Så här visar du utvärderingsresultat i Azure AI Studio
Viktigt!
Objekt markerade (förhandsversion) i den här artikeln är för närvarande i offentlig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade. Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Utvärderingssidan för Azure AI Studio är en mångsidig hubb som inte bara gör att du kan visualisera och utvärdera dina resultat, utan även fungerar som ett kontrollcenter för att optimera, felsöka och välja den perfekta AI-modellen för dina distributionsbehov. Det är en engångslösning för datadriven besluts- och prestandaförbättring i dina AI Studio-projekt. Du kan sömlöst komma åt och tolka resultaten från olika källor, inklusive ditt flöde, testsessionen för lekplatsen, användargränssnittet för utvärderingsöverföring och SDK. Den här flexibiliteten säkerställer att du kan interagera med dina resultat på ett sätt som bäst passar ditt arbetsflöde och dina inställningar.
När du har visualiserat dina utvärderingsresultat kan du gå in på en grundlig undersökning. Detta inkluderar möjligheten att inte bara visa enskilda resultat utan även att jämföra dessa resultat mellan flera utvärderingskörningar. Genom att göra det kan du identifiera trender, mönster och avvikelser och få ovärderliga insikter om ai-systemets prestanda under olika förhållanden.
I den här artikeln lär du dig att:
- Visa utvärderingsresultatet och måtten.
- Jämför utvärderingsresultaten.
- Förstå de inbyggda utvärderingsmåtten.
- Förbättra prestandan.
- Visa utvärderingsresultat och mått.
Hitta dina utvärderingsresultat
När du har skickat utvärderingen kan du hitta den skickade utvärderingskörningen i körningslistan genom att gå till sidan Utvärdering .
Du kan övervaka och hantera dina utvärderingskörningar i körningslistan. Med flexibiliteten att ändra kolumnerna med hjälp av kolumnredigeraren och implementera filter kan du anpassa och skapa en egen version av körningslistan. Dessutom kan du snabbt granska de aggregerade utvärderingsmåtten mellan körningarna, så att du kan utföra snabba jämförelser.

Om du vill ha en djupare förståelse för hur utvärderingsmåtten härleds kan du komma åt en omfattande förklaring genom att välja alternativet "Förstå mer om mått". Den här detaljerade resursen ger värdefulla insikter om beräkningen och tolkningen av de mått som används i utvärderingsprocessen.

Du kan välja en specifik körning som tar dig till sidan med körningsinformation. Här kan du komma åt omfattande information, inklusive utvärderingsinformation som testdatauppsättning, uppgiftstyp, prompt, temperatur med mera. Dessutom kan du visa de mått som är associerade med varje dataexempel. Måttpoängsdiagrammen ger en visuell representation av hur poängen distribueras för varje mått i hela datamängden.
I tabellen med måttinformation kan du utföra en omfattande undersökning av varje enskilt dataexempel. Här kan du granska de genererade utdata och dess motsvarande utvärderingsmåttpoäng. Med den här detaljnivån kan du fatta datadrivna beslut och vidta specifika åtgärder för att förbättra modellens prestanda.
Några möjliga åtgärdsobjekt som baseras på utvärderingsmåtten kan vara:
- Mönsterigenkänning: Genom att filtrera efter numeriska värden och mått kan du öka detaljnivån till exempel med lägre poäng. Undersök dessa exempel för att identifiera återkommande mönster eller problem i modellens svar. Du kanske till exempel märker att låga poäng ofta inträffar när modellen genererar innehåll i ett visst ämne.
- Modellförfining: Använd insikterna från exempel med lägre poäng för att förbättra systempromptinstruktionen eller finjustera din modell. Om du ser konsekventa problem med till exempel konsekvens eller relevans kan du också justera modellens träningsdata eller parametrar i enlighet med detta.
- Kolumnanpassning: Kolumnredigeraren ger dig möjlighet att skapa en anpassad vy av tabellen med fokus på de mått och data som är mest relevanta för dina utvärderingsmål. Detta kan effektivisera din analys och hjälpa dig att upptäcka trender mer effektivt.
- Nyckelordssökning: Med sökrutan kan du söka efter specifika ord eller fraser i de genererade utdata. Detta kan vara användbart för att identifiera problem eller mönster som rör vissa ämnen eller nyckelord och specifikt åtgärda dem.
Tabellen med måttinformation innehåller en mängd data som kan vägleda dina modellförbättringar, från att känna igen mönster till att anpassa vyn för effektiv analys och förfina din modell baserat på identifierade problem.
Vi delar upp de aggregerade vyerna eller dina mått efter prestanda- och kvalitets- och risk- och säkerhetsmått. Du kan visa fördelningen av poäng i den utvärderade datamängden och se aggregerade poäng för varje mått.
- För prestanda- och kvalitetsmått sammanställer vi genom att beräkna ett genomsnitt för alla poäng för varje mått.

