CQRS står för Kommando- och Frågeansvarsfördelning, ett mönster som separerar läs- och uppdateringsåtgärder för ett datalager. Implementering av CQRS i ditt program kan maximera dess prestanda, skalbarhet och säkerhet. Flexibiliteten som skapas genom migrering till CQRS gör att ett system kan utvecklas bättre över tid och förhindrar att uppdateringskommandon orsakar sammanslagningskonflikter på domännivå.
Kontext och problem
I traditionella arkitekturer används samma datamodell för att fråga och uppdatera en databas. Det är enkelt och fungerar bra för grundläggande CRUD-åtgärder. I mer avancerade tillämpningar kan den här metoden däremot bli svårhanterlig. Vid skrivåtgärder kan tillämpningen till exempel utföra många olika frågor och returnera dataöverföringsobjekt (DTO) med olika former. Objektmappningen kan bli komplicerad. Vid skrivåtgärder kan modellen implementera komplex validerings- och affärslogik. Resultatet kan bli en överdrivet komplex modell med överflödig kapacitet.
Läs- och skrivarbetsbelastningar är ofta asymmetriska, med mycket olika prestanda- och skalningskrav.
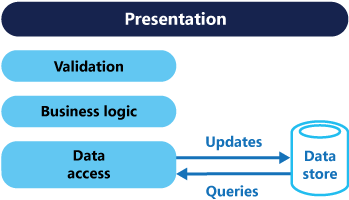
Det finns ofta ett matchningsfel mellan läs- och skrivrepresentationerna av data, till exempel ytterligare kolumner eller egenskaper som måste uppdateras korrekt även om de inte krävs som en del av en åtgärd.
Datakonkurration kan uppstå när åtgärder utförs parallellt på samma uppsättning data.
Den traditionella metoden kan ha en negativ inverkan på prestanda på grund av belastningen på datalagret och dataåtkomstskiktet och komplexiteten i frågor som krävs för att hämta information.
Att hantera säkerhet och behörigheter kan bli komplext eftersom varje entitet omfattas av både läs- och skrivåtgärder, vilket kan exponera data i fel kontext.
Lösning
CQRS separerar läsningar och skrivningar i olika modeller med hjälp av kommandon för att uppdatera data och frågor för att läsa data.
- Kommandon ska vara aktivitetsbaserade snarare än datacentrerade. ("Boka hotellrum", inte "set ReservationStatus to Reserved"). Detta kan kräva vissa motsvarande ändringar i användarinteraktionsstilen. Den andra delen av det är att titta på hur du ändrar affärslogiken som bearbetar dessa kommandon så att de lyckas oftare. En teknik som stöder detta är att köra vissa valideringsregler på klienten även innan du skickar kommandot, eventuellt inaktivera knappar, vilket förklarar varför i användargränssnittet ("inga rum kvar"). På så sätt kan orsaken till kommandofel på serversidan begränsas till konkurrensförhållanden (två användare försöker boka det sista rummet), och även de kan ibland åtgärdas med lite mer data och logik (att placera en gäst på en väntelista).
- Kommandon kan placeras i en kö för asynkron bearbetning i stället för att bearbetas synkront.
- Frågor kan aldrig ändra databasen. En fråga returnerar ett DTO som inte kapslar in någon domäninformation.
Modellerna kan sedan isoleras, vilket visas i följande diagram, även om det inte är ett absolut krav.
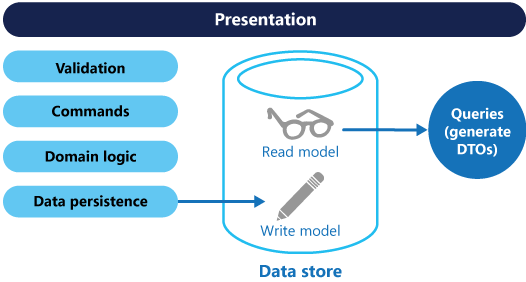
Att ha separata fråge- och uppdateringsmodeller förenklar designen och implementeringen. En nackdel är dock att CQRS-kod inte automatiskt kan genereras från ett databasschema med hjälp av scaffolding-mekanismer som O/RM-verktyg (du kommer dock att kunna skapa din anpassning ovanpå den genererade koden).
