Den här artikeln beskriver hur ett utvecklingsteam använde mått för att hitta flaskhalsar och förbättra prestanda för ett distribuerat system. Artikeln baseras på faktisk belastningstestning som vi gjorde för ett exempelprogram.
Den här artikeln ingår i en serie. Läs den första delen här.
Scenario: Bearbeta en händelseström med hjälp av Azure Functions.

I det här scenariot skickar en flotta med drönare positionsdata i realtid till Azure IoT Hub. En Functions-app tar emot händelserna, transformerar data till GeoJSON-format och skriver transformerade data till Azure Cosmos DB. Azure Cosmos DB har inbyggt stöd för geospatiala data och Azure Cosmos DB-samlingar kan indexeras för effektiva rumsliga frågor. Ett klientprogram kan till exempel fråga efter alla drönare inom 1 km från en viss plats eller hitta alla drönare inom ett visst område.
Dessa bearbetningskrav är så enkla att de inte kräver en fullvärdig strömbearbetningsmotor. I synnerhet ansluter bearbetningen inte strömmar, aggregerar data eller bearbetar över tidsfönster. Baserat på dessa krav passar Azure Functions bra för bearbetning av meddelanden. Azure Cosmos DB kan också skalas för att stödja mycket högt skrivdataflöde.
Övervaka dataflöde
Det här scenariot är en intressant prestandautmaning. Datahastigheten per enhet är känd, men antalet enheter kan variera. I det här affärsscenariot är svarstidskraven inte särskilt strikta. Den rapporterade positionen för en drönare behöver bara vara korrekt inom en minut. Funktionsappen måste dock hålla jämna poäng med den genomsnittliga inmatningsfrekvensen över tid.
IoT Hub lagrar meddelanden i en loggström. Inkommande meddelanden läggs till i strömmens slut. En läsare av strömmen – i det här fallet funktionsappen – styr sin egen hastighet för att passera dataströmmen. Denna avkoppling av läs- och skrivvägar gör IoT Hub mycket effektiv, men innebär också att en långsam läsare kan hamna på efterkälken. För att identifiera det här villkoret har utvecklingsteamet lagt till ett anpassat mått för att mäta meddelandets fördröjning. Det här måttet registrerar deltat mellan när ett meddelande tas emot IoT Hub och när funktionen tar emot meddelandet för bearbetning.
var ticksUTCNow = DateTimeOffset.UtcNow;
// Track whether messages are arriving at the function late.
DateTime? firstMsgEnqueuedTicksUtc = messages[0]?.EnqueuedTimeUtc;
if (firstMsgEnqueuedTicksUtc.HasValue)
{
CustomTelemetry.TrackMetric(
context,
"IoTHubMessagesReceivedFreshnessMsec",
(ticksUTCNow - firstMsgEnqueuedTicksUtc.Value).TotalMilliseconds);
}
Metoden TrackMetric skriver ett anpassat mått till Application Insights. Information om hur du använder TrackMetric i en Azure-funktion finns i Anpassad telemetri i C#-funktionen.
Om funktionen håller jämna resultat med mängden meddelanden bör det här måttet ha ett lågt stabilt tillstånd. En del svarstider är oundvikliga, så värdet blir aldrig noll. Men om funktionen hamnar på efterkälken börjar deltat mellan den köade tiden och bearbetningstiden att öka.
Test 1: Baslinje
Det första belastningstestet visade ett omedelbart problem: Funktionsappen tog konsekvent emot HTTP 429-fel från Azure Cosmos DB, vilket indikerar att Azure Cosmos DB begränsade skrivbegäranden.
