Konfigurera personalizer-inlärningsloop
Viktigt!
Från och med den 20 september 2023 kommer du inte att kunna skapa nya personaliseringsresurser. Personanpassningstjänsten dras tillbaka den 1 oktober 2026.
Tjänstkonfigurationen omfattar hur tjänsten behandlar belöningar, hur ofta tjänsten utforskar, hur ofta modellen tränas om och hur mycket data som lagras.
Konfigurera inlärningsloopen på sidan Konfiguration i Azure-portalen för den personanpassningsresursen.
Planera konfigurationsändringar
Eftersom vissa konfigurationsändringar återställer din modell bör du planera konfigurationsändringarna.
Om du planerar att använda lärlingsläge bör du granska konfigurationen för Personanpassning innan du byter till Lärlingsläge.
Inställningar som omfattar återställning av modellen
Följande åtgärder utlöser en omträning av modellen med data som är tillgängliga upp till de senaste 2 dagarna.
- Belöning
- Utforskning
Om du vill rensa alla dina data använder du sidan Modell- och inlärningsinställningar .
Konfigurera belöningar för feedbackloopen
Konfigurera tjänsten för din inlärningsloops användning av belöningar. Ändringar i följande värden återställer den aktuella personanpassningsmodellen och tränar om den med de senaste två dagarnas data.
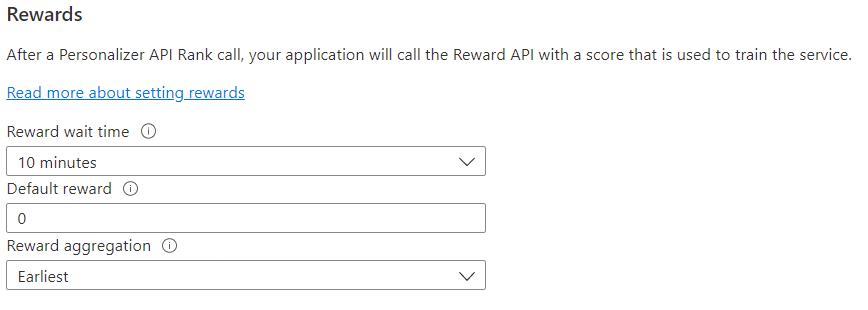
| Värde | Syfte |
|---|---|
| Väntetid för belöning | Anger hur lång tid personanpassningen ska samla in belöningsvärden för ett rankningsanrop, från och med det ögonblick då Rank-anropet inträffar. Det här värdet anges genom att fråga: "Hur länge ska personaliseraren vänta på belöningssamtal?" Alla belöningar som kommer efter det här fönstret loggas men används inte för inlärning. |
| Standardbelöning | Om inget belöningssamtal tas emot av Personanpassning under fönstret Väntetid för belöning som är associerat med ett rankningssamtal tilldelar Personalizer standardbelöningen. Som standard, och i de flesta scenarier, är Standardbelöning noll (0). |
| Belöningsaggregering | Om flera belöningar tas emot för samma Rank API-anrop används den här aggregeringsmetoden: summa eller tidigast. Tidigast väljer den tidigaste poängen som tagits emot och tar bort resten. Detta är användbart om du vill ha en unik belöning bland eventuellt duplicerade anrop. |
När du har ändrat dessa värden måste du välja Spara.
Konfigurera utforskning så att inlärningsloopen kan anpassas
Anpassning kan identifiera nya mönster och anpassa sig till användarbeteendeändringar över tid genom att utforska alternativ i stället för att använda den tränade modellens förutsägelse. Utforskningsvärdet avgör vilken procentandel av Rank-anrop som besvaras med utforskning.
Ändringar av det här värdet återställer den aktuella personanpassningsmodellen och tränar om den med de senaste 2 dagarnas data.
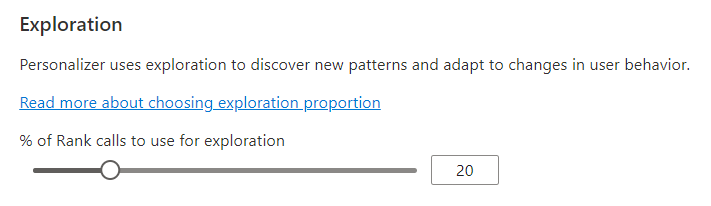
När du har ändrat det här värdet väljer du Spara.
Konfigurera modelluppdateringsfrekvens för modellträning
Uppdateringsfrekvensen för modell anger hur ofta modellen tränas.
| Frekvensinställning | Syfte |
|---|---|
| 1 minut | Uppdateringsfrekvenser på en minut är användbara när du felsöker ett programs kod med hjälp av Personanpassning, gör demonstrationer eller testar maskininlärningsaspekter interaktivt. |
| 15 minuter | Höga modelluppdateringsfrekvenser är användbara i situationer där du vill spåra ändringar i användarbeteenden. Exempel är webbplatser som körs på livenyheter, viralt innehåll eller liveproduktbudgivning. Du kan använda en frekvens på 15 minuter i dessa scenarier. |
| 1 timme | För de flesta användningsfall är en lägre uppdateringsfrekvens effektiv. |
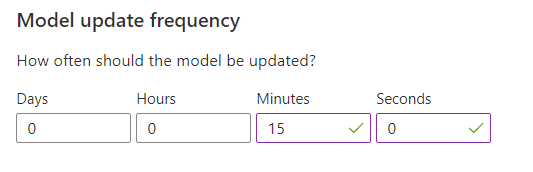
När du har ändrat det här värdet väljer du Spara.
Datakvarhållning
Datakvarhållningsperioden anger hur många dagar Personanpassning lagrar dataloggar. Tidigare dataloggar krävs för att utföra offlineutvärderingar, som används för att mäta effektiviteten hos Personanpassning och optimera inlärningspolicyn.
När du har ändrat det här värdet väljer du Spara.