TDSP är en flexibel och iterativ datavetenskapsmetod som du kan använda för att leverera förutsägelseanalyslösningar och AI-program effektivt. TDSP förbättrar teamsamarbetet och inlärningen genom att rekommendera optimala sätt för teamroller att arbeta tillsammans. TDSP innehåller metodtips och ramverk från Microsoft och andra branschledare för att hjälpa ditt team att effektivt implementera datavetenskapsinitiativ. Med TDSP kan du fullt ut inse fördelarna med ditt analysprogram.
Den här artikeln innehåller en översikt över TDSP och dess huvudkomponenter. Den innehåller vägledning om hur du implementerar TDSP med hjälp av Microsofts verktyg och infrastruktur. Du hittar mer detaljerade resurser i artikeln.
Viktiga komponenter i TDSP
TDSP har följande nyckelkomponenter:
- Definition av livscykel för datavetenskap
- Standardiserad projektstruktur
- Infrastruktur och resurser som är idealiska för datavetenskapsprojekt
- Ansvarsfull AI: och ett åtagande för att främja AI, som drivs av etiska principer
Livscykel för datavetenskap
TDSP tillhandahåller en livscykel som du kan använda för att strukturera utvecklingen av dina datavetenskapsprojekt. Livscykeln beskriver de fullständiga steg som lyckade projekt följer.
Du kan kombinera aktivitetsbaserad TDSP med andra datavetenskapslivscykler, till exempel branschöverskridande standardprocess för datautvinning (CRISP-DM), kunskapsidentifiering i databaser (KDD) eller en annan anpassad process. På hög nivå har dessa olika metoder mycket gemensamt.
Använd den här livscykeln om du har ett datavetenskapsprojekt som ingår i ett intelligent program. Intelligenta program distribuerar maskininlärning eller AI-modeller för förutsägelseanalys. Du kan också använda den här processen för undersökande datavetenskapsprojekt och improviserade analysprojekt.
TDSP-livscykeln består av fem större steg som ditt team utför iterativt. Dessa steg omfattar:
Här är en visuell representation av TDSP-livscykeln:
