Dokumentmodell för dokumentinformations-ID
Viktigt!
- Versioner av den offentliga förhandsversionen av Document Intelligence ger tidig åtkomst till funktioner som är i aktiv utveckling. Funktioner, metoder och processer kan ändras, före allmän tillgänglighet (GA), baserat på användarfeedback.
- Den offentliga förhandsversionen av Dokumentinformationsklientbiblioteken är som standard REST API version 2024-07-31-preview.
- Den offentliga förhandsversionen 2024-07-31-preview är för närvarande endast tillgänglig i följande Azure-regioner. Observera att modellen för anpassad generativ (extrahering av dokumentfält) i AI Studio endast är tillgänglig i regionen USA, norra centrala:
- USA, östra
- USA, västra 2
- Europa, västra
- USA, norra centrala
Det här innehållet gäller för: ![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Det här innehållet gäller för: ![]() v3.1 (GA) | Senaste version:
v3.1 (GA) | Senaste version:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner: ![]() v3.0
v3.0![]() v2.1
v2.1
Det här innehållet gäller för: ![]() v3.0 (GA) | Senaste versioner:
v3.0 (GA) | Senaste versioner: ![]() v4.0 (förhandsversion)
v4.0 (förhandsversion) ![]() v3.1 | Tidigare version:
v3.1 | Tidigare version: ![]() v2.1
v2.1
Det här innehållet gäller för: ![]() v2.1 | Senaste version:
v2.1 | Senaste version: ![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)
ID-modellen (Document Intelligence Identity Document) kombinerar optisk teckenigenkänning (OCR) med djupinlärningsmodeller för att analysera och extrahera viktig information från identitetsdokument. API:et analyserar identitetsdokument (inklusive följande) och returnerar en strukturerad JSON-datarepresentation:
- Passbok, passkort över hela världen
- Körkort från USA, Europa, Indien, Kanada och Australien
- USA id-kort, uppehållstillstånd (grönt kort), socialförsäkringskort, militärt ID
- Europeiska id-kort, uppehållstillstånd
- Indien PAN-kort, Aadhaar-kort
- Kanada id-kort, uppehållstillstånd (lönnkort)
- Australien fotokort, nyckel-pass-ID (inklusive digital version)
Dokumentinformation kan analysera och extrahera information från myndighetsutfärdade identifieringsdokument (ID: er) med hjälp av dess fördefinierade ID-modell. Den kombinerar våra kraftfulla funktioner för optisk teckenigenkänning (OCR) med ID-igenkänningsfunktioner för att extrahera viktig information från globala pass och amerikanska körkort (alla 50 delstater och D.C.). API:et för ID:n extraherar viktig information från dessa identitetsdokument, till exempel förnamn, efternamn, födelsedatum, dokumentnummer med mera. Det här API:et är tillgängligt i Document Intelligence v2.1 som en molntjänst.
Bearbetning av identitetsdokument
Bearbetning av identitetsdokument innebär att extrahera data från identitetsdokument antingen manuellt eller med hjälp av OCR-baserad teknik. ID-dokumentbearbetning är ett viktigt steg i alla affärsåtgärder som kräver identitetsbevis. Exempel är kundverifiering i banker och andra finansinstitut, inteckningsansökningar, medicinska besök, anspråksbehandling, hotell- och restaurangbranschen med mera. Individer ger vissa bevis på sin identitet via körkort, pass och andra liknande dokument så att företaget effektivt kan verifiera dem innan de tillhandahåller tjänster och förmåner.