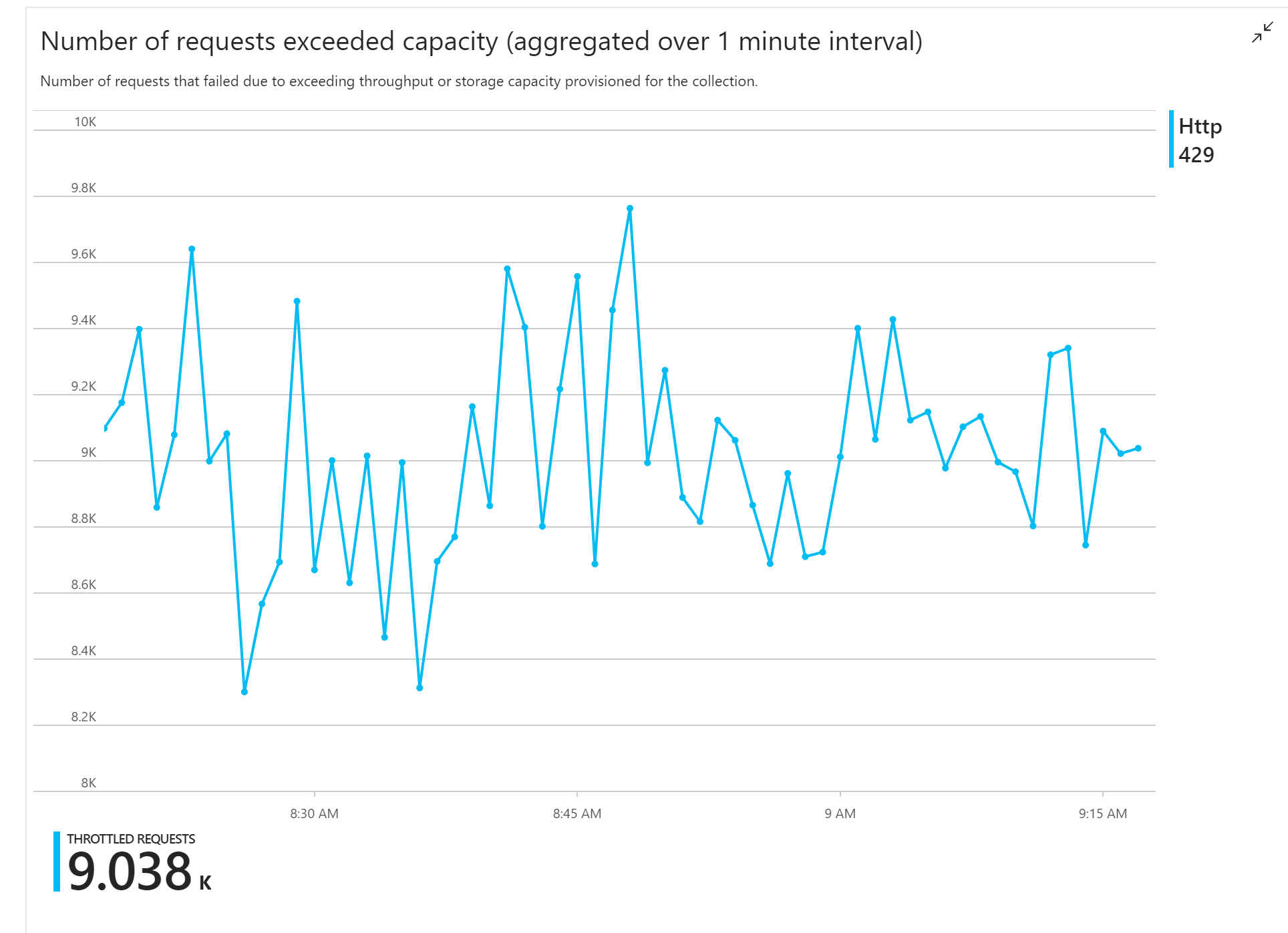
Som svar skalade teamet Azure Cosmos DB genom att öka antalet RU:er som allokerats för samlingen, men felen fortsatte. Detta verkade konstigt eftersom beräkningen av baksidan av kuvertet visade att Azure Cosmos DB inte borde ha några problem med att hålla jämna steg med mängden skrivbegäranden.
Senare samma dag skickade en av utvecklarna följande e-postmeddelande till teamet:
Jag tittade på Azure Cosmos DB för den varma vägen. Det finns en sak jag inte förstår. Partitionsnyckeln är deliveryId, men vi skickar inte deliveryId till Azure Cosmos DB. Saknar jag något?
Det var ledtråden. När vi tittade på partitionsvärmekartan visade det sig att alla dokument landade på samma partition.