För bättre isolering kan du avgränsa läsdata fysiskt från skrivdata. På så sätt kan läsdatabasen använda ett eget dataschema som är optimerat för frågor. Den kan till exempel lagra en materialiserad vy av data för att undvika komplexa kopplingar eller komplexa O/RM-mappningar. Den kan till och med använda en annan typ av datalagring. Till exempel kanske skrivdatabasen är relationell, medan läsdatabasen är en dokumentdatabas.
Om separata läs- och skrivdatabaser används måste de hållas synkroniserade. Detta sker vanligtvis genom att skrivmodellen publicerar en händelse när den uppdaterar databasen. Mer information om hur du använder händelser finns i Händelsedriven arkitekturstil. Eftersom meddelandeköer och databaser vanligtvis inte kan registreras i en enda distribuerad transaktion kan det finnas utmaningar när det gäller att garantera konsekvens vid uppdatering av databasen och publiceringshändelser. Mer information finns i vägledningen om idempotent meddelandebearbetning.
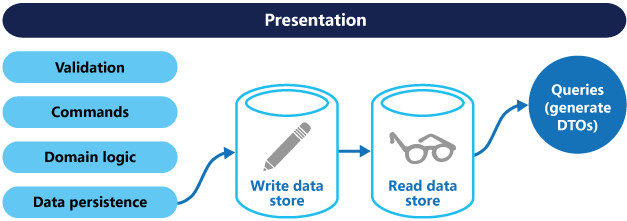
Lagringsplatsen för läsning kan vara en skrivskyddad replik av arkivet för skrivning. Lagringsplatserna för läsning och skrivning kan också ha helt olika struktur. Om du använder flera skrivskyddade repliker kan du öka frågeprestandan, särskilt i distribuerade scenarier där skrivskyddade repliker finns nära programinstanserna.
Uppdelning av lagringsplatserna för läsning och skrivning gör också att de var för sig kan skalas på lämpligt sätt för att matcha belastningen. Till exempel har lagringsplatser för läsning vanligtvis en mycket högre belastning än lagringsplatser för skrivning.
Med vissa implementeringar av CQRS används mönstret för händelsekällor. Med det här mönstret lagras tillämpningstillståndet som en händelsesekvens. Varje händelse representerar en uppsättning ändringar av data. Det aktuella tillståndet skapas genom att händelserna spelas upp igen. I en CQRS-kontext är en fördel med händelsekällor att samma händelser kan användas för att meddela andra komponenter – särskilt för att meddela läsmodellen. Läsmodellen använder händelserna för att skapa en ögonblicksbild av det aktuella tillståndet, vilket är mer effektivt för frågor. Händelsekällor gör dock designen mer komplex.
Fördelarna med CQRS är:
- Oberoende skalning. Med CQRS kan arbetsbelastningar för läs- och skrivåtgärder skalas oberoende av varandra, och därmed ge färre låsningstvister.
- Optimerade datascheman. Lässidan kan använda ett schema som är optimerat för frågor, medan skrivsidan använder ett schema som är optimerat för uppdateringar.
- Säkerhet. Det är enklare att se till att bara de rätta domänentiteterna utför skrivåtgärder på data.
- Separering av problem. Att segregera delarna för läs- och skrivåtgärder kan resultera i mer hanterbara och flexibla modeller. Merparten av den komplexa affärslogiken hamnar i skrivmodellen. Läsmodellen kan vara förhållandevis enkel.
- Enklare frågor. Genom att lagra en materialiserad vy i läsdatabasen kan tillämpningen undvika komplexa kopplingar vid frågor.
Implementeringsproblem och överväganden
Några utmaningar med att implementera det här mönstret är:
Komplexitet. Grundtanken med CQRS är enkel. Samtidigt kan den ge upphov till en mer komplex programdesign, i synnerhet om mönstret för händelsekällor tillämpas.
Meddelandetjänster. CQRS kräver inga meddelandetjänster, men det är ändå vanligt att använda meddelanden för att bearbeta kommandon och publicera uppdateringshändelser. Då måste tillämpningen kunna hantera fel i meddelanden eller dubbletter av meddelanden. Se vägledningen om prioritetsköer för att hantera kommandon som har olika prioriteter.
