Använda Jupyter Notebooks i Azure Data Studio
Viktig
Azure Data Studio går i pension den 28 februari 2026. Vi rekommenderar att du använder Visual Studio Code. Mer information om hur du migrerar till Visual Studio Code finns i Vad händer med Azure Data Studio?
Gäller för:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Jupyter Notebook är ett webbprogram med öppen källkod som gör att du kan skapa och dela dokument som innehåller livekod, ekvationer, visualiseringar och narrativ text. Användningen omfattar datarensning och transformering, numerisk simulering, statistisk modellering, datavisualisering och maskininlärning.
Den här artikeln beskriver hur du skapar en ny notebook-fil i den senaste versionen av Azure Data Studio och hur du börjar redigera egna notebook-filer med olika kärnor.
Titta på den här korta videon på 5 minuter för en introduktion till notebook-filer i Azure Data Studio:
Skapa en notebook-fil
Det finns flera sätt att skapa en ny notebook-fil. I varje fall öppnas en ny fil med namnet Notebook-1.ipynb .
Gå till arkivmenyn i Azure Data Studio och välj Ny anteckningsbok.
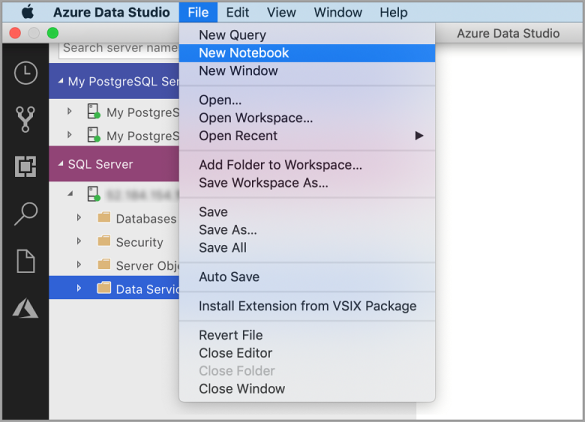
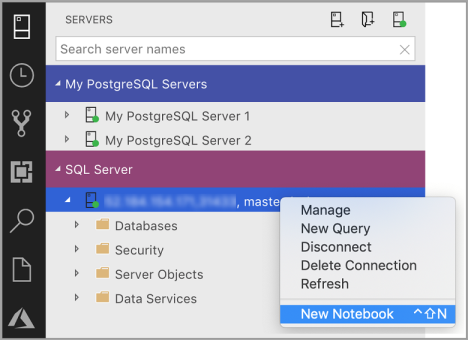
Högerklicka på en SQL Server-anslutning och välj Ny anteckningsbok.
Öppna kommandopaletten (Ctrl+Skift+P), skriv "ny anteckningsbok" och välj kommandot Ny anteckningsbok .

Ansluta till en kernel
Azure Data Studio-notebook-filer stöder ett antal olika kärnor, inklusive SQL Server, Python, PySpark och andra. Varje kernel stöder ett annat språk i kodcellerna i notebook-filen. När du till exempel är ansluten till SQL Server-kerneln kan du ange och köra T-SQL-instruktioner i en notebook-kodcell.
Bifoga till tillhandahåller kontexten för kerneln. Om du till exempel använder SQL Kernel kan du ansluta till någon av dina SQL Server-instanser. Om du använder Python3 Kernel kopplar du till localhost och du kan använda den här kerneln för din lokala Python-utveckling.
SQL Kernel kan också användas för att ansluta till PostgreSQL-serverinstanser. Om du är PostgreSQL-utvecklare och vill ansluta notebook-filerna till PostgreSQL-servern laddar du ned PostgreSQL-tillägget i Azure Data Studio-tillägget Marketplace och ansluter till PostgreSQL-servern.
Om du är ansluten till SQL Server 2019-stordataklustret är standardanslutningen till klustrets slutpunkt. Du kan skicka Python-, Scala- och R-kod med hjälp av Spark-beräkningen av klustret.
| Kernel | beskrivning |
|---|---|
| SQL-kernel | Skriv SQL Code som riktar sig till relationsdatabasen. |
| PySpark3 och PySpark Kernel | Skriv Python-kod med Hjälp av Spark-beräkning från klustret. |
| Spark-kernel | Skriv Scala- och R-kod med Spark-beräkning från klustret. |
| Python-kernel | Skriv Python-kod för lokal utveckling. |
Mer information om specifika kernels finns i:
- Skapa och köra en SQL Server-notebook-fil
- Skapa och köra en Python-notebook-fil
- Kqlmagic-tillägg i Azure Data Studio – detta utökar funktionerna i Python-kerneln
Lägga till en kodcell
Med kodceller kan du köra kod interaktivt i notebook-filen.