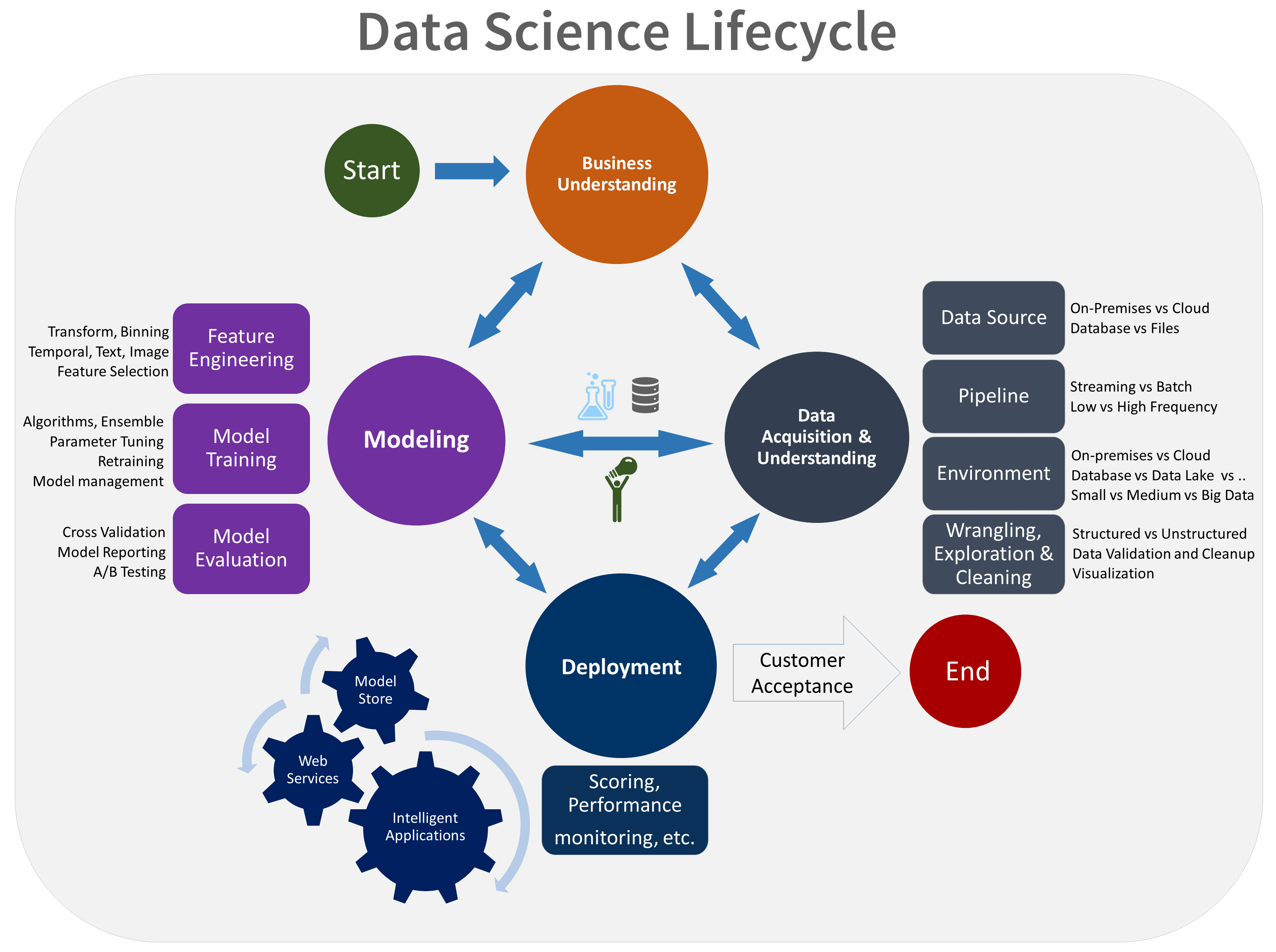
Mer information om mål, uppgifter och dokumentationsartefakter för varje steg finns i TDSP-livscykeln.
Dessa uppgifter och artefakter överensstämmer med projektroller, till exempel:
- Lösningsarkitekt
- Projektledare
- Datatekniker
- Dataexpert
- Programutvecklare
- Projektledare
Följande diagram visar de uppgifter (i blått) och artefakter (i grönt) som motsvarar varje fas i livscykeln som visas på den vågräta axeln och för de roller som visas på den lodräta axeln.

Standardiserad projektstruktur
Ditt team kan använda Azure-infrastrukturen för att organisera dina datavetenskapstillgångar.
Azure Mašinsko učenje stöder MLflow med öppen källkod. Vi rekommenderar att du använder MLflow för datavetenskap och AI-projekthantering. MLflow är utformat för att hantera hela livscykeln för maskininlärning. Den tränar och hanterar modeller på olika plattformar, så att du kan använda en konsekvent uppsättning verktyg oavsett var experimenten körs. Du kan använda MLflow lokalt på datorn, på ett fjärrberäkningsmål, på en virtuell dator eller på en datorinstans för beräkning av maskininlärning.
MLflow består av flera viktiga funktioner:
Spåra experiment: Du kan använda MLflow för att hålla reda på experiment, inklusive parametrar, kodversioner, mått och utdatafiler. Den här funktionen hjälper dig att jämföra olika körningar och effektivt hantera experimenteringsprocessen.
Paketkod: Det ger ett standardiserat format för att paketera maskininlärningskod, som innehåller beroenden och konfigurationer. Den här paketeringen gör det enklare att återskapa körningar och dela kod med andra.
Hantera modeller: MLflow tillhandahåller funktioner för att hantera och versionsmodeller. Den stöder olika maskininlärningsramverk så att du kan lagra, version och hantera modeller.
Hantera och distribuera modeller: MLflow integrerar funktioner för modellservering och distribution så att du enkelt kan distribuera modeller i olika miljöer.
