независимо от ограничения. Проверка данных выполняется таким же образом, и оптимизатор запросов не отличается от уникального индекса, созданного ограничением или созданным вручную. Однако необходимо создать UNIQUE или PRIMARY KEY ограничение столбца, если целостность данных является целевой задачей. Таким образом, цель индекса понятна.
Рекомендации
Уникальный индекс, ограничение или
PRIMARY KEYограничение нельзя создать,UNIQUEесли в данных существуют повторяющиеся значения ключей.Если данные уникальны и если нужно и далее требовать этой уникальности, создание уникального индекса вместо неуникального для тех же сочетаний столбцов предоставит дополнительные сведения оптимизатору запросов, который может создать более эффективные планы выполнения. В этом случае рекомендуется создать уникальный индекс (предпочтительно путем создания
UNIQUEограничения).Уникальный некластеризованный индекс может содержать любые неключевые столбцы. Дополнительные сведения см. в разделе Индекс с включенными столбцами.
Рекомендации по проектированию отфильтрованного индекса
Отфильтрованный индекс — это оптимизированный некластеризованный индекс, особенно подходящий для запросов, осуществляющих выборку из хорошо определенного подмножества данных. Он использует предикат фильтра для индексирования части строк в таблице. Хорошо спроектированный отфильтрованный индекс позволяет повысить производительность запросов, снизить затраты на обслуживание и хранение индексов по сравнению с полнотабличными индексами.
Отфильтрованные индексы могут предоставить следующие преимущества по сравнению с индексами, построенными на всей таблице.
Улучшение производительности запроса и качества плана
Хорошо разработанный отфильтрованный индекс повышает производительность запросов и качество плана выполнения, так как он меньше, чем некластеризованный индекс полной таблицы и имеет отфильтрованную статистику. Отфильтрованная статистика точнее полнотабличной статистики, так как содержит только строки отфильтрованного индекса.
Снижение расходов на обслуживание индекса
Индекс обслуживается только в случае, если инструкции языка обработки данных (DML) затрагивают данные в индексе. Отфильтрованный индекс уменьшает затраты на обслуживание индекса по сравнению с некластеризованным индексом полной таблицы, так как он меньше и сохраняется только при влиянии данных в индексе. Можно иметь большое количество отфильтрованных индексов, особенно если они содержат данные, затронутые редко. Аналогично, если отфильтрованный индекс содержит только часто изменяемые данные, меньший размер индекса уменьшает затраты на обновление статистики.
Снижение затрат на хранение индекса
Создание отфильтрованного индекса может уменьшить объем дискового хранилища для некластеризованных индексов, если не требуется полно табличный индекс. Полнотабличный некластеризованный индекс можно заменить несколькими отфильтрованными индексами без значительного увеличения требований к хранилищу.
Отфильтрованные индексы полезны, если столбцы содержат четко определенные подмножества данных, которые запрашивают ссылку в SELECT инструкциях. Примеры:
- Разреженные столбцы, содержащие только несколько не-значений
NULL. - Разнородные столбцы, содержащие категории данных.
- Столбцы, содержащие диапазоны значений, таких как количество долларов, время и даты.
- Секции таблицы, определенные логикой простого сравнения для значений столбцов.
Снижение затрат на обслуживание отфильтрованного индекса более заметно, когда количество строк в индексе является небольшим по сравнению с полнотабличным индексом. Если отфильтрованный индекс включает большую часть строк в таблице, его обслуживание может быть более затратным по сравнению с полнотабличным индексом. В этом случае нужно использовать полнотабличный индекс вместо отфильтрованного.
Отфильтрованные индексы определены в одной таблице и поддерживают только простые операторы сравнения. Если необходим критерий фильтра, который ссылается на множество таблиц или имеет сложную логику, нужно создать представление.
Рекомендации по проектированию
Чтобы разработать эффективные отфильтрованные индексы, важно понять, какие запросы использует приложение и как они связаны с подмножествами данных. Некоторые примеры данных с хорошо определенными подмножествами — это столбцы с NULL главным образом значениями, столбцами с разнородными категориями значений и столбцов с различными диапазонами значений. Далее приведены различные сценарии, в которых отфильтрованный индекс дает преимущества над полнотабличными индексами.
Совет
Определение некластеризованного индекса columnstore поддерживает использование отфильтрованных условий. Чтобы свести к минимуму негативное влияние на производительность, вызванное добавлением некластеризованного индекса columnstore для таблицы OLTP, можно использовать отфильтрованное условие для создания некластеризованного индекса columnstore только для холодных данных операционной рабочей нагрузки.
