Dela upp ett datalager i en uppsättning horisontella partitioner eller delar. Detta kan förbättra skalbarheten vid lagring och hämtning av stora datavolymer.
Kontext och problem
Ett datalager med en enda server som värd kan uppleva följande begränsningar:
Lagringsutrymme. Ett datalager för ett storskaligt molnprogram förväntas kunna innehålla en enorm datavolym som kan öka avsevärt med tiden. En server tillhandahåller normalt endast en begränsad mängd disklagring, men du kan byta ut befintliga diskar mot större eller lägga till ytterligare diskar i datorn vartefter datavolymerna växer. Systemet når dock till slut en gräns där det inte går att öka lagringskapaciteten på en viss server på ett enkelt sätt.
Bearbetningsresurser. Ett molnprogram krävs för att ge stöd åt ett stort antal samtidiga användare, där var och en kan köra frågor som hämtar information från datalagret. En enskild server som är värd för datalagret kanske inte kan tillhandahålla den databehandlingskraft som krävs för den här belastningen, vilket resulterar i längre svarstider för användare och frekventa fel när program som försöker lagra och hämta data överskrider tidsgränsen. Det kan vara möjligt att lägga till minnes- eller uppgraderingsprocessorer, men systemet når en gräns när det inte går att öka beräkningsresurserna ytterligare.
Nätverksbandbredd. Slutligen styrs prestanda för ett datalager som körs på en enda server av den hastighet med vilken servern kan ta emot begäranden och skicka svar. Det kan hända att nätverkstrafikens volym överskrider kapaciteten hos det nätverk som används för att ansluta till servern, vilket leder till misslyckade begäranden.
Geografi. Det kan vara nödvändigt att lagra data som genereras av specifika användare i samma region som de användarna av juridik-, efterlevnads- eller prestandaskäl, eller för att sänka svarstiden för dataåtkomst. Om användarna är utspridda över olika länder eller regioner kan det hända att det inte går att lagra hela datavolymen för programmet i ett enda datalager.
Vertikal skalning genom att lägga till mer diskkapacitet, bearbetningskraft, minne och nätverksanslutningar kan skjuta upp effekterna av några av dessa begränsningar, men det är troligtvis endast en tillfällig lösning. Ett kommersiellt molnprogram som kan ge stöd för ett stort antal användare och höga datavolymer måste kunna skalas nästan oändligt, så vertikal skalning är inte nödvändigtvis den bästa lösningen.
Lösning
Dela upp datalagret i horisontella partitioner eller shards. Varje shard har samma schema, men det innehåller en avskild delmängd av data. En shard är ett datalager på egen hand (den kan innehålla data för många entiteter av olika typer) och körs på en server som fungerar som en lagringsnod.
Det här mönstret har följande fördelar:
Du kan skala ut systemet genom att lägga till fler shards som körs på ytterligare lagringsnoder.
Ett system kan använda standardmaskinvara i stället för särskilda och dyra datorer för varje lagringsnod.
Du kan minska konkurrensen och förbättra prestanda genom att balansera arbetsbelastningen över shards.
I molnet kan shards ligga fysiskt nära de användare som ska komma åt data.
När du delar upp ett datalager i shards måste du avgöra vilka data som ska placeras i varje shard. En shard innehåller normalt objekt som ligger inom ett visst omfång som avgörs av ett eller flera attribut i data. Dessa attribut utgör shardnyckeln (kallas ibland partitionsnyckeln). Shardnyckeln ska vara statisk. Den får inte vara baserad på data som kan ändras.
Horisontell partitionering organiserar data fysiskt. När ett program lagrar och hämtar data dirigerar den horisontella partitioneringen programmet till lämplig shard. Den här logiken för horisontell partitionering kan implementeras som en del av dataåtkomstkoden i programmet, eller så kan den implementeras av datalagringssystemet om det har transparent stöd för horisontell partitionering.
Genom att abstrahera den fysiska platsen för data i logiken för horisontell partitionering går det att uppnå en hög styrningsnivå över vilka shards som innehåller vilka data. Det gör det också möjligt att migrera data mellan shards utan att göra om affärslogiken i ett program om data i shards behöver distribueras om senare (till exempel om shards blir obalanserade). Nackdelen är den ytterligare prestanda för dataåtkomst som krävs när platsen för varje dataobjekt fastställs när det hämtas.
Det är viktigt att dela upp data på ett sätt som är lämpligt för de typer av frågor som programmet kör om man vill uppnå bästa prestanda och skalbarhet. I många fall är det osannolikt att schemat för horisontell partitionering exakt överensstämmer med kraven för varje fråga. I ett system med flera klienter kan ett program till exempel behöva hämta klientdata med hjälp av klientorganisations-ID:t, men det kan också behöva söka efter dessa data baserat på något annat attribut, till exempel klientens namn eller plats. För att hantera dessa strategier kan man implementera en strategi för horisontell partitionering med en shardnyckel som har stöd för de frågor som körs oftast.