Registrera modeller: Du kan hantera livscykeln för en modell, som omfattar versionshantering, fasövergångar och anteckningar. Du kan använda MLflow för att underhålla ett centraliserat modellarkiv i en samarbetsmiljö.
Använd ett API och användargränssnitt: I Azure paketeras MLflow i Mašinsko učenje API version 2, så att du kan interagera med systemet programmatiskt. Du kan använda Azure-portalen för att interagera med ett användargränssnitt.
MLflow förenklar och standardiserar processen för maskininlärningsutveckling, från experimentering till distribution.
Mašinsko učenje integreras med Git-lagringsplatser så att du kan använda Git-kompatibla tjänster, till exempel GitHub, GitLab, Bitbucket, Azure DevOps eller en annan Git-kompatibel tjänst. Förutom de tillgångar som redan spåras i Mašinsko učenje kan ditt team utveckla sin egen taxonomi i sin Git-kompatibla tjänst för att lagra andra projektdata, till exempel:
- Dokumentation
- Projektdata: till exempel den slutliga projektrapporten
- Datarapport: till exempel dataordlistan eller datakvalitetsrapporter
- Modell: till exempel modellrapporter
- Kod
- Dataförberedelse
- Modellutveckling
- Operationalisering, som omfattar säkerhet och efterlevnad
Infrastruktur och resurser
TDSP ger rekommendationer för hur du hanterar delad analys och lagringsinfrastruktur i följande kategorier:
- Molnfilsystem för att lagra datauppsättningar
- Molndatabaser
- Stordatakluster som använder SQL eller Spark
- AI- och maskininlärningstjänster
Molnfilsystem för att lagra datauppsättningar
Molnfilsystem är avgörande för TDSP av flera skäl:
Centraliserad datalagring: Molnfilsystem ger en central plats för att lagra datauppsättningar, vilket är viktigt för samarbete mellan data science-teammedlemmar. Centralisering säkerställer att alla teammedlemmar kan komma åt de senaste data och minskar risken för att arbeta med inaktuella eller inkonsekventa datauppsättningar.
Skalbarhet: Molnfilsystem kan hantera stora mängder data, vilket är vanligt i datavetenskapsprojekt. Filsystemen tillhandahåller skalbara lagringslösningar som växer med projektets behov. De gör det möjligt för team att lagra och bearbeta massiva datauppsättningar utan att behöva oroa sig för maskinvarubegränsningar.
Hjälpmedel: Med molnfilsystem kan du komma åt data var som helst med en Internetanslutning. Den här åtkomsten är viktig för distribuerade team eller när gruppmedlemmar behöver arbeta på distans. Molnfilsystem underlättar sömlöst samarbete och säkerställer att data alltid är tillgängliga.
Säkerhet och efterlevnad: Molnleverantörer implementerar ofta robusta säkerhetsåtgärder som omfattar kryptering, åtkomstkontroller och efterlevnad av branschstandarder och föreskrifter. Starka säkerhetsåtgärder kan skydda känsliga data och hjälpa ditt team att uppfylla juridiska och regelmässiga krav.
Versionskontroll: Molnfilsystem innehåller ofta funktioner för versionskontroll, som team kan använda för att spåra ändringar i datauppsättningar över tid. Versionskontrollen är avgörande för att upprätthålla dataintegriteten och återskapa resultaten i datavetenskapsprojekt. Det hjälper dig också att granska och felsöka eventuella problem som uppstår.
Integrering med verktyg: Molnfilsystem kan integreras sömlöst med olika datavetenskapsverktyg och plattformar. Verktygsintegrering stöder enklare datainmatning, databearbetning och dataanalys. Azure Storage kan till exempel integreras väl med Mašinsko učenje, Azure Databricks och andra datavetenskapsverktyg.
Samarbete och delning: Molnfilsystem gör det enkelt att dela datauppsättningar med andra teammedlemmar eller intressenter. Dessa system stöder samarbetsfunktioner som delade mappar och behörighetshantering. Samarbetsfunktioner underlättar samarbete och säkerställer att rätt personer har åtkomst till de data de behöver.