Отфильтрованные индексы для подмножеств данных
Если столбец имеет только несколько соответствующих значений для запросов, можно создать отфильтрованный индекс в подмножестве значений. Например, если значения в столбце в основном NULL и запрос выбирается только из значений, отличных от значений, можно создать отфильтрованный индекс для строк, неNULL являющихсяNULL данными. Результирующий индекс меньше и стоит меньше, чем полный некластеризованный индекс, определенный на одних и том же ключевых столбцах.
Например, в примере базы данных AdventureWorks есть Production.BillOfMaterials таблица с 2679 строками. Столбец EndDate содержит только 199 строк, которые содержат не-значениеNULL , а другие 2480 строки содержатся NULL. Следующий отфильтрованный индекс будет охватывать запросы, возвращающие столбцы, определенные в индексе, и которые выбирают только строки с незначаемымNULL значением EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
GO
Отфильтрованный индекс FIBillOfMaterialsWithEndDate допустим для следующего запроса. Отображение предполагаемого плана выполнения, чтобы определить, использовал ли оптимизатор запросов отфильтрованный индекс.
SELECT ProductAssemblyID, ComponentID, StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
GO
Дополнительные сведения о создании отфильтрованных индексов и определении выражения предиката отфильтрованного индекса см. в разделе "Создание отфильтрованных индексов".
Отфильтрованные индексы для разнородных данных
Если таблица содержит строки с разнородными данными, можно создать отфильтрованный индекс для одной или более категорий данных.
Например, продукты, содержащиеся в таблице Production.Product , связаны с идентификатором ProductSubcategoryID, который в свою очередь связан с категориями продуктов, такими как велосипеды, запчасти, одежда или аксессуары. Эти категории являются разнородными, так как их значения столбцов в Production.Product таблице не тесно коррелируются. Например, столбцы Color, ReorderPoint, ListPrice, Weight, Classи Style имеют уникальные характеристики для каждой категории продукта. Предположим, что существуют частые запросы на аксессуары, которые имеют подкатегории от 27 до 36 включительно. Можно повысить результативность запросов на аксессуары, создав отфильтрованный индекс по подкатегориям аксессуаров, как показано в следующем примере.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
Include (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
GO
Отфильтрованный индекс охватывает следующий запрос, так как результаты запроса содержатся в индексе FIProductAccessories , а план запроса не включает подстановку базовой таблицы. Например, выражение предиката запроса ProductSubcategoryID = 33 — это подмножество предиката отфильтрованного индекса ProductSubcategoryID >= 27 и ProductSubcategoryID <= 36, а столбцы ProductSubcategoryID и ListPrice в предикате запроса являются ключевыми столбцами в индексе. Имя сохраняется на конечном уровне индекса в качестве включенного столбца.
SELECT Name, ProductSubcategoryID, ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33 AND ListPrice > 25.00;
GO
Ключевые столбцы
Рекомендуется включить несколько ключевых или включенных столбцов в определение отфильтрованного индекса, а также включить только столбцы, необходимые для оптимизатора запросов, чтобы выбрать отфильтрованный индекс для плана выполнения запроса. Оптимизатор запросов может выбрать отфильтрованный индекс для запроса независимо от того, выполняется ли он или не охватывает запрос. Однако оптимизатор запросов с большей вероятностью выберет отфильтрованный индекс, если он перекрывает запрос.
В некоторых случаях отфильтрованный индекс перекрывает запрос, не включая в определение отфильтрованного индекса в качестве ключевых или включенных столбцов столбцы из выражения отфильтрованного индекса. Следующие правила содержат описание того, должен ли быть столбец в выражении отфильтрованного индекса ключевым или включенным столбцом в определении отфильтрованного индекса. В примерах используется ранее созданный отфильтрованный индекс FIBillOfMaterialsWithEndDate .
Столбец в отфильтрованном выражении индекса не должен быть ключом или включенным столбцом в определение отфильтрованного индекса, если отфильтрованное выражение индекса эквивалентно предикату запроса, и запрос не возвращает столбец в отфильтрованном выражении индекса с результатами запроса. Например, охватывает следующий запрос, FIBillOfMaterialsWithEndDate так как предикат запроса эквивалентен выражению фильтра и EndDate не возвращается с результатами запроса. FIBillOfMaterialsWithEndDate не требуется EndDate в качестве ключа или включенного столбца в определение отфильтрованного индекса.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Столбец в отфильтрованном выражении индекса должен быть ключом или включенным столбцом в определение отфильтрованного индекса, если предикат запроса использует столбец в сравнении, который не эквивалентен выражению отфильтрованного индекса. Например, отфильтрованный индекс FIBillOfMaterialsWithEndDate допустим для следующего запроса, поскольку этот запрос выбирает подмножество строк из отфильтрованного индекса. Однако он не охватывает следующий запрос, так как EndDate используется в сравнении EndDate > '20040101', который не эквивалентен выражению отфильтрованного индекса. Обработчик запросов не может выполнить этот запрос без поиска значений EndDate. Поэтому в определении отфильтрованного индекса EndDate должен быть ключевым или включенным столбцом.
