Изучение производительности и безопасности
Экосистема Azure предлагает несколько вариантов производительности и безопасности для экземпляра SQL Server на виртуальной машине Azure. Каждый вариант предоставляет несколько возможностей, таких как различные типы дисков, которые соответствуют требованиям к емкости и производительности рабочей нагрузки.
Рекомендации по работе с хранилищем
Для SQL Server требуется высокопроизводительное хранилище, чтобы обеспечить надежное функционирование приложений, будь то локальный экземпляр или приложение, установленное на виртуальной машине Azure. Azure предоставляет разнообразные решения для хранения данных в соответствии с особенностями рабочей нагрузки. Azure предлагает хранилища различного типа (BLOB-объекты, файлы, очереди, таблицы). В большинстве случаев для рабочих нагрузок будут использоваться управляемые диски Azure. Исключением является экземпляр отказоустойчивого кластера, который может быть создан в хранилище файлов, а для резервных копий будет использоваться хранилище BLOB-объектов. Управляемые диски Azure функционируют как устройство хранения блочного уровня, выделенное для виртуальной машины Azure. Управляемые диски предоставляют ряд преимуществ, к которым относятся доступность 99,999 %, масштабируемое развертывание (можно использовать до 50 000 дисков виртуальных машин в каждой подписке для каждого региона), а также интеграция с группами и зонами доступности, что обеспечивает более высокий уровень устойчивости в случае сбоя.
Для всех управляемых дисков Azure выполняется шифрование двух типов. Шифрование на стороне сервера Azure выполняет служба хранения и представляет собой шифрование неактивных данных. Для шифрования дисков Azure используется BitLocker в Windows и DM-Crypt в Linux. Эти средства обеспечивают шифрование ОС и диска данных внутри виртуальной машины. Обе указанные технологии интегрируются с Azure Key Vault и позволяют пользователям использовать собственные ключи шифрования.
Каждая из виртуальных машин имеет не менее двух дисков, связанных с ней:
Диск операционной системы. Для каждой виртуальной машины потребуется диск операционной системы, содержащий загрузочный том. Это должен быть диск C:\ в случае виртуальной машины Windows или /dev/sda1 в Linux. Операционная система будет автоматически установлена на диск операционной системы.
Временный диск. Каждая виртуальная машина будет содержать один диск, используемый для временного хранения данных. Это хранилище предназначено для данных, которые не должны быть устойчивыми, например файлов страниц или файлов подкачки. Так как диск является временным, его не следует использовать для хранения критически важных данных, таких как файлы базы данных или журналов транзакций, так как они будут потеряны во время обслуживания или перезагрузки виртуальной машины. Данный диск будет подключен как D:\ в Windows и /dev/sdb1 в Linux.
Кроме того, к виртуальным машинам Azure, на которых выполняется SQL Server, можно и нужно добавить дополнительные диски данных.
- Диски данных. Термин "диск данных" используется на портале Azure, но на практике такие диски представляют собой просто дополнительные управляемые диски, добавленные к виртуальной машине. Эти диски можно объединить в пул для увеличения количества доступных операций ввода-вывода в секунду и емкости диска благодаря применению технологии дисковых пространств в Windows или функции управления логическими томами в Linux.
Кроме того, каждый диск может относиться к одному из следующих типов.
| Компонент | Диск (цен. категория "Ультра") | Диск SSD (цен. категория "Премиум") | SSD (цен. категория "Стандартный") | HDD (цен. категория "Стандартный") |
|---|---|---|---|---|
| Тип диска | SSD | SSD | SSD | HDD |
| Оптимально для | Интенсивные рабочие нагрузки по вводу-выводу | Рабочая нагрузка с учетом производительности | Упрощенные рабочие нагрузки | Резервная копия, некритические рабочие нагрузки |
| Максимальный размер диска | 65,536 Гиб | 32 767 ГиБ | 32 767 ГиБ | 32 767 ГиБ |
| Максимальная пропускная способность | 2000 МБ/с | 900 МБ/с | 750 МБ/с | 500 МБ/с |
| Maкс. количество операций ввода-вывода в секунду | 160 000 | 20 000 | 6000 | 2 000 |
В соответствии с рекомендациями по SQL Server в Azure для повышения количества операций ввода-вывода в секунду и емкости хранилища лучше всего использовать диски "Премиум", объединенные в пул. Файлы данных должны храниться в своем собственном пуле и кэшироваться при чтении на дисках Azure.