Eventuell konsekvens. Om du separerar databaserna för läs- och skrivåtgärder finns risken att läsdata blir inaktuella. Läsmodelllagret måste uppdateras för att återspegla ändringar i skrivmodellarkivet, och det kan vara svårt att identifiera när en användare har utfärdat en begäran baserat på inaktuella läsdata.
När du ska använda CQRS-mönster
Överväg CQRS för följande scenarier:
Samarbetsdomäner där många användare har åtkomst till samma data parallellt. Med CQRS kan du definiera kommandon med tillräckligt detaljerad information för att minimera sammanslagningskonflikter på domännivå, och konflikter som uppstår kan sammanfogas av kommandot.
Uppgiftsbaserade användargränssnitt, där användare vägleds genom en komplicerad process med en serie steg, eller med komplexa domänmodeller. Skrivmodellen har en fullständig kommandobearbetningsstack med affärslogik, indataverifiering och affärsverifiering. Skrivmodellen kan behandla en uppsättning associerade objekt som en enda enhet för dataändringar (en aggregering, i DDD-terminologi) och se till att dessa objekt alltid är i ett konsekvent tillstånd. Läsmodellen har ingen affärslogik eller valideringsstack och returnerar bara en DTO för användning i en vymodell. Läsningsmodellen är i slutlig överensstämmelse med skrivningsmodellen.
Scenarier där prestanda för dataläsningar måste finjusteras separat från prestanda för dataskrivningar, särskilt när antalet läsningar är mycket större än antalet skrivningar. I det här scenariot kan du skala ut läsmodellen, men köra skrivmodellen på bara några få instanser. Ett litet antal skrivningsmodellinstanser hjälper också till att minimera förekomsten av sammanslagningskonflikter.
Scenarier där ett team med utvecklare kan fokusera på den komplexa domänmodell som är en del av skrivningsmodellen och ett annat team kan fokusera på läsningsmodellen och användargränssnitten.
Scenarier där systemet förväntas utvecklas över tid och kan innehålla flera versioner av modellen, eller där affärsregler ändras regelbundet.
Integrering med andra system, särskilt i kombination med händelsekällor där ett tillfälligt fel i ett undersystem inte ska påverka tillgängligheten för de andra.
Det här mönstret rekommenderas inte när:
Domänen eller affärsreglerna är enkla.
Det räcker med ett enkelt CRUD-gränssnitt och dataåtkomståtgärder.
Överväg att använda CQRS i avgränsade sektorer av systemet där det är mest värdefullt.
Design av arbetsbelastning
En arkitekt bör utvärdera hur CQRS-mönstret kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Prestandaeffektivitet hjälper din arbetsbelastning att effektivt uppfylla kraven genom optimeringar inom skalning, data och kod. | Separationen av läs- och skrivåtgärder i hög läs-till-skriv-arbetsbelastningar möjliggör riktade prestanda- och skaloptimeringar för varje åtgärds specifika syfte. - PE:05 Skalning och partitionering - PE:08 Dataprestanda |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Händelsekällor och CQRS-mönster
CQRS-mönstret används ofta tillsammans med mönstret Händelsekälla. CQRS-baserade system använder separata läsnings- och skrivningsdatamodeller, som var och en är anpassad till relevanta uppgifter och ofta finns i fysiskt separata lagringsplatser. När den används med mönster Händelsekälla är händelsernas lagringsplats skrivningsmodellen, och detta är den officiella källan för information. Läsningsmodell för ett CQRS-baserat system ger vanligtvis materialiserade vyer av data, oftast som höggradigt avnormaliserade vyer. Dessa vyer skräddarsys för gränssnitten och visa kraven för programmet. vilket hjälper dig att maximera både visnings- och frågeprestanda.
Genom att dataströmmen av händelser används som lagerplats för skrivåtgärder, i stället för faktiska data vid en specifik tidpunkt, undviks uppdateringskonflikter på en enskild samling samtidigt som prestanda och skalbarhet maximeras. Händelserna kan användas för att asynkront generera materialiserade vyer av de data som används för att fylla i lagringsplatsen för läsning.
