Hämtningsförhöjd generation med Azure AI Document Intelligence
Det här innehållet gäller för: ![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)
Introduktion
RAG (Retrieval-Augmented Generation) är ett designmönster som kombinerar en förtränad stor språkmodell (LLM) som ChatGPT med ett externt datahämtningssystem för att generera ett förbättrat svar som innehåller nya data utanför de ursprungliga träningsdata. Genom att lägga till ett informationshämtningssystem i dina program kan du chatta med dina dokument, generera fängslande innehåll och få åtkomst till kraften i Azure OpenAI-modeller för dina data. Du har också mer kontroll över de data som används av LLM när den formulerar ett svar.
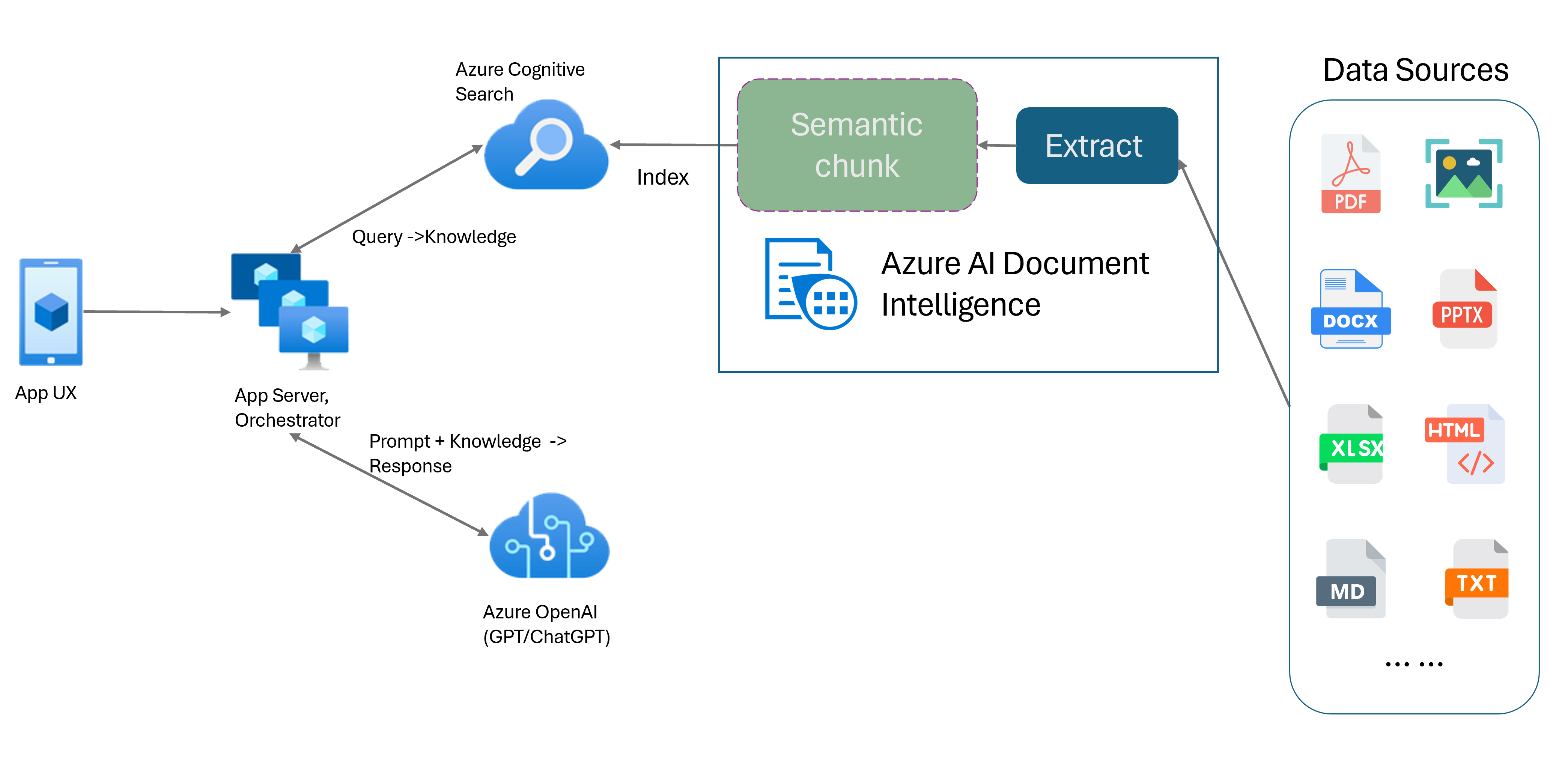
Layoutmodellen för dokumentinformation är ett avancerat api för maskininlärningsbaserad dokumentanalys. Layoutmodellen erbjuder en omfattande lösning för avancerade funktioner för innehållsextrahering och analys av dokumentstruktur. Med layoutmodellen kan du enkelt extrahera text och strukturella element för att dela upp stora textkroppar i mindre, meningsfulla segment baserat på semantiskt innehåll i stället för godtyckliga delningar. Den extraherade informationen kan enkelt matas ut till Markdown-format, så att du kan definiera din semantiska segmenteringsstrategi baserat på angivna byggstenar.
