Så här använder du autoetiketter för anpassad namngiven entitetsigenkänning
Märkningsprocessen är en viktig del av förberedelsen av datamängden. Eftersom den här processen kräver både tid och arbete kan du använda funktionen autolabeling för att automatiskt märka dina entiteter. Du kan starta automärkningsjobb baserat på en modell som du tidigare har tränat eller använt GPT-modeller. Med automärkning baserat på en modell som du tidigare har tränat kan du börja märka några av dina dokument, träna en modell och sedan skapa ett autoetiketteringsjobb för att skapa entitetsetiketter för andra dokument baserat på modellen. Med automatisk etikettering med GPT kan du omedelbart utlösa ett automärkningsjobb utan någon tidigare modellträning. Den här funktionen kan spara tid och arbete med att manuellt märka dina entiteter.
Förutsättningar
Innan du kan använda automärkning baserat på en modell som du har tränat behöver du:
- Ett projekt som har skapats med ett konfigurerat Azure Blob Storage-konto.
- Textdata som har laddats upp till ditt lagringskonto .
- Etiketterade data
- En modell som tränats
Utlösa ett autoetiketteringsjobb
När du utlöser ett autoetiketteringsjobb baserat på en modell som du har tränat finns det en månatlig gräns på 5 000 textposter per månad, per resurs. Det innebär att samma gräns gäller för alla projekt inom samma resurs.
Dricks
En textpost beräknas som taket för (Antal tecken i ett dokument /1 000). Om ett dokument till exempel innehåller 8 921 tecken är antalet textposter:
ceil(8921/1000) = ceil(8.921), vilket är 9 textposter.
I den vänstra navigeringsmenyn väljer du Dataetiketter.
Välj knappen Autoetikett under fönstret Aktivitet till höger på sidan.
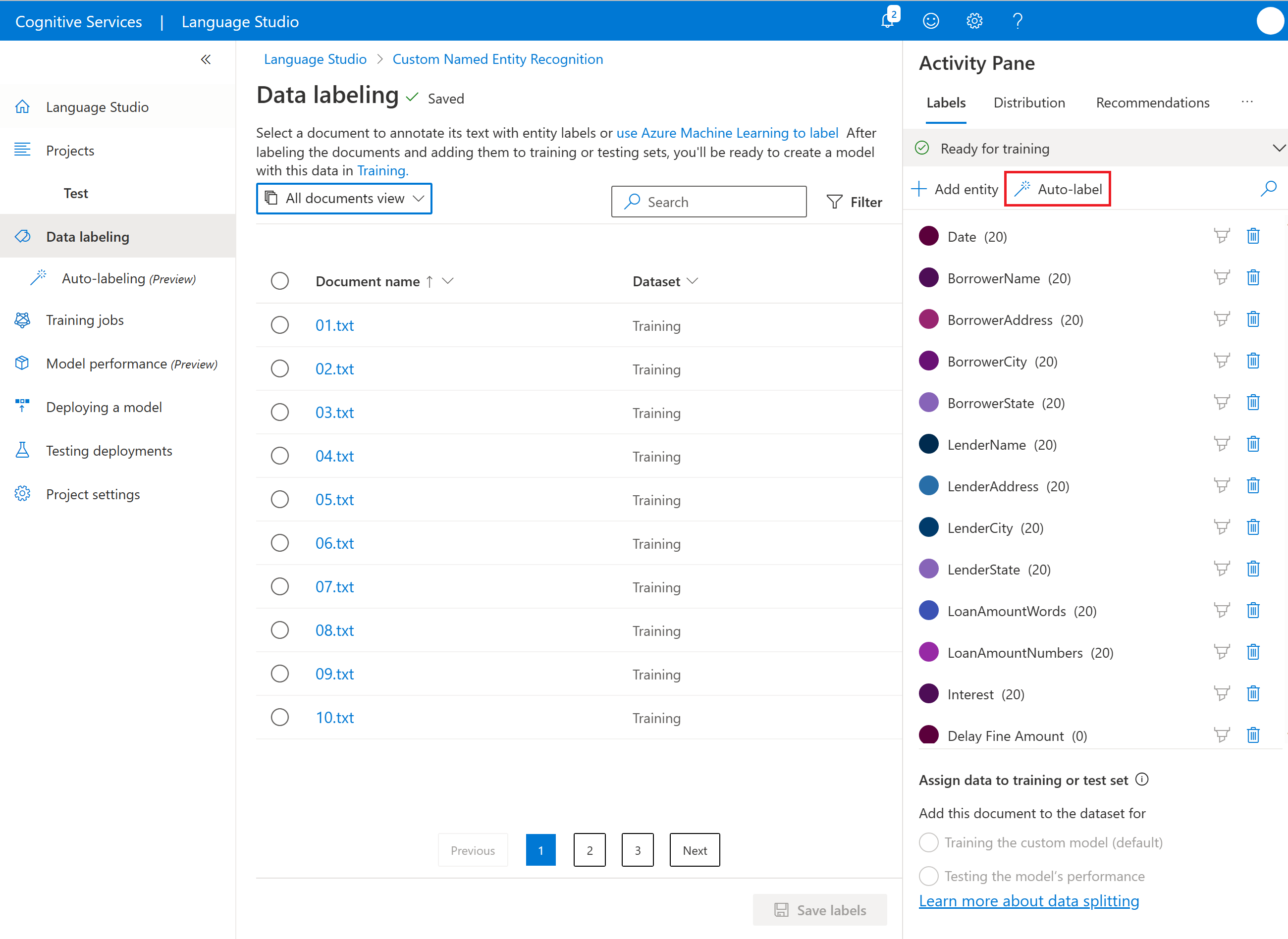
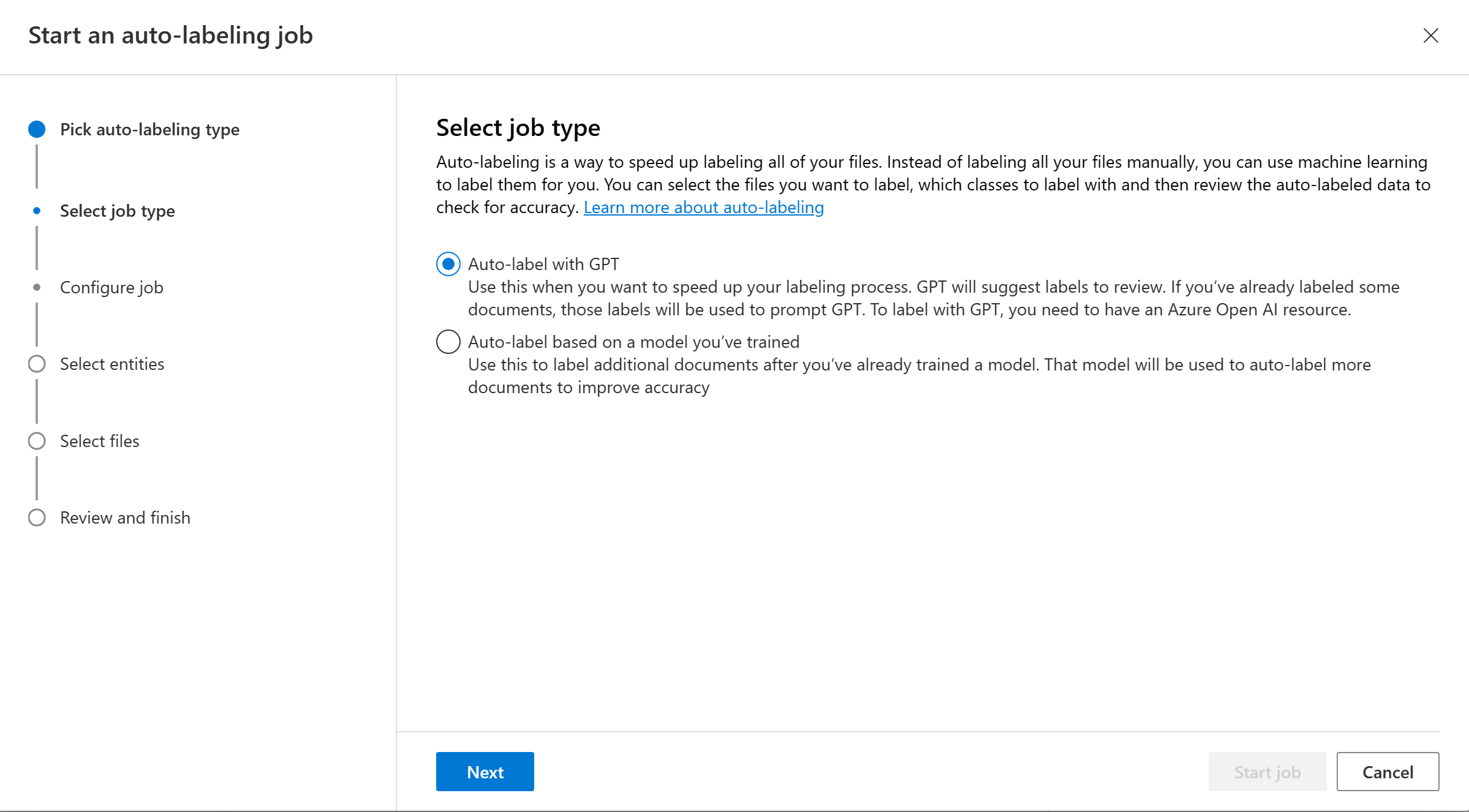
Välj Autoetikett baserat på en modell som du har tränat och välj Nästa.
Välj en tränad modell. Vi rekommenderar att du kontrollerar modellens prestanda innan du använder den för automatisk etikettering.

