Träna din professionella röstmodell
I den här artikeln får du lära dig hur du tränar en anpassad neural röst via Speech Studio-portalen.
Viktigt!
Anpassad neural röstträning är för närvarande endast tillgänglig i vissa regioner. När din röstmodell har tränats i en region som stöds kan du kopiera den till en Speech-resurs i en annan region efter behov. Mer information finns i fotnoterna i taltjänsttabellen.
Träningsvaraktigheten varierar beroende på hur mycket data du använder. Det tar i genomsnitt cirka 40 beräkningstimmar att träna en anpassad neural röst. Standardprenumerationsanvändare (S0) kan träna fyra röster samtidigt. Om du når gränsen väntar du tills minst en av dina röstmodeller har slutfört träningen och försöker sedan igen.
Kommentar
Även om det totala antalet timmar som krävs per träningsmetod varierar, gäller samma enhetspris för var och en. Mer information finns i prisinformationen för anpassad neural träning.
Välj en träningsmetod
När du har verifierat dina datafiler använder du dem för att skapa din anpassade neurala röstmodell. När du skapar en anpassad neural röst kan du välja att träna den med någon av följande metoder:
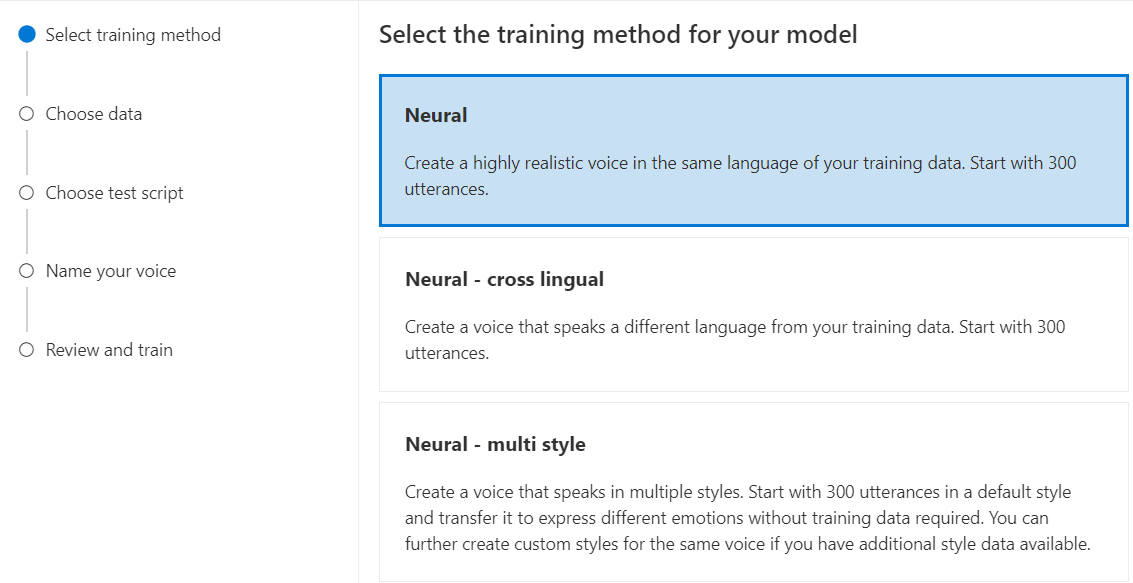
Neural: Skapa en röst på samma språk som dina träningsdata.
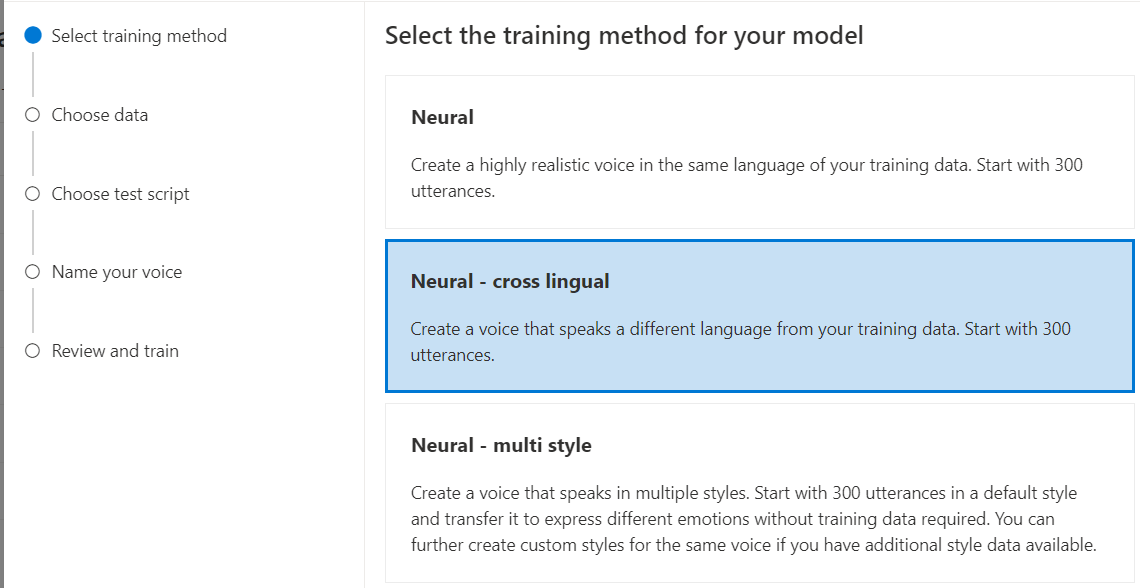
Neural – korslingual: Skapa en röst som talar ett annat språk än dina träningsdata. Med träningsdata kan du till exempel
zh-CNskapa en röst som talaren-US.Språket i träningsdata och målspråket måste båda vara ett av de språk som stöds för korsspråkig röstträning. Du behöver inte förbereda träningsdata på målspråket, men testskriptet måste vara på målspråket.