Om frågorna ofta hämtar data med en kombination av attributvärden kan du antagligen definiera en shardnyckel genom att länka samman attribut. Du kan även använda ett mönster som Indextabell för att ge snabb sökning av data baserat på attribut som inte täcks av shardnyckeln.
Strategier för horisontell partitionering
Tre strategier används ofta vid val av shardnyckel och hur data ska distribueras över shards. Observera att det inte behöver finnas en en-till-en-korrespondens mellan shards och servrarna som är värdar för dem – en enskild server kan vara värd för flera shards. Strategierna är:
Sökningsstrategin. I den här strategin implementerar logiken för horisontell partitionering en karta som dirigerar en databegäran till den shard som innehåller dessa data med hjälp av shardnyckeln. I ett program med flera klienter kan alla data för en klientorganisation lagras tillsammans i en shard med hjälp av klientorganisations-ID:t som shardnyckel. Flera klienter kan dela samma shard, men data för en enda klient sprids inte över flera shards. Bilden visar horisontell partitionering av klientdata baserat på klient-ID:n.
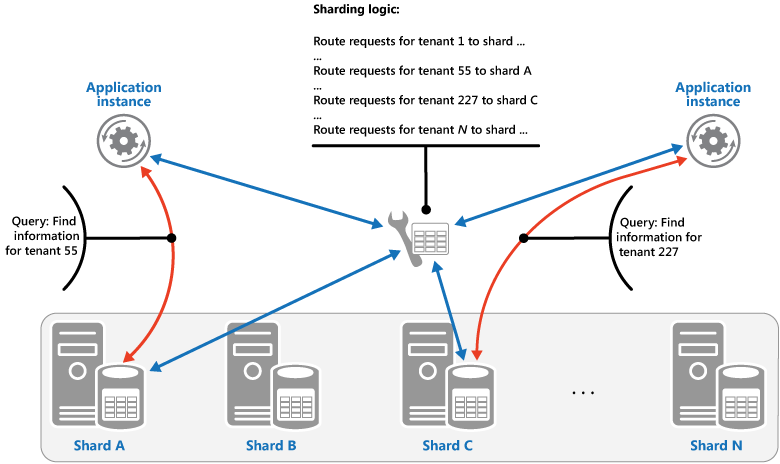
Mappningen mellan shardnyckelvärdet och den fysiska lagring som data finns på kan baseras på fysiska shards där varje shardnyckelvärde mappar till en fysisk partition. Alternativt är en mer flexibel teknik för ombalansering av shards virtuell partitionering, där värden för shardnycklar mappas till samma antal virtuella shards, vilket i sin tur mappar till färre fysiska partitioner. I den här metoden letar ett program upp data med hjälp av ett shardnyckelvärde som refererar till en virtuell shard, och systemet mappar transparent virtuella shards till fysiska partitioner. Mappningen mellan en virtuell shard och en fysisk partition kan ändras utan att programkoden behöver ändras för att använda en annan uppsättning shardnyckelvärden.
Omfångsstrategin. Den här strategin grupperar relaterade objekt i samma fragment och beställer dem efter shardnyckel – shardnycklarna är sekventiella. Det här är praktiskt vid program som ofta hämtar objektuppsättningar med hjälp av omfångsfrågor (frågor som returnerar en uppsättning med dataobjekt för en shardnyckel som ligger inom ett visst omfång). Till exempel om ett program regelbundet behöver hitta alla beställningar som har gjorts under en viss månad går det att hämta dessa data snabbare om alla beställningar för en månad lagras i datum- och tidsordning i samma shard. Om varje beställning hade lagrats i olika shards hade det varit nödvändigt att hämta dem enskilt genom att utföra ett stort antal punktfrågor (frågor som returnerar ett enda dataobjekt). Nästa bild visar lagring av sekventiella uppsättningar (omfång) med data i en shard.