Lägg till en ny kodcell genom att klicka på kommandot +Cell i verktygsfältet och välja Kodcell. En ny kodcell läggs till efter den markerade cellen.
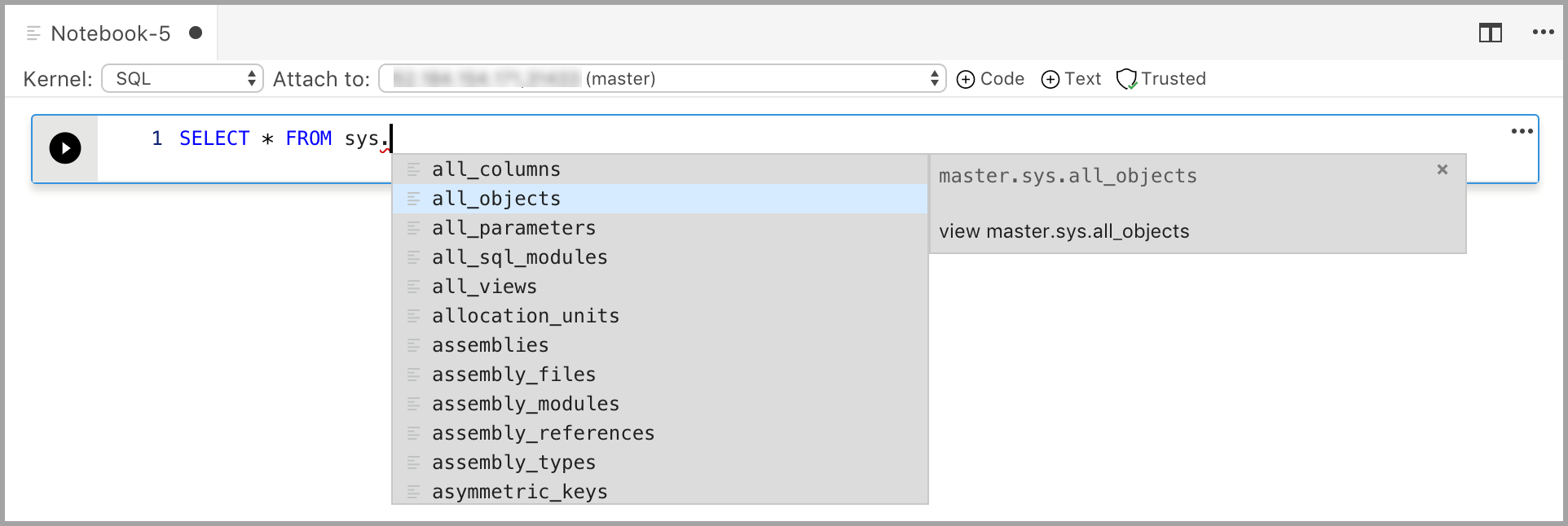
Ange kod i cellen för den valda kerneln. Om du till exempel använder SQL-kerneln kan du ange T-SQL-kommandon i kodcellen.
Att ange kod med SQL-kerneln liknar en SQL-frågeredigerare. Kodcellen stöder en modern SQL-kodningsupplevelse med inbyggda funktioner som en omfattande SQL-redigerare, IntelliSense och inbyggda kodfragment. Med kodfragment kan du generera rätt SQL-syntax för att skapa databaser, tabeller, vyer, lagrade procedurer och uppdatera befintliga databasobjekt. Använd kodfragment för att snabbt skapa kopior av databasen i utvecklings- eller testsyfte och för att generera och köra skript.
Lägga till en textcell
Med textceller kan du dokumentera koden genom att lägga till Markdown-textblock mellan kodceller.
Lägg till en ny textcell genom att klicka på kommandot +Cell i verktygsfältet och välja Textcell.
Cellen startar i redigeringsläge där du kan skriva Markdown-text. När du skriver visas en förhandsgranskning nedan.