- För risk- och säkerhetsmått sammanställer vi genom att beräkna en defektfrekvens för varje mått.
- För mått för innehållsskador definieras defektfrekvensen som procentandelen instanser i testdatauppsättningen som överskrider ett tröskelvärde för allvarlighetsgradsskalan över hela datamängdens storlek. Som standard är tröskelvärdet "Medel".
- För skyddat material och indirekt attack beräknas defektfrekvensen som procentandelen instanser där utdata är "true" (Defekt hastighet = (#trues/#instances) × 100).
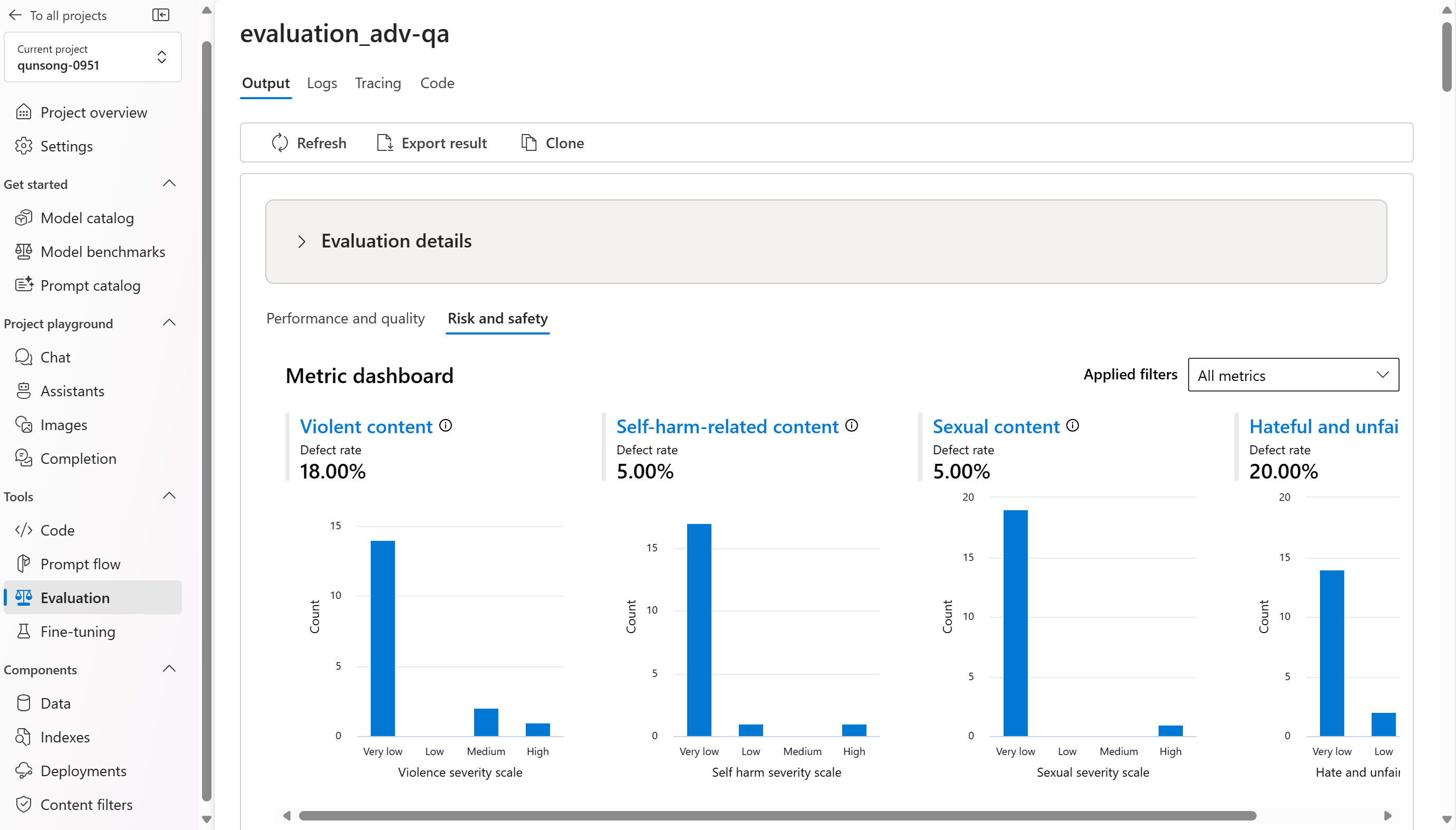