Semantisk segmentering
Långa meningar är utmanande för NLP-program (natural language processing). Särskilt när de består av flera satser, komplexa substantiv eller verbfraser, relativa satser och parentesiska grupperingar. Precis som den mänskliga betraktaren måste ett NLP-system också framgångsrikt hålla reda på alla presenterade beroenden. Målet med semantisk segmentering är att hitta semantiskt sammanhängande fragment av en meningsrepresentation. Dessa fragment kan sedan bearbetas oberoende och kombineras som semantiska representationer utan förlust av information, tolkning eller semantisk relevans. Textens inneboende betydelse används som en guide för segmenteringsprocessen.
Strategier för segmentering av textdata spelar en viktig roll när det gäller att optimera RAG-svar och prestanda. Fast storlek och semantik är två distinkta segmenteringsmetoder:
Segmentering med fast storlek. De flesta segmenteringsstrategier som används i RAG idag baseras på textsegment med korrigeringsstorlek som kallas segment. Segmentering med fast storlek är snabb, enkel och effektiv med text som inte har en stark semantisk struktur som loggar och data. Det rekommenderas dock inte för text som kräver semantisk förståelse och exakt kontext. Fönstrets fasta storlek kan leda till att ord, meningar eller stycken skärs ned, vilket hindrar förståelse och stör informations- och förståelseflödet.
Semantisk segmentering. Den här metoden delar upp texten i segment baserat på semantisk förståelse. Divisionsgränser fokuserar på meningsämne och använder betydande beräkningsalgoritmiskt komplexa resurser. Den har dock den distinkta fördelen att upprätthålla semantisk konsekvens inom varje segment. Det är användbart för textsammanfattning, attitydanalys och dokumentklassificeringsuppgifter.
Semantisk segmentering med dokumentinformationslayoutmodell
Markdown är ett strukturerat och formaterat markeringsspråk och en populär indata för att aktivera semantisk segmentering i RAG (Retrieval-Augmented Generation). Du kan använda Markdown-innehållet från layoutmodellen för att dela upp dokument baserat på styckegränser, skapa specifika segment för tabeller och finjustera segmenteringsstrategin för att förbättra kvaliteten på de genererade svaren.
Fördelar med att använda layoutmodellen
Förenklad bearbetning. Du kan parsa olika dokumenttyper, till exempel digitala och skannade PDF-filer, bilder, office-filer (docx, xlsx, pptx) och HTML, med bara ett enda API-anrop.
Skalbarhet och AI-kvalitet. Layoutmodellen är mycket skalbar i optisk teckenigenkänning (OCR), tabellextrahering och dokumentstrukturanalys. Det stöder 309 tryckta och 12 handskrivna språk, vilket ytterligare säkerställer högkvalitativa resultat som drivs av AI-funktioner.
Kompatibilitet med stor språkmodell (LLM). Markdown-formaterade utdata i layoutmodellen är LLM-vänliga och underlättar sömlös integrering i dina arbetsflöden. Du kan omvandla valfri tabell i ett dokument till Markdown-format och undvika omfattande arbete med att parsa dokumenten för större LLM-förståelse.
