Läsmodell för dokumentinformation
Viktigt!
- Versioner av den offentliga förhandsversionen av Document Intelligence ger tidig åtkomst till funktioner som är i aktiv utveckling. Funktioner, metoder och processer kan ändras, före allmän tillgänglighet (GA), baserat på användarfeedback.
- Den offentliga förhandsversionen av Dokumentinformationsklientbiblioteken är som standard REST API version 2024-07-31-preview.
- Den offentliga förhandsversionen 2024-07-31-preview är för närvarande endast tillgänglig i följande Azure-regioner. Observera att modellen för anpassad generativ (extrahering av dokumentfält) i AI Studio endast är tillgänglig i regionen USA, norra centrala:
- USA, östra
- USA, västra 2
- Europa, västra
- USA, norra centrala
Det här innehållet gäller för:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Det här innehållet gäller för:![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Kommentar
Om du vill extrahera text från externa bilder som etiketter, gatuskyltar och affischer använder du funktionen Azure AI Image Analysis v4.0 Read som är optimerad för allmänna bilder som inte är dokument med ett prestandaförstärkt synkront API som gör det enklare att bädda in OCR i dina användarupplevelsescenarier.
MODELLEN Läs optisk teckenigenkänning (OCR) för dokumentinformation körs med en högre upplösning än Azure AI Vision Read och extraherar utskrift och handskriven text från PDF-dokument och skannade bilder. Den innehåller även stöd för att extrahera text från Microsoft Word-, Excel-, PowerPoint- och HTML-dokument. Den identifierar stycken, textrader, ord, platser och språk. Read-modellen är den underliggande OCR-motorn för andra fördefinierade dokumentinformationsmodeller som layout, allmänt dokument, faktura, kvitto, identitetsdokument (ID), sjukförsäkringskort, W2 utöver anpassade modeller.
Vad är optisk teckenigenkänning?
Optisk teckenigenkänning (OCR) för dokument är optimerat för stora textintensiva dokument i flera filformat och globala språk. Den innehåller funktioner som genomsökning med högre upplösning av dokumentbilder för bättre hantering av mindre och kompakt text. styckeidentifiering; och fyllbar formulärhantering. OCR-funktioner omfattar även avancerade scenarier som rutor med en tecken och korrekt extrahering av nyckelfält som ofta finns i fakturor, kvitton och andra fördefinierade scenarier.
Utvecklingsalternativ (v4)
Document Intelligence v4.0 (2024-07-31-preview) stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Läs OCR-modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Indatakrav (v4)
Filformat som stöds:
Modell PDF Bild: JPEG/JPG,PNG,BMP, ,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLästa ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en prenumeration på den kostnadsfria nivån bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för betald (S0) nivå och
4MB för den kostnadsfria nivån (F0).Bilddimensioner måste vara mellan 50 bildpunkter x 50 bildpunkter och 10 000 bildpunkter x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar om
8punkttext vid 150 punkter per tum (DPI).För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och
1GB för den neurala modellen.För anpassad klassificeringsmodellträning är
1den totala storleken på träningsdata GB med högst 10 000 sidor. För förhandsversionen 2024-07-31 och senare är2den totala storleken på träningsdata GB med högst 10 000 sidor.
Kom igång med läsmodell (v4)
Prova att extrahera text från formulär och dokument med hjälp av Document Intelligence Studio. Du behöver följande tillgångar:
En Azure-prenumeration – du kan skapa en kostnadsfritt.