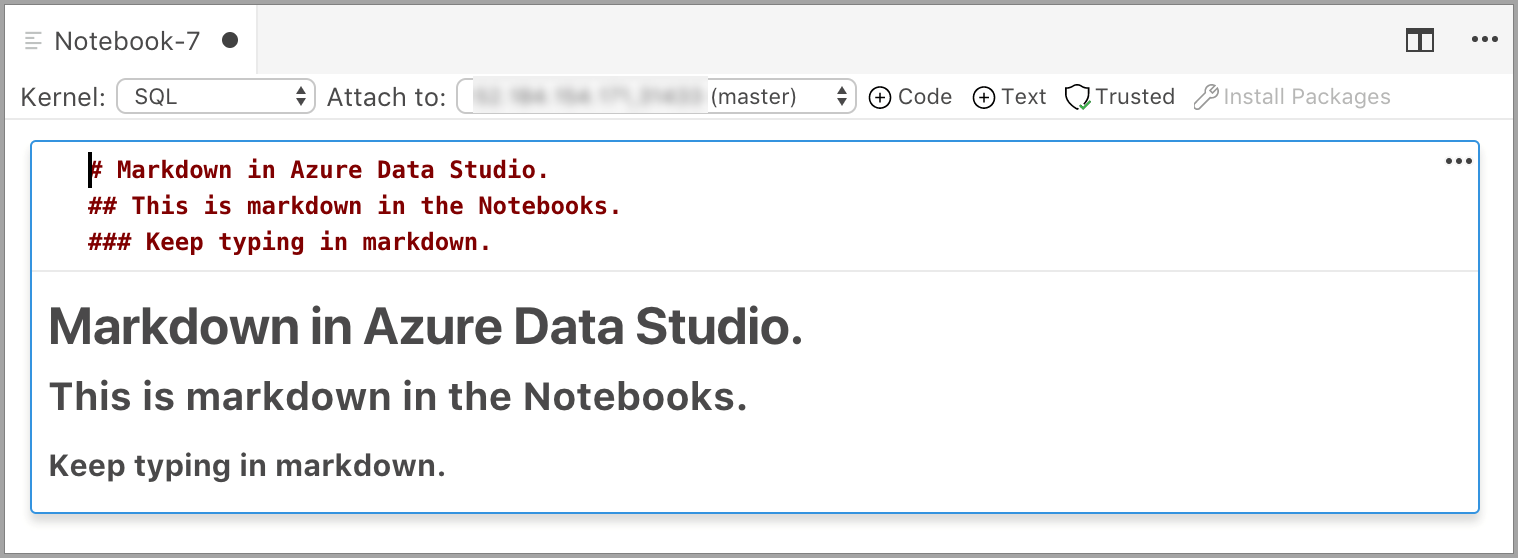
Markdown-texten visas när markdown-texten markeras utanför textcellen.
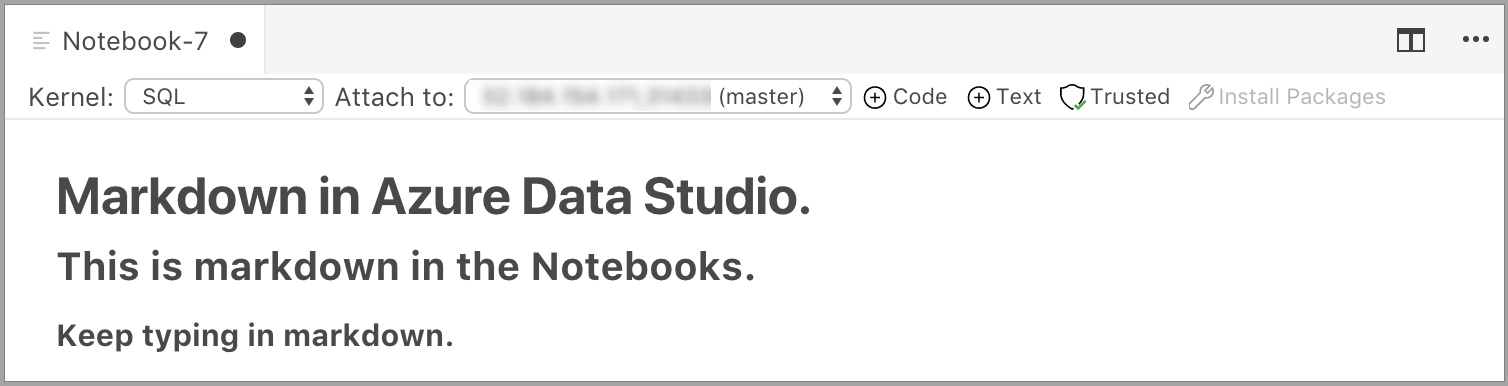
Om du klickar i textcellen igen ändras den till redigeringsläge.
Köra en cell
Om du vill köra en cell klickar du på Kör cell (den runda svarta pilen) till vänster om cellen eller markerar cellen och trycker på F5. Du kan köra alla celler i anteckningsboken genom att klicka på Kör alla i verktygsfältet – cellerna körs en i taget och körningen stoppas om ett fel påträffas i en cell.
Resultat från cellen visas under cellen. Du kan rensa resultatet av alla utförda celler i anteckningsboken genom att välja knappen Rensa resultat i verktygsfältet.
Spara en notebook-fil
Spara en notebook-fil genom att göra något av följande.
- Skriv Ctrl+S
- Välj Spara på Arkiv-menyn
- Välj Spara som... på Arkiv-menyn
- Välj Spara alla på arkivmenyn – då sparas alla öppna anteckningsböcker
- I kommandopaletten anger du Arkiv: Spara
Notebook-filer sparas som .ipynb filer.