Файлы журнала транзакций не будут пользоваться этим кэшированием, поэтому эти файлы должны переходить в собственный пул без кэширования. TempDB может при необходимости перейти в собственный пул или использовать временный диск виртуальной машины, который обеспечивает низкую задержку, так как физически подключен к физическому серверу, на котором работают виртуальные машины. Для корректно настроенных SSD-дисков "Премиум" задержка будет составлять несколько миллисекунд. Для критически важных рабочих нагрузок, требующих еще меньшей задержки, следует учитывать возможность применения SSD-дисков "Ультра".
Вопросы безопасности
Существует несколько отраслевых нормативных требований и стандартов, которым соответствует Azure, что позволяет создать решение, соответствующее системе SQL Server, работающей на виртуальной машине.
Microsoft Defender для SQL
Microsoft Defender для SQL обеспечивает поддержку функций безопасности в Центре безопасности Azure, таких как оценки уязвимости и оповещения безопасности.
Azure Defender для SQL можно использовать для выявления и устранения потенциальных уязвимостей в экземпляре и базе данных SQL Server. Функция оценки уязвимостей может обнаруживать потенциальные риски в среде SQL Server и помогает устранить их. Этот компонент предоставляет сведения о состоянии безопасности и предлагает практические действия для устранения проблем с безопасностью.
Центр безопасности Azure
Центр безопасности Azure — это единая система управления безопасностью, которая оценивает и предлагает возможности для улучшения нескольких аспектов безопасности среды данных. Центр безопасности Azure дает полное представление о работоспособности системы безопасности всех гибридных облачных ресурсов.
Замечания, связанные с быстродействием
Большинство существующих локальных функций производительности SQL Server также доступны на виртуальных машинах Azure. Среди предлагаемых вариантов — сжатие данных, которое может повысить производительность рабочих нагрузок с интенсивным вводом-выводом, уменьшая размер базы данных. Аналогичным образом секционирование таблиц и индексов может повысить производительность запросов больших таблиц, улучшая производительность и масштабируемость.
Секционирование таблиц в хранилище данных SQL
Секционирование таблиц дает множество преимуществ, но часто эта стратегия рассматривается только в том случае, если таблица становится достаточно большой, что начинает компрометации производительности запросов. Определение того, какие таблицы являются кандидатами для секционирования таблиц, является хорошей практикой, что может привести к меньшему нарушению и вмешательству. При фильтрации данных с помощью столбца секционирования доступ осуществляется только к подмножествам данных, а не ко всей таблице. Аналогичным образом операции обслуживания в секционированной таблице сокращают продолжительность обслуживания, например путем сжатия определенных данных в конкретной секции или перестроения определенных секций индекса.
При определении секции таблицы необходимо выполнить четыре основных шага.
- Создание файловых групп, определяющих файлы, участвующие при создании секций.
- Создание функции секционирования, определяющее правила секционирования на основе указанного столбца.
- Создание схемы секционирования, определяющей файловую группу каждой секции.
- Таблица для секционирования.
В приведенном ниже примере показано, как создать функцию секционирования 1 января 2021 г. по 1 декабря 2021 г. и распределить секции между разными файловыми группами.
-- Partition function
CREATE PARTITION FUNCTION PartitionByMonth (datetime2)
AS RANGE RIGHT
-- The boundary values defined is the first day of each month, where the table will be partitioned into 13 partitions
FOR VALUES ('20210101', '20210201', '20210301',
'20210401', '20210501', '20210601', '20210701',
'20210801', '20210901', '20211001', '20211101',
'20211201');
-- The partition scheme below will use the partition function created above, and assign each partition to a specific filegroup.