Exempel på U.S. Driver's License som bearbetats med Document Intelligence Studio
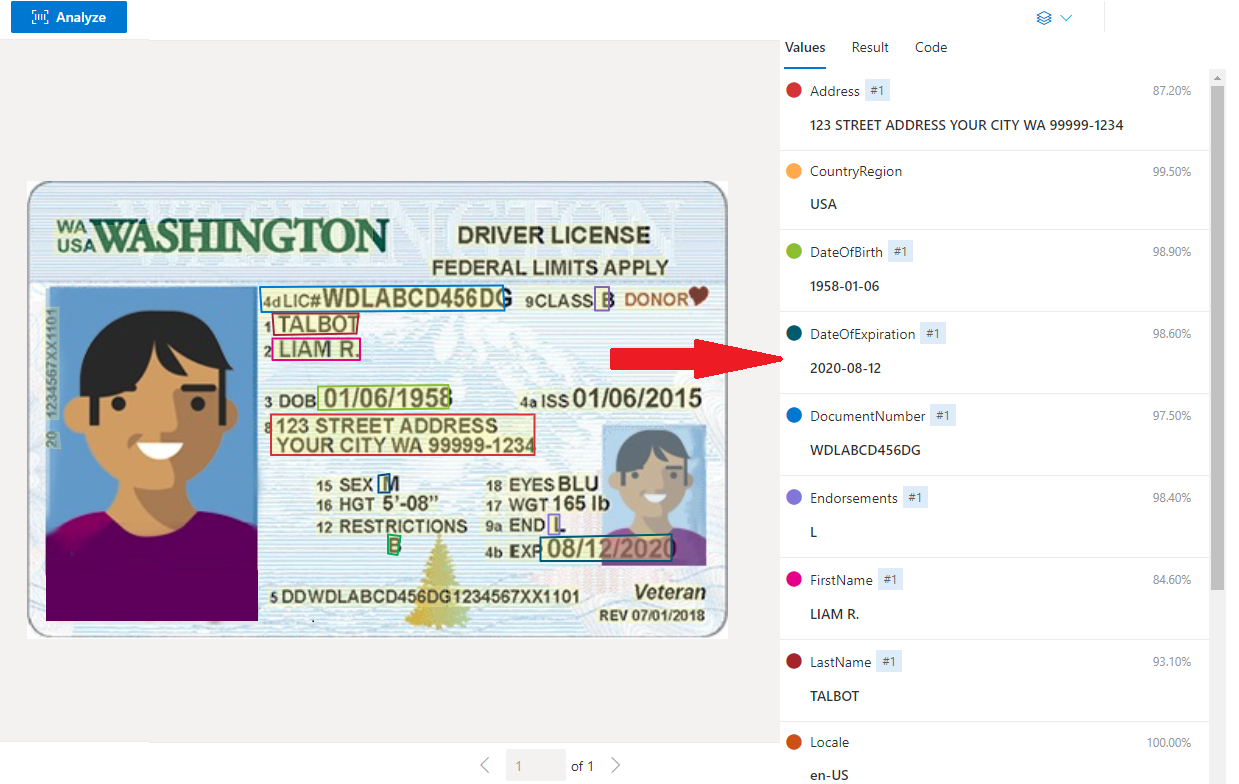
Extrahering av data
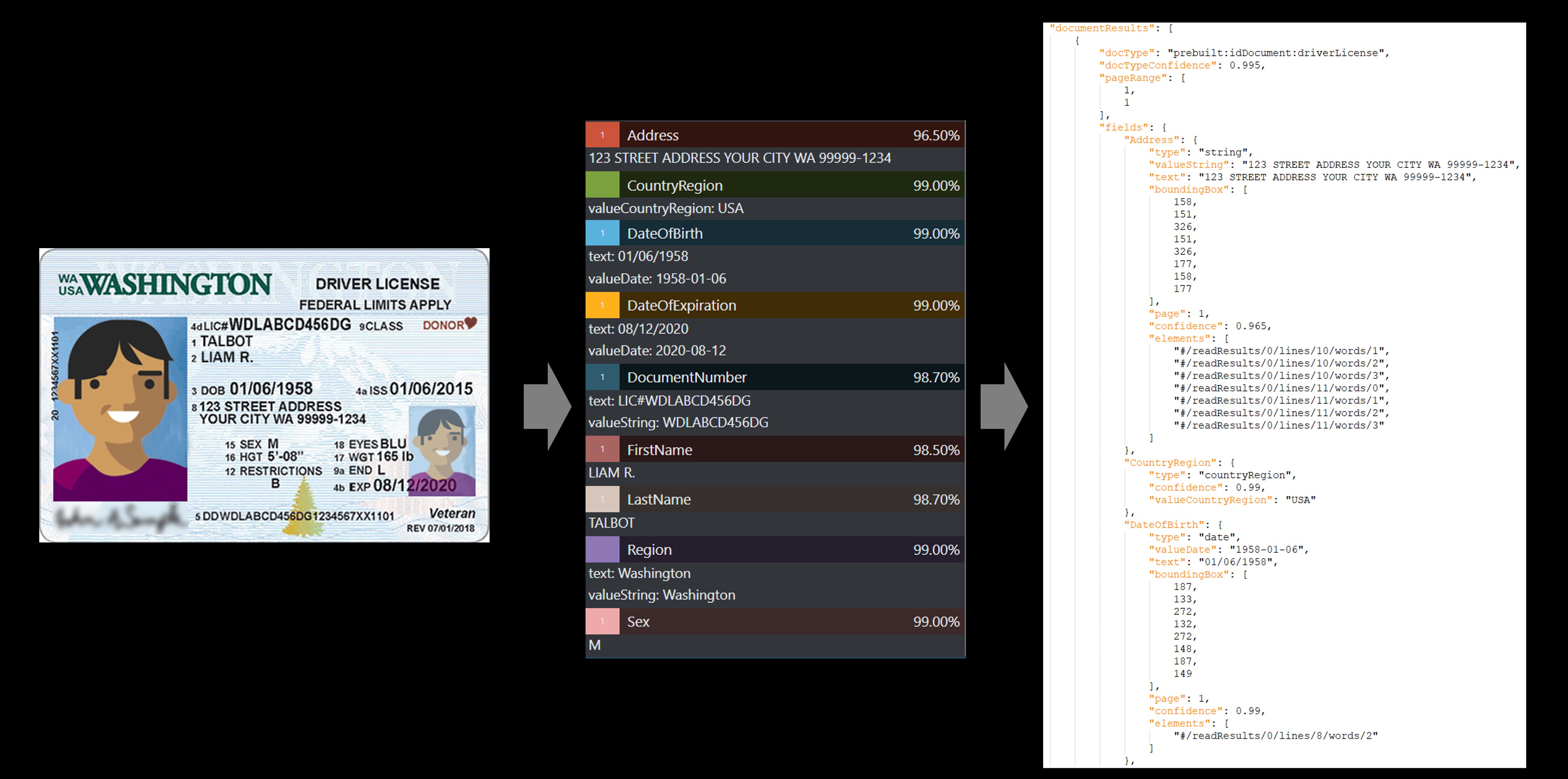
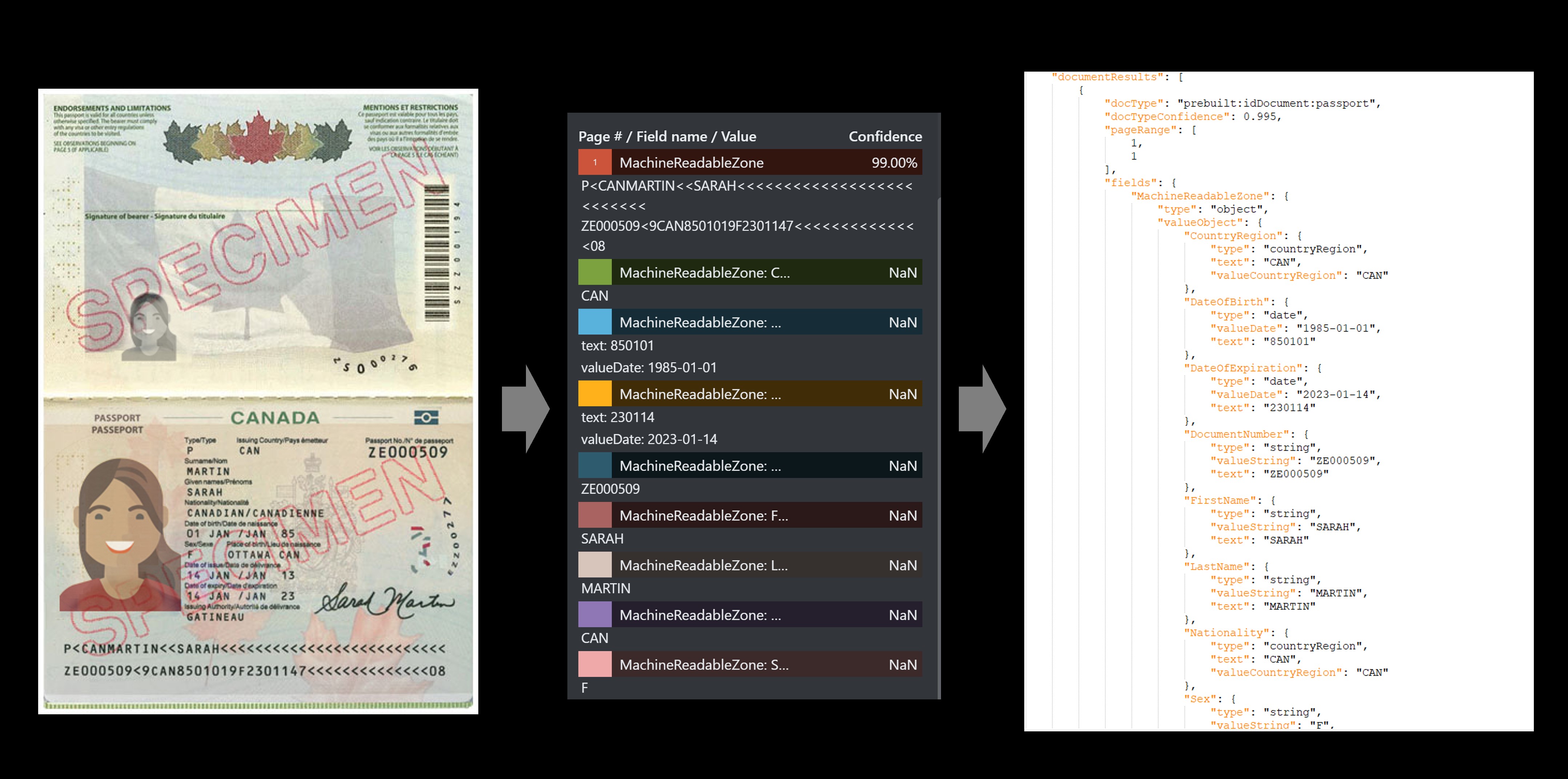
Den fördefinierade ID-tjänsten extraherar nyckelvärdena från globala pass och amerikanska körkort och returnerar dem i ett organiserat strukturerat JSON-svar.
Exempel på körkort
Passport-exempel
Utvecklingsalternativ
Document Intelligence v4.0 (2024-07-31-preview) stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| ID-dokumentmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.1 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| ID-dokumentmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v3.0 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| ID-dokumentmodell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
Document Intelligence v2.1 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser |
|---|---|
| ID-dokumentmodell | • Etikettverktyg för dokumentinformation• REST API • Klientbiblioteks-SDK • Docker-container för dokumentinformation |
Indatakrav
Filformat som stöds:
Modell PDF Bild: JPEG/JPG,PNG,BMP, ,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLästa ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en prenumeration på den kostnadsfria nivån bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för betald (S0) nivå och
4MB för den kostnadsfria nivån (F0).Bilddimensioner måste vara mellan 50 bildpunkter x 50 bildpunkter och 10 000 bildpunkter x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar om
8punkttext vid 150 punkter per tum (DPI).För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och
1GB för den neurala modellen.För anpassad klassificeringsmodellträning är
1den totala storleken på träningsdata GB med högst 10 000 sidor. För förhandsversionen 2024-07-31 och senare är2den totala storleken på träningsdata GB med högst 10 000 sidor.