Välj de entiteter som du vill ska ingå i autoetiketteringsjobbet. Som standard är alla entiteter markerade. Du kan se de totala etiketterna, precisionen och återkallandet av varje entitet. Vi rekommenderar att du inkluderar entiteter som fungerar bra för att säkerställa kvaliteten på de automatiskt märkta entiteterna.

Välj de dokument som du vill ska etiketteras automatiskt. Antalet textposter för varje dokument visas. När du väljer ett eller flera dokument bör du se hur många textposter som har valts. Vi rekommenderar att du väljer de omärkta dokumenten från filtret.
Kommentar
- Om en entitet har etiketterats automatiskt, men har en användardefinierad etikett, används och visas endast den användardefinierade etiketten.
- Du kan visa dokumenten genom att klicka på dokumentnamnet.

Välj Autolabel för att utlösa autoetiketteringsjobbet. Du bör se vilken modell som används, antalet dokument som ingår i autoetiketteringsjobbet, antalet textposter och entiteter som ska märkas automatiskt. Automatisk etikettering av jobb kan ta allt från några sekunder till några minuter, beroende på antalet dokument som du har inkluderat.








Granska de automatiskt märkta dokumenten
När autoetiketteringsjobbet är klart kan du se utdatadokumenten på sidan Dataetiketter i Language Studio. Välj Granska dokument med autoetiketter för att visa dokumenten med det automatiskt märkta filtret tillämpat .

Entiteter som har etiketterats automatiskt visas med en streckad linje. Dessa entiteter har två väljare (en bockmarkering och ett "X") som gör att du kan acceptera eller avvisa den automatiska etiketten.
När en entitet har accepterats ändras den streckade linjen till en solid linje, och etiketten ingår i eventuell ytterligare modellträning som blir en användardefinierad etikett.
Du kan också acceptera eller avvisa alla automatiskt märkta entiteter i dokumentet med Acceptera alla eller Avvisa alla i det övre högra hörnet på skärmen.
När du har godkänt eller avvisat de etiketterade entiteterna väljer du Spara etiketter för att tillämpa ändringarna.
Kommentar
- Vi rekommenderar att du validerar automatiskt märkta entiteter innan du godkänner dem.
- Alla etiketter som inte accepterades tas bort när du tränar din modell.

Nästa steg
- Läs mer om att märka dina data.