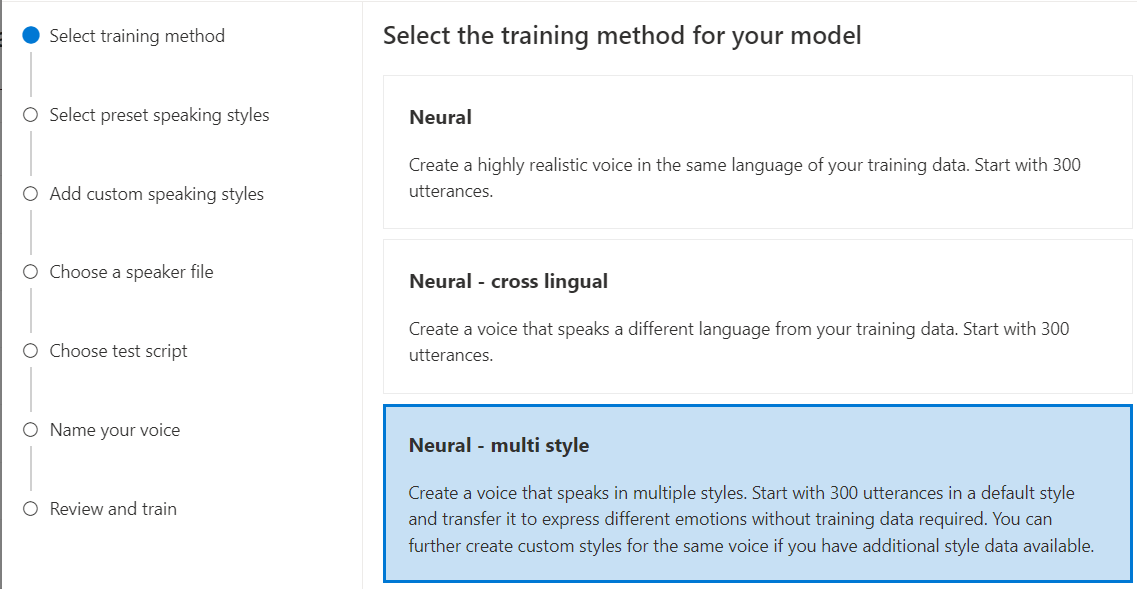
Neural – flera format: Skapa en anpassad neural röst som talar i flera stilar och känslor, utan att lägga till nya träningsdata. Flera stilröster är användbara för videospelskaraktärer, konversationschattrobotar, ljudböcker, innehållsläsare med mera.
Om du vill skapa en röst med flera format måste du förbereda en uppsättning allmänna träningsdata, minst 300 yttranden. Välj en eller flera av de förinställda måltalande formatmallarna. Du kan också skapa flera anpassade format genom att tillhandahålla formatexempel, med minst 100 yttranden per format, som extra träningsdata för samma röst. De förinställda format som stöds varierar beroende på olika språk. Se tillgängliga förinställda format på olika språk.
Språket för träningsdata måste vara ett av de språk som stöds för anpassad neural röst, korslinguell eller flera formatträning.
Träna din anpassade neurala röstmodell
Följ dessa steg för någon av följande metoder för att skapa en anpassad neural röst i Speech Studio:
Logga in på Speech Studio.
Välj Anpassad röst<>Projektnamnet>>Träna modell>Träna en ny modell.
Välj Neural som träningsmetod för din modell och välj sedan Nästa. Om du vill använda en annan träningsmetod kan du läsa Neural – korslingual eller Neural – i flera format.
Välj en version av träningsreceptet för din modell. Den senaste versionen är markerad som standard. De funktioner och träningstider som stöds kan variera beroende på version. Normalt rekommenderar vi den senaste versionen. I vissa fall kan du välja en tidigare version för att minska träningstiden. Mer information om tvåspråkig utbildning och skillnader mellan nationella inställningar finns i Tvåspråkig utbildning .