Filformat som stöds: JPEG, PNG, PDF och TIFF.
Antal sidor som stöds för PDF- och TIFF-filer: upp till 2 000 sidor eller endast de två första sidorna för kostnadsfria prenumeranter.
Filstorlek som stöds: mindre än 50 MB TOTALT; minsta bildpunkter: 50 x 50 px; maximalt antal bildpunkter 10 000 x 10 000 px.
Extrahering av ID-dokumentmodelldata
Extrahera data, inklusive namn, födelsedatum och utgångsdatum, från ID-dokument. Du behöver följande resurser:
En Azure-prenumeration – du kan skapa en kostnadsfritt.
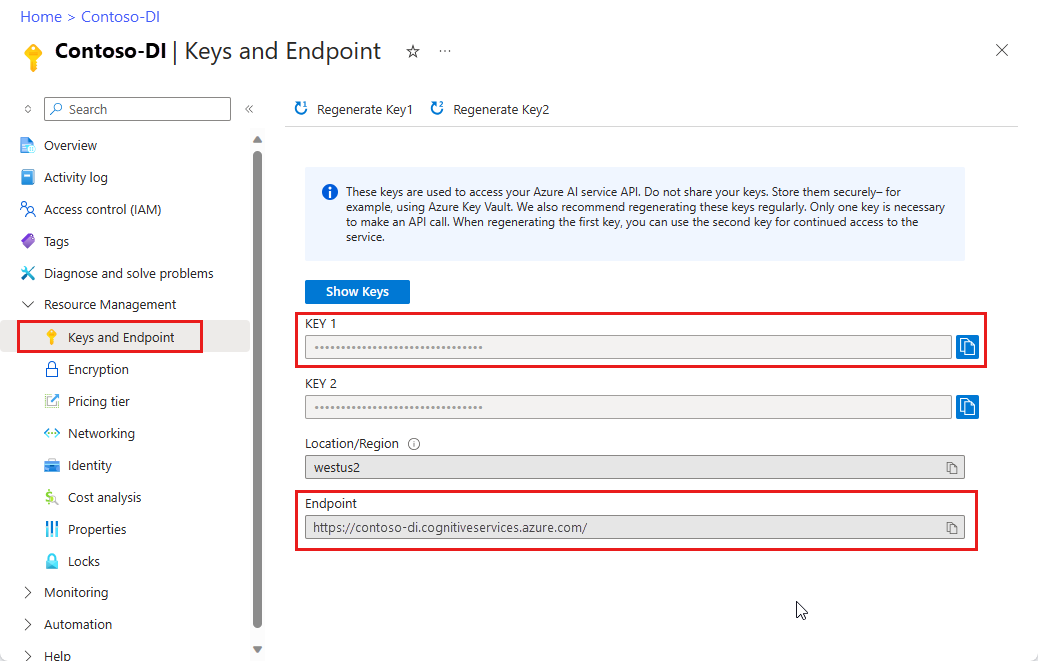
En instans av dokumentinformation i Azure Portal. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten. När resursen har distribuerats väljer du Gå till resurs för att hämta din nyckel och slutpunkt.
Kommentar
Document Intelligence Studio är tillgängligt med v3.1- och v3.0-API:er och senare versioner.
På startsidan för Document Intelligence Studio väljer du Identitetsdokument.
Du kan analysera exempelfakturan eller ladda upp dina egna filer.
Välj knappen Kör analys och konfigurera vid behov alternativen Analysera:

Exempeletikettverktyg för dokumentinformation
Gå till exempelverktyget för dokumentinformation.
På exempelverktygets startsida väljer du panelen Använd fördefinierad modell för att hämta data .
Välj den formulärtyp som ska analyseras från den nedrullningsbara menyn.
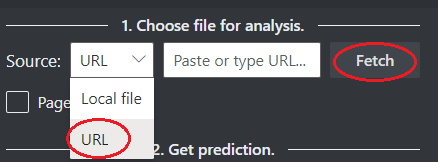
Välj en URL för filen som du vill analysera från alternativen nedan:
I fältet Källa väljer du URL på den nedrullningsbara menyn, klistrar in den valda URL:en och väljer knappen Hämta .