Betrodda och ej betrodda
De notebook-filer som är öppna i Azure Data Studio är som standard betrodda.
Om du öppnar en notebook-fil från någon annan källa öppnas den i icke-betrott läge och sedan kan du göra den betrodd.
Exempel
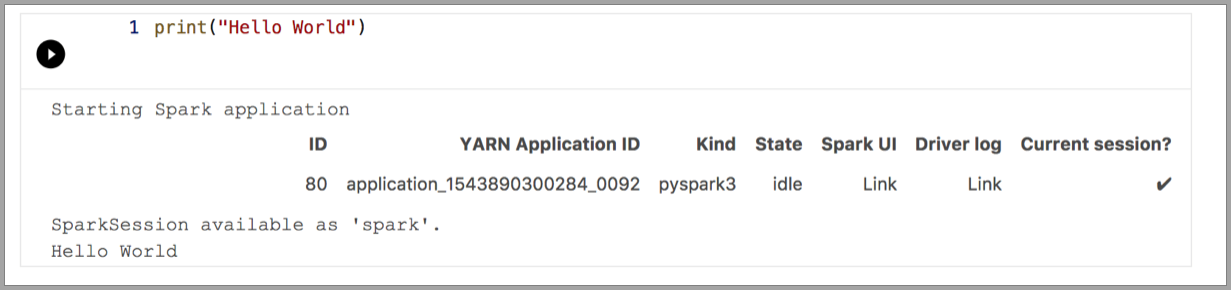
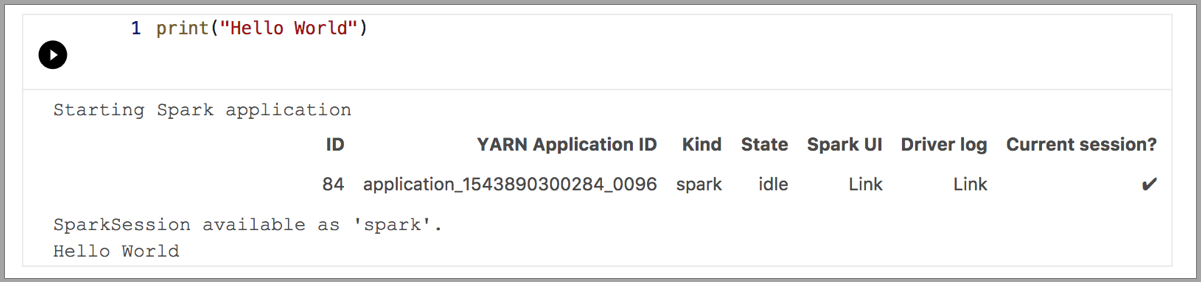
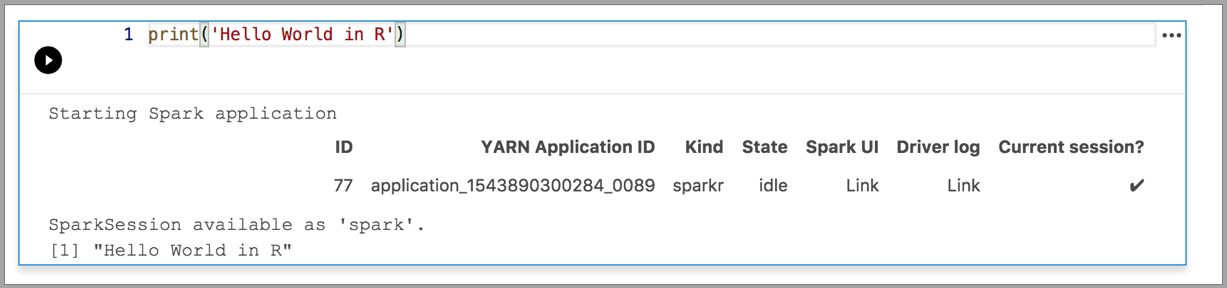
Följande exempel visar hur du använder olika kernels för att köra ett enkelt "Hello World"-kommando. Välj kerneln, ange exempelkoden i en cell och klicka på Kör cell.
Pyspark
Spark | Scala-språk
Spark | R-språk
Python 3

Nästa steg
- Skapa och kör en SQL Server-notebook-fil.
- Skapa och köra en Python-notebook-fil
- Kör Python- och R-skript i Azure Data Studio-notebook-filer med SQL Server Machine Learning Services.
- Distribuera SQL Server-stordatakluster med Azure Data Studio Notebook.
- Hantera SQL Server-Stordatakluster med Azure Data Studio-notebook-filer.
- Kör en exempelanteckningsbok med Spark.