Kostnadseffektivitet: Molnfilsystem kan vara mer kostnadseffektiva än att underhålla lokala lagringslösningar. Molnleverantörer har flexibla prismodeller som innehåller alternativ för att betala per användning, vilket kan hjälpa dig att hantera kostnader baserat på de faktiska användnings- och lagringskraven för ditt data science-projekt.
Haveriberedskap: Molnfilsystem innehåller vanligtvis funktioner för säkerhetskopiering av data och haveriberedskap. Dessa funktioner hjälper till att skydda data mot maskinvarufel, oavsiktliga borttagningar och andra katastrofer. Det ger sinnesfrid och stöder kontinuitet i datavetenskapsåtgärder.
Automatisering och arbetsflödesintegrering: Molnlagringssystem kan integreras i automatiserade arbetsflöden, vilket möjliggör sömlös dataöverföring mellan olika faser i datavetenskapsprocessen. Automatisering kan hjälpa till att förbättra effektiviteten och minska det manuella arbete som krävs för att hantera data.
Rekommenderade Azure-resurser för molnfilsystem
- Azure Blob Storage – Omfattande dokumentation om Azure Blob Storage, som är en skalbar objektlagringstjänst för ostrukturerade data.
- Azure Data Lake Storage – Information om Azure Data Lake Storage Gen2, utformad för stordataanalys och har stöd för storskaliga datamängder.
- Azure Files – Information om Azure Files, som tillhandahåller fullständigt hanterade filresurser i molnet.
Sammanfattningsvis är molnfilsystem avgörande för TDSP eftersom de tillhandahåller skalbara, säkra och tillgängliga lagringslösningar som stöder hela datalivscykeln. Molnfilsystem möjliggör sömlös dataintegrering från olika källor, vilket stöder omfattande datainsamling och förståelse. Dataexperter kan använda molnfilsystem för att effektivt lagra, hantera och komma åt stora datamängder. Den här funktionen är viktig för träning och distribution av maskininlärningsmodeller. Dessa system förbättrar också samarbetet genom att göra det möjligt för teammedlemmar att dela och arbeta med data samtidigt i en enhetlig miljö. Molnfilsystem ger robusta säkerhetsfunktioner som hjälper till att skydda data och göra dem kompatibla med regelkrav, vilket är viktigt för att upprätthålla dataintegritet och förtroende.
Molndatabaser
Molndatabaser spelar en viktig roll i TDSP av flera skäl:
Skalbarhet: Molndatabaser tillhandahåller skalbara lösningar som enkelt kan växa för att uppfylla de ökande databehoven i ett projekt. Skalbarhet är avgörande för datavetenskapsprojekt som ofta hanterar stora och invecklade datamängder. Molndatabaser kan hantera varierande arbetsbelastningar utan att behöva utföra manuella åtgärder eller maskinvaruuppgraderingar.
Prestandaoptimering: Utvecklare optimerar molndatabaser för prestanda med hjälp av funktioner som automatisk indexering, frågeoptimering och belastningsutjämning. Dessa funktioner hjälper till att säkerställa att datahämtning och bearbetning är snabba och effektiva, vilket är avgörande för datavetenskapsuppgifter som kräver dataåtkomst i realtid eller nästan i realtid.
Hjälpmedel och samarbete: Teams kan komma åt lagrade data i molndatabaser från valfri plats. Den här tillgängligheten främjar samarbete mellan gruppmedlemmar som kan vara geografiskt spridda. Tillgänglighet och samarbete är viktigt för distribuerade team eller personer som arbetar på distans. Molndatabaser stöder miljöer med flera användare som möjliggör samtidig åtkomst och samarbete.
Integrering med datavetenskapsverktyg: Molndatabaser integreras sömlöst med olika datavetenskapsverktyg och plattformar. Azure-molndatabaser kan till exempel integreras väl med Mašinsko učenje, Power BI och andra dataanalysverktyg. Den här integreringen effektiviserar datapipelinen, från inmatning och lagring till analys och visualisering.