I fältet För dokumentinformationstjänstens slutpunkt klistrar du in slutpunkten som du fick med din Document Intelligence-prenumeration.
I nyckelfältet klistrar du in den nyckel som du fick från dokumentinformationsresursen.

Välj Kör analys. Verktyget Exempeletiketter för dokumentinformation anropar API:et Analysera fördefinierat och analyserar dokumentet.
Visa resultaten – se nyckel/värde-par extraherade, radobjekt, markerad text som extraherats och tabeller har identifierats.
Ladda ned JSON-utdatafilen för att visa de detaljerade resultaten.
- Noden "readResults" innehåller varje textrad med respektive placering av avgränsningsrutan på sidan.
- Noden "selectionMarks" visar varje markeringsmarkering (kryssruta, alternativmarkering) och om dess status är markerad eller omarkerad.
- Avsnittet "pageResults" innehåller de tabeller som extraherats. För varje tabell extraherar Dokumentinformation text-, rad- och kolumnindex, rad- och kolumnintervall, avgränsningsruta med mera.
- Fältet "documentResults" innehåller information om nyckel/värde-par och radobjektinformation för de mest relevanta delarna i dokumentet.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Dokumenttypen som stöds
| Region | Dokumenttyper |
|---|---|
| Världsomfattande | Passport Book, Passport-kort |
| USA | Körkort, ID-kort, uppehållstillstånd (grönt kort), socialförsäkringskort, militärt ID |
| Europa | Körkort, ID-kort, Uppehållstillstånd |
| Indien | Körkort, PAN-kort, Aadhaar-kort |
| Kanada | Körkort, ID-kort, Uppehållstillstånd (Lönnkort) |
| Australien | Körkort, fotokort, nyckelkorts-ID (inklusive digital version) |
Fältextraheringar
Information om fält för extrahering av dokument som stöds finns på schemasidan för ID-dokumentmodell i vår GitHub-exempellagringsplats.
Dokumenttypen som stöds
ID-dokumentmodellen stöder för närvarande amerikanska körkort och den biografiska sidan från internationella pass (exklusive visum och andra resedokument) extrahering.
Fält extraherade
| Namn | Type | Beskrivning | Värde |
|---|---|---|---|
| Country | land | Landskod som är kompatibel med ISO 3166-standarden | "USA" |
| DateOfBirth | datum | DOB i YYYY-MM-DD-format | "1980-01-01" |
| DateOfExpiration | datum | Förfallodatum i ÅÅÅÅ-MM-DD-format | "2019-05-05" |
| DocumentNumber | sträng | Relevant passnummer, körkortsnummer osv. | "340020013" |
| FirstName | sträng | Extraherat förnamn och mellan initial om tillämpligt | "JENNIFER" |
| LastName | sträng | Extraherat efternamn | "BROOKS" |
| Nationalitet | land | Landskod som är kompatibel med ISO 3166-standarden | "USA" |
| Kön | kön | Möjliga extraherade värden är "M" "F" "X" | "F" |
| MachineReadableZone | objekt | Extraherat Passport MRZ med två rader med 44 tecken vardera |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | sträng | Dokumenttyp, till exempel Passport, Körkort | "pass" |
| Adress | sträng | Extraherad adress (endast körkort) | "123 GATUADRESS DIN STAD WA 99999-1234" |
| Region | sträng | Extraherad region, delstat, provins osv. (endast körkort) | "Washington" |
Migreringsguide
Nästa steg
Prova att bearbeta dina egna formulär och dokument med Document Intelligence Studio.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.
Prova att bearbeta dina egna formulär och dokument med verktyget Exempeletiketter för dokumentinformation.
Slutför en snabbstart för dokumentinformation och kom igång med att skapa en app för dokumentbearbetning på valfritt utvecklingsspråk.