En instans av dokumentinformation i Azure Portal. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten. När resursen har distribuerats väljer du Gå till resurs för att hämta din nyckel och slutpunkt.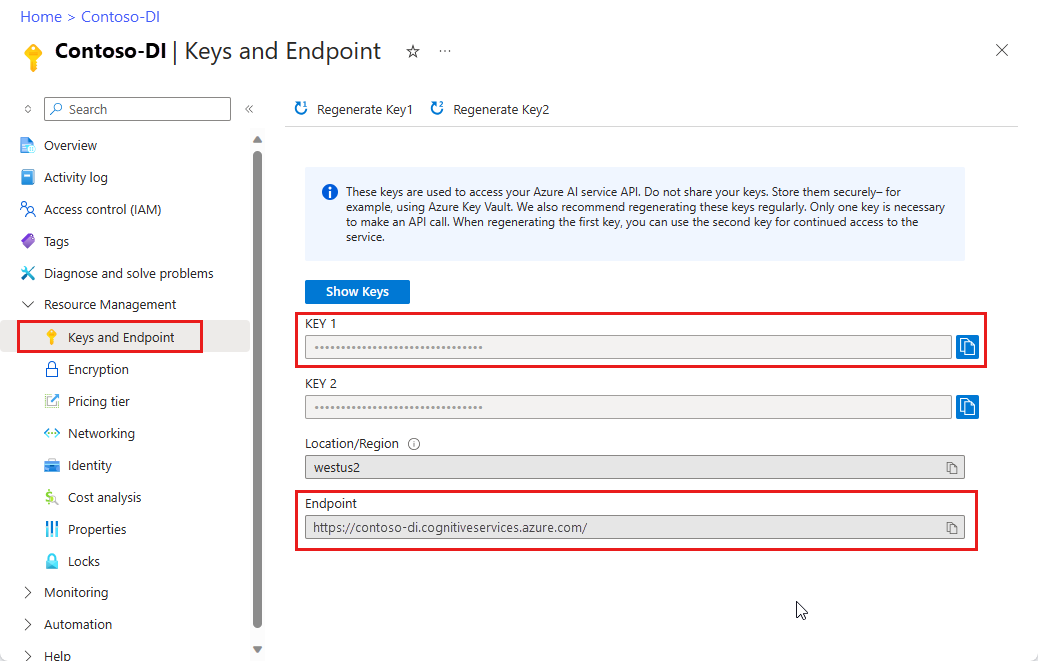
Kommentar
Document Intelligence Studio stöder för närvarande inte Microsoft Word-, Excel-, PowerPoint- och HTML-filformat.
Exempeldokument som bearbetas med Document Intelligence Studio
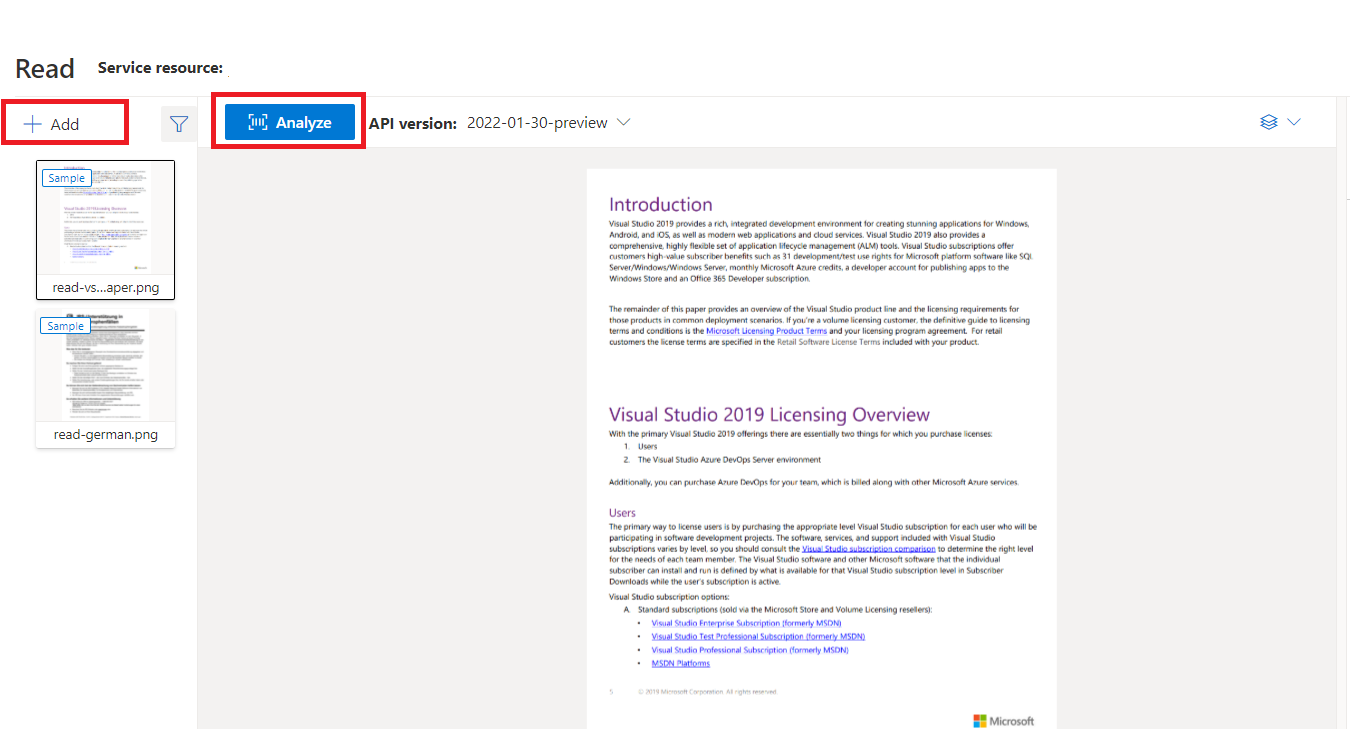
På startsidan för Document Intelligence Studio väljer du Läs.
Du kan analysera exempeldokumentet eller ladda upp dina egna filer.
Välj knappen Kör analys och konfigurera vid behov alternativen Analysera:

Språk och språk som stöds (v4)
Se sidan Språkstöd – modeller för dokumentanalys för en fullständig lista över språk som stöds.
Extrahering av data (v4)
Kommentar
Microsoft Word- och HTML-filen stöds i v4.0. Jämfört med PDF och bilder stöds inte funktionerna nedan:
- Det finns ingen vinkel, bredd/höjd och enhet för varje sidobjekt.
- För varje objekt som identifieras finns det ingen avgränsande polygon eller avgränsningsregion.
- Sidintervall (
pages) stöds inte som en parameter. - Inget
linesobjekt.
Sökbara PDF-filer
Med den sökbara PDF-funktionen kan du konvertera en analog PDF, till exempel skannade PDF-filer, till en PDF med inbäddad text. Den inbäddade texten möjliggör djuptextsökning i PDF-filens extraherade innehåll genom att lägga över de identifierade textentiteterna ovanpå bildfilerna.
Viktigt!
- För närvarande stöds den sökbara PDF-funktionen endast av Read OCR-modellen
prebuilt-read. När du använder den här funktionen angermodelIddu somprebuilt-read, eftersom andra modelltyper returnerar fel för den här förhandsversionen. - Sökbar PDF ingår i modellen 2024-07-31-preview
prebuilt-readutan extra kostnad för att generera sökbara PDF-utdata.- Sökbar PDF stöder för närvarande endast PDF-filer som indata. Stöd för andra filtyper, till exempel bildfiler, kommer att vara tillgängligt senare.
Använda sökbara PDF-filer
Om du vill använda sökbar PDF gör du en POST begäran med hjälp av Analyze åtgärden och anger utdataformatet som pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Sök efter slutförande av åtgärden Analyze . När åtgärden är klar skickar du en GET begäran om att hämta PDF-formatet för åtgärdsresultatet Analyze .