Kommentar
Modellversionerna
V2.2021.07,V4.2021.10,V5.2022.05,V6.2022.11ochV9.2023.10kommer att dras tillbaka senast den 1 oktober 2024. De röstmodeller som redan har skapats i dessa tillbakadragna versioner påverkas inte.Välj de data som du vill använda för träning. Dubbletter av ljudnamn tas bort från träningen. Kontrollera att de data du väljer inte innehåller samma ljudnamn i flera .zip filer.
Du kan bara välja datauppsättningar som har bearbetats för träning. Om du inte ser träningsuppsättningen i listan kontrollerar du databehandlingsstatusen.
Välj en talarfil med rösttalang-instruktionen som motsvarar talaren i dina träningsdata.
Välj Nästa.
Varje träning genererar 100 ljudexempelfiler automatiskt som hjälper dig att testa modellen med ett standardskript.
Du kan också välja Lägg till mitt eget testskript och ange ett eget testskript med upp till 100 yttranden för att testa modellen utan extra kostnad. De genererade ljudfilerna är en kombination av automatiska testskript och anpassade testskript. Mer information finns i testskriptkrav.
Ange ett namn som hjälper dig att identifiera modellen. Välj ett namn noggrant. Modellnamnet används som röstnamn i din talsyntesbegäran av SDK- och SSML-indata. Endast bokstäver, siffror och några skiljetecken tillåts. Använd olika namn för olika neurala röstmodeller.
Du kan också ange beskrivningen som hjälper dig att identifiera modellen. En vanlig användning av beskrivningen är att registrera namnen på de data som du använde för att skapa modellen.
Välj Nästa.
Granska inställningarna och välj rutan för att acceptera användningsvillkoren.
Välj Skicka för att börja träna modellen.
Tvåspråkig träning
Om du väljer neural träningstyp kan du träna en röst att tala på flera språk. Språkvarianterna zh-CN, zh-HKoch zh-TW stöder tvåspråkig utbildning för att rösten ska tala både kinesiska och engelska. Beroende delvis på dina träningsdata kan den syntetiserade rösten tala engelska med en engelsk infödd accent eller engelska med samma accent som träningsdata.
Kommentar
Om du vill att en röst på språkspråket zh-CN ska tala engelska med samma dekorfärg som exempeldata bör du välja Chinese (Mandarin, Simplified), English bilingual när du skapar ett projekt eller ange språkvarianten zh-CN (English bilingual) för träningsuppsättningsdata via REST API.
I följande tabell visas skillnaderna mellan nationella inställningar:
| Språkvariant för Speech Studio | SPRÅKVARIANT FÖR REST API | Tvåspråkigt stöd |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Om dina exempeldata innehåller engelska talar den syntetiserade rösten engelska med en engelsk infödd accent, i stället för samma accent som exempeldata, oavsett mängden engelska data. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Om du vill att den syntetiserade rösten ska tala engelska med samma accent som exempeldata rekommenderar vi att du inkluderar över 10 % engelska data i träningsuppsättningen. Annars kanske den engelsktalande accenten inte är idealisk. |
Chinese (Cantonese, Simplified) |
zh-HK |
Om du vill träna en syntetiserad röst som kan tala engelska med samma accent som dina exempeldata måste du ange över 10 % engelska data i träningsuppsättningen. Annars är standardinställningen en engelsk infödd accent. Tröskelvärdet på 10 % beräknas baserat på de data som accepteras efter en lyckad uppladdning, inte data innan de laddas upp. Om vissa uppladdade engelska data avvisas på grund av defekter och inte uppfyller tröskelvärdet på 10 % är den syntetiserade rösten som standard en engelsk infödd accent. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Om du vill träna en syntetiserad röst som kan tala engelska med samma accent som dina exempeldata måste du ange över 10 % engelska data i träningsuppsättningen. Annars är standardinställningen en engelsk infödd accent. Tröskelvärdet på 10 % beräknas baserat på de data som accepteras efter en lyckad uppladdning, inte data innan de laddas upp. Om vissa uppladdade engelska data avvisas på grund av defekter och inte uppfyller tröskelvärdet på 10 % är den syntetiserade rösten som standard en engelsk infödd accent. |
Tillgängliga förinställda format på olika språk
I följande tabell sammanfattas de olika förinställda formaten enligt olika språk.
| Samtalsstil | Språk (språk) |
|---|---|
| arg | Engelska (USA) (en-US)Japanska (Japan) ( ja-JP) 1Kinesiska (mandarin, förenklad) ( zh-CN) 1 |
| lugn | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| chatt | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| gladlynt | Engelska (USA) (en-US)Japanska (Japan) ( ja-JP) 1Kinesiska (mandarin, förenklad) ( zh-CN) 1 |
| missnöjd | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| upphetsad | Engelska (USA) (en-US) |
| fruktansvärd | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| vänlig | Engelska (USA) (en-US) |
| hoppfull | Engelska (USA) (en-US) |
| Ledsen | Engelska (USA) (en-US)Japanska (Japan) ( ja-JP) 1Kinesiska (mandarin, förenklad) ( zh-CN) 1 |
| Skrika | Engelska (USA) (en-US) |
| allvarlig | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| förskräckt | Engelska (USA) (en-US) |
| ovänlig | Engelska (USA) (en-US) |
| Viskar | Engelska (USA) (en-US) |
1 Den neurala röststilen är tillgänglig i offentlig förhandsversion. Formatmallar i offentlig förhandsversion är endast tillgängliga i dessa tjänstregioner: USA, östra, Europa, västra och Asien, sydöstra.