SELECT ComponentID, StartDate FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
Столбец в выражении отфильтрованного индекса должен быть ключевым или включенным столбцом в определении отфильтрованного индекса, если этот столбец содержится в результирующем наборе запроса. Например, не охватывает следующий запрос, FIBillOfMaterialsWithEndDate так как он возвращает EndDate столбец в результатах запроса. Поэтому в определении отфильтрованного индекса EndDate должен быть ключевым или включенным столбцом.
SELECT ComponentID, StartDate, EndDate FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
Ключ кластеризованного индекса таблицы не должен быть ключом или включенным столбцом в определение отфильтрованного индекса. Ключ кластеризованного индекса автоматически включается во все некластеризованные индексы, в том числе отфильтрованные индексы.
Чтобы удалить индексы FIBillOfMaterialsWithEndDate и FIProductAccessories, выполните следующие инструкции:
DROP INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials;
GO
DROP INDEX FIProductAccessories
ON Production.Product;
GO
Операторы преобразования данных в предикате фильтра
Если оператор сравнения, указанный в отфильтрованном выражении индекса, приводит к неявным или явным преобразованиям данных, ошибка возникает, если преобразование происходит слева от оператора сравнения. Решением является запись отфильтрованного выражения индекса с помощью оператора преобразования данных (CAST или CONVERT) справа от оператора сравнения.
В следующем примере создается таблица с различными типами данных.
CREATE TABLE dbo.TestTable (
a INT,
b VARBINARY(4)
);
GO
В следующем определении отфильтрованного индекса столбец b неявно преобразуется в тип данных integer для сравнения с константой 1. Это вызывает сообщение об ошибке 10611, поскольку преобразование выполняется в левой части оператора в отфильтрованном предикате.
CREATE NONCLUSTERED INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = 1;
GO
Решением является преобразование константы в правой части к типу столбца b, как показано в следующем примере.
CREATE INDEX TestTabIndex ON dbo.TestTable (a, b)
WHERE b = CONVERT(VARBINARY(4), 1);
GO
Перемещение преобразования данных из левой части оператора сравнения в правую может изменить значение преобразования. В предыдущем примере, когда CONVERT оператор был добавлен в правую сторону, сравнение изменилось с целочисленного сравнения на сравнение varbinary .
Удалите объекты, созданные в этом примере, выполнив следующую инструкцию:
DROP TABLE TestTable;
GO
Архитектура индексов columnstore
Индекс columnstore — это технология хранения и получения данных, а также управления ими с помощью формата хранения данных в столбцах, называемого columnstore. Дополнительные сведения см. в разделе "Индексы Columnstore: Обзор".
Сведения о версии и сведения о новых возможностях см . в новых индексах columnstore.
Знание этих основных принципов упрощает понимание других статей columnstore, которые объясняют, как эффективно использовать их.
Данные хранятся в форматах columnstore и rowstore
При обсуждении индексов columnstore для обозначения формата хранения данных используются термины rowstore и columnstore. Индексы columnstore используют оба типа хранилища.
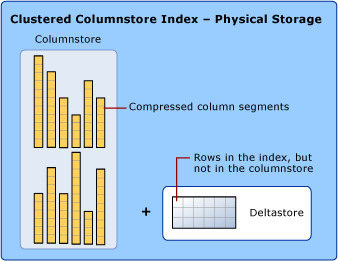
columnstore — это данные, логически организованные в виде таблицы, состоящей из строк и столбцов, и физически хранящиеся как столбцы
Индекс columnstore физически сохраняет большинство данных в формате columnstore. В этом формате данные представлены столбцами, которые можно сжимать и распаковывать. Нет необходимости распаковывать другие значения в каждой строке, которая не запрашивается запросом. Благодаря этому можно быстро просматривать целые столбцы большой таблицы.
rowstore — это данные, логически организованные в виде таблицы, состоящей из строк и столбцов, и физически хранящиеся как строки. Это стандартный способ хранения реляционных данных таблиц Это стандартный способ хранения реляционных данных таблиц, например кластеризованного индекса B⁺-дерева или кучи.
Индекс columnstore также физически сохраняет некоторые строки в формате rowstore, который называется deltastore. Deltastore, также называемый разностными группами строк, является местом хранения для строк, которые слишком мало числа, чтобы претендовать на сжатие в columnstore. Каждая разностная группа строк реализована в виде кластеризованного индекса B⁺-дерева.
deltastore — это место хранения строк, которых слишком мало для сжатия в columnstore. В deltastore таблица хранится в формате rowstore.
Дополнительные сведения о терминах и понятиях columnstore см. в статье "Общие сведения об индексах Columnstore".