När pdf-filen har slutförts kan den hämtas och laddas ned som application/pdf. Den här åtgärden möjliggör direkt nedladdning av den inbäddade textformen pdf i stället för Base64-kodad JSON.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Sidparameter
Sidsamlingen är en lista över sidor i dokumentet. Varje sida representeras sekventiellt i dokumentet och innehåller orienteringsvinkeln som anger om sidan roteras och bredden och höjden (dimensioner i bildpunkter). Sidenheterna i modellutdata beräknas enligt följande:
| Filformat | Beräknad sidenhet | Totalt antal sidor |
|---|---|---|
| Bilder (JPEG/JPG, PNG, BMP, HEIF) | Varje bild = 1 sidenhet | Totalt antal bilder |
| Varje sida i PDF = 1 sidenhet | Totalt antal sidor i PDF-filen | |
| TIFF | Varje bild i enheten TIFF = 1 sida | Totalt antal bilder i TIFF |
| Word (DOCX) | Upp till 3 000 tecken = en sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal sidor på upp till 3 000 tecken vardera |
| Excel (XLSX) | Varje kalkylblad = 1 sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal kalkylblad |
| PowerPoint (PPTX) | Varje bild = 1 sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal bilder |
| HTML | Upp till 3 000 tecken = en sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal sidor på upp till 3 000 tecken vardera |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
Använda sidor för textextrahering
För stora PDF-dokument med flera sidor använder du pages frågeparametern för att ange specifika sidnummer eller sidintervall för textextrahering.
Extrahering av stycke
Read OCR-modellen i Document Intelligence extraherar alla identifierade textblock i paragraphs samlingen som ett objekt på översta nivån under analyzeResults. Varje post i den här samlingen representerar ett textblock och innehåller den extraherade texten somcontent och avgränsningskoordinaterna polygon . Informationen span pekar på textfragmentet i den översta egenskapen content som innehåller den fullständiga texten från dokumentet.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Extrahering av text, rader och ord
Read OCR-modellen extraherar utskrifts- och handskriven formatmallstext som lines och words. Modellen matar ut avgränsningskoordinater polygon och confidence för extraherade ord. Samlingen styles innehåller alla handskrivna formatmallar för rader om de identifieras tillsammans med de intervall som pekar på den associerade texten. Den här funktionen gäller för handskrivna språk som stöds.
För Microsoft Word, Excel, PowerPoint och HTML extraherar dokumentinformationsmodellen v3.1 och senare versioner all inbäddad text som den är. Texterna är extrated som ord och stycken. Inbäddade bilder stöds inte.
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
Extrahering av handskriven stil
Svaret innehåller klassificering av om varje textrad har handskriftsstil eller inte, tillsammans med en konfidenspoäng. Mer information finns i stöd för handskrivna språk. I följande exempel visas ett exempel på JSON-kodfragment.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Om du har aktiverat addon-funktionen för teckensnitt/format får du även teckensnitts-/formatmallsresultatet styles som en del av objektet.
Nästa steg v4.0
Slutför en snabbstart för dokumentinformation:
Utforska vårt REST API:
Hitta fler exempel på GitHub:
Det här innehållet gäller för: ![]() v3.1 (GA) | Senaste version:
v3.1 (GA) | Senaste version: ![]() v4.0 (förhandsversion) | Tidigare versioner:
v4.0 (förhandsversion) | Tidigare versioner: ![]() v3.0
v3.0
Det här innehållet gäller för: ![]() v3.0 (GA) | Senaste versioner:
v3.0 (GA) | Senaste versioner: ![]() v4.0 (förhandsversion)
v4.0 (förhandsversion)![]() v3.1
v3.1
Kommentar
Om du vill extrahera text från externa bilder som etiketter, gatuskyltar och affischer använder du funktionen Azure AI Image Analysis v4.0 Read som är optimerad för allmänna bilder som inte är dokument med ett prestandaförstärkt synkront API som gör det enklare att bädda in OCR i dina användarupplevelsescenarier.
MODELLEN Läs optisk teckenigenkänning (OCR) för dokumentinformation körs med en högre upplösning än Azure AI Vision Read och extraherar utskrift och handskriven text från PDF-dokument och skannade bilder. Den innehåller även stöd för att extrahera text från Microsoft Word-, Excel-, PowerPoint- och HTML-dokument. Den identifierar stycken, textrader, ord, platser och språk. Read-modellen är den underliggande OCR-motorn för andra fördefinierade dokumentinformationsmodeller som layout, allmänt dokument, faktura, kvitto, identitetsdokument (ID), sjukförsäkringskort, W2 utöver anpassade modeller.
Vad är OCR för dokument?