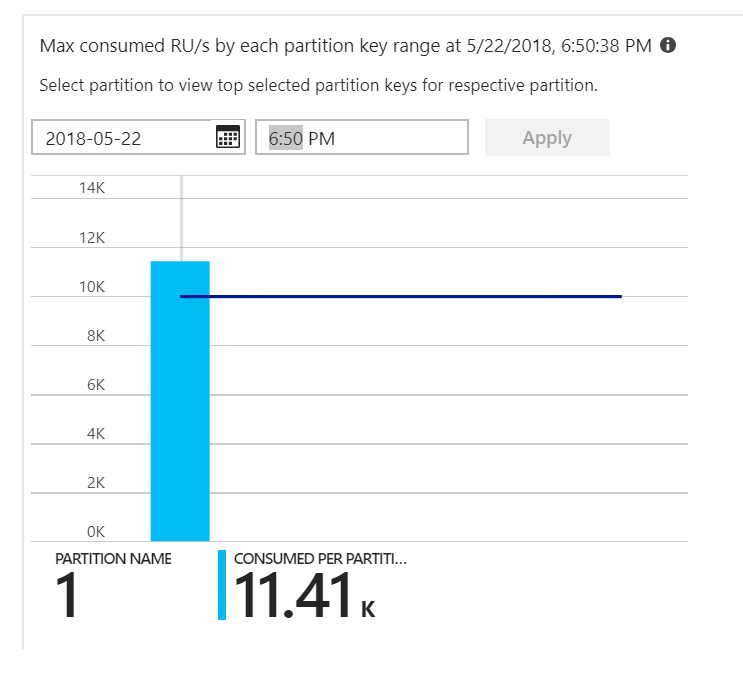
Det du vill se i termisk karta är en jämn fördelning mellan alla partitioner. I det här fallet hjälpte det inte att lägga till RU:er eftersom varje dokument skrevs till samma partition. Problemet visade sig vara en bugg i koden. Även om Azure Cosmos DB-samlingen hade en partitionsnyckel innehöll Inte Azure-funktionen partitionsnyckeln i dokumentet. Mer information om partitionsvärmekartan finns i Fastställa dataflödesfördelningen mellan partitioner.
Test 2: Åtgärda partitioneringsproblem
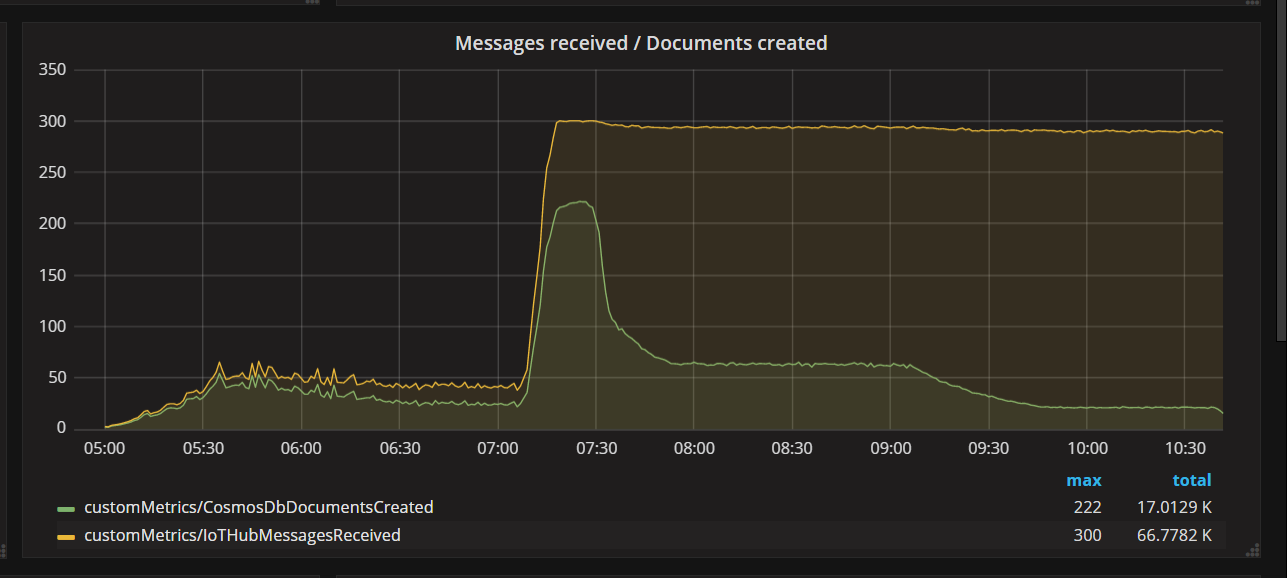
När teamet distribuerade en kodkorrigering och körde testet igen stoppade Azure Cosmos DB begränsningen. Ett tag såg allt bra ut. Men vid en viss belastning visade telemetrin att funktionen skrev färre dokument som den borde. I följande diagram visas meddelanden som tar emot från IoT Hub jämfört med dokument som skrivits till Azure Cosmos DB. Den gula linjen är antalet meddelanden som tas emot per batch, och den gröna är antalet dokument som skrivs per batch. Dessa bör vara proportionella. I stället minskar antalet skrivåtgärder för databaser per batch avsevärt vid cirka 07:30.