Tabellen Träna modell visar en ny post som motsvarar den nya modellen. Statusen återspeglar processen för att konvertera dina data till en röstmodell enligt beskrivningen i den här tabellen:
| Tillstånd | Innebörd |
|---|---|
| Bearbetning | Din röstmodell skapas. |
| Klart | Din röstmodell har skapats och kan distribueras. |
| Misslyckad | Din röstmodell har misslyckats i träningen. Orsaken till felet kan till exempel vara osedda dataproblem eller nätverksproblem. |
| Avbruten | Träningen för din röstmodell avbröts. |
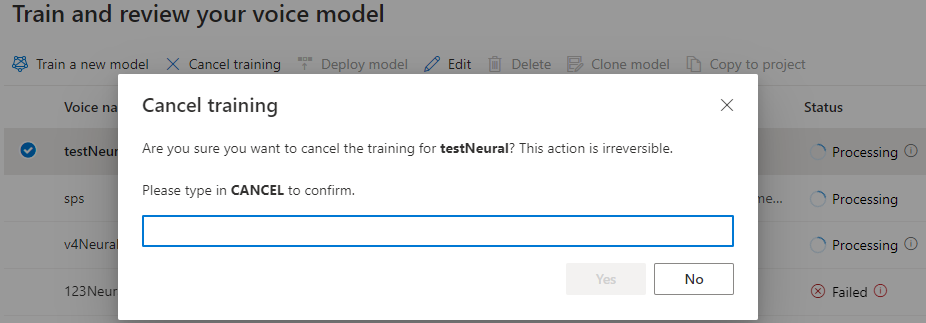
Medan modellstatusen är Bearbetning kan du välja Avbryt träning för att avbryta röstmodellen. Du debiteras inte för den här avbrutna träningen.
När du har tränat modellen kan du granska modellinformationen och testa din röstmodell.
Du kan använda verktyget Skapa ljudinnehåll i Speech Studio för att skapa ljud och finjustera din distribuerade röst. Om det är tillämpligt för din röst kan du välja ett av flera formatmallar.
Byt namn på din modell
Om du vill byta namn på den modell som du skapade väljer du Klona modell för att skapa en klon av modellen med ett nytt namn i det aktuella projektet.
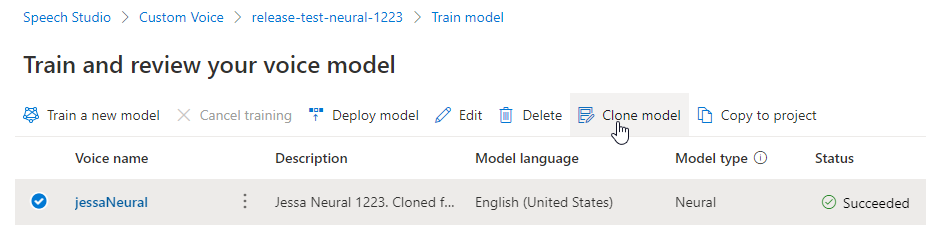
Ange det nya namnet i fönstret Klona röstmodell och välj sedan Skicka. Texten Neural läggs automatiskt till som ett suffix i det nya modellnamnet.
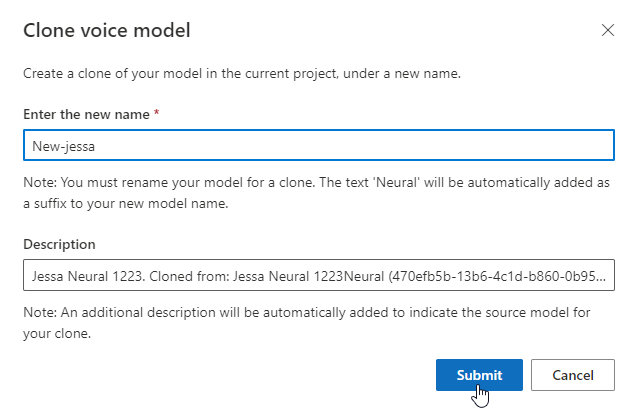
Testa din röstmodell
När röstmodellen har skapats kan du använda de genererade ljudfilerna för att testa den innan du distribuerar den.
Röstens kvalitet beror på många faktorer, till exempel:
- Storleken på träningsdata.
- Kvaliteten på inspelningen.
- Noggrannheten i avskriftsfilen.
- Hur väl den inspelade rösten i träningsdata matchar den designade röstens personlighet för ditt avsedda användningsfall.