Optisk teckenigenkänning (OCR) för dokument är optimerat för stora textintensiva dokument i flera filformat och globala språk. Den innehåller funktioner som genomsökning med högre upplösning av dokumentbilder för bättre hantering av mindre och kompakt text. styckeidentifiering; och fyllbar formulärhantering. OCR-funktioner omfattar även avancerade scenarier som rutor med en tecken och korrekt extrahering av nyckelfält som ofta finns i fakturor, kvitton och andra fördefinierade scenarier.
Utvecklingsalternativ
Document Intelligence v3.1 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Läs OCR-modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Document Intelligence v3.0 stöder följande verktyg, program och bibliotek:
| Funktion | Resurser | Model ID |
|---|---|---|
| Läs OCR-modell | • Document Intelligence Studio • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
Indatakrav
Filformat som stöds:
Modell PDF Bild: JPEG/JPG,PNG,BMP, ,TIFFHEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLästa ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Allmänt dokument ✔ ✔ Inbyggda ✔ ✔ Anpassad extrahering ✔ ✔ Anpassad klassificering ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) För bästa resultat anger du ett tydligt foto eller en genomsökning av hög kvalitet per dokument.
För PDF och TIFF kan upp till 2 000 sidor bearbetas (med en prenumeration på den kostnadsfria nivån bearbetas endast de två första sidorna).
Filstorleken för att analysera dokument är 500 MB för betald (S0) nivå och
4MB för den kostnadsfria nivån (F0).Bilddimensioner måste vara mellan 50 bildpunkter x 50 bildpunkter och 10 000 bildpunkter x 10 000 bildpunkter.
Om dina PDF-filer är låsta med lösenord måste du ta bort låset innan du skickar filerna.
Den minsta höjden på texten som ska extraheras är 12 bildpunkter för en bild på 1 024 x 768 bildpunkter. Den här dimensionen motsvarar om
8punkttext vid 150 punkter per tum (DPI).För anpassad modellträning är det maximala antalet sidor för träningsdata 500 för den anpassade mallmodellen och 50 000 för den anpassade neurala modellen.
För anpassad extraheringsmodellträning är den totala storleken på träningsdata 50 MB för mallmodellen och
1GB för den neurala modellen.För anpassad klassificeringsmodellträning är
1den totala storleken på träningsdata GB med högst 10 000 sidor. För förhandsversionen 2024-07-31 och senare är2den totala storleken på träningsdata GB med högst 10 000 sidor.
Kom igång med läsmodell
Prova att extrahera text från formulär och dokument med hjälp av Document Intelligence Studio. Du behöver följande tillgångar:
En Azure-prenumeration – du kan skapa en kostnadsfritt.
En instans av dokumentinformation i Azure Portal. Du kan använda den kostnadsfria prisnivån (
F0) för att prova tjänsten. När resursen har distribuerats väljer du Gå till resurs för att hämta din nyckel och slutpunkt.
Kommentar
Document Intelligence Studio stöder för närvarande inte Microsoft Word-, Excel-, PowerPoint- och HTML-filformat.
Exempeldokument som bearbetas med Document Intelligence Studio
På startsidan för Document Intelligence Studio väljer du Läs.
Du kan analysera exempeldokumentet eller ladda upp dina egna filer.
Välj knappen Kör analys och konfigurera vid behov alternativen Analysera:
Språk och nationella inställningar som stöds
Se sidan Språkstöd – modeller för dokumentanalys för en fullständig lista över språk som stöds.
Extrahering av data
Kommentar
Microsoft Word- och HTML-fil stöds i v3.1 och senare versioner. Jämfört med PDF och bilder stöds inte funktionerna nedan:
- Det finns ingen vinkel, bredd/höjd och enhet för varje sidobjekt.
- För varje objekt som identifieras finns det ingen avgränsande polygon eller avgränsningsregion.
- Sidintervall (
pages) stöds inte som en parameter. - Inget
linesobjekt.
Sökbar PDF
Med den sökbara PDF-funktionen kan du konvertera en analog PDF, till exempel skannade PDF-filer, till en PDF med inbäddad text. Den inbäddade texten möjliggör djuptextsökning i PDF-filens extraherade innehåll genom att lägga över de identifierade textentiteterna ovanpå bildfilerna.