Säkerhet och efterlevnad: Molnleverantörer implementerar robusta säkerhetsåtgärder som omfattar datakryptering, åtkomstkontroller och efterlevnad av branschstandarder och föreskrifter. Säkerhetsåtgärder skyddar känsliga data och hjälper ditt team att uppfylla juridiska och regelmässiga krav. Säkerhetsfunktioner är viktiga för att upprätthålla dataintegritet och sekretess.
Kostnadseffektivitet: Molndatabaser fungerar ofta med en betala per användning-modell, vilket kan vara mer kostnadseffektivt än att underhålla lokala databassystem. Med den här prisflexflexen kan organisationer hantera sina budgetar effektivt och endast betala för de lagrings- och beräkningsresurser som de använder.
Automatiska säkerhetskopieringar och haveriberedskap: Molndatabaser tillhandahåller automatiska lösningar för säkerhetskopiering och haveriberedskap. Dessa lösningar hjälper till att förhindra dataförlust om det uppstår maskinvarufel, oavsiktliga borttagningar eller andra katastrofer. Tillförlitlighet är avgörande för att upprätthålla datakontinuitet och integritet i datavetenskapsprojekt.
Databearbetning i realtid: Många molndatabaser stöder databearbetning och analys i realtid, vilket är viktigt för datavetenskapsuppgifter som kräver den senaste informationen. Den här funktionen hjälper dataexperter att fatta beslut i rätt tid baserat på de senaste tillgängliga data.
Dataintegrering: Molndatabaser kan enkelt integreras med andra datakällor, databaser, datasjöar och externa dataflöden. Integrering hjälper dataexperter att kombinera data från flera källor och ger en omfattande vy och mer avancerad analys.
Flexibilitet och variation: Molndatabaser finns i olika former, till exempel relationsdatabaser, NoSQL-databaser och informationslager. Med den här sorten kan datavetenskapsteam välja den bästa typen av databas för sina specifika behov, oavsett om de behöver strukturerad datalagring, ostrukturerad datahantering eller storskalig dataanalys.
Stöd för avancerad analys: Molndatabaser har ofta inbyggt stöd för avancerad analys och maskininlärning. Azure SQL Database tillhandahåller till exempel inbyggda maskininlärningstjänster. Dessa tjänster hjälper dataexperter att utföra avancerad analys direkt i databasmiljön.
Rekommenderade Azure-resurser för molndatabaser
- Azure SQL Database – Dokumentation om Azure SQL Database, en fullständigt hanterad relationsdatabastjänst.
- Azure Cosmos DB – Information om Azure Cosmos DB, en globalt distribuerad databastjänst med flera modeller.
- Azure Database for PostgreSQL – Guide till Azure Database for PostgreSQL, en hanterad databastjänst för apputveckling och distribution.
- Azure Database for MySQL – information om Azure Database for MySQL, en hanterad tjänst för MySQL-databaser.
Sammanfattningsvis är molndatabaser avgörande för TDSP eftersom de tillhandahåller skalbara, tillförlitliga och effektiva datalagrings- och hanteringslösningar som stöder datadrivna projekt. De underlättar sömlös dataintegrering, vilket hjälper dataexperter att mata in, förbearbeta och analysera stora datamängder från olika källor. Molndatabaser möjliggör snabb frågekörning och databearbetning, vilket är viktigt för att utveckla, testa och distribuera maskininlärningsmodeller. Molndatabaser förbättrar också samarbetet genom att tillhandahålla en centraliserad plattform för teammedlemmar att komma åt och arbeta med data samtidigt. Slutligen tillhandahåller molndatabaser avancerade säkerhetsfunktioner och efterlevnadsstöd för att hålla data skyddade och kompatibla med regelstandarder, vilket är viktigt för att upprätthålla dataintegritet och förtroende.
Stordatakluster som använder SQL eller Spark
Stordatakluster, till exempel de som använder SQL eller Spark, är grundläggande för TDSP av flera skäl:
Hantera stora mängder data: Stordatakluster är utformade för att hantera stora mängder data effektivt. Datavetenskapsprojekt omfattar ofta massiva datamängder som överskrider kapaciteten för traditionella databaser. SQL-baserade stordatakluster och Spark kan hantera och bearbeta dessa data i stor skala.
