CREATE TABLE AS SELECT
Область применения: ![]() Azure Synapse Analytics Analytics
Azure Synapse Analytics Analytics ![]() Platform System (PDW)
Platform System (PDW)
CREATE TABLE AS SELECT (CTAS) — одна из наиболее важных доступных функций T-SQL. Это полностью распараллеленная операция, которая создает таблицу на основе выходных данных инструкции SELECT. CTAS позволяет быстро и легко создать копию таблицы.
CTAS можно использовать, например, для решения следующих задач:
- Повторное создание таблицы с другим столбцом распределения хэша.
- Повторное создание таблицы в виде реплицированной таблицы.
- Создание индекса columnstore для всех столбцов таблицы.
- Отправка запроса к внешним данным или импорт внешних данных.
Примечание.
Поскольку с помощью CTAS можно создавать таблицы, в этом разделе мы не будем повторять содержимое раздела CREATE TABLE. Вместо этого мы опишем различия между инструкциями CTAS и CREATE TABLE. Сведения об инструкции CREATE TABLE см. в разделе Инструкция CREATE TABLE (Azure Synapse Analytics).
- Этот синтаксис не поддерживается бессерверным пулом SQL в Azure Synapse Analytics.
- CTAS поддерживается в хранилище в Microsoft Fabric.
![]() Соглашения о синтаксисе Transact-SQL
Соглашения о синтаксисе Transact-SQL
Синтаксис
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
Аргументы
Дополнительные сведения см. в подразделе "Аргументы" раздела, посвященного инструкции CREATE TABLE.
Параметры столбца
column_name [ ,...n ]
Имена столбцов не позволяют использовать параметры столбцов, упомянутые в CREATE TABLE. Вместо этого можно указать необязательный список из одного или нескольких имен столбцов для новой таблицы. Столбцы в новой таблице используют указанные имена. При указании имен столбцов число столбцов в списке столбцов должно совпадать с числом столбцов в результатах выборки. Если имена столбцов не указаны, новая целевая таблица использует имена столбцов в результатах инструкции select.
Вы не можете указать другие параметры столбца, такие как типы данных, параметры сортировки или значение NULL. Каждый из этих атрибутов определяется на основе результатов выполнения инструкции SELECT. Тем не менее инструкцию SELECT можно использовать для изменения атрибутов. Пример см. в разделе Использование инструкции CTAS для изменения атрибутов столбца.
Параметры распространения таблицы
Дополнительные сведения и инструкции по выбору столбца распределения см. в подразделе Параметры распределения таблицы раздела, посвященного инструкции CREATE TABLE. Рекомендации по выбору распределения для таблицы на основе фактического использования или примеры запросов см. в статье Помощник по распространению в Azure Synapse SQL.
DISTRIBUTION = HASH (distribution_column_name) | ROUND_ROBIN | Инструкция РЕПЛИЦирует инструкцию CTAS, требуя параметра распространения и не имеет значений по умолчанию. Это отличает ее от инструкции CREATE TABLE, у которой есть параметры по умолчанию.
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] ) Распределяет строки на основе хэш-значений до восьми столбцов, что позволяет более равномерно распределять данные базовой таблицы, уменьшая количество данных с течением времени и повышая производительность запросов.
Примечание.
- Чтобы включить функцию, измените уровень совместимости базы данных на 50 с помощью этой команды. Дополнительные сведения о настройке уровня совместимости базы данных см. в разделе ALTER DATABASE SCOPED CONFIGURATION. Например:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - Чтобы отключить функцию распределения с несколькими столбцами (MCD), выполните следующую команду, чтобы изменить уровень совместимости базы данных на AUTO. Например:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;существующие таблицы MCD останутся нечитаемыми. Запросы к таблицам MCD будут возвращать эту ошибку:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- Чтобы восстановить доступ к таблицам MCD, снова включите эту функцию.