CREATE PARTITION SCHEME PartitionByMonthSch
AS PARTITION PartitionByMonth
TO (FILEGROUP1, FILEGROUP2, FILEGROUP3, FILEGROUP4,
FILEGROUP5, FILEGROUP6, FILEGROUP7, FILEGROUP8,
FILEGROUP9, FILEGROUP10, FILEGROUP11, FILEGROUP12);
-- Creates a partitioned table called Order that applies PartitionByMonthSch partition scheme to partition the OrderDate column
CREATE TABLE Order ([Id] int PRIMARY KEY, OrderDate datetime2)
ON PartitionByMonthSch (OrderDate) ;
GO
Сжатие данных
SQL Server предлагает различные варианты сжатия данных. Хотя SQL Server по-прежнему хранит сжатые данные на страницах размером 8 КБ, при сжатии данных на данной странице можно хранить больше строк данных, что позволяет запросу читать меньше страниц. Чтение меньшего числа страниц имеет двойное преимущество: уменьшается объем физических операций ввода-вывода и появляется возможность хранить больше строк в буферном пуле, что позволяет эффективнее использовать память. Рекомендуется включить сжатие страниц базы данных, если это необходимо.
Преимущество сжатия заключается в том, что для него требуется небольшое количество ресурсов ЦП, однако в большинстве случаев преимущества для операций ввода-вывода хранилища значительно перевешивают любое дополнительное использование процессора.
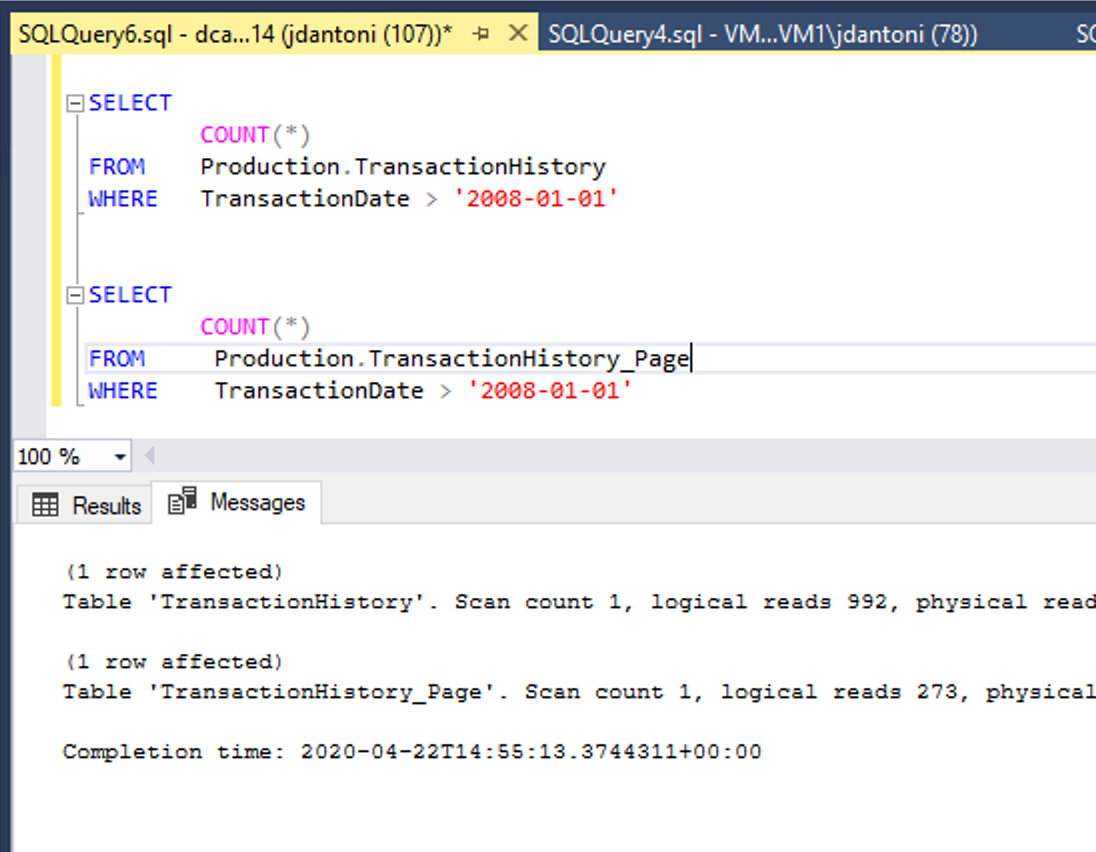
На рисунке выше показано это преимущество производительности. Эти таблицы имеют одинаковые базовые индексы. Единственное отличие заключается в том, что кластеризованные и некластеризованные индексы в таблице Production.TransactionHistory_Page имеют сжатые страницы. Запрос к объекту со сжатыми страницами выполняет на 72 % меньше логических операций чтения, чем запрос, использующий несжатые объекты.