Nästa diagram visar svarstiden mellan när ett meddelande tas emot IoT Hub från en enhet och när funktionsappen bearbetar meddelandet. Du kan se att vid samma tidpunkt ökar fördröjningen dramatiskt, planar ut och minskar.
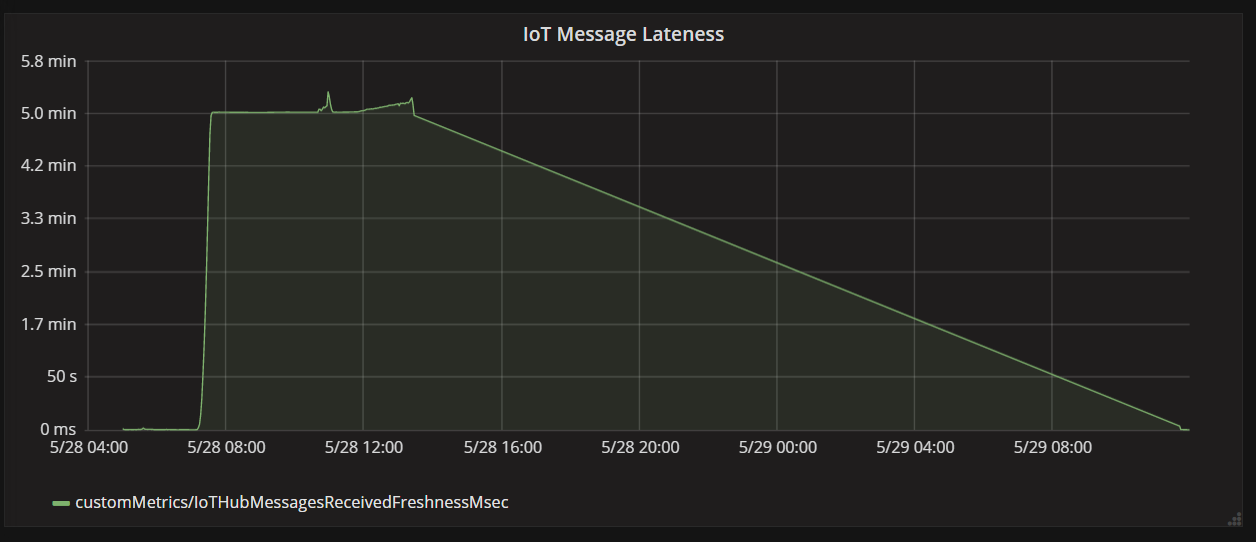
Anledningen till att värdet når sin topp vid 5 minuter och sedan sjunker till noll är att funktionsappen tar bort meddelanden som är mer än 5 minuter sena:
foreach (var message in messages)
{
// Drop stale messages,
if (message.EnqueuedTimeUtc < cutoffTime)
{
log.Info($"Dropping late message batch. Enqueued time = {message.EnqueuedTimeUtc}, Cutoff = {cutoffTime}");
droppedMessages++;
continue;
}
}
Du kan se detta i grafen när måttet för fördröjning sjunker tillbaka till noll. Under tiden har data gått förlorade eftersom funktionen kastade bort meddelanden.