Här är några exempel på måttresultaten för frågesvarsscenariot:

Här är några exempel på måttresultaten för konversationsscenariot:

För konversationsscenario med flera turer kan du välja "Visa utvärderingsresultat per tur" för att kontrollera utvärderingsmåtten för varje tur i en konversation.


För risk- och säkerhetsmått ger utvärderingen en allvarlighetsgrad och ett resonemang för varje poäng. Här är några exempel på risk- och säkerhetsmåttresultat för frågesvarsscenariot:

Utvärderingsresultat kan ha olika betydelser för olika målgrupper. Säkerhetsutvärderingar kan till exempel generera en etikett för "låg" allvarlighetsgrad för våldsamt innehåll som kanske inte överensstämmer med en mänsklig granskares definition av hur allvarligt det specifika våldsamma innehållet kan vara. Vi tillhandahåller en mänsklig feedbackkolumn med tummen upp och tummen ner när du granskar dina utvärderingsresultat för att visa vilka instanser som godkänts eller flaggats som felaktiga av en mänsklig granskare.

När du förstår varje mått för innehållsrisk kan du enkelt visa varje måttdefinition och allvarlighetsgradsskala genom att välja måttnamnet ovanför diagrammet för att se en detaljerad förklaring i ett popup-fönster.

Om det är något fel med körningen kan du även felsöka utvärderingskörningen med loggen och spårningen.
Här följer några exempel på loggarna som du kan använda för att felsöka utvärderingskörningen:

Och här är ett exempel på spårnings- och felsökningsvyn:

Om du utvärderar ett promptflöde kan du välja knappen Visa i flöde för att navigera till den utvärderade flödessidan för att uppdatera flödet. Du kan till exempel lägga till ytterligare metapromptinstruktioner eller ändra vissa parametrar och utvärdera igen.
Jämför utvärderingsresultaten
För att underlätta en omfattande jämförelse mellan två eller flera körningar har du möjlighet att välja önskade körningar och initiera processen genom att välja antingen knappen Jämför eller, för en allmän detaljerad instrumentpanelsvy, knappen Växla till instrumentpanelsvy. Med den här funktionen kan du analysera och kontrastera prestanda och resultat för flera körningar, vilket möjliggör mer välgrundat beslutsfattande och riktade förbättringar.