Операции выполняются в сегментах групп строк и столбцов
Индексы columnstore группируют строки в управляемые элементы. Каждый из этих элементов называется группой строк. Для лучшей производительности число строк в группе строк должно быть достаточно большим, чтобы повысить скорость сжатия, и достаточно малым для использования преимуществ операций в памяти.
В группах строк индекс columnstore может выполнять следующие операции:
- сжимает группы строк в columnstore (выполняется в каждом сегменте столбца в группе строк);
- объединяет группы строк во время операции
ALTER INDEX ... REORGANIZEс очисткой удаленных данных; - создает новые группы строк во время операции
ALTER INDEX ... REBUILD; - отправляет отчеты об исправности и фрагментации групп строк в динамических административных представлениях.
deltastore состоит из одной или нескольких групп строк, которые называются разностными группами строк. Каждая разностная группа строк — это кластеризованный индекс B⁺-дерева, в котором хранятся небольшие массовые загрузки и вставки, пока группа строк не будет содержать 1 048 576 строк. При этом процесс, который называется задачей переноса кортежей, автоматически сжимает закрытую группу строк в columnstore.
Дополнительные сведения о состоянии группы строк см. в sys.dm_db_column_store_row_group_physical_stats.
Совет
Слишком большое количество небольших групп строк ухудшает качество индекса columnstore. Операция реорганизации объединяет небольшие группы строк, следуя внутренней политике порогового значения, которая определяет, как удалить удаленные строки и объединить сжатые группы строк. После объединения качество индекса должно повыситься.
В SQL Server 2019 (15.x) и более поздних версиях кортеж-перемещение помогает задачей фонового слияния, которая автоматически сжимает небольшие OPEN разностные группы строк, которые существовали в течение некоторого времени, как определено внутренним пороговым значением, или объединяет COMPRESSED группы строк, из которых было удалено большое количество строк.
Каждый столбец содержит несколько собственных значений в каждой группе строк. Эти значения называются сегментами столбцов. Каждая rowgroup содержит один сегмент столбца для каждого столбца в таблице. Каждый столбец содержит один сегмент столбца в каждой группе строк.
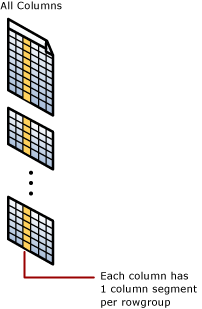
Когда индекс columnstore сжимает группу строк, он отдельно сжимает каждый сегмент столбца. Чтобы распаковать целый столбец, индексу columnstore необходимо распаковать только один сегмент столбца из каждой группы строк.
Дополнительные сведения о терминах и понятиях columnstore см. в статье "Общие сведения об индексах Columnstore".
Небольшие загрузки и вставки переносятся в deltastore
Индекс columnstore улучшает сжатие и производительность columnstore за счет сжатия как минимум 102 400 строк в индекс columnstore за раз. Чтобы выполнить массовое сжатие строк, индекс columnstore накапливает небольшие загрузки и вставки в deltastore. Операции deltastore обрабатываются в фоновом режиме. Для получения правильных результатов запросов кластеризованные индексы columnstore объединяют результаты запроса от columnstore и deltastore.
Переход строк в deltastore происходит в следующих случаях:
- если они вставляются с помощью инструкции
INSERT INTO ... VALUES; - В конце массовой нагрузки и меньше 102 400.
- в случае обновления (каждое обновление реализуется как операция удаления или вставки).
В deltastore также хранится список идентификаторов для удаленных строк, которые были помечены как удаленные, но еще не удалены физически из columnstore.
Дополнительные сведения о терминах и понятиях columnstore см. в статье "Общие сведения об индексах Columnstore".
Когда разностные группы строк заполнены, они сжимаются в columnstore
Прежде чем сжать группу строк в columnstore, кластеризованные индексы собирают 1 048 576 строк в каждой разностной группе строк. Это повышает степень сжатия индекса columnstore. Когда разностная группа строк достигает максимального количества строк, она переходит из OPEN CLOSED состояния в состояние. Фоновый процесс, который называется задачей переноса кортежей, проверяет наличие закрытых групп строк. При обнаружении закрытой группы строк она сжимается и сохраняется в columnstore.
Когда разностная группа строк была сжата, существующая разностная группа строк переходит в TOMBSTONE состояние, которое будет удалено позже перемещением кортежей, когда нет ссылки на нее, и новая сжатые группы строк помечаются как COMPRESSED.
Дополнительные сведения о состоянии группы строк см. в sys.dm_db_column_store_row_group_physical_stats.
Чтобы перестроить или реорганизовать индекс, вы можете принудительно сжать разностную группу строк в columnstore с помощью ALTER INDEX. Если во время сжатия возникает давление памяти, индекс columnstore может уменьшить количество строк в сжатой группе строк.