- Чтобы загрузить данные в таблицу MCD, используйте инструкцию CTAS, а источник данных должен представлять собой таблицы Synapse SQL.
- CTAS в целевых таблицах MCD HEAP не поддерживается. Вместо этого используйте INSERT SELECT в качестве обходного решения для загрузки данных в таблицы MCD HEAP.
- Использование SSMS для создания скрипта для создания таблиц MCD в настоящее время поддерживается за пределами SSMS версии 19.
Дополнительные сведения и инструкции по выбору столбца распределения см. в подразделе Параметры распределения таблицы раздела, посвященного инструкции CREATE TABLE.
Рекомендации по оптимальному распределению на основе рабочих нагрузок см. в помощнике по распространению Synapse SQL (предварительная версия).
Параметры секционирования таблицы
Оператор CTAS создает непартиментированную таблицу по умолчанию, даже если исходная таблица секционирована. Чтобы создать секционированную таблицу с помощью инструкции CTAS, необходимо указать параметр секционирования.
Дополнительные сведения см. в подразделе Параметры секционирования таблицы раздела, посвященного инструкции CREATE TABLE.
Инструкция SELECT
Оператор SELECT — это основное различие между CTAS и CREATE TABLE.
WITH common_table_expression
Задается временно именованный результирующий набор, называемый обобщенным табличным выражением (ОТВ). Дополнительные сведения см. в статье WITH common_table_expression (Transact-SQL).
SELECT select_criteria
Заполняет новую таблицу результатами выполнения инструкции SELECT. select_criteria являются основной частью инструкции SELECT и определяют, какие данные нужно скопировать в новую таблицу. Сведения об инструкциях SELECT см. в статье SELECT (Transact-SQL).
Указание запроса
Пользователи могут задать для параметра MAXDOP целое значение, чтобы управлять максимальной степенью параллелизма. Если параметр MAXDOP имеет значение 1, запрос выполняется одним потоком.
Разрешения
Инструкции CTAS требуется разрешение SELECT для всех объектов, указанных в критериях_выборки.
Разрешения на создание таблицы см. в подразделе Разрешения раздела, посвященного инструкции CREATE TABLE.
Замечания
Дополнительные сведения см. в подразделе Общие замечания раздела, посвященного инструкции CREATE TABLE.
ограничения
Дополнительные сведения об ограничениях и ограничениях см. в разделе "Ограничения и ограничения" в CREATE TABLE.
Упорядоченный кластеризованный индекс columnstore можно создать на столбцах любых типов данных, поддерживаемых в Azure Synapse Analytics, за исключением строковых столбцов.
SET ROWCOUNT (Transact-SQL) не влияет на инструкцию CTAS. Чтобы обеспечить аналогичное поведение, воспользуйтесь инструкцией TOP (Transact-SQL).
CTAS не поддерживает
OPENJSONфункцию в рамках инструкцииSELECT. В качестве альтернативы используйтеINSERT INTO ... SELECT. Например:DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
Режим блокировки
Дополнительные сведения см. в подразделе Режим блокировки раздела, посвященного инструкции CREATE TABLE.
Производительность
Для таблиц с распределенным хэшем с помощью инструкции CTAS можно выбрать другой столбец распределения, что позволит повысить производительность операций соединения и агрегатов. Если выбор другого столбца распространения не является вашей целью, вы будете иметь лучшую производительность CTAS, если указать тот же столбец распространения, так как это позволит избежать распространения строк.
Если вы используете CTAS для создания таблицы и производительности не является фактором, можно указать ROUND_ROBIN , чтобы избежать необходимости выбирать столбец распределения.
Чтобы избежать перемещения данных в последующих запросах, можно указать REPLICATE, что приведет к увеличению размера хранилища для загрузки полной копии таблицы на каждом вычислительном узле.