Vad hände? För det här belastningstestet hade Azure Cosmos DB-samlingen RU:er att spara, så flaskhalsen fanns inte i databasen. I stället fanns problemet i meddelandebearbetningsloopen. Funktionen skrev helt enkelt inte dokument tillräckligt snabbt för att hålla jämna hand med den inkommande mängden meddelanden. Med tiden föll det längre och längre efter.
Test 3: Parallella skrivningar
Om tiden för att bearbeta ett meddelande är flaskhalsen är en lösning att bearbeta fler meddelanden parallellt. I det här scenariot:
- Öka antalet IoT Hub partitioner. Varje IoT Hub partition tilldelas en funktionsinstans i taget, så vi förväntar oss att dataflödet skalar linjärt med antalet partitioner.
- Parallellisera dokumentskrivningarna i funktionen.
För att utforska det andra alternativet ändrade teamet funktionen för att stödja parallella skrivningar. Den ursprungliga versionen av funktionen använde Azure Cosmos DB-utdatabindningen. Den optimerade versionen anropar Azure Cosmos DB-klienten direkt och utför skrivningarna parallellt med Hjälp av Task.WhenAll:
private async Task<(long documentsUpserted,
long droppedMessages,
long cosmosDbTotalMilliseconds)>
ProcessMessagesFromEventHub(
int taskCount,
int numberOfDocumentsToUpsertPerTask,
EventData[] messages,
TraceWriter log)
{
DateTimeOffset cutoffTime = DateTimeOffset.UtcNow.AddMinutes(-5);
var tasks = new List<Task>();
for (var i = 0; i < taskCount; i++)
{
var docsToUpsert = messages
.Skip(i * numberOfDocumentsToUpsertPerTask)
.Take(numberOfDocumentsToUpsertPerTask);
// client will attempt to create connections to the data
// nodes on Azure Cosmos DB clusters on a range of port numbers
tasks.Add(UpsertDocuments(i, docsToUpsert, cutoffTime, log));
}
await Task.WhenAll(tasks);
return (this.UpsertedDocuments,
this.DroppedMessages,
this.CosmosDbTotalMilliseconds);
}
Observera att konkurrensförhållanden är möjliga med metoden . Anta att två meddelanden från samma drönare råkar komma in i samma batch med meddelanden. Genom att skriva dem parallellt kan det tidigare meddelandet skriva över det senare meddelandet. I det här scenariot kan programmet tolerera att förlora ett tillfälligt meddelande. Drönare skickar nya positionsdata var femte sekund, så data i Azure Cosmos DB uppdateras kontinuerligt. I andra scenarier kan det dock vara viktigt att bearbeta meddelanden strikt i ordning.
När den här kodändringen har distribuerats kunde programmet mata in mer än 2 500 begäranden per sekund med hjälp av en IoT Hub med 32 partitioner.
Överväganden på klientsidan
Den övergripande klientupplevelsen kan minskas av aggressiv parallellisering på serversidan. Överväg att använda Azure Cosmos DB-massexecutorbiblioteket (visas inte i den här implementeringen) vilket avsevärt minskar de beräkningsresurser på klientsidan som behövs för att mätta dataflödet som allokerats till en Azure Cosmos DB-container. Ett enda trådat program som skriver data med hjälp av API:et för massimport uppnår nästan tio gånger större skrivgenomflöde jämfört med ett flertrådat program som skriver data parallellt samtidigt som klientdatorns PROCESSORmättas.
Sammanfattning
I det här scenariot identifierades följande flaskhalsar:
- Partition med frekvent skrivning på grund av att partitionsnyckelvärdet saknas i dokumenten som skrivs.
- Skriva dokument i seriellt per IoT Hub partition.
För att diagnostisera dessa problem förlitade sig utvecklingsteamet på följande mått:
- Begränsade begäranden i Azure Cosmos DB.
- Karta över partitionsvärme – Maximalt förbrukade RU:er per partition.
- Mottagna meddelanden jämfört med dokument som skapats.
- Meddelandefördendhet.
Nästa steg
Granska prestandaantimönster