Дополнительные сведения о терминах и понятиях columnstore см. в статье "Общие сведения об индексах Columnstore".
Каждая секция таблицы содержит собственные группы строк и разностные группы
Понятие секционирования одинаково для двух кластеризованных индексов — индекса кучи и columnstore. При секционировании таблица разделяется на небольшие группы строк в соответствии с диапазоном значений столбцов. Часто используется для управления данными. Например, вы можете создать секцию для каждого года данных, а затем использовать переключение секций, чтобы архивировать данные для получения более экономичного хранилища. Переключение секций выполняется для индексов columnstore и упрощает перемещение секции данных в другое расположение.
Группы строк всегда определяются в пределах секции таблицы. При секционировании индекса columnstore каждая секция получает свои собственные сжатые группы строк и разностные группы строк.
Совет
Если вам нужно удалить данные из columnstore, попробуйте использовать секционирование таблиц. Переключение и усечение секций, которые больше не нужны, является эффективной стратегией удаления данных без создания фрагментации, введенной с помощью небольших групп строк.
Каждая секция может содержать несколько разностных групп строк
Каждая секция может содержать несколько разностных групп строк. Если индекс columnstore должен добавить данные в разностную группу строк и разностную группу строк заблокирован, индекс columnstore пытается получить блокировку другой разностной группы строк. Если нет разностных групп строк, индекс columnstore создает новую разностную группу строк. Например, у таблицы с 10 секциями может быть 20 и более разностных групп строк.
Объединение индексов columnstore и rowstore в одной таблице
Некластеризованный индекс содержит копию всех или части строк и столбцов в базовой таблице. Индекс определяется как один или несколько столбцов таблицы и включает дополнительное условие для фильтрации строк.
Можно создать обновляемый некластеризованный индекс columnstore в таблице rowstore. Индекс columnstore сохраняет копию данных, так что вам обязательно потребуется дополнительное хранилище. Однако данные в индексе columnstore сжимаются до меньшего размера, чем требуется таблица rowstore. Таким образом, вы сможете выполнять аналитику на основе индекса columnstore и транзакции на основе индекса rowstore одновременно. Columnstore обновляется при изменении данных в таблице rowstore, поэтому оба индекса работают с одинаковыми данными.
Индекс columnstore может включать один или несколько некластеризованных индексов rowstore. Это обеспечивает эффективность поиска по таблицам на основе базового индекса columnstore. Кроме того, появляется доступ к другим возможностям. Например, можно применить ограничение первичного ключа с помощью UNIQUE ограничения таблицы rowstore. Так как неуниковое значение не вставляется в таблицу rowstore, ядро СУБД не может вставить значение в columnstore.
Замечания, связанные с быстродействием
Определение некластеризованного индекса columnstore поддерживает использование отфильтрованных условий. Чтобы свести к минимуму негативное влияние на производительность, вызванное добавлением некластеризованного индекса columnstore для таблицы OLTP, можно использовать отфильтрованное условие для создания некластеризованного индекса columnstore только для холодных данных операционной рабочей нагрузки.
Таблица в памяти может включать один индекс columnstore. Ее можно создать при создании или добавлении таблицы позже с помощью ALTER TABLE (Transact-SQL). До SQL Server 2016 (13.x) только для дисковой таблицы может быть индекс columnstore.
Дополнительные сведения см. в статье Производительность запросов по индексам columnstore.
Руководство по проектированию
- Таблица rowstore может включать один обновляемый некластеризованный индекс columnstore. До SQL Server 2014 (12.x) индекс некластеризованного columnstore был только для чтения.
Дополнительные сведения см. в руководстве по проектированию индексов Columnstore.
Рекомендации по проектированию хэш-индекса
Все оптимизированные для памяти таблицы должны иметь по крайней мере один индекс, так как это индексы, которые соединяют строки вместе. В таблице, оптимизированной для памяти, каждый индекс также будет оптимизирован для памяти. Хэш-индексы являются одним из возможных типов индексов в таблице, оптимизированной для памяти. Дополнительные сведения см. в разделе "Индексы для таблиц, оптимизированных для памяти".
Область применения: SQL Server, База данных SQL Azure и Управляемый экземпляр SQL Azure.
Архитектура хэш-индекса
Хэш-индекс состоит из массива указателей. Каждый элемент массива называется хэш-контейнером.
- Каждый контейнер имеет размер 8 байт, в которых хранится адрес списка ссылок на записи ключей.
- Каждая запись представляет собой значение ключа индекса, к которому добавляется адрес соответствующей строки в оптимизированной для памяти таблице.
- Каждая запись указывает на следующую запись в списке ссылок на записи, связанных с текущим контейнером.
При определении индекса необходимо указать число контейнеров.