Примеры копирования таблицы
А. Использование инструкции CTAS для копирования таблицы
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
Одно из наиболее частых применений CTAS — создание копии таблицы для изменения DDL. Например, если вы изначально создали таблицу как ROUND_ROBIN и теперь хотите изменить ее на таблицу с распределением по столбцу, вы можете изменить столбец распределения с помощью CTAS. CTAS также может использоваться для изменения секционирования, индексирования и типов столбцов.
Предположим, что вы создали эту таблицу с указанием HEAP и использованием стандартного типа распределения ROUND_ROBIN.
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Теперь вы хотите создать новую копию этой таблицы с кластеризованным индексом columnstore, чтобы получить преимущества производительности таблиц с кластеризованными индексами columnstore. Вы также хотите распространить эту таблицу ProductKey , так как ожидается присоединение к этому столбцу и хотите избежать перемещения данных во время соединения ProductKey. Наконец, вы также хотите добавить секционирование по столбцу OrderDateKey, чтобы быстро удалять старые данные путем удаления старых секций. Ниже приведена инструкция CTAS, которая будет копировать старую таблицу в новую таблицу:
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Наконец, вы можете переименовать таблицы, чтобы поместить старую таблицу на место новой и удалить старую.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Примеры параметров столбцов
B. Использование инструкции CTAS для изменения атрибутов столбца
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
В этом примере инструкция CTAS используется для изменения типов данных, допустимости значений NULL и параметров сортировки для нескольких столбцов в таблице DimCustomer2.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
В качестве последнего шага можно изменить имена таблиц с помощью инструкции RENAME (Transact-SQL). После этого DimCustomer2 станет новой таблицей.
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
Примеры распределения таблиц
C. Использование инструкции CTAS для изменения метода распределения таблицы
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
В этом простом примере показано, как изменить метод распределения таблицы. Для иллюстрации механизма изменения в этом примере таблица с распределенным хэшем изменяется на таблицу с циклическим распределением и затем обратно на таблицу с распределенным хэшем. Окончательная таблица совпадает с исходной таблицей.
В большинстве случаев вам не нужно изменять хэш-распределенную таблицу на таблицу с циклическим перебором. Чаще требуется изменить таблицу с циклическим распределением на таблицу с распределенным хэшем. Например, вы можете изначально загрузить новую таблицу как таблицу с циклическим распределением и затем изменить ее на таблицу с распределенным хэшем для повышения производительности операций соединения.
В этом примере используется образец базы данных AdventureWorksDW. Инструкции по загрузке версии Azure Synapse Analytics: Краткое руководство. Создание выделенного пула SQL (ранее — Хранилище данных SQL) в Azure Synapse Analytics и отправка в него запросов с помощью портала Azure.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Затем измените таблицу обратно на таблицу с распределенным хэшем.
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D. Использование инструкции CTAS для преобразования таблицы в реплицированную таблицу
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
Этот пример относится к преобразованию таблицы с циклическим распределением или таблицы с распределенным хэшем в реплицированную таблицу. В этом примере предыдущий способ изменения типа распределения продвигается на один шаг дальше. Так как DimSalesTerritory является измерением и скорее всего таблицей меньшего размера, вы можете создать таблицу повторно в виде реплицированной таблицы, чтобы избежать перемещения данных при присоединении к другим таблицам.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Е. Использование инструкции CTAS для создания таблицы с меньшим количеством столбцов
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
В следующем примере создается таблица myTable (c, ln) с циклическим распределением. Новая таблица содержит только два столбца. В этом примере в инструкции SELECT в качестве имен столбцов используются псевдонимы столбцов.
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
Примеры указания запросов
F. Использование указания запроса с инструкцией CREATE TABLE AS SELECT (CTAS)
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
В этом запросе показан базовый синтаксис для указания запроса на соединение с инструкцией CTAS. После отправки запроса Azure Synapse Analytics применяет стратегию хэш-соединения при создании плана запроса для каждого отдельного дистрибутива. Дополнительные сведения об указании запроса на хэш-соединение см. в разделе Предложение OPTION (Transact-SQL).