Distribuerad databehandling: Stordatakluster använder distribuerad databehandling för att sprida data och beräkningsuppgifter över flera noder. Funktionen parallell bearbetning påskyndar databearbetnings- och analysuppgifter avsevärt, vilket är viktigt för att få insikter i tid i datavetenskapsprojekt.
Skalbarhet: Stordatakluster ger hög skalbarhet, både horisontellt genom att lägga till fler noder och lodrätt genom att öka kraften hos befintliga noder. Skalbarhet hjälper till att säkerställa att datainfrastrukturen växer med projektets behov genom att hantera ökande datastorlekar och komplexitet.
Integrering med datavetenskapsverktyg: Stordatakluster integreras väl med olika datavetenskapsverktyg och plattformar. Spark integreras till exempel sömlöst med Hadoop och SQL-kluster fungerar med olika dataanalysverktyg. Integrering underlättar ett smidigt arbetsflöde från datainmatning till analys och visualisering.
Avancerad analys: Stordatakluster stöder avancerad analys och maskininlärning. Spark tillhandahåller till exempel följande inbyggda bibliotek:
- Maskininlärning, MLlib
- Grafbearbetning, GraphX
- Dataströmbearbetning, Spark Streaming
Dessa funktioner hjälper dataexperter att utföra komplexa analyser direkt i klustret.
Databearbetning i realtid: Stordatakluster, särskilt de som använder Spark, stöder databearbetning i realtid. Den här funktionen är avgörande för projekt som kräver dataanalys och beslutsfattande upp till minuten. Realtidsbearbetning hjälper till i scenarier som bedrägeriidentifiering, realtidsrekommendationer och dynamisk prissättning.
Datatransformering och extrahering, transformering, inläsning (ETL): Stordatakluster är idealiska för datatransformering och ETL-processer. De kan effektivt hantera komplexa datatransformeringar, rensnings- och aggregeringsuppgifter, vilket ofta är nödvändigt innan data kan analyseras.
Kostnadseffektivitet: Stordatakluster kan vara kostnadseffektiva, särskilt när du använder molnbaserade lösningar som Azure Databricks och andra molntjänster. Dessa tjänster tillhandahåller flexibla prismodeller som inkluderar betala per användning, vilket kan vara mer ekonomiskt än att underhålla lokal stordatainfrastruktur.
Feltolerans: Stordatakluster är utformade med feltolerans i åtanke. De replikerar data mellan noder för att säkerställa att systemet förblir i drift även om vissa noder misslyckas. Den här tillförlitligheten är viktig för att upprätthålla dataintegritet och tillgänglighet i datavetenskapsprojekt.
Data lake-integrering: Stordatakluster integreras ofta sömlöst med datasjöar, vilket gör det möjligt för dataforskare att komma åt och analysera olika datakällor på ett enhetligt sätt. Integrering främjar mer omfattande analyser genom att stödja en kombination av strukturerade och ostrukturerade data.
SQL-baserad bearbetning: För dataexperter som är bekanta med SQL tillhandahåller stordatakluster som fungerar med SQL-frågor, till exempel Spark SQL eller SQL på Hadoop, ett välbekant gränssnitt för att fråga och analysera stordata. Den här användarvänligheten kan påskynda analysprocessen och göra den mer tillgänglig för ett bredare spektrum av användare.
Samarbete och delning: Stordatakluster stöder samarbetsmiljöer där flera dataforskare och analytiker kan arbeta tillsammans med samma datauppsättningar. De tillhandahåller funktioner för att dela kod, notebook-filer och resultat som främjar teamarbete och kunskapsdelning.
Säkerhet och efterlevnad: Stordatakluster ger robusta säkerhetsfunktioner, till exempel datakryptering, åtkomstkontroller och efterlevnad av branschstandarder. Säkerhetsfunktionerna skyddar känsliga data och hjälper ditt team att uppfylla regelkraven.