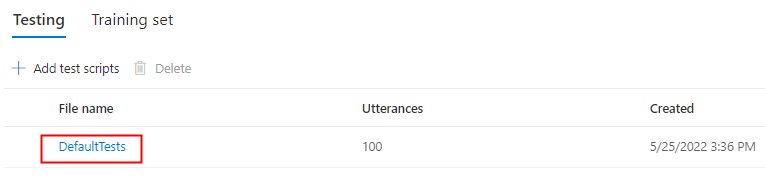
Välj DefaultTests under Testning för att lyssna på exempelljudfilerna. Standardtestexemplen innehåller 100 exempelljudfiler som genereras automatiskt under träningen för att hjälpa dig att testa modellen. Utöver dessa 100 ljudfiler som tillhandahålls som standard läggs även dina egna testskriptyttranden till i DefaultTests-uppsättningen . Det här tillägget är högst 100 yttranden. Du debiteras inte för testningen med DefaultTests.
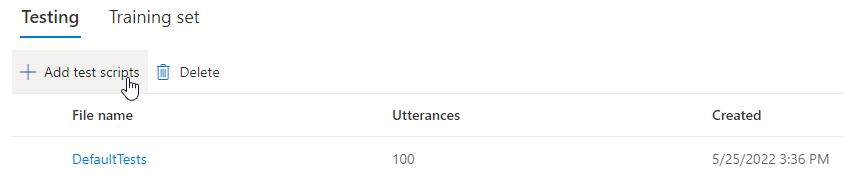
Om du vill ladda upp egna testskript för att ytterligare testa din modell väljer du Lägg till testskript för att ladda upp ditt eget testskript.
Kontrollera kraven för testskript innan du laddar upp testskriptet. Du debiteras för den extra testningen med batchsyntesen baserat på antalet fakturerbara tecken. Se Priser för Azure AI Speech.
Under Lägg till testskript väljer du Bläddra efter en fil för att välja ditt eget skript och sedan Lägg till för att ladda upp den.
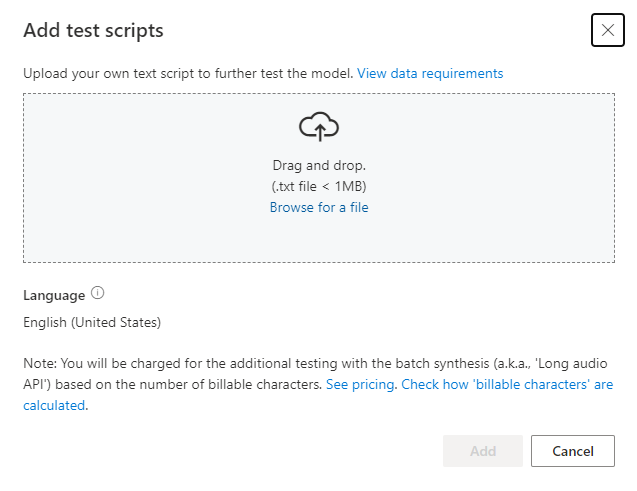
Krav för testskript
Testskriptet måste vara en .txt fil som är mindre än 1 MB. Kodningsformat som stöds är ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE eller UTF-16-BE.
Till skillnad från transkriptionsfilerna för träning bör testskriptet undanta yttrande-ID:t, som är filnamnet för varje yttrande. Annars talas dessa ID:er.
Här är en exempeluppsättning med yttranden i en .txt fil:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Varje stycke i yttrandet resulterar i ett separat ljud. Om du vill kombinera alla meningar till ett ljud gör du dem till ett enda stycke.
Kommentar
De genererade ljudfilerna är en kombination av automatiska testskript och anpassade testskript.
Uppdatera motorversionen för din röstmodell
Azure text till talmotorer uppdateras då och då för att samla in den senaste språkmodellen som definierar uttalet av språket. När du har tränat din röst kan du tillämpa din röst på den nya språkmodellen genom att uppdatera till den senaste motorversionen.
När en ny motor är tillgänglig uppmanas du att uppdatera din neurala röstmodell.

Gå till sidan med modellinformation och följ anvisningarna på skärmen för att installera den senaste motorn.
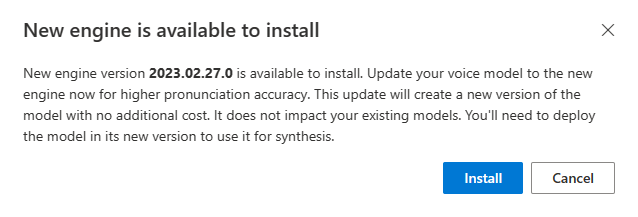
Du kan också välja Installera den senaste motorn senare för att uppdatera din modell till den senaste motorversionen.
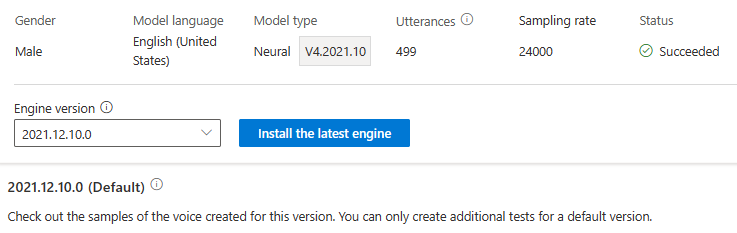
Du debiteras inte för motoruppdatering. De tidigare versionerna behålls fortfarande.