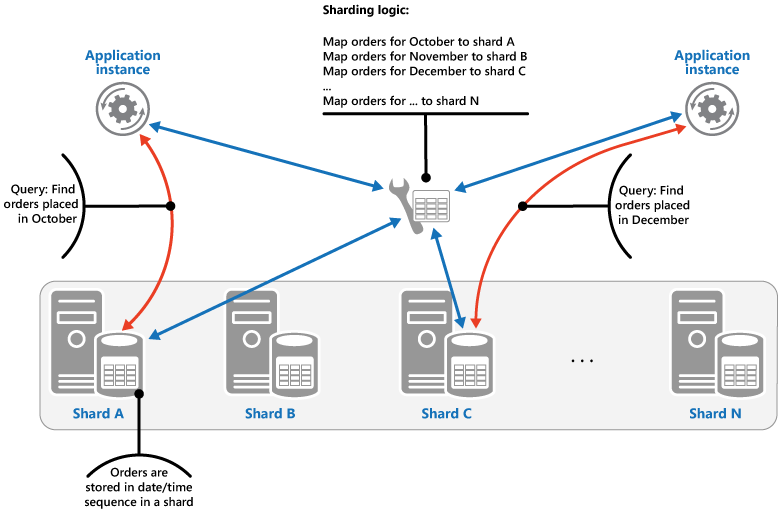
I det här exemplet är shardnyckeln en sammansatt nyckel som innehåller beställningsmånaden som det viktigaste elementet, följt av dag och tid för beställningen. Data för beställningar sorteras naturligt när nya beställningar skapas och läggs till i en shard. Vissa datalager har stöd för tvådelade shardnycklar som innehåller ett partitionsnyckelelement som identifierar sharden och en radnyckel som identifierar ett objekt i sharden unikt. Data lagras vanligtvis i radnyckelordning i sharden. Objekt som omfattas av omfångsfrågor och behöver grupperas tillsammans kan använda en shardnyckel som har samma värde för partitionsnyckeln men ett unikt värde för radnyckeln.
Hash-strategin. Syftet med den här strategin är att minska risken för hotspots (shards som tar emot oproportionerligt hög belastning). Den fördelar data över shards på ett sätt som uppnår en balans mellan storleken på varje shard och den genomsnittliga belastning som varje shard möter. Logiken för horisontell partitionering beräknar den shard som ett objekt ska lagras i baserat på en hash för ett eller flera attribut i data. Den valda hash-funktionen ska fördela data jämnt över shards, eventuellt genom att införa ett slumpmässigt element i beräkningen. Nästa bild visar horisontell partitionering av klientdata baserat på hash för klient-ID:n.
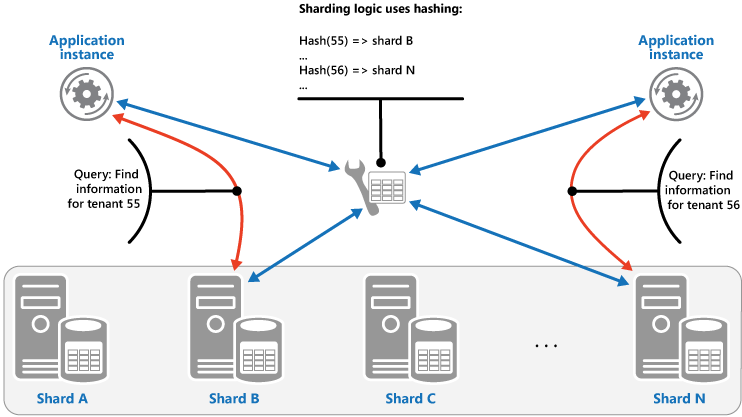
För att förstå fördelen med Hash-strategin jämfört med andra strategier för horisontell partitionering bör du överväga hur ett program med flera klienter som registrerar nya klienter sekventiellt kan tilldela klientorganisationer till shards i datalagret. Om man använder omfångsstrategin kommer data för alla klienterna 1 till n att lagras i shard A, data för alla klienterna n+1 till m kommer att lagras i shard B osv. Om de senast registrerade klienterna också är de mest aktiva kommer den mesta dataaktiviteten att inträffa i ett litet antal shards, vilket kan leda till hotspots. Hash-strategin tilldelar i stället klienter till shards baserat på en hash av deras klient-ID. Det innebär att sekventiella klienter mest sannolikt tilldelas till olika shards, vilket fördelar belastningen mellan dem. Föregående bild visar detta för klienterna 55 och 56.
De tre strategierna för horisontell partitionering har följande fördelar och överväganden:
Sökning. Det här ger mer kontroll över hur shards konfigureras och används. Med hjälp av virtuella shards minskas effekten vid ombalansering av data, eftersom de nya fysiska partitionerna kan läggas till för att jämna ut arbetsbelastningen. Mappningen mellan en virtuell shard och de fysiska partitioner som implementerar denna shard kan ändras utan att påverka programkod som använder en shardnyckel för att lagra och hämta data. Att leta upp platser för shards kan kräva ytterligare prestanda.
Omfång. Det här är enkelt att implementera och fungerar bra med omfångsfrågor, eftersom de ofta kan hämta flera dataobjekt från en enda shard i en enda åtgärd. Den här strategin ger enklare datahantering. Om exempelvis användare i samma region finns i samma shard kan uppdateringar schemaläggas i varje tidszon baserat på lokal belastning och begäransmönster. Den här strategin ger dock inte optimal balansering mellan shards. Det är svårt att ombalansera shards och det kanske inte löser problemet med ojämn belastning om den mesta aktiviteten gäller intilliggande shardnycklar.