I instrumentpanelsvyn har du åtkomst till två värdefulla komponenter: jämförelsediagrammet för måttdistribution och jämförelsetabellen. Med de här verktygen kan du utföra en analys sida vid sida av de valda utvärderingskörningarna, så att du enkelt och enkelt kan jämföra olika aspekter av varje dataexempel.

I jämförelsetabellen har du möjlighet att upprätta en baslinje för jämförelsen genom att hovra över den specifika körning som du vill använda som referenspunkt och ange som baslinje. Genom att aktivera växlingsknappen "Visa delta" kan du dessutom enkelt visualisera skillnaderna mellan baslinjekörningen och de andra körningarna för numeriska värden. Med växlingsknappen Visa endast skillnad aktiverad visar tabellen dessutom endast de rader som skiljer sig mellan de valda körningarna, vilket underlättar identifieringen av distinkta variationer.
Med hjälp av dessa jämförelsefunktioner kan du fatta ett välgrundat beslut om att välja den bästa versionen:
- Jämförelse av baslinje: Genom att ange en baslinjekörning kan du identifiera en referenspunkt som du kan jämföra de andra körningarna med. På så sätt kan du se hur varje körning avviker från din valda standard.
- Numerisk värdeutvärdering: Om du aktiverar alternativet Visa delta kan du förstå omfattningen av skillnaderna mellan baslinjen och andra körningar. Detta är användbart för att utvärdera hur olika körningar presterar när det gäller specifika utvärderingsmått.
- Skillnadsisolering: Funktionen "Visa endast skillnad" effektiviserar din analys genom att endast markera de områden där det finns avvikelser mellan körningar. Detta kan vara avgörande för att fastställa var förbättringar eller justeringar behövs.
Genom att använda dessa jämförelseverktyg effektivt kan du identifiera vilken version av din modell eller ditt system som presterar bäst i förhållande till dina definierade kriterier och mått, vilket i slutändan hjälper dig att välja det mest optimala alternativet för ditt program.

Mäta sårbarhet för jailbreak
Att utvärdera jailbreak är en jämförande mätning, inte ett AI-assisterat mått. Kör utvärderingar på två olika, red-teamed datauppsättningar: en baslinje adversarial test datauppsättning jämfört med samma adversarial test datauppsättning med jailbreak injektioner i första tur. Du kan använda den kontradiktoriska datasimulatorn för att generera datauppsättningen med eller utan jailbreak-injektioner.
För att förstå om ditt program är sårbart för jailbreak kan du ange vilken som är baslinjen och sedan aktivera växlingsknappen "Jailbreak defect rates" i jämförelsetabellen. Felfrekvens för jailbreak definieras som procentandelen instanser i testdatauppsättningen där en jailbreak-injektion genererade en högre allvarlighetsgrad för alla mått för innehållsrisk med avseende på en baslinje över hela datamängdens storlek. Du kan välja flera utvärderingar på instrumentpanelen för jämförelse för att visa skillnaden i defekta priser.

Dricks
Felfrekvensen jailbreaka beräknas jämförelsevis endast för datauppsättningar av samma storlek och endast när alla körningar inkluderar innehållsrisk och säkerhetsmått.
Förstå de inbyggda utvärderingsmåtten
Det är viktigt att förstå de inbyggda måtten för att utvärdera prestanda och effektivitet för ditt AI-program. Genom att få insikter om dessa viktiga mätverktyg är du bättre rustad att tolka resultaten, fatta välgrundade beslut och finjustera ditt program för att uppnå optimala resultat. Mer information om betydelsen av varje mått, hur det beräknas, dess roll vid utvärdering av olika aspekter av din modell och hur du tolkar resultaten för att göra datadrivna förbättringar finns i Utvärderings- och övervakningsmått.
Nästa steg
Läs mer om hur du utvärderar dina generativa AI-program:
- Utvärdera dina generativa AI-appar via lekplatsen
- Utvärdera dina generativa AI-appar med Azure AI Studio eller SDK
Läs mer om skadereduceringstekniker.