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
Примеры внешних таблиц
G. Использование инструкции CTAS для импорта данных из хранилища BLOB-объектов Azure
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
Чтобы импортировать данные из внешней таблицы, используйте CREATE TABLE AS SELECT, чтобы выбрать из внешней таблицы. Синтаксис для выбора данных из внешней таблицы в Azure Synapse Analytics аналогичен синтаксису для выбора данных из обычной таблицы.
В следующем примере определяется внешняя таблица данных в учетной записи Хранилище BLOB-объектов Azure. Затем используется инструкция CREATE TABLE AS SELECT для выбора данных из внешней таблицы. Это импортирует данные из Хранилище BLOB-объектов Azure текстовых файлов с разделителями и сохраняет данные в новую таблицу Azure Synapse Analytics.
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. Использование инструкции CTAS для импорта данных Hadoop из внешней таблицы
Область применения: Analytics Platform System (PDW)
Чтобы импортировать данные из внешней таблицы, используйте инструкцию CREATE TABLE AS SELECT для выбора данных из внешней таблицы. Синтаксис для выбора данных из внешней таблицы в систему платформы аналитики (PDW) совпадает с синтаксисом для выбора данных из обычной таблицы.
В следующем примере определяется внешняя таблица в кластере Hadoop. Затем используется инструкция CREATE TABLE AS SELECT для выбора данных из внешней таблицы. При этом данные из файлов с разделителями текста Hadoop импортируются и хранятся в новой таблице платформы Аналитики (PDW).
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
Примеры использования инструкции CTAS для замены кода SQL Server
Используйте инструкцию CTAS, чтобы обойти некоторые неподдерживаемые функции. Наряду с возможностью запуска кода в хранилище данных переработка существующего кода для использования инструкции CTAS обычно повышает производительность. Это является результатом полностью параллельной структуры инструкции CTAS.
Примечание.
Попробуйте решить задачу "в первую очередь с инструкцией CTAS". Если вы считаете, что можете решить задачу с помощью CTAS, то обычно это лучший способ ее решения — даже если в результате будут созданы дополнительные данные.
I. Использование инструкции CTAS вместо SELECT..INTO
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
В коде SQL Server для заполнения таблицы результатами выполнения инструкции SELECT обычно используется SELECT..INTO. Ниже приведен пример использования инструкции SQL Server SELECT..INTO.
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
Этот синтаксис не поддерживается в Azure Synapse Analytics и параллельном хранилище данных. В этом примере показано, как переписать предыдущую инструкцию SELECT..INTO в виде инструкции CTAS. Вы можете выбрать любой из параметров DISTRIBUTION, описанных в синтаксисе CTAS. В этом примере используется метод распределения ROUND_ROBIN.
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. Использование инструкции CTAS для упрощения инструкций слияния
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
Операторы слияния, по крайней мере, частично могут быть заменены на CTAS. Вы можете объединить INSERT и UPDATE в одну инструкцию. Любые удаленные записи потребуется включить во вторую инструкцию.
Пример следующего UPSERT вида:
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. явно указывайте тип данных и допустимость нулевого результата.
Область применения: Azure Synapse Analytics и система платформы аналитики (PDW)
При переносе кода SQL Server в Azure Synapse Analytics вы можете обнаружить, что выполняется в этом типе кода:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
Инстинктивно вы можете подумать, что этот код следует перенести в CTAS, и будете правы. Однако в этом подходе кроется проблема.
Следующий код не позволяет получить тот же самый результат:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
Обратите внимание, что столбец "result" переносит тип данных и допустимость значений NULL для выражения. Это может привести к некоторым различиям в значениях, если не соблюдать осторожность.
Попробуйте следующий код в качестве примера:
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
Значение, сохраненное для результата, отличается. Так как сохраненное значение в столбце результатов используется в других выражениях, ошибка становится еще более значительной.