Du kan kontrollera alla motorversioner för modellen från listan Motorversion eller ta bort en om du inte behöver den längre.
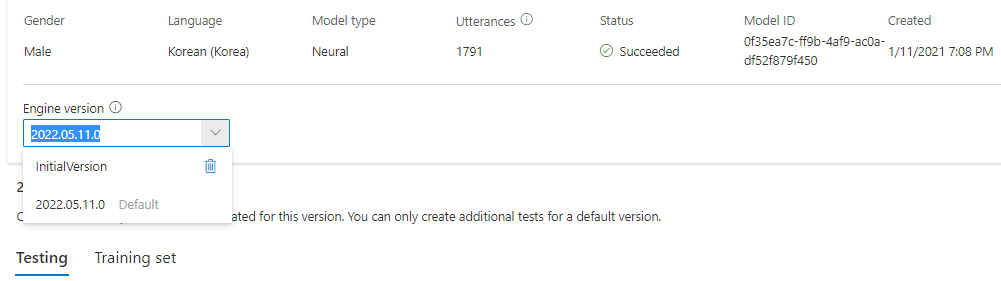
Den uppdaterade versionen anges automatiskt som standard. Men du kan ändra standardversionen genom att välja en version i listrutan och välja Ange som standard.
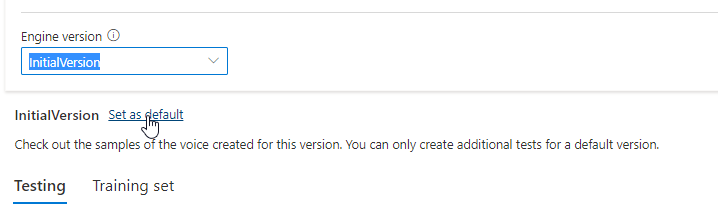

Om du vill testa varje motorversion av röstmodellen kan du välja en version i listan och sedan välja DefaultTests under Testning för att lyssna på ljudfilerna. Om du vill ladda upp dina egna testskript för att ytterligare testa den aktuella motorversionen kontrollerar du först att versionen är inställd som standard och följer sedan stegen i Testa din röstmodell.
När motorn uppdateras skapas en ny version av modellen utan extra kostnad. När du har uppdaterat motorversionen för röstmodellen måste du distribuera den nya versionen för att skapa en ny slutpunkt. Du kan bara distribuera standardversionen.
När du har skapat en ny slutpunkt måste du överföra trafiken till den nya slutpunkten i produkten.
Mer information om funktionerna och gränserna för den här funktionen och bästa praxis för att förbättra modellkvaliteten finns i Egenskaper och begränsningar för att använda anpassad neural röst.
Kopiera röstmodellen till ett annat projekt
Du kan kopiera röstmodellen till ett annat projekt för samma region eller en annan region. Du kan till exempel kopiera en neural röstmodell som har tränats i en region till ett projekt för en annan region.
Kommentar
Anpassad neural röstträning är för närvarande endast tillgänglig i vissa regioner. Du kan kopiera en neural röstmodell från dessa regioner till andra regioner. Mer information finns i regionerna för anpassad neural röst.
Så här kopierar du din anpassade neurala röstmodell till ett annat projekt:
På fliken Träna modell väljer du en röstmodell som du vill kopiera och väljer sedan Kopiera till projekt.
Välj den prenumeration, region, talresurs och projekt där du vill kopiera modellen. Du måste ha en talresurs och ett projekt i målregionen, annars måste du skapa dem först.
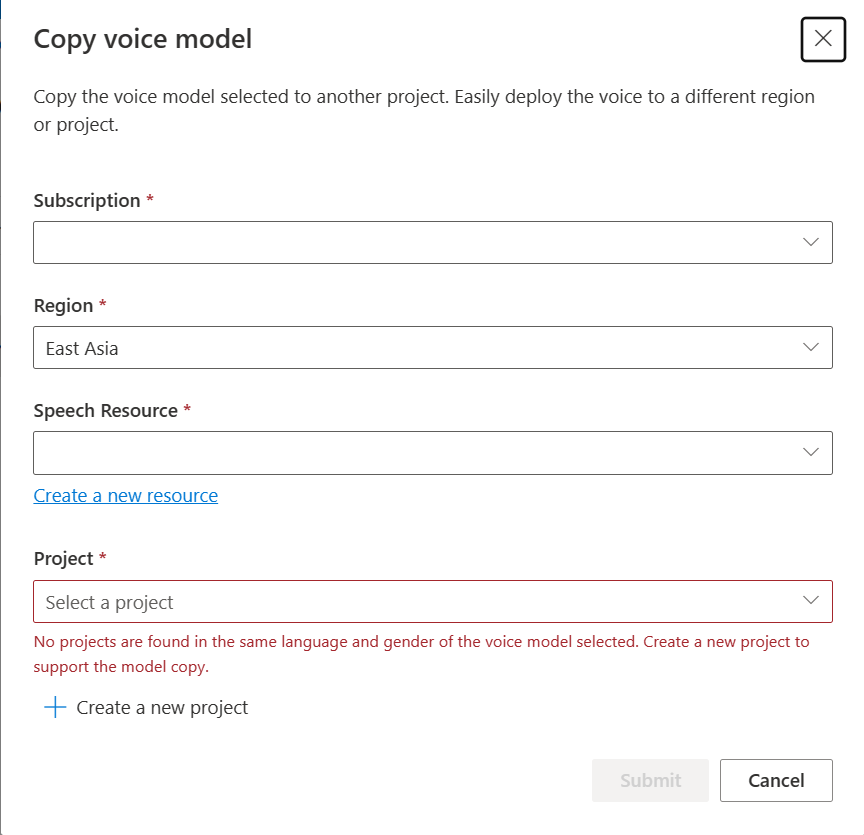
Välj Skicka för att kopiera modellen.