Hash. Den här strategin ger större möjlighet till jämnare data- och belastningsfördelning. Routning av begäran kan åstadkommas direkt med hjälp av hash-funktionen. Det är inte nödvändigt att upprätthålla en karta. Tänk på att beräkning av hash kan kräva ytterligare prestanda. Det är även svårt att ombalansera shards.
De vanligaste systemen för horisontell partitionering implementerar en av de metoder som beskrivs ovan, men du bör även överväga programmens krav och deras mönster för dataanvändning. Till exempel i ett program med flera klientorganisationer:
Du kan fragmentera data baserat på arbetsbelastning. Du kan särskilja data för ej beständiga klienter i separata shards. Dataåtkomsthastigheten för andra klienter kan därigenom förbättras.
Du kan fragmentera data baserat på klienternas plats. Du kan ta data för klienter i en viss geografisk region och utföra säkerhetskopiering och underhåll under perioder med låg belastning i den regionen, medan data för klienter i andra regioner fortfarande är online och tillgängliga under deras arbetstid.
Klienter med högt värde kan tilldelas sina egna privata, högpresterande, lätt inlästa shards, medan klienter med lägre värde kan förväntas dela mer tätt packade, upptagna shards.
Data för klienter som behöver en hög grad av dataisolering och sekretess kan lagras på en helt separat server.
Åtgärder för skalning och dataförflyttning
Var och en av strategierna för horisontell partitionering innebär olika funktioner och komplexitetsnivåer för att hantera skalning in och ut, dataförflyttning och upprätthållande av tillstånd.
Sökningsstrategin tillåter att åtgärder för skalning och dataförflyttning utförs på användarnivå, antingen online eller offline. Tekniken innebär att pausa en del eller all användaraktivitet (kanske under perioder med låg belastning), flytta data till den nya virtuella partitionen eller fysiska sharden, ändra mappningarna, ogiltigförklara eller uppdatera eventuella cacheminnen som innehåller dessa data, och sedan tillåta att användaraktiviteten återupptas. Den här typen av åtgärd kan hanteras centralt. Sökningsstrategin kräver att tillståndet är cachelagringsbart i hög utsträckning och replikvänligt.
Omfångsstrategin innebär vissa begränsningar av åtgärder för skalning och dataförflyttning, som normalt måste utföras när en del av eller hela datalagret är offline, eftersom data måste delas och slås samman över shards. Flyttning av data för att balansera om shards kanske inte löser problemet med ojämn belastning om den mesta aktiviteten gäller intilliggande shardnycklar eller dataidentifierare som ligger inom samma intervall. Omfångsstrategin kan också kräva att ett visst tillstånd bibehålls för att mappa omfång till de fysiska partitionerna.
Hash-strategin gör åtgärder för skalning och dataförflyttning mer komplexa eftersom partitionsnycklarna är hashvärden av shardnycklarna eller dataidentifierarna. Den nya platsen för varje shard måste avgöras av hash-funktionen, eller funktionen som har ändrats för att tillhandahålla rätt mappningar. Hash-strategin kräver dock inte underhåll av tillstånd.
Problem och överväganden
Tänk på följande när du bestämmer hur du ska implementera mönstret:
Horisontell partitionering kompletterar andra former av partitionering, t.ex. vertikal partitionering och funktionell partitionering. En enda shard kan exempelvis innehålla entiteter som har partitionerats vertikalt, och en funktionell partition kan implementeras som flera shards. Mer information om partitionering finns i Vägledning om datapartitionering.
Se till att shards är balanserade så att de hanterar en liknande I/O-volym. När data infogas och raderas är det nödvändigt att regelbundet balansera om shards för att garantera jämn fördelning och minska risken för hotspots. Ombalansering kan vara en kostsam åtgärd. Minska behovet av ombalansering genom att planera för tillväxt genom att se till att varje shard innehåller tillräckligt med ledigt utrymme för att hantera den ändringsvolym som förväntas. Du bör också utveckla strategier och skript som du kan använda för att snabbt balansera om shards om detta blir nödvändigt.
Använd stabila data för shardnyckeln. Om shardnyckeln ändras kan motsvarande dataobjekt behöva flyttas mellan shards, vilket ökar den mängd arbete som kan utföras av uppdateringsåtgärder. Undvik därför att basera shardnyckeln på eventuell ej beständig information. Leta i stället efter attribut som inte varierar eller som bildar en nyckel på ett naturligt sätt.
Se till att shardnycklarna är unika. Undvik till exempel att använda fält som ökar automatiskt som shardnyckel. I vissa system kan autoinkrementerade fält inte samordnas mellan shards, vilket kan leda till att objekt i olika shards har samma shardnyckel.
Värden som ökar automatiskt i andra fält som inte är shardnycklar kan också orsaka problem. Om du till exempel använder fält som ökar automatiskt för att generera unika ID:n kan två olika objekt som finns i olika shards tilldelas samma ID.