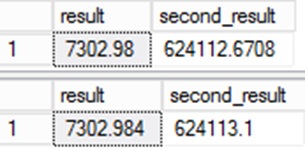
Это важно для переноса данных. Несмотря на то что второй запрос, возможно, более точным является проблема. Данные будут отличаться по сравнению с исходной системой, и это приведет к вопросам целостности при миграции. Это один из тех редких случаев, когда "неправильный" ответ на самом деле является правильным!
Причина несоответствия между двумя результатами заключается в неявном преобразовании типов. В первом примере в таблице приводится определение столбца. При вставке строки происходит неявное преобразование типов. Во втором примере неявное преобразование типов отсутствует, так как выражение определяет тип данных столбца. Обратите внимание, что столбец во втором примере определен как столбец NULLable, в то время как в первом примере он не имеет. При создании таблицы в первом примере была явно указана допустимость значений NULL для столбца. Во втором примере оно осталось в выражении, и по умолчанию это приведет к NULL определению.
Для устранения этих проблем необходимо явно задать преобразование типов и допустимость значений NULL в части SELECT инструкции CTAS. Эти свойства нельзя задать в части создания таблицы.
В этом примере показано, как исправить код:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Обратите внимание на следующее в примере:
- Можно было использовать CAST или CONVERT.
- ISNULL используется для принудительного применения NULLability not COALESCE.
- ISNULL — это внешняя функция.
- Вторая часть ISNULL является константой.
0
Примечание.
Для правильной установки допустимости значений NULL обязательно используйте ISNULL, а не COALESCE. COALESCE не является детерминированной функцией, и поэтому результат выражения всегда может иметь значение NULL. Функция ISNULL отличается от нее. Она является детерминированной. Поэтому когда вторая часть функции ISNULL является константой или литералом, результирующим значением будет NOT NULL.
Этот совет не просто полезен для обеспечения целостности вычислений. Также важно переключение секций таблиц. Представьте, что в качестве факта определена следующая таблица:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
Однако поле значения — это вычисляемое выражение, которое не является частью исходных данных.
Для создания секционированного набора данных рассмотрите следующий пример:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
Запрос выполняется без ошибок. Проблема возникает при попытке выполнить переключение секций. Определения таблиц не совпадают. Чтобы определения таблиц совпадали, необходимо изменить инструкцию CTAS.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Таким образом, рекомендуется использовать инструкцию CTAS для обеспечения согласованности типов и поддержания допустимости значений NULL. Это помогает поддерживать целостность вычислений и обеспечивает возможность переключения секций.
L. Создание упорядоченного кластеризованного индекса columnstore при помощи MAXDOP 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Следующие шаги
- CREATE EXTERNAL DATA SOURCE (Transact-SQL)
- CREATE EXTERNAL FILE FORMAT (Transact-SQL)
- CREATE EXTERNAL TABLE (Transact-SQL)
- CREATE EXTERNAL TABLE AS SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP TABLE (Transact-SQL)
- DROP EXTERNAL TABLE (Transact-SQL)
- Инструкция ALTER TABLE (Transact-SQL)
- ALTER EXTERNAL TABLE (Transact-SQL)
Область применения: ![]() хранилище в Microsoft Fabric
хранилище в Microsoft Fabric
CREATE TABLE AS SELECT (CTAS) — одна из наиболее важных доступных функций T-SQL. Это полностью распараллеленная операция, которая создает таблицу на основе выходных данных инструкции SELECT. CTAS позволяет быстро и легко создать копию таблицы.
Например, используйте CTAS в хранилище в Microsoft Fabric, чтобы:
- Создайте копию таблицы с некоторыми столбцами исходной таблицы.
- Создайте таблицу, которая является результатом запроса, который присоединяет другие таблицы.
Дополнительные сведения об использовании CTAS в хранилище в Microsoft Fabric см. в разделе "Прием данных в хранилище" с помощью Transact-SQL.
Примечание.