Textbild som bearbetas med Document Intelligence Studio och utdata till MarkDown med hjälp av layoutmodellen

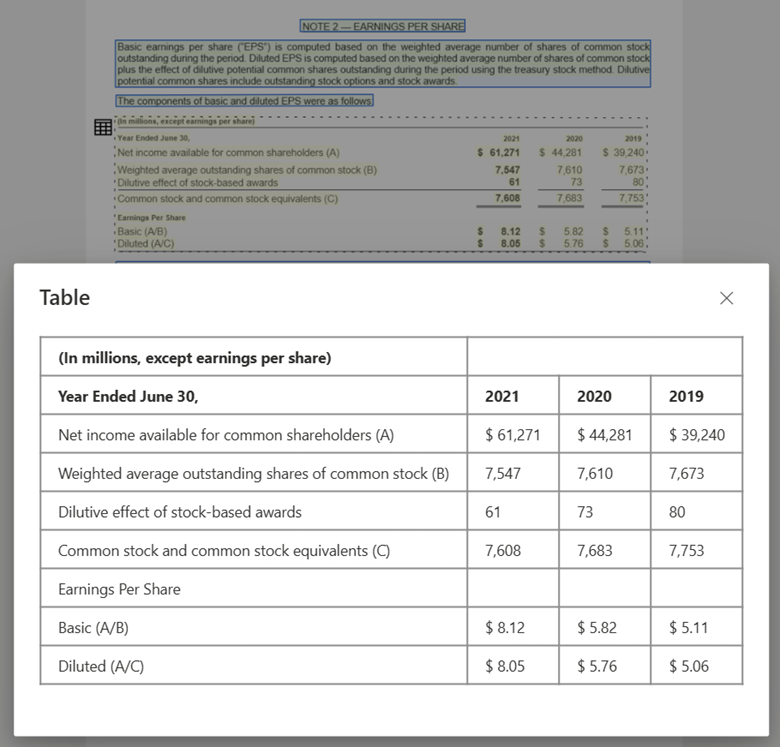
Tabellbild som bearbetas med Document Intelligence Studio med hjälp av layoutmodell
Kom igång
Layoutmodellen för dokumentinformation 2024-07-31-preview och 2023-10-31-preview stöder följande utvecklingsalternativ:
Är du redo att börja?
Document Intelligence Studio
Du kan följa snabbstarten för Document Intelligence Studio för att komma igång. Sedan kan du integrera funktioner för dokumentinformation med ditt eget program med hjälp av exempelkoden som tillhandahålls.
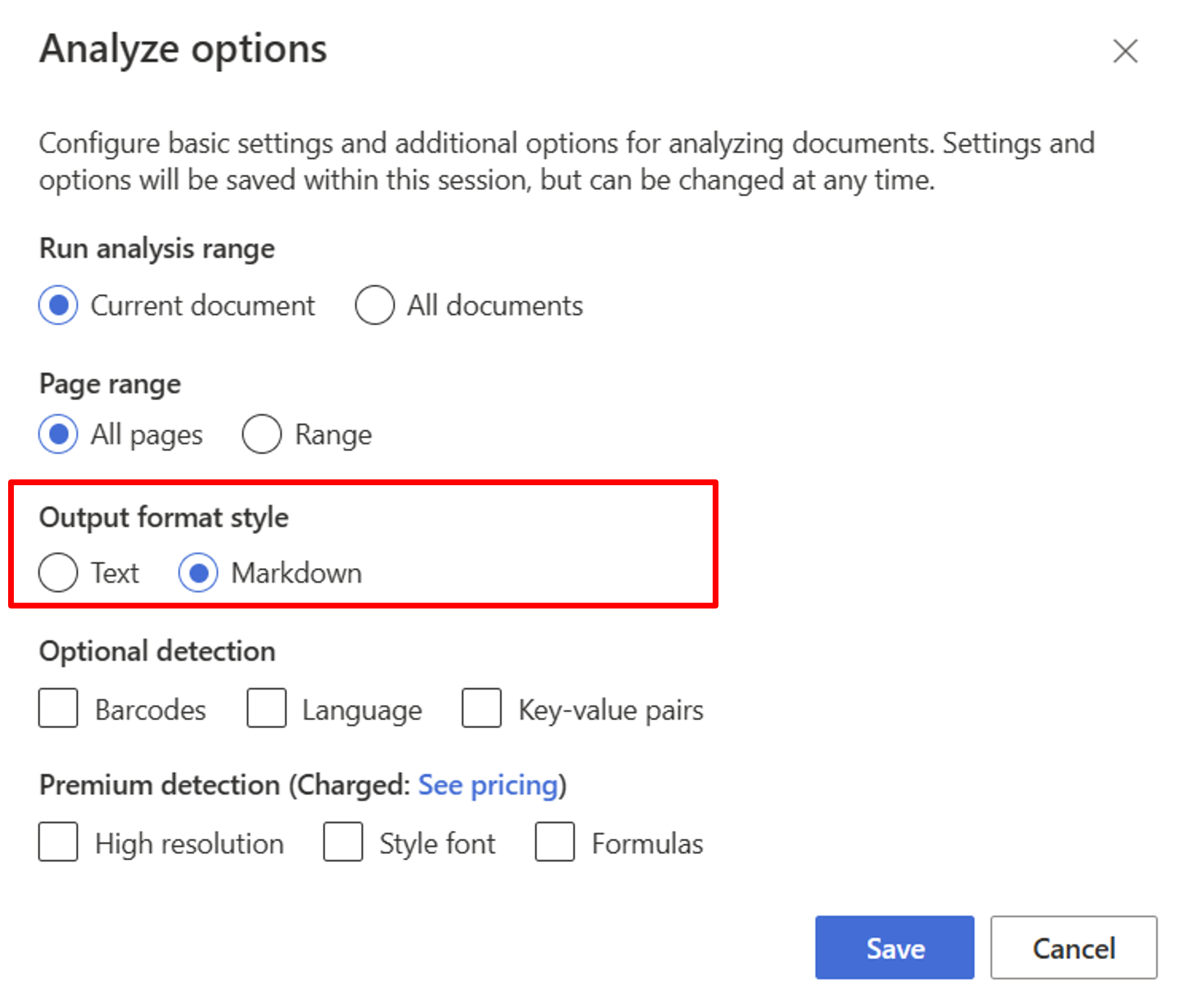
Börja med layoutmodellen. Du måste välja följande analysalternativ för att använda RAG i studion:
**Required**- Kör analysintervallet → aktuellt dokument.
- Sidintervall → Alla sidor.
- Formatformat för utdata → Markdown.
**Optional**- Du kan också välja relevanta valfria identifieringsparametrar.
Välj Spara.
Välj knappen Kör analys för att visa utdata.

SDK eller REST API
Du kan följa snabbstarten för dokumentinformation för det programmeringsspråk som du föredrar SDK eller REST API. Använd layoutmodellen för att extrahera innehåll och struktur från dina dokument.
Du kan också kolla in GitHub-lagringsplatser för kodexempel och tips för att analysera ett dokument i markdown-utdataformat.
Skapa dokumentchatt med semantisk segmentering
Med Azure OpenAI på dina data kan du köra chatt som stöds i dina dokument. Azure OpenAI på dina data använder modellen för dokumentinformationslayout för att extrahera och parsa dokumentdata genom att segmentera lång text baserat på tabeller och stycken. Du kan också anpassa din segmenteringsstrategi med hjälp av Azure OpenAI-exempelskript som finns på vår GitHub-lagringsplats.