Det kanske inte går att utforma en shardnyckel som överensstämmer med kraven för varje tänkbar fråga mot data. Fragmentera data för att få stöd för de frågor som körs oftast, och skapa vid behov sekundära indextabeller som ger stöd för frågor som hämtar data med hjälp av kriterier baserat på attribut som inte är en del av shardnyckeln. Mer information finns i Mönster för indextabell.
Frågor som endast har åtkomst till en enda shard är mer effektiva än de som hämtar data från flera shards, så undvik att implementera ett shard-system som leder till att program utför stora mängder frågor som kopplar data som finns i olika shards. Tänk på att en enda shard kan innehålla data för flera typer av entiteter. Överväg att avnormalisera data för att hålla samman relaterade entiteter som ofta frågas (t.ex. information om kunder och beställningar som de har gjort) i samma shard för att minska antalet separata läsningar som ett program utför.
Om en entitet i en shard hänvisar till en entitet som är lagrad i en annan shard, ska shardnyckeln inkluderas för den andra entiteten som en del av schemat för den första entiteten. Det kan hjälpa till att förbättra prestanda för frågor som hänvisar till relaterade data i olika shards.
Om ett program måste köra frågor som hämtar data från flera shards kan det vara möjligt att hämta dessa data med hjälp av parallella uppgifter. Exempel på detta kan vara förgreningsfrågor, där data från flera shards hämtas parallellt och sedan aggregeras till ett enda resultat. Den här metoden lägger dock oundvikligen till komplexitet i dataåtkomstlogiken för en lösning.
För många program kan det vara mer effektivt att skapa ett stort antal små shards i stället för att ha ett litet antal stora shards, eftersom de ger bättre möjligheter till belastningsutjämning. Det kan också vara användbart om du tror att du kommer att behöva migrera shards från en fysisk plats till en annan. Det går snabbare att flytta en liten shard än att flytta en stor.
Kontrollera att resurserna som är tillgängliga för varje shardlagringsnod är tillräckliga för att hantera skalbarhetskraven vad gäller datastorlek och dataflöde. Mer information finns i avsnittet "Designa partitioner för skalbarhet" i vägledningen för datapartitionering.
Överväg att replikera referensdata till alla shards. Om en åtgärd som hämtar data från en shard även hänvisar till statiska eller långsamma data som en del av samma fråga lägger du till dessa data i sharden. Programmet kan sedan enkelt hämta alla data för frågan enkelt utan att behöva göra ett ytterligare serveranrop till ett separat datalager.
Om referensdata som lagras i flera shards ändras måste systemet synkronisera dessa ändringar över alla shards. Systemet kan uppleva viss inkonsekvens under den här synkroniseringen. Om du gör detta ska programmen utformas för att kunna hantera det.
Det kan vara svårt att bibehålla referensintegriteten och konsekvensen mellan shards, så du bör minimera de åtgärder som påverkar data i flera shards. Utvärdera om fullständig datakonsekvens faktiskt krävs om ett program måste ändra data över shards. En vanlig metod i molnet är att istället implementera eventuell (slutlig) konsekvens. Data i varje partition uppdateras separat och programlogiken måste ta ansvar för att se till att alla uppdateringar slutförs, samt hantera de inkonsekvenser som kan uppstå från att skicka frågor till data under tiden en konsekvent åtgärd körs. Mer information om hur du hanterar slutlig datakonsekvens finns i introduktionen till datakonsekvens.
Det kan vara en utmaning att konfigurera och hantera ett stort antal shards. Uppgifter som övervakning, säkerhetskopiering, kontroll av konsekvens och loggning eller granskning måste utföras på flera shards och servrar, som eventuellt finns på flera platser. De här uppgifterna implementeras troligtvis med skript eller andra automatiseringslösningar, men det är inte säkert att det helt tar bort de ytterligare administrativa kraven.
Shards kan geolokaliseras så att data de innehåller finns nära de instanser av ett program som använder dem. Med den här metoden går det att förbättra prestanda avsevärt, men det kräver ytterligare överväganden för uppgifter som måste komma åt flera shards på olika platser.
När du ska använda det här mönstret
Använd det här mönstret när ett datalager troligtvis behöver skalas bortom de resurser som är tillgängliga för en enda lagringsnod, eller för att förbättra prestanda genom att minska konkurrens i ett datalager.
Kommentar
Primärt fokus för horisontell partitionering är att förbättra prestanda och skalbarhet i ett system, men det kan även leda till att man förbättrar tillgängligheten till följd av hur data delas upp i separata partitioner. Ett fel i en partition hindrar inte nödvändigtvis ett program från att komma åt data som lagras i andra partitioner, och en operatör kan utföra underhåll eller återställning av en eller flera partitioner utan att göra alla data för ett program otillgängliga. Mer information finns i Vägledning om datapartitionering.