Rekommenderade Azure-resurser för stordatakluster
- Apache Spark i Mašinsko učenje: Mašinsko učenje integrering med Azure Synapse Analytics ger enkel åtkomst till distribuerade beräkningsresurser via Apache Spark-ramverket.
- Azure Synapse Analytics: Omfattande dokumentation för Azure Synapse Analytics, som integrerar stordata och informationslager.
Sammanfattningsvis är stordatakluster, oavsett om de är SQL eller Spark, avgörande för TDSP eftersom de ger den beräkningskraft och skalbarhet som krävs för att effektivt hantera stora mängder data. Stordatakluster gör det möjligt för dataforskare att utföra komplexa frågor och avancerad analys på stora datamängder som underlättar djupinsikter och korrekt modellutveckling. När du använder distribuerad databehandling möjliggör dessa kluster snabb databearbetning och analys, vilket påskyndar det övergripande arbetsflödet för datavetenskap. Stordatakluster stöder även sömlös integrering med olika datakällor och verktyg, vilket förbättrar möjligheten att mata in, bearbeta och analysera data från flera miljöer. Stordatakluster främjar också samarbete och reproducerbarhet genom att tillhandahålla en enhetlig plattform där team effektivt kan dela resurser, arbetsflöden och resultat.
AI- och maskininlärningstjänster
AI- och maskininlärningstjänster (ML) är integrerade i TDSP av flera skäl:
Avancerad analys: AI- och ML-tjänster möjliggör avancerad analys. Dataexperter kan använda avancerad analys för att upptäcka komplexa mönster, göra förutsägelser och generera insikter som inte är möjliga med traditionella analysmetoder. Dessa avancerade funktioner är avgörande för att skapa datavetenskapslösningar med hög effekt.
Automatisering av repetitiva uppgifter: AI- och ML-tjänster kan automatisera repetitiva uppgifter, till exempel datarensning, funktionsutveckling och modellträning. Automation sparar tid och hjälper dataexperter att fokusera på mer strategiska aspekter av projektet, vilket förbättrar den totala produktiviteten.
Förbättrad noggrannhet och prestanda: ML-modeller kan förbättra precisionen och prestandan för förutsägelser och analyser genom att lära sig från data. Dessa modeller kan förbättras kontinuerligt när de exponeras för mer data, vilket leder till bättre beslutsfattande och mer tillförlitliga resultat.
Skalbarhet: AI- och ML-tjänster som tillhandahålls av molnplattformar, till exempel Mašinsko učenje, är mycket skalbara. De kan hantera stora mängder data och komplexa beräkningar, vilket hjälper datavetenskapsteam att skala sina lösningar för att möta växande krav utan att behöva oroa sig för underliggande infrastrukturbegränsningar.
Integrering med andra verktyg: AI- och ML-tjänster integreras sömlöst med andra verktyg och tjänster i Microsofts ekosystem, till exempel Azure Data Lake, Azure Databricks och Power BI. Integrering stöder ett effektiviserat arbetsflöde från datainmatning och bearbetning till modelldistribution och visualisering.
Modelldistribution och hantering: AI- och ML-tjänster tillhandahåller robusta verktyg för att distribuera och hantera maskininlärningsmodeller i produktion. Funktioner som versionskontroll, övervakning och automatiserad omträning hjälper till att säkerställa att modellerna förblir korrekta och effektiva över tid. Den här metoden förenklar underhållet av ML-lösningar.
Realtidsbearbetning: AI- och ML-tjänster stöder databearbetning och beslutsfattande i realtid. Realtidsbearbetning är viktigt för program som kräver omedelbara insikter och åtgärder, till exempel identifiering av bedrägerier, dynamisk prissättning och rekommendationssystem.
Anpassningsbarhet och flexibilitet: AI- och ML-tjänster erbjuder en rad anpassningsbara alternativ, från fördefinierade modeller och API:er till ramverk för att skapa anpassade modeller från grunden. Den här flexibiliteten hjälper datavetenskapsteam att skräddarsy lösningar efter specifika affärsbehov och användningsfall.