Поскольку с помощью CTAS можно создавать таблицы, в этом разделе мы не будем повторять содержимое раздела CREATE TABLE. Вместо этого мы опишем различия между инструкциями CTAS и CREATE TABLE. Сведения о CREATE TABLE см . в инструкции CREATE TABLE .
![]() Соглашения о синтаксисе Transact-SQL
Соглашения о синтаксисе Transact-SQL
Синтаксис
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
Аргументы
Дополнительные сведения см. в разделе "Аргументы" в CREATE TABLE для Microsoft Fabric.
Параметры столбца
column_name [ ,...n ]
Имена столбцов не позволяют использовать параметры столбцов, упомянутые в CREATE TABLE. Вместо этого можно указать необязательный список из одного или нескольких имен столбцов для новой таблицы. Столбцы в новой таблице используют указанные имена. При указании имен столбцов число столбцов в списке столбцов должно совпадать с числом столбцов в результатах выборки. Если имена столбцов не указаны, новая целевая таблица использует имена столбцов в результатах инструкции select.
Вы не можете указать другие параметры столбца, такие как типы данных, параметры сортировки или значение NULL. Каждый из этих атрибутов определяется на основе результатов выполнения инструкции SELECT. Тем не менее инструкцию SELECT можно использовать для изменения атрибутов.
Инструкция SELECT
Оператор SELECT — это основное различие между CTAS и CREATE TABLE.
SELECT select_criteria
Заполняет новую таблицу результатами выполнения инструкции SELECT. select_criteria являются основной частью инструкции SELECT и определяют, какие данные нужно скопировать в новую таблицу. Сведения об инструкциях SELECT см. в статье SELECT (Transact-SQL).
Примечание.
В Microsoft Fabric использование переменных в CTAS запрещено.
Разрешения
Инструкции CTAS требуется разрешение SELECT для всех объектов, указанных в критериях_выборки.
Разрешения на создание таблицы см. в подразделе Разрешения раздела, посвященного инструкции CREATE TABLE.
Замечания
Дополнительные сведения см. в подразделе Общие замечания раздела, посвященного инструкции CREATE TABLE.
ограничения
SET ROWCOUNT (Transact-SQL) не влияет на инструкцию CTAS. Чтобы обеспечить аналогичное поведение, воспользуйтесь инструкцией TOP (Transact-SQL).
Дополнительные сведения см. в подразделе Ограничения раздела, посвященного инструкции CREATE TABLE.
Режим блокировки
Дополнительные сведения см. в подразделе Режим блокировки раздела, посвященного инструкции CREATE TABLE.
Примеры копирования таблицы
Дополнительные сведения об использовании CTAS в хранилище в Microsoft Fabric см. в разделе "Прием данных в хранилище" с помощью Transact-SQL.
А. Использование инструкции CTAS для изменения атрибутов столбца
В этом примере CTAS используется для изменения типов данных и допустимости null для нескольких столбцов в DimCustomer2 таблице.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. Использование инструкции CTAS для создания таблицы с меньшим количеством столбцов
В следующем примере создается таблица с именем myTable (c, ln). Новая таблица содержит только два столбца. В этом примере в инструкции SELECT в качестве имен столбцов используются псевдонимы столбцов.
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. Использование инструкции CTAS вместо SELECT..INTO
В коде SQL Server для заполнения таблицы результатами выполнения инструкции SELECT обычно используется SELECT..INTO. Ниже приведен пример использования инструкции SQL Server SELECT..INTO.
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
В этом примере показано, как переписать предыдущую инструкцию SELECT..INTO в виде инструкции CTAS.
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D. Использование инструкции CTAS для упрощения инструкций слияния
Операторы слияния, по крайней мере, частично могут быть заменены на CTAS. Вы можете объединить INSERT и UPDATE в одну инструкцию. Любые удаленные записи потребуется включить во вторую инструкцию.
Пример следующего UPSERT вида:
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;