Design av arbetsbelastning
En arkitekt bör utvärdera hur horisontell partitioneringsmönstret kan användas i arbetsbelastningens design för att uppfylla de mål och principer som beskrivs i grundpelarna i Azure Well-Architected Framework. Till exempel:
| Grundpelare | Så här stöder det här mönstret pelarmål |
|---|---|
| Beslut om tillförlitlighetsdesign hjälper din arbetsbelastning att bli motståndskraftig mot fel och se till att den återställs till ett fullt fungerande tillstånd när ett fel inträffar. | Eftersom data eller bearbetningen är isolerad till fragmentet förblir ett fel i ett fragment isolerat till fragmentet. - RE:06 Datapartitionering - RE:07 Självbevarande |
| Kostnadsoptimering fokuserar på att upprätthålla och förbättra arbetsbelastningens avkastning på investeringen. | Ett system som implementerar shards drar ofta nytta av att använda flera instanser av billigare beräknings- eller lagringsresurser i stället för en enda dyrare resurs. I många fall kan den här konfigurationen spara pengar. - CO:07 Komponentkostnader |
| Prestandaeffektivitet hjälper din arbetsbelastning att effektivt uppfylla kraven genom optimeringar inom skalning, data och kod. | När du använder horisontell partitionering i din skalningsstrategi isoleras data eller bearbetningen till en shard, så den konkurrerar endast om resurser med andra begäranden som dirigeras till fragmentet. Du kan också använda horisontell partitionering för att optimera baserat på geografi. - PE:05 Skalning och partitionering - PE:08 Dataprestanda |
Som med alla designbeslut bör du överväga eventuella kompromisser mot målen för de andra pelarna som kan införas med det här mönstret.
Exempel
Överväg en webbplats som visar upp en omfattande samling information om publicerade böcker över hela världen. Antalet möjliga böcker som katalogiseras i den här arbetsbelastningen och de typiska fråge-/användningsmönstren kontra indikerar användningen av en enda relationsdatabas för att lagra bokinformationen. Arbetsbelastningsarkitekten bestämmer sig för att fragmentera data över flera databasinstanser med hjälp av böckernas statiska internationella standardboknummer (ISBN) för shardnyckeln. Mer specifikt använder de kontrollsiffran (0–10) av ISBN eftersom det ger 11 möjliga logiska shards och data balanseras rättvist över varje shard. Till att börja med bestämmer de sig för att samplacera de 11 logiska fragmenten i tre fysiska sharddatabaser. De använder metoden för uppslagssharding och lagrar information om nyckel-till-server-mappning i en shard-kartdatabas.
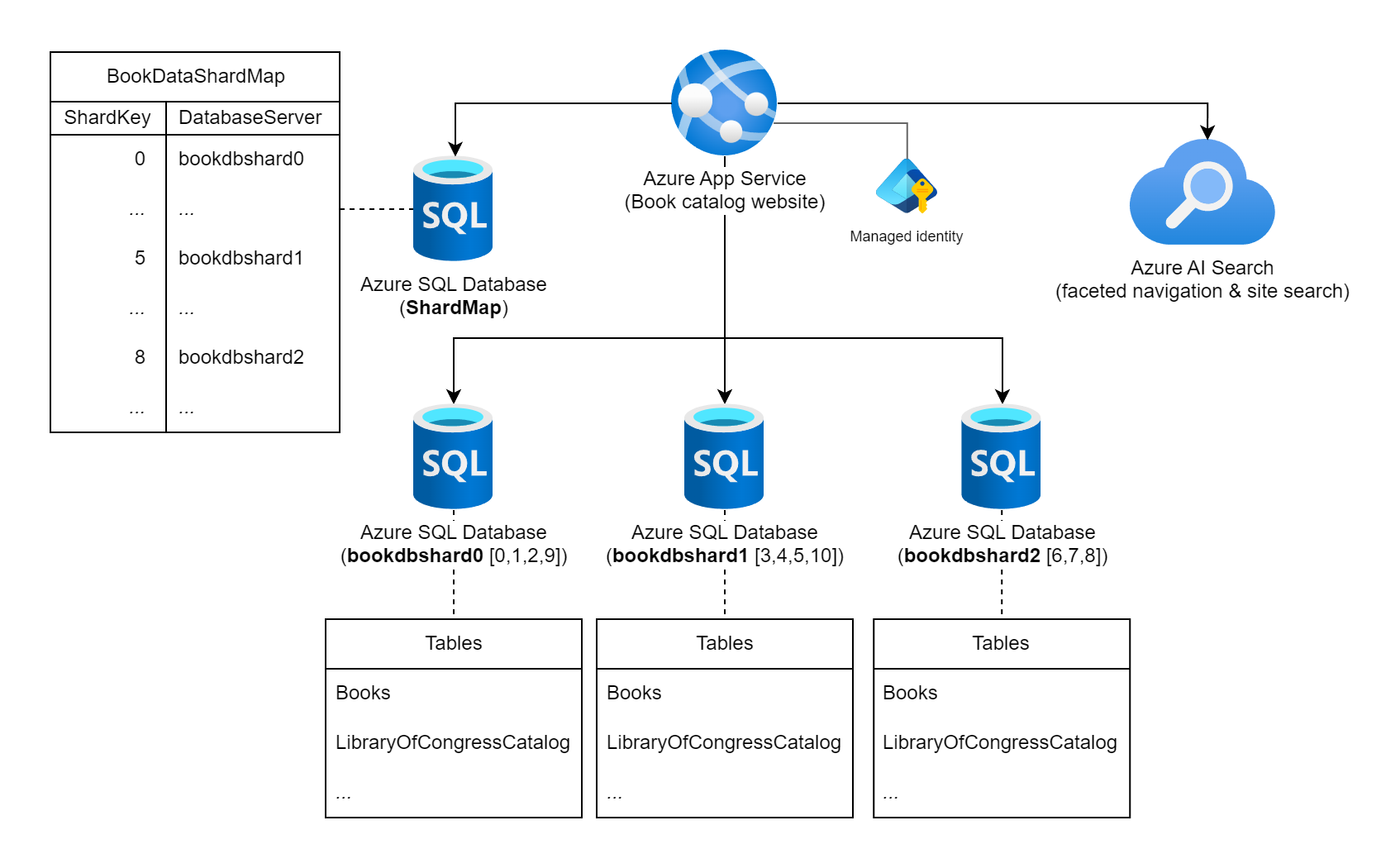