Åtkomst till banbrytande algoritmer: AI- och ML-tjänster ger dataforskare tillgång till banbrytande algoritmer och tekniker som utvecklats av ledande forskare. Åtkomst säkerställer att teamet kan använda de senaste framstegen inom AI och ML för sina projekt.
Samarbete och delning: AI- och ML-plattformar stöder samarbetsutvecklingsmiljöer, där flera teammedlemmar kan samarbeta i samma projekt, dela kod och återskapa experiment. Samarbete förbättrar teamarbetet och bidrar till att säkerställa konsekvens i modellutveckling.
Kostnadseffektivitet: AI- och ML-tjänster i molnet kan vara mer kostnadseffektiva än att skapa och underhålla lokala lösningar. Molnleverantörer har flexibla prismodeller som innehåller alternativ för att betala per användning, vilket kan minska kostnaderna och optimera resursanvändningen.
Förbättrad säkerhet och efterlevnad: AI- och ML-tjänster har robusta säkerhetsfunktioner som omfattar datakryptering, säkra åtkomstkontroller och efterlevnad av branschstandarder och föreskrifter. De här funktionerna hjälper dig att skydda dina data och modeller och uppfylla juridiska och regelmässiga krav.
Fördefinierade modeller och API:er: Många AI- och ML-tjänster tillhandahåller fördefinierade modeller och API:er för vanliga uppgifter som bearbetning av naturligt språk, bildigenkänning och avvikelseidentifiering. De fördefinierade lösningarna kan påskynda utvecklingen och distributionen och hjälpa teamen att snabbt integrera AI-funktioner i sina program.
Experimentering och prototyper: AI- och ML-plattformar tillhandahåller miljöer för snabba experiment och prototyper. Dataexperter kan snabbt testa olika algoritmer, parametrar och datauppsättningar för att hitta den bästa lösningen. Experimentering och prototyper stöder en iterativ metod för modellutveckling.
Rekommenderade Azure-resurser för AI- och ML-tjänster
Mašinsko učenje är den viktigaste resursen som vi rekommenderar för data science-programmet och TDSP. Dessutom tillhandahåller Azure AI-tjänster som har färdiga AI-modeller för specifika program.
- Mašinsko učenje: Huvuddokumentationssidan för Mašinsko učenje som omfattar installation, modellträning, distribution och så vidare.
- Azure AI-tjänster: Information om AI-tjänster som tillhandahåller fördefinierade AI-modeller för visions-, tal-, språk- och beslutsuppgifter.
Sammanfattningsvis är AI- och ML-tjänster avgörande för TDSP eftersom de tillhandahåller kraftfulla verktyg och ramverk som effektiviserar utveckling, utbildning och distribution av maskininlärningsmodeller. Dessa tjänster automatiserar komplexa uppgifter, till exempel algoritmval och justering av hyperparametrar, vilket avsevärt påskyndar modellutvecklingsprocessen. Dessa tjänster tillhandahåller också skalbar infrastruktur som hjälper dataexperter att effektivt hantera stora datamängder och beräkningsintensiva uppgifter. AI- och ML-verktyg integreras sömlöst med andra Azure-tjänster och förbättrar datainmatning, förbearbetning och modelldistribution. Integreringen säkerställer ett smidigt arbetsflöde från slutpunkt till slutpunkt. Dessa tjänster främjar också samarbete och reproducerbarhet. Team kan dela insikter och effektivt experimentera med resultat och modeller samtidigt som de upprätthåller höga standarder för säkerhet och efterlevnad.
Ansvarsfull AI
Med AI- eller ML-lösningar främjar Microsoft ansvarsfulla AI-verktyg inom sina AI- och ML-lösningar. Dessa verktyg stöder Microsoft Responsible AI Standard. Din arbetsbelastning måste fortfarande individuellt hantera AI-relaterade skador.
Peer-granskade citat
TDSP är en väletablerad metod som team använder i Microsoft-åtaganden. TDSP dokumenteras och studeras i peer-granskad litteratur. Citaten ger en möjlighet att undersöka TDSP-funktioner och -program. Mer information och en lista över citat finns i TDSP-livscykeln.