- Чем ниже соотношение сегментов к строкам таблицы или к отдельным значениям, тем длиннее среднее значение списка ссылок на контейнеры.
- Короткие списки обладают большим быстродействием по сравнению с длинными.
- Максимальное число контейнеров в хэш-индексах составляет 1 073 741 824.
Совет
Сведения о том, как определить право BUCKET_COUNT для данных, см. в разделе "Настройка количества сегментов хэш-индекса".
Хэш-функция применяется к ключевым столбцам индекса, и результат функции определяет, к какому контейнеру относится ключ. Каждый контейнер содержит указатель на строки, хэшированные значения ключей которых сопоставлены с этим контейнером.
Функция, используемая для хэширования индексов, имеет следующие характеристики.
- Ядро СУБД имеет одну хэш-функцию, используемую для всех хэш-индексов.
- Хэш-функция является детерминированной. Одно значение входного ключа всегда связано с одним контейнером в хэш-индексе.
- Несколько ключей индекса могут быть сопоставлены с тем же хэш-контейнером.
- Хэш-функция сбалансирована, а это означает, что распределение значений ключей индекса, связанных с хэш-контейнерами, соответствует распределению Пуассона или нормальному распределению, а не плоскому линейному распределению.
- Распределение Poisson не является даже распределением. Значения ключа индекса равномерно не распределяются в хэш-контейнерах.
- Если два ключа индекса сопоставлены с тем же хэш-контейнером , возникает конфликт хэша. Большое число конфликтов хэша может оказывать негативное влияние на операции чтения. Реалистичная цель состоит в том, чтобы 30 процентов сегментов содержали два разных ключевых значения.
Взаимозависимость хэш-индекса и контейнеров иллюстрируется на следующем рисунке.
Настройка количества сегментов хэш-индекса
Число контейнеров хэш-индекса указывается в момент создания индекса и может быть изменено с помощью синтаксиса ALTER TABLE...ALTER INDEX REBUILD.
В большинстве случаев идеальное число контейнеров должно находиться в диапазоне, в 1–2 раза превышающем число уникальных значений в ключе индекса.
Возможно, вы не всегда сможете предсказать, сколько значений может иметь определенный ключ индекса или будет иметь. Производительность обычно хороша, если BUCKET_COUNT значение находится в пределах 10 раз от фактического количества ключевых значений, а переоценка обычно лучше, чем недооценка.
Слишком мало контейнеров может иметь следующие недостатки:
- Возникает больше конфликтов хэша из-за уникальных значений ключей.
- Каждое уникальное значение вынуждено использовать один и тот же контейнер с другим уникальным значением.
- Средняя длина цепочки для контейнера возрастает.
- Чем длиннее цепочка контейнеров, тем медленнее скорость выполнения проверки на равенство индексов.
Слишком много контейнеров может иметь следующие недостатки:
- Слишком большое количество контейнеров может привести к более пустым контейнерам.
- Пустые контейнеры влияют на производительность полной проверки индекса. Если сканирование выполняется регулярно, рассмотрите возможность выбора количества контейнеров, близкого к количеству уникальных значений ключа индекса.
- Пустые контейнеры задействуют память, хотя каждый контейнер использует всего 8 байт.
Примечание.
При добавлении большего числа контейнеров цепочка записей, которые имеют повторяющееся значение, не уменьшается. Степень повторяемости значения используется для того, чтобы решить, правильный ли тип имеет индекс, а не для определения числа контейнеров.
Замечания, связанные с быстродействием
Производительность хэш-индекса обладает следующими характеристиками.
- Отличная, если предикат в предложении
WHEREзадает точное значение каждого столбца в ключе хэш-индекса. Хэш-индекс возвращается к сканированию с заданным предикатом неравенства. - Низкая, если в предикате в предложении
WHEREуказан диапазон значений ключа индекса. - Плохо, если предикат в
WHEREпредложении предусматривает одно конкретное значение для первого столбца ключа хэш-индекса двух столбцов, но не указывает значение для других столбцов ключа.
Совет
Предикат должен содержать все столбцы в ключе хэш-индекса. Для хэш-индекса требуется ключ (для хэша) для поиска в индексе.
Если ключ индекса состоит из двух столбцов и WHERE предложение предоставляет только первый столбец, ядро СУБД не имеет полного ключа для хэша. Это приводит к выполнению плана запроса на сканирование индекса.
Если используется хэш-индекс, а число уникальных ключей индекса равно 100 раз (или больше), чем число строк, рассмотрите возможность увеличения числа сегментов большего размера, чтобы избежать больших цепочек строк или использовать некластеризованный индекс .
Рекомендации по объявлению
Хэш-индекс может существовать только для таблицы, оптимизированной для памяти. Он не может существовать в таблице на основе диска.
Хэш-индекс можно объявить как:
UNIQUE, или может по умолчанию неуникироваться.NONCLUSTERED— значение по умолчанию.