Diagram som visar en Azure App Service märkt som "Bokkatalogwebbplats" som är ansluten till flera Azure SQL Database-instanser och en Azure AI Search-instans. En av databaserna är märkt som ShardMap-databasen och har en exempeltabell som speglar en del av mappningstabellen som också visas längre upp i det här dokumentet. Det finns även tre instanser av sharddatabaser: bookdbshard0, bookdbshard1 och bookdbshard2. Var och en av databaserna har en exempellista med tabeller under sig. Alla tre exemplen är identiska och visar tabellerna "Böcker" och "LibraryOfCongressCatalog" och en indikator på fler tabeller. Azure AI Search-ikonen anger att den används för fasetterad navigering och webbplatssökning. Hanterad identitet visas som associerad med Azure App Service.
Karta över uppslagsshard
Shard Map-databasen innehåller följande shardmappningstabell och data.
SELECT ShardKey, DatabaseServer
FROM BookDataShardMap
| ShardKey | DatabaseServer |
|----------|----------------|
| 0 | bookdbshard0 |
| 1 | bookdbshard0 |
| 2 | bookdbshard0 |
| 3 | bookdbshard1 |
| 4 | bookdbshard1 |
| 5 | bookdbshard1 |
| 6 | bookdbshard2 |
| 7 | bookdbshard2 |
| 8 | bookdbshard2 |
| 9 | bookdbshard0 |
| 10 | bookdbshard1 |
Exempel på webbplatskod – enkel shardåtkomst
Webbplatsen är inte medveten om antalet fysiska sharddatabaser (tre i det här fallet) eller logiken som mappar en shardnyckel till en databasinstans, men webbplatsen vet att kontrollsiffran för en boks ISBN bör betraktas som shardnyckeln. Webbplatsen har skrivskyddad åtkomst till shardmappningsdatabasen och skrivskyddad åtkomst till alla sharddatabaser. I det här exemplet använder webbplatsen Azure App Service systemhanterade identitet som är värd för webbplatsen för auktorisering för att hålla hemligheter borta från niska veze.
Webbplatsen konfigureras med följande niska veze, antingen i en appsettings.json fil, till exempel i det här exemplet, eller via App Service-appinställningar.
{
...
"ConnectionStrings": {
"ShardMapDb": "Data Source=tcp:<database-server-name>.database.windows.net,1433;Initial Catalog=ShardMap;Authentication=Active Directory Default;App=Book Site v1.5a",
"BookDbFragment": "Data Source=tcp:SHARD.database.windows.net,1433;Initial Catalog=Books;Authentication=Active Directory Default;App=Book Site v1.5a"
},
...
}
Med anslutningsinformation till shardmappningsdatabasen tillgänglig skulle ett exempel på en uppdateringsfråga som körs av webbplatsen till arbetsbelastningens databasshardpool se ut ungefär som följande kod.
...
// All data for this book is stored in a shard based on the book's ISBN check digit,
// which is converted to an integer 0 - 10 (special value 'X' becomes 10).
int isbnCheckDigit = book.Isbn.CheckDigitAsInt;
// Establish a pooled connection to the database shard for this specific book.
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: isbnCheckDigit, cancellationToken))
{
// Update the book's Library of Congress catalog information
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"UPDATE LibraryOfCongressCatalog
SET ControlNumber = @lccn,
...