Välj Visa modell under meddelandemeddelandet för lyckad kopiering.
Gå till projektet där du kopierade modellen för att distribuera modellkopian.
Nästa steg
I den här artikeln får du lära dig hur du tränar en anpassad neural röst via det anpassade röst-API:et.
Viktigt!
Anpassad neural röstträning är för närvarande endast tillgänglig i vissa regioner. När din röstmodell har tränats i en region som stöds kan du kopiera den till en Speech-resurs i en annan region efter behov. Mer information finns i fotnoterna i taltjänsttabellen.
Träningsvaraktigheten varierar beroende på hur mycket data du använder. Det tar i genomsnitt cirka 40 beräkningstimmar att träna en anpassad neural röst. Standardprenumerationsanvändare (S0) kan träna fyra röster samtidigt. Om du når gränsen väntar du tills minst en av dina röstmodeller har slutfört träningen och försöker sedan igen.
Kommentar
Även om det totala antalet timmar som krävs per träningsmetod varierar, gäller samma enhetspris för var och en. Mer information finns i prisinformationen för anpassad neural träning.
Välj en träningsmetod
När du har verifierat dina datafiler använder du dem för att skapa din anpassade neurala röstmodell. När du skapar en anpassad neural röst kan du välja att träna den med någon av följande metoder:
Neural: Skapa en röst på samma språk som dina träningsdata.
Neural – korslingual: Skapa en röst som talar ett annat språk än dina träningsdata. Med träningsdata kan du till exempel
fr-FRskapa en röst som talaren-US.Språket i träningsdata och målspråket måste båda vara ett av de språk som stöds för korsspråkig röstträning. Du behöver inte förbereda träningsdata på målspråket, men testskriptet måste vara på målspråket.
Neural – flera format: Skapa en anpassad neural röst som talar i flera stilar och känslor, utan att lägga till nya träningsdata. Flera stilröster är användbara för videospelskaraktärer, konversationschattrobotar, ljudböcker, innehållsläsare med mera.
Om du vill skapa en röst med flera format måste du förbereda en uppsättning allmänna träningsdata, minst 300 yttranden. Välj en eller flera av de förinställda måltalande formatmallarna. Du kan också skapa flera anpassade format genom att tillhandahålla formatexempel, med minst 100 yttranden per format, som extra träningsdata för samma röst. De förinställda format som stöds varierar beroende på olika språk. Se tillgängliga förinställda format på olika språk.
Språket i träningsdata måste vara ett av de språk som stöds för anpassad neural röst, korslingual eller träning i flera format.
Skapa en röstmodell
Om du vill skapa en neural röst använder du den Models_Create åtgärden för det anpassade röst-API:et. Skapa begärandetexten enligt följande instruktioner:
- Ange den obligatoriska
projectIdegenskapen. Se skapa ett projekt. - Ange den obligatoriska
consentIdegenskapen. Se lägga till rösttalangmedgivande. - Ange den obligatoriska
trainingSetIdegenskapen. Se skapa en träningsuppsättning. - Ange den nödvändiga receptegenskapen
kindtillDefaultför neural röstträning. Recepttypen anger träningsmetoden och kan inte ändras senare. Om du vill använda en annan träningsmetod kan du läsa Neural – korslingual eller Neural – i flera format. Mer information om tvåspråkig utbildning och skillnader mellan nationella inställningar finns i Tvåspråkig utbildning . - Ange den obligatoriska
voiceNameegenskapen. Röstnamnet måste sluta med "Neural" och kan inte ändras senare. Välj ett namn noggrant. Röstnamnet används i din talsyntesbegäran av SDK- och SSML-indata. Endast bokstäver, siffror och några skiljetecken tillåts. Använd olika namn för olika neurala röstmodeller. - Du kan också ange
descriptionegenskapen för röstbeskrivningen. Röstbeskrivningen kan ändras senare.
Gör en HTTP PUT-begäran med hjälp av URI:n enligt följande Models_Create exempel.