Следующий пример синтаксиса создает хэш-индекс за пределами инструкции CREATE TABLE :
ALTER TABLE MyTable_memop
ADD INDEX ix_hash_Column2 UNIQUE
HASH (Column2) WITH (BUCKET_COUNT = 64);
Версии строк и сборка мусора
При изменении строки с помощью инструкции UPDATE в таблице, оптимизированной для памяти, создается обновленная версия строки. Во время транзакции обновления другие сеансы могут считывать старую версию строки, поэтому избежать замедления производительности, связанного с блокировкой строки.
Хэш-индекс также может иметь разные версии своих записей для размещения обновления.
Позже, когда старые версии больше не требуются, поток сборки мусора перебирает список контейнеров и их списки ссылок, удаляя старые записи. Поток сборки мусора работает быстрее, если списки ссылок короткие. Дополнительные сведения см. в статье Сборка мусора OLTP в памяти.
Рекомендации по проектированию некластеризованных индексов, оптимизированные для памяти
Некластеризованные индексы являются одним из возможных типов индексов в таблице, оптимизированной для памяти. Дополнительные сведения см. в разделе "Индексы для таблиц, оптимизированных для памяти".
Область применения: SQL Server, База данных SQL Azure и Управляемый экземпляр SQL Azure.
Архитектура некластеризованного индекса в памяти
Некластеризованные индексы в памяти реализуются с помощью структуры данных, которая называется BW-деревом. Она была изобретена и описана подразделением Microsoft Research в 2011 году. BW-дерево — это разновидность сбалансированного дерева без блокировок и кратковременных блокировок. Дополнительные сведения см. в разделе "Дерево Bw: дерево B для новых аппаратных платформ".
На высоком уровне дерево Bw-дерева можно понять как карту страниц, упорядоченных по идентификатору страницы (PidMap), объекту для выделения и повторного использования идентификаторов страниц (PidAlloc) и набора страниц, связанных с картой страниц и друг с другом. Эти три высокоуровневых подкомпоновки составляют базовую внутреннюю структуру дерева Bw-дерева.
Эта структура схожа со структурой обычного сбалансированного дерева в том плане, что каждая страница имеет набор упорядоченных ключевых значений и в индексе есть уровни, каждый из которых указывает на нижележащий уровень, а конечные уровни указывают на строки данных. Тем не менее есть несколько отличий.
Так же как и в случае с хэш-индексами, несколько строк данных могут быть связаны друг с другом (версии). Указателями на страницы между уровнями являются идентификаторы логических страниц, которые представляют собой смещения в таблице сопоставления страниц, которая, в свою очередь, содержит физические адреса всех страниц.
Изменение страниц индекса на месте не производится. Поэтому были введены новые разностные страницы.
- Для изменения страницы блокировка или кратковременная блокировка не требуется.
- Страницы индекса не являются фиксированным размером.
Значение ключа на каждой странице уровня, не относящееся к небезопасной, является самым высоким значением, которое указывает на дочерний элемент, и каждая строка также содержит идентификатор логической страницы страницы. Страница конечного уровня, помимо значения ключа, содержит физический адрес строки данных.
Подстановки точек похожи на деревья B, за исключением того, что страницы связаны только в одном направлении, SQL Server ядро СУБД следует правым указателям страницы, где каждая нелепая страница имеет наибольшее значение своего дочернего, а не наименьшее значение, как в дереве B.
Если страница конечного уровня должна измениться, sql Server ядро СУБД не изменяет саму страницу. Вместо этого SQL Server ядро СУБД создает разностную запись, описывающую изменение, и добавляет ее на предыдущую страницу. Затем оно также меняет адрес этой прежней страницы в таблице сопоставления страниц на адрес разностной записи, который теперь становится физическим адресом страницы.
Существует три различных операции, которые могут потребоваться для управления структурой дерева Bw: консолидации, разделения и слияния.
Консолидация разностных записей
Длинная цепочка разностных записей в конечном итоге может снизить производительность поиска, так как это может означать, что мы пересекаем длинные цепи при поиске по индексу. Если новая разностная запись добавляется в цепочку, которая уже содержит 16 элементов, изменения в разностных записях объединяются на страницу индекса со ссылкой, а затем перестроена страница, включая изменения, указанные новой разностной записью, которая вызвала консолидацию. У вновь созданной страницы есть тот же идентификатор страницы, но новый адрес памяти.
Разделение страницы
Страница индекса в дереве Bw растет по мере необходимости, начиная с хранения одной строки до хранения не более 8 КБ. После роста страницы индекса до 8 КБ новая вставка одной строки приводит к разделию страницы индекса. Для внутренней страницы это означает, что при добавлении другого ключевого значения и указателя на конечную страницу строка будет слишком большой, чтобы поместиться на страницу после включения всех разностных записей. Сведения о статистике в заголовке страницы для конечной страницы отслеживают, сколько пространства требуется для консолидации разностных записей. Эти сведения корректируются при добавлении каждой новой разностной записи.