Сжатие реализуется в SQL Server на уровне объектов. Каждый индекс или таблицу можно сжать по отдельности. Вы также можете сжимать секции в секционированной таблице или индексе. Вы можете оценить, сколько места будет сохранено с помощью системной хранимой процедуры sp_estimate_data_compression_savings. До SQL Server 2019 эта процедура не поддерживала индексы columnstore или архивное сжатие columnstore.
Сжатие строк . Сжатие строк является довольно простым и не приводит к большим затратам. Однако это не обеспечивает одинаковое количество сжатия (измеряемое на процентном снижении места в хранилище), которое может предложить сжатие страницы. Сжатие строк, по сути, сохраняет каждое значение в каждом столбце в строке, занимая минимальный объем пространства. Оно использует формат хранения переменной длины для числовых типов данных, таких как целое число, число с плавающей точкой и десятичное число, и сохраняет символьные строки фиксированной длины в формате переменной длины.
Сжатие страниц Сжатие страниц — это надмножество сжатия строк, так как все страницы изначально сжимаются на уровне строк. Затем к данным применяются сочетания методов, которые называются сжатием префиксов и словаря. Сжатие префиксов устраняет избыточные данные в одном столбце, сохраняя указатели в заголовке страницы. После этого шага сжатие словаря выполняет поиск повторяющихся значений на странице и заменяет их указателями, еще больше уменьшая объем хранилища. Чем больше избыточность данных, тем больше пространства вы экономите при сжатии данных.
Архивное сжатие columnstore Объекты columnstore всегда сжимаются, однако их можно сжать еще больше с помощью архивного сжатия, использующего алгоритм сжатия данных Microsoft XPRESS. Этот тип сжатия лучше всего подходит для данных, которые редко считываются, но должны храниться в соответствии с нормативными требованиями или по бизнес-причинам. Хотя эти данные сжаты еще больше, затраты ресурсов ЦП при распаковке обычно перевешивают любой выигрыш в производительности от сокращения операций ввода-вывода.
Дополнительные параметры
Ниже приведен список дополнительных функций SQL Server и действий, которые следует учитывать для рабочих нагрузок.
- Используйте сжатие резервной копии
- Включите быструю инициализацию для файлов данных.
- Ограничьте авторасширение базы данных.
- Отключение автоматического сжатия или автоматического закрытия для баз данных
- Перенесите все базы данных, включая системные, на диски данных.
- Переместите каталоги журнала ошибок и файлов трассировки SQL Server на диски данных.
- Установка максимального ограничения памяти SQL Server
- Использование блокировки страниц в памяти
- Включите оптимизацию для нерегламентированных рабочих нагрузок в среде с активным выполнением операций OLTP.
- Включите хранилище запросов.
- Запланируйте для агента SQL Server выполнение заданий DBCC CHECKDB, реорганизации индекса, перестроения индекса и обновления статистики.
- Мониторинг работоспособности и размера файлов журнала транзакций и управление ими
Дополнительные сведения о рекомендациях по повышению производительности см. в Рекомендациях по SQL Server на виртуальных машинах Azure.