- Ersätt
YourResourceKeymed din Speech-resursnyckel. - Ersätt
YourResourceRegionmed din Speech-resursregion. - Ersätt
JessicaModelIdmed ett valfritt modell-ID. Skiftlägeskänsligt ID används i modellens URI och kan inte ändras senare.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
Du bör få en svarstext i följande format:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Tvåspråkig träning
Om du väljer neural träningstyp kan du träna en röst att tala på flera språk. Språkvarianterna zh-CN, zh-HKoch zh-TW stöder tvåspråkig utbildning för att rösten ska tala både kinesiska och engelska. Beroende delvis på dina träningsdata kan den syntetiserade rösten tala engelska med en engelsk infödd accent eller engelska med samma accent som träningsdata.
Kommentar
Om du vill att en röst på språkspråket zh-CN ska tala engelska med samma dekorfärg som exempeldata bör du välja Chinese (Mandarin, Simplified), English bilingual när du skapar ett projekt eller ange språkvarianten zh-CN (English bilingual) för träningsuppsättningsdata via REST API.
I följande tabell visas skillnaderna mellan nationella inställningar:
| Språkvariant för Speech Studio | SPRÅKVARIANT FÖR REST API | Tvåspråkigt stöd |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Om dina exempeldata innehåller engelska talar den syntetiserade rösten engelska med en engelsk infödd accent, i stället för samma accent som exempeldata, oavsett mängden engelska data. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Om du vill att den syntetiserade rösten ska tala engelska med samma accent som exempeldata rekommenderar vi att du inkluderar över 10 % engelska data i träningsuppsättningen. Annars kanske den engelsktalande accenten inte är idealisk. |
Chinese (Cantonese, Simplified) |
zh-HK |
Om du vill träna en syntetiserad röst som kan tala engelska med samma accent som dina exempeldata måste du ange över 10 % engelska data i träningsuppsättningen. Annars är standardinställningen en engelsk infödd accent. Tröskelvärdet på 10 % beräknas baserat på de data som accepteras efter en lyckad uppladdning, inte data innan de laddas upp. Om vissa uppladdade engelska data avvisas på grund av defekter och inte uppfyller tröskelvärdet på 10 % är den syntetiserade rösten som standard en engelsk infödd accent. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Om du vill träna en syntetiserad röst som kan tala engelska med samma accent som dina exempeldata måste du ange över 10 % engelska data i träningsuppsättningen. Annars är standardinställningen en engelsk infödd accent. Tröskelvärdet på 10 % beräknas baserat på de data som accepteras efter en lyckad uppladdning, inte data innan de laddas upp. Om vissa uppladdade engelska data avvisas på grund av defekter och inte uppfyller tröskelvärdet på 10 % är den syntetiserade rösten som standard en engelsk infödd accent. |
Tillgängliga förinställda format på olika språk
I följande tabell sammanfattas de olika förinställda formaten enligt olika språk.
| Samtalsstil | Språk (språk) |
|---|---|
| arg | Engelska (USA) (en-US)Japanska (Japan) ( ja-JP) 1Kinesiska (mandarin, förenklad) ( zh-CN) 1 |
| lugn | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| chatt | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| gladlynt | Engelska (USA) (en-US)Japanska (Japan) ( ja-JP) 1Kinesiska (mandarin, förenklad) ( zh-CN) 1 |
| missnöjd | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| upphetsad | Engelska (USA) (en-US) |
| fruktansvärd | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| vänlig | Engelska (USA) (en-US) |
| hoppfull | Engelska (USA) (en-US) |
| Ledsen | Engelska (USA) (en-US)Japanska (Japan) ( ja-JP) 1Kinesiska (mandarin, förenklad) ( zh-CN) 1 |
| Skrika | Engelska (USA) (en-US) |
| allvarlig | Kinesiska (mandarin, förenklad) (zh-CN) 1 |
| förskräckt | Engelska (USA) (en-US) |
| ovänlig | Engelska (USA) (en-US) |
| Viskar | Engelska (USA) (en-US) |
1 Den neurala röststilen är tillgänglig i offentlig förhandsversion. Formatmallar i offentlig förhandsversion är endast tillgängliga i dessa tjänstregioner: USA, östra, Europa, västra och Asien, sydöstra.
Hämta träningsstatus
Om du vill få träningsstatus för en röstmodell använder du den Models_Get funktionen för det anpassade röst-API:et. Konstruera begärande-URI:n enligt följande instruktioner:
Gör en HTTP GET-begäran med hjälp av URI:n enligt följande Models_Get exempel.
- Ersätt
YourResourceKeymed din Speech-resursnyckel. - Ersätt
YourResourceRegionmed din Speech-resursregion. - Ersätt
JessicaModelIdom du angav ett annat modell-ID i föregående steg.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Du bör få en svarstext i följande format.
Kommentar
Receptet kind och andra egenskaper beror på hur du tränade rösten. I det här exemplet är Default recepttyp för neural röstträning.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Du kan behöva vänta i flera minuter innan träningen är klar. Så småningom ändras statusen till antingen Succeeded eller Failed.