Операция разделения выполняется в двух атомарных шагах. На следующей схеме предполагается, что на конечной странице выполняется разделение, так как ключ со значением 5 вставляется, а нелебезопасная страница указывает на конец текущей страницы конечного уровня (ключевое значение 4).

Шаг 1. Выделите две новые страницы P1 и P2разделите строки со старой P1 страницы на эти новые страницы, включая только что вставленную строку. Новый слот в таблице сопоставления страниц используется для хранения физического адреса страницы P2. Эти страницы P1 и P2 пока недоступны для параллельных операций. Кроме того, задается логический указатель на P1 P2 объект. Затем на одном атомарном шаге обновите таблицу сопоставления страниц, чтобы изменить указатель с старого P1 на новое P1.
Шаг 2. Нелиафетная страница указывает на P1 то, что нет прямого указателя на нелебезопасную страницу P2. P2 доступен только через P1. Чтобы создать указатель на небезопасную страницу, выделите новую нелифайлую страницу P2(внутреннюю страницу индекса), скопируйте все строки из старой небезопасной страницы и добавьте новую строку для указания P2. После этого в одном атомарном шаге обновите таблицу сопоставления страниц, чтобы изменить указатель с старой нелиафетной страницы на новую нелегивую страницу.
Слияние страниц
DELETE Если операция приводит к тому, что страница имеет менее 10 процентов максимального размера страницы (в настоящее время 8 КБ) или с одной строкой на ней, эта страница объединяется с непрерывной страницей.
При удалении строки со страницы добавляется разностная запись для операции удаления. Кроме того, выполняется проверка, чтобы определить, соответствует ли страница индекса (нелиафетная страница) для слияния. Эта проверка проверяет, не превышает ли оставшееся пространство после удаления строки меньше 10 процентов максимального размера страницы. Если это условие выполняется, слияние производится в три отдельных этапа.
На следующем рисунке предполагается, что DELETE операция удаляет значение ключа 10.

Шаг 1. Создается разностная страница, представляющая значение 10 ключа (синий треугольник), и его указатель на небезопасную страницу устанавливается на новую разностную страницу Pp1 . Кроме того, создается специальная страница слияния -delta (зеленый треугольник), которая связана с указанием разностной страницы. На этом этапе обе страницы (разностная и разностная страница) не отображаются для любой параллельной транзакции. На одном атомарном шаге указатель на страницу конечного уровня в таблице сопоставления страниц обновляется, чтобы указать на страницу P1 слияния-разностной страницы. На этом шаге запись для значения 10 ключа в Pp1 настоящее время указывает на страницу слияния-delta.
Шаг 2. Строка, представляющая ключевое значение 7 на странице Pp1 , отличной от нелифлекса, должна быть удалена, а запись для значения 10 ключа обновлена для указания P1. Для этого выделяется новая неклафовая страница Pp2 , а все строки Pp1 из них копируются, за исключением строки, представляющей значение 7ключа, а затем строка для значения 10 ключа обновляется, чтобы указать на страницу P1. После этого на одном атомарном шаге точка входа Pp1 таблицы сопоставления страниц обновляется до точки Pp2. Pp1 больше недоступен.
Шаг 3. Страницы P2 конечного уровня и объединены, P1 а разностные страницы удалены. Для этого выделяется новая страница, а строки из P2 и P1 объединяются, а изменения разностной страницы P3 включаются в новуюP3. Затем на одном атомарном шаге запись таблицы сопоставления страниц, указывающей на страницу, обновляется, чтобы указать на страницу P1 P3.
Замечания, связанные с быстродействием
При запросе оптимизированной для памяти таблицы с предикатами неравенства некластеризованные индексы работают лучше, чем некластеризованные хэш-индексы.
Столбец в таблице, оптимизированной для памяти, может быть частью хэш-индекса и некластеризованного индекса.
Если ключевой столбец в некластеризованном индексе имеет много повторяющихся значений, производительность может снизиться для обновлений, вставок и удаления. Одним из способов повышения производительности в этой ситуации является добавление столбца, который имеет лучшую выборку в ключе индекса.
Связанный контент
- Инструкция CREATE INDEX (Transact-SQL)
- Оптимизация обслуживания индексов позволяет повысить производительность запросов и снизить уровень потребления ресурсов
- Секционированные таблицы и индексы
- Индексы для оптимизированных для памяти таблиц
- Общие сведения об индексах columnstore
- Индексы вычисляемых столбцов
- Настройка некластеризованных индексов с предложениями отсутствующих индексов