Eftersom lagringsplatsen för händelser är den officiella informationskällan, är det möjligt att ta bort de materialiserade vyerna och spela upp alla tidigare händelser för att skapa en ny representation av det aktuella tillståndet när systemet utvecklas, eller när läsningsmodellen måste ändras. De materialiserade vyerna är i praktiken en beständig skrivskyddad cache av data.
När CQRS används i kombination med mönstret Händelsekälla ska du tänka på följande:
Precis som med alla system där lagringsplatserna för skriv- och läsåtgärder är åtskilda, är system som baseras på det här mönstret bara slutligt överensstämmande. Det kommer att finnas en fördröjning mellan att händelsen genereras och att datalagret uppdateras.
Mönstret lägger till komplexitet eftersom kod måste skapas för att initiera och hantera händelser, och för att samla ihop eller uppdatera lämpliga vyer eller objekt som krävs av frågor eller en läsningsmodell. Komplexiteten i CQRS mönstret när det används med mönstret Händelsekälla kan försvåra en lyckad implementering och kräver en annan metod för att utforma system. Dock kan händelsekällor göra det enklare att modellera domänen, och de gör det enklare att återskapa vyer eller skapa nya eftersom syftet med ändringar i data bevaras.
Att generera materialiserade vyer för användning i läsningsmodellen eller projektioner av data genom att spela upp och hantera händelserna för specifika entiteter eller mängder av entiteter kan kräva betydande bearbetningstid och resursanvändning. Detta gäller särskilt om det krävs summering eller analys av värden över långa perioder, eftersom de associerade händelserna kan behöva undersökas. Lös detta genom att implementera ögonblicksbilder av data med schemalagda intervall, till exempel ett totalt antal av antalet specifika åtgärder som har inträffat eller aktuellt tillstånd för en entitet.
Exempel på CQRS-mönster
Följande kod visar vissa utdrag ur ett exempel på en CQRS-implementation som använder olika definitioner för läsnings- och skrivningsmodeller. Modellgränssnitten kräver inte några speciella funktioner i underliggande datalagringsplatser, och de kan utvecklas och finjusteras oberoende eftersom dessa gränssnitt är åtskilda.
Följande kod visar läsningsmodellens definition.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
Systemet tillåter användare att betygsätta produkter. Programkoden gör detta med hjälp av kommandot RateProduct som visas i följande kod.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
Systemet använder klassen ProductsCommandHandler för att hantera kommandon som skickas av programmet. Klienter skickar vanligtvis kommandon till domänen via ett meddelandesystem, till exempel en kö. Kommandohanteraren accepterar dessa kommandon och anropar metoder i domängränssnittet. Granulariteten för varje kommando har utformats för att minska risken för begäranden som står i konflikt. Följande kod visar en översikt över klassen ProductsCommandHandler.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
Nästa steg
Följande mönster och riktlinjer kan vara relevanta när du implementerar det här mönstret:
Datakonsekvensprimer. Beskriver de problem som vanligtvis inträffar på grund av den slutliga konsekvensen mellan datalagringen för läsning och skrivning när du använder CQRS-mönstret och hur de här problemen kan lösas.
Horisontell, lodrät och funktionell datapartitionering. Beskriver metodtips för att dela upp data i partitioner som kan hanteras och nås separat för att förbättra skalbarheten, minska konkurrensen och optimera prestanda.
Mönster och praxis vägleder CQRS-resan. I synnerhet utforskar introduktionen av mönstret ansvarsfördelning för kommandofrågor mönstret och när det är användbart, och Epilog: Lessons Learned hjälper dig att förstå några av de problem som uppstår när du använder det här mönstret.
Martin Fowlers blogginlägg:
Relaterade resurser
Mönstret Händelsekällor. Beskrivs i detalj hur Händelsekällor kan användas med CQRS-mönster för att förenkla uppgifter i komplexa domäner och samtidigt förbättra prestanda, skalbarhet och svarstider. Samt hur du tillhandahåller konsekvens för transaktionsdata och samtidigt bibehåller fullständig granskningshistorik och historik som kan möjliggöra kompenserande åtgärder.
Mönster för materialiserad vy. Läsningsmodellen i en CQRS-implementering kan innehålla materialiserade vyer av skrivningsmodelldata, eller läsningsmodellen kan användas för att skapa materialiserade vyer.
Presentation om bättre CQRS via asynkrona användarinteraktionsmönster