Azure AI Document Intelligence är nu integrerat med LangChain som en av dess dokumentinläsare. Du kan använda den för att enkelt läsa in data och utdata till Markdown-format. Mer information finns i vår exempelkod som visar en enkel demo för RAG-mönster med Azure AI Document Intelligence som dokumentinläsare och Azure Search som retriever i LangChain.
Chatten med kodexemplet för datalösningsacceleratorn visar ett rag-mönsterexempel från slutpunkt till slutpunkt. Den använder Azure AI Search som hämtare och Azure AI Document Intelligence för inläsning av dokument och semantisk segmentering.
Användningsfall
Om du letar efter ett specifikt avsnitt i ett dokument kan du använda semantisk segmentering för att dela upp dokumentet i mindre segment baserat på avsnittsrubrikerna som hjälper dig att hitta det avsnitt du letar efter snabbt och enkelt:
# Using SDK targeting 2024-02-29-preview or 2023-10-31-preview, make sure your resource is in one of these regions: East US, West US2, West Europe
# pip install azure-ai-documentintelligence==1.0.0b1
# pip install langchain langchain-community azure-ai-documentintelligence
from azure.ai.documentintelligence import DocumentIntelligenceClient
endpoint = "https://<my-custom-subdomain>.cognitiveservices.azure.com/"
key = "<api_key>"
from langchain_community.document_loaders import AzureAIDocumentIntelligenceLoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# Initiate Azure AI Document Intelligence to load the document. You can either specify file_path or url_path to load the document.
loader = AzureAIDocumentIntelligenceLoader(file_path="<path to your file>", api_key = key, api_endpoint = endpoint, api_model="prebuilt-layout")
docs = loader.load()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
docs_string = docs[0].page_content
splits = text_splitter.split_text(docs_string)
splits
Nästa steg
Läs mer om Azure AI Document Intelligence.
Lär dig hur du bearbetar dina egna formulär och dokument med Document Intelligence Studio.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.