Viktigt!
- För närvarande stöds den sökbara PDF-funktionen endast av Read OCR-modellen
prebuilt-read. När du använder den här funktionen angermodelIddu somprebuilt-read, eftersom andra modelltyper returnerar fel för den här förhandsversionen. - Sökbar PDF ingår i modellen 2024-07-31-preview
prebuilt-readutan extra kostnad för att generera sökbara PDF-utdata.- Sökbar PDF stöder för närvarande endast PDF-filer som indata. Stöd för andra filtyper, till exempel bildfiler, kommer att vara tillgängligt senare.
Använda sökbar PDF
Om du vill använda sökbar PDF gör du en POST begäran med hjälp av Analyze åtgärden och anger utdataformatet som pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
Sök efter slutförande av åtgärden Analyze . När åtgärden är klar skickar du en GET begäran om att hämta PDF-formatet för åtgärdsresultatet Analyze .
När pdf-filen har slutförts kan den hämtas och laddas ned som application/pdf. Den här åtgärden möjliggör direkt nedladdning av den inbäddade textformen pdf i stället för Base64-kodad JSON.
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
Sidor
Sidsamlingen är en lista över sidor i dokumentet. Varje sida representeras sekventiellt i dokumentet och innehåller orienteringsvinkeln som anger om sidan roteras och bredden och höjden (dimensioner i bildpunkter). Sidenheterna i modellutdata beräknas enligt följande:
| Filformat | Beräknad sidenhet | Totalt antal sidor |
|---|---|---|
| Bilder (JPEG/JPG, PNG, BMP, HEIF) | Varje bild = 1 sidenhet | Totalt antal bilder |
| Varje sida i PDF = 1 sidenhet | Totalt antal sidor i PDF-filen | |
| TIFF | Varje bild i enheten TIFF = 1 sida | Totalt antal bilder i TIFF |
| Word (DOCX) | Upp till 3 000 tecken = en sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal sidor på upp till 3 000 tecken vardera |
| Excel (XLSX) | Varje kalkylblad = 1 sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal kalkylblad |
| PowerPoint (PPTX) | Varje bild = 1 sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal bilder |
| HTML | Upp till 3 000 tecken = en sidenhet, inbäddade eller länkade bilder stöds inte | Totalt antal sidor på upp till 3 000 tecken vardera |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
Välj sidor för extrahering av text
För stora PDF-dokument med flera sidor använder du pages frågeparametern för att ange specifika sidnummer eller sidintervall för textextrahering.
Punkterna
Read OCR-modellen i Document Intelligence extraherar alla identifierade textblock i paragraphs samlingen som ett objekt på översta nivån under analyzeResults. Varje post i den här samlingen representerar ett textblock och innehåller den extraherade texten somcontent och avgränsningskoordinaterna polygon . Informationen span pekar på textfragmentet i den översta egenskapen content som innehåller den fullständiga texten från dokumentet.
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
Text, rader och ord
Read OCR-modellen extraherar utskrifts- och handskriven formatmallstext som lines och words. Modellen matar ut avgränsningskoordinater polygon och confidence för extraherade ord. Samlingen styles innehåller alla handskrivna formatmallar för rader om de identifieras tillsammans med de intervall som pekar på den associerade texten. Den här funktionen gäller för handskrivna språk som stöds.
För Microsoft Word, Excel, PowerPoint och HTML extraherar dokumentinformationsmodellen v3.1 och senare versioner all inbäddad text som den är. Texterna är extrated som ord och stycken. Inbäddade bilder stöds inte.
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
Handskriven stil för textrader
Svaret innehåller klassificering av om varje textrad har handskriftsstil eller inte, tillsammans med en konfidenspoäng. Mer information finns i stöd för handskrivna språk. I följande exempel visas ett exempel på JSON-kodfragment.
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
Om du har aktiverat addon-funktionen för teckensnitt/format får du även teckensnitts-/formatmallsresultatet styles som en del av objektet.
Nästa steg
Slutför en snabbstart för dokumentinformation:
Utforska vårt REST API:
Hitta fler exempel på GitHub: