Обучение модели классификатора изображений с помощью PyTorch
На предыдущем этапе выполнения задач этого руководства мы приобрели набор данных, который будем использовать в PyTorch для классификации изображений. Теперь нам пора применить эти данные.
Для обучения классификатора изображений с помощью PyTorch нужно выполнить следующие действия:
- Загрузите данные. Если вы выполнили задачи на предыдущем этапе этого руководства, значит, эта часть уже готова.
- Определение нейронной сети свертки.
- Определение функции потери.
- Обучение модели по данным для обучения.
- Тестирование модели по данным для проверки.
Определение нейронной сети свертки.
Чтобы создать с помощью PyTorch нейронную сеть, используйте пакет torch.nn. Этот пакет содержит модули, расширяемые классы и все компоненты, необходимые для создания нейронных сетей.
В нашем примере вы создадите простейшую нейронную сеть свертки (convolution neural network — CNN), чтобы классифицировать изображения из набора данных CIFAR10.
Класс нейронных сетей CNN определяется как многослойные нейронные сети, предназначенные для обнаружения сложных признаков в данных. Это наиболее применимый тип в приложениях компьютерного зрения.
Структура нашей сети будет включать следующие 14 слоев:
Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> MaxPool -> Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> Linear.
Слой свертки
Слой свертки является основным в структуре CNN и предназначен для обнаружения признаков на изображениях. Каждый из слоев содержит несколько каналов, которые обнаруживают определенные виды признаков, а также несколько ядер для определения размера обнаруженных признаков. Таким образом, слой свертки с 64 каналами и размером ядра 3×3 может обнаруживать 64 отдельных признака размером 3×3 каждый. Определяя слой свертки, вам следует указать число входящих каналов, число исходящих каналов и размер ядра. Число исходящих каналов каждого слоя определяет число входящих каналов для следующего слоя.
Пример: слой свертки с параметрами in-channels=3, out-channels=10 и kernel-size=6 будет принимать на вход RGB-изображение (три канала) и применять к изображениям 10 детекторов признаков с размером ядра 6×6. Чем меньше размер ядра, тем быстрее выполняется вычисление и меньше результатов с одинаковым весом.
Другие слои
Слои в нашей сети расположены в следующем порядке:
- Слой
ReLUвыполняет роль функции активации, которая присваивает всем входящим признакам значения не меньше нуля. При применении этого слоя все отрицательные числа заменяются нулями, а положительные сохраняются без изменений. - Слой
BatchNorm2dприменяет нормализацию входа так, чтобы среднее значение и вариантность элементов стали нулевыми. Это повышает точность работы сети. - Слой
MaxPoolпозволяет сделать так, чтобы расположение объекта в изображении не влияло на способность нейронной сети обнаруживать его признаки. - Слои
Linearзавершают структуру нашей сети и используются для вычисления оценки по каждому классу. В наборе данных CIFAR10 присвоены метки десяти классов. Прогнозом модели будет считаться та из этих меток, у которой самая высокая оценка. На линейном уровне вам нужно определить количество входящих признаков и количество исходящих признаков, которое обычно соответствует количеству классов.
Как работает нейронная сеть?
Сеть типа CNN является сетью прямого распространения. В процессе обучения эта сеть будет обрабатывать входные данные поочередно в каждом слое и вычислять потери, обозначающие отклонение прогнозируемой метки для изображения от правильной, а также распространять градиенты обратно по сети для корректировки весовых коэффициентов в каждом слое. Повторяя этот процесс для большого набора данных, сеть постепенно "обучается", то есть подбирает весовые коэффициенты для достижения оптимального результата.
Функция прямого распространения позволяет вычислить значение функции потери, а функция обратного распространения — градиенты параметров, по которым выполняется обучение. Когда вы создаете нейронную сеть с помощью PyTorch, вам следует определить только функцию прямого распространения. Функция обратного распространения будет определена автоматически.
- Скопируйте приведенный ниже код в файл
PyTorchTraining.pyв Visual Studio, чтобы определить CNN.
import torch
import torch.nn as nn
import torchvision
import torch.nn.functional as F
# Define a convolution neural network
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*10*10, 10)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn4(self.conv4(output)))
output = F.relu(self.bn5(self.conv5(output)))
output = output.view(-1, 24*10*10)
output = self.fc1(output)
return output
# Instantiate a neural network model
model = Network()
Примечание.
Вам нужны дополнительные данные о работе с нейронными сетями в PyTorch? Воспользуйтесь документацией PyTorch.
Определение функции потери
Функция потери позволяет вычислить значение, которое определяет отклонение выходного значения от целевого. Основная задача нейронной сети заключается в минимизации функции потери путем корректировки значений векторных весовых коэффициентов через функцию обратного распространения.
Значение потери не совпадает с точностью модели. Функция потери дает приблизительное представление о том, насколько хорошо работает модель после каждой итерации процесса оптимизации по набору для обучения. В свою очередь, точность модели вычисляется по набору для проверки и обозначает долю правильных прогнозов по нему.
В PyTorch пакет нейронной сети содержит несколько разных функций потери, которые и лежат в основе создания глубоких нейронных сетей. При работе с этим руководством вы примените функцию потери "Классификация", которая основана на процессе определения функции потери и использует тип потери "перекрестная энтропия" и оптимизатор Adam. Скорость обучения позволяет задать допустимую степень изменения весовых коэффициентов в нейронной сети в отношении градиента потери. В нашем примере задайте значение 0,001. Чем ниже это значение, тем медленнее выполняется обучение.
- В Visual Studio скопируйте в файл
PyTorchTraining.pyприведенный ниже код, который определяет функцию потери и оптимизатор.
from torch.optim import Adam
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Обучение модели по данным для обучения.
Чтобы обучить модель, нужно в цикле пропустить ее через итератор данных, передавая в сеть входные данные и оптимизируя ее результаты. PyTorch не предоставляет отдельной библиотеки для использования графического процессора, но вы можете вручную определить устройство для выполнения вычислений. Будет использоваться GPU Nvidia, если он установлен на вашем компьютере. Если это не так, будет использоваться обычный ЦП.
- Добавьте в файл
PyTorchTraining.pyуказанный ниже код.
from torch.autograd import Variable
# Function to save the model
def saveModel():
path = "./myFirstModel.pth"
torch.save(model.state_dict(), path)
# Function to test the model with the test dataset and print the accuracy for the test images
def testAccuracy():
model.eval()
accuracy = 0.0
total = 0.0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.no_grad():
for data in test_loader:
images, labels = data
# run the model on the test set to predict labels
outputs = model(images.to(device))
# the label with the highest energy will be our prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels.to(device)).sum().item()
# compute the accuracy over all test images
accuracy = (100 * accuracy / total)
return(accuracy)
# Training function. We simply have to loop over our data iterator and feed the inputs to the network and optimize.
def train(num_epochs):
best_accuracy = 0.0
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device")
# Convert model parameters and buffers to CPU or Cuda
model.to(device)
for epoch in range(num_epochs): # loop over the dataset multiple times
running_loss = 0.0
running_acc = 0.0
for i, (images, labels) in enumerate(train_loader, 0):
# get the inputs
images = Variable(images.to(device))
labels = Variable(labels.to(device))
# zero the parameter gradients
optimizer.zero_grad()
# predict classes using images from the training set
outputs = model(images)
# compute the loss based on model output and real labels
loss = loss_fn(outputs, labels)
# backpropagate the loss
loss.backward()
# adjust parameters based on the calculated gradients
optimizer.step()
# Let's print statistics for every 1,000 images
running_loss += loss.item() # extract the loss value
if i % 1000 == 999:
# print every 1000 (twice per epoch)
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
# zero the loss
running_loss = 0.0
# Compute and print the average accuracy fo this epoch when tested over all 10000 test images
accuracy = testAccuracy()
print('For epoch', epoch+1,'the test accuracy over the whole test set is %d %%' % (accuracy))
# we want to save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
Протестируйте модель по данным для проверки.
Теперь вы можете проверить модель по набору изображений из набора для проверки.
- Добавьте в файл
PyTorchTraining.pyуказанный ниже код.
import matplotlib.pyplot as plt
import numpy as np
# Function to show the images
def imageshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Function to test the model with a batch of images and show the labels predictions
def testBatch():
# get batch of images from the test DataLoader
images, labels = next(iter(test_loader))
# show all images as one image grid
imageshow(torchvision.utils.make_grid(images))
# Show the real labels on the screen
print('Real labels: ', ' '.join('%5s' % classes[labels[j]]
for j in range(batch_size)))
# Let's see what if the model identifiers the labels of those example
outputs = model(images)
# We got the probability for every 10 labels. The highest (max) probability should be correct label
_, predicted = torch.max(outputs, 1)
# Let's show the predicted labels on the screen to compare with the real ones
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(batch_size)))
Теперь мы, наконец, добавим основной код. Он отвечает за выполнение цикла обучения модели, ее последующее ее сохранение и отображение результатов на экране. Мы выполняем всего две итерации [train(2)] по набору для обучения, поэтому процесс не займет много времени.
- Добавьте в файл
PyTorchTraining.pyуказанный ниже код.
if __name__ == "__main__":
# Let's build our model
train(5)
print('Finished Training')
# Test which classes performed well
testAccuracy()
# Let's load the model we just created and test the accuracy per label
model = Network()
path = "myFirstModel.pth"
model.load_state_dict(torch.load(path))
# Test with batch of images
testBatch()
Давайте запустим тест. В раскрывающихся меню на верхней панели инструментов нужно указать режим "Отладка". Для запуска проекта на локальном компьютере укажите для параметра "Платформа решения" значение x64 для 64-разрядного устройства или x86 для 32-разрядного.
Выберите для числа эпох (число полных проходов по набору данных для обучения) значение [train(2)] (два), чтобы выполнялось два прохода по полному набору данных для проверки (10 000 изображений). Выполнение такого задания обучения займет около 20 минут на ЦП Intel 8-го поколения, и эта модель должна показать примерно 65 % успешных прогнозов по классификации десяти меток.
- Чтобы запустить проект, нажмите кнопку Начать отладку на панели инструментов или клавишу F5.
Откроется окно консоли, в котором вы сможете отслеживать ход обучения.
В соответствии с заданными параметрами значение потери будет выводиться через каждые 1000 пакетов изображений, то есть пять раз за каждую итерацию по набору для обучения. Вы можете ожидать, что значение потери после каждого цикла будет снижаться.
Также после каждой итерации будет отображаться значение точности модели. Точность модели — не то же самое, что значение потери. Функция потери дает приблизительное представление о том, насколько хорошо работает модель после каждой итерации процесса оптимизации по набору для обучения. В свою очередь, точность модели вычисляется по набору для проверки и обозначает долю правильных прогнозов по нему. В нашем примере это показатель того, сколько изображений из набора размером в 10 000 наша модель смогла правильно классифицировать после выполнения очередной итерации.
Когда обучение завершится, поступит результат примерно такого вида, как показано ниже. Конкретные значения в вашем случае будут отличаться, ведь на обучение влияет множество факторов и оно редко дает совершенно идентичный результат. Но и значительных отклонений ожидать не стоит.
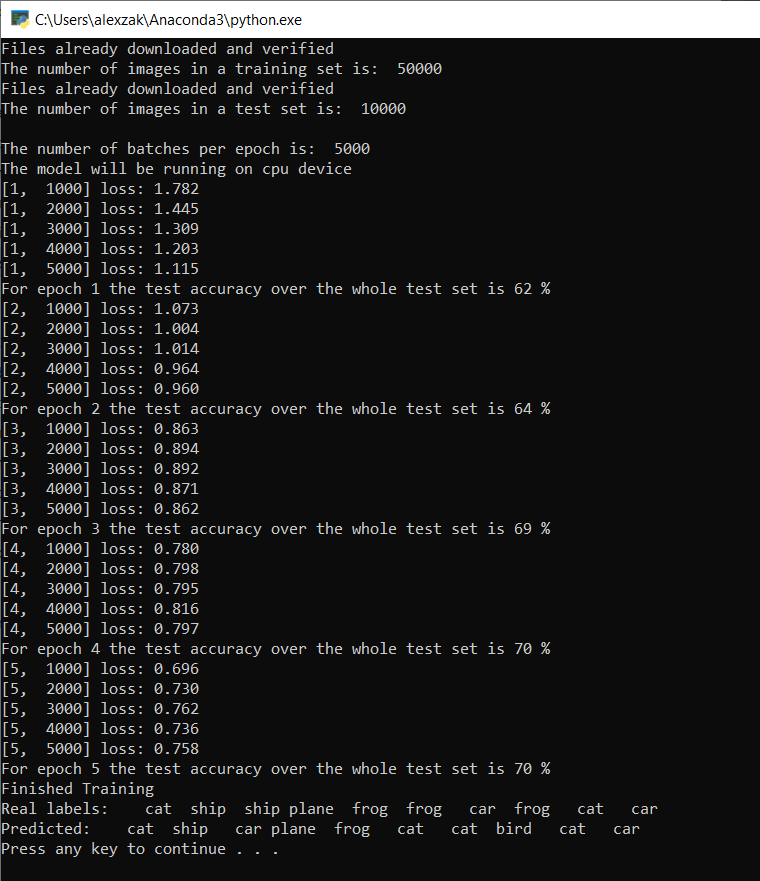
После выполнения всего пяти эпох модель дает 70 % успешных прогнозов. Это хороший результат для такой простой модели с коротким временем обучения.
Тестирование модели по набору изображений показало, что модель правильно определяет 7 изображений из каждых 10. Это совсем неплохо и хорошо согласуется с долей успешных прогнозов.

Кроме того, вы можете проверить, по каким классам наша модель дает наилучшие результаты. Для этого добавьте и выполните следующий код:
- Необязательно — добавьте приведенную ниже функцию
testClassessв файлPyTorchTraining.pyи вызов этой функцииtestClassess()в функции main:__name__ == "__main__".
# Function to test what classes performed well
def testClassess():
class_correct = list(0. for i in range(number_of_labels))
class_total = list(0. for i in range(number_of_labels))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(number_of_labels):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
Вывод выглядит следующим образом.

Дальнейшие действия
Итак, у нас есть готовая модель классификации и мы можем перейти к преобразованию модели в формат ONNX.