Classification = @lcc
WHERE BookID = @bookId";
cmd.Parameters.AddWithValue("@lccn", book.LibraryOfCongress.Lccn);
...
cmd.Parameters.AddWithValue("@lcc", book.LibraryOfCongress.Lcc);
cmd.Parameters.AddWithValue("@bookId", book.Id);
await cmd.ExecuteNonQueryAsync(cancellationToken);
}
...
I föregående exempelkod, om book.Isbn var 978-8-1130-1024-6, ska då isbnCheckDigit vara 6. Anropet till OpenShardConnectionForKeyAsync(6) implementeras vanligtvis med en cache-aside-metod. Den frågar den shardmappningsdatabas som identifierats med niska veze ShardMapDb om den inte har cachelagrad shardinformation för shardnyckel 6. Antingen från programmets cacheminne eller från sharddatabasen ersätter SHARD värdet bookdbshard2 i BookDbFragment niska veze. En poolanslutning upprättas (på nytt) för att bookdbshard2.database.windows.net, öppnas och returneras till anropskoden. Koden uppdaterar sedan den befintliga posten på den databasinstansen.
Exempel på webbplatskod – flera shard-åtkomst
I sällsynta fall krävs en direkt, kors-shard-fråga av webbplatsen, programmet utför en parallell-out-fråga över alla shards.
...
// Retrieve all shard keys
var shardKeys = shardedDatabaseConnections.GetAllShardKeys();
// Execute the query, in a fan-out style, against each shard in the shard list.
Parallel.ForEachAsync(shardKeys, async (shardKey, cancellationToken) =>
{
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: shardKey, cancellationToken))
{
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"SELECT ...
FROM ...
WHERE ...";
SqlDataReader reader = await cmd.ExecuteReaderAsync(cancellationToken);
while (await reader.ReadAsync(cancellationToken))
{
// Read the results in to a thread-safe data structure.
}
reader.Close();
}
});
...
Ett alternativ till frågor mellan fragment i den här arbetsbelastningen kan vara att använda ett externt underhållet index i Azure AI Search, till exempel för webbplatssökning eller fasetterade navigeringsfunktioner.
Lägga till shard-instanser
Arbetsbelastningsteamet är medvetna om att om datakatalogen eller dess samtidiga användning ökar betydligt mer än tre databasinstanser kan det krävas. Arbetsbelastningsteamet förväntar sig inte att dynamiskt lägga till databasservrar och kommer att uthärda arbetsbelastningsavbrott om en ny shard behöver komma online. För att en ny shard-instans ska kunna tas online måste data flyttas från befintliga shards till den nya fragmentet tillsammans med en uppdatering av shardkarttabellen. Med den här ganska statiska metoden kan arbetsbelastningen cachelagras säkert shardnyckeldatabasmappningen i webbplatskoden.
Logiken för shardnyckeln i det här exemplet har en hård övre gräns på 11 maximala fysiska shards. Om arbetsbelastningsteamet utför belastningsuppskattningstester och utvärderar att fler än 11 databasinstanser så småningom kommer att krävas, skulle en invasiv ändring av shardnyckellogik behöva göras. Den här ändringen omfattar noggrann planering av kodändringar och datamigrering till den nya nyckellogik.
SDK-funktioner
I stället för att skriva anpassad kod för shardhantering och frågeroutning till Azure SQL Database-instanser utvärderar du Elastic Database-klientbiblioteket. Det här biblioteket stöder hantering av fragmentkartor, databeroende frågeroutning och frågor mellan fragment i både C# och Java.
Nästa steg
Följande riktlinjer kan även vara relevanta när du implementerar det här mönstret:
- Datakonsekvensprimer. Det kan vara nödvändigt att bibehålla konsekvensen för data som distribueras över olika shards. Sammanfattar problem med att bibehålla konsekvens över distribuerade data och beskriver fördelar och nackdelar med olika konsekvensmodeller.
- Riktlinjer för datapartitionering. Horisontell partitionering av ett dataarkiv kan leda till ett antal ytterligare problem. Beskriver de här problemen i relation till partitionering av datalager i molnet för att förbättra skalbarhet, minska konkurrens och optimera prestanda.
Relaterade resurser
Följande mönster kan också vara relevanta när du implementerar det här mönstret:
- Indextabellmönster. Ibland är det inte möjligt att uppnå fullständigt stöd för frågor endast genom utformningen av shardnyckeln. Gör det möjligt för ett program att snabbt hämta data från ett stort datalager genom att ange en annan nyckel än shardnyckeln.
- Mönster för materialiserad vy. Om du vill behålla prestandan för vissa frågeåtgärder är det praktiskt att skapa materialiserade vyer som sammanställer och sammanfattar data, särskilt om dessa sammanfattande data baseras på information som är fördelad i shards. Beskriver hur du skapar och fyller i dessa vyer.