Självstudie: Utföra vektorlikhetssökning på Azure OpenAI-inbäddningar med Azure Cache for Redis
I den här självstudien går du igenom ett grundläggande användningsfall för vektorlikhetssökning. Du använder inbäddningar som genereras av Azure OpenAI-tjänsten och de inbyggda vektorsökningsfunktionerna på Enterprise-nivån i Azure Cache for Redis för att fråga en datauppsättning med filmer för att hitta den mest relevanta matchningen.
I självstudien används datamängden Wikipedia Movie Plots som innehåller diagrambeskrivningar av över 35 000 filmer från Wikipedia som täcker åren 1901 till 2017. Datamängden innehåller en plotsammanfattning för varje film, plus metadata som året då filmen släpptes, regissörerna, huvudskådespelarna och genren. Du följer stegen i självstudien för att generera inbäddningar baserat på diagramsammanfattningen och använda andra metadata för att köra hybridfrågor.
I den här självstudien lär du dig att:
- Skapa en Azure Cache for Redis-instans som konfigurerats för vektorsökning
- Installera Azure OpenAI och andra nödvändiga Python-bibliotek.
- Ladda ned filmdatauppsättningen och förbered den för analys.
- Använd modellen text-embedding-ada-002 (version 2) för att generera inbäddningar.
- Skapa ett vektorindex i Azure Cache for Redis
- Använd cosinélikhet för att rangordna sökresultat.
- Använd hybridfrågefunktioner via RediSearch för att förfiltrera data och göra vektorsökningen ännu kraftfullare.
Viktigt!
Den här självstudien beskriver hur du skapar en Jupyter Notebook. Du kan följa den här självstudien med en Python-kodfil (.py) och få liknande resultat, men du måste lägga till alla kodblock i den här självstudien .py i filen och köra en gång för att se resultat. Med andra ord ger Jupyter Notebooks mellanliggande resultat när du kör celler, men det här är inte det beteende du bör förvänta dig när du arbetar i en Python-kodfil.
Viktigt!
Om du vill följa med i en slutförd Jupyter-anteckningsbok i stället laddar du ned Jupyter Notebook-filen med namnet tutorial.ipynb och sparar den i den nya redis-vector-mappen .
Förutsättningar
- En Azure-prenumeration – Skapa en kostnadsfritt
- Åtkomst som beviljas till Azure OpenAI i den önskade Azure-prenumerationen För närvarande måste du ansöka om åtkomst till Azure OpenAI. Du kan ansöka om åtkomst till Azure OpenAI genom att fylla i formuläret på https://aka.ms/oai/access.
- Python 3.7.1 eller senare version
- Jupyter Notebooks (valfritt)
- En Azure OpenAI-resurs med modellen text-embedding-ada-002 (version 2) distribuerad. Den här modellen är för närvarande endast tillgänglig i vissa regioner. Mer information om hur du distribuerar modellen finns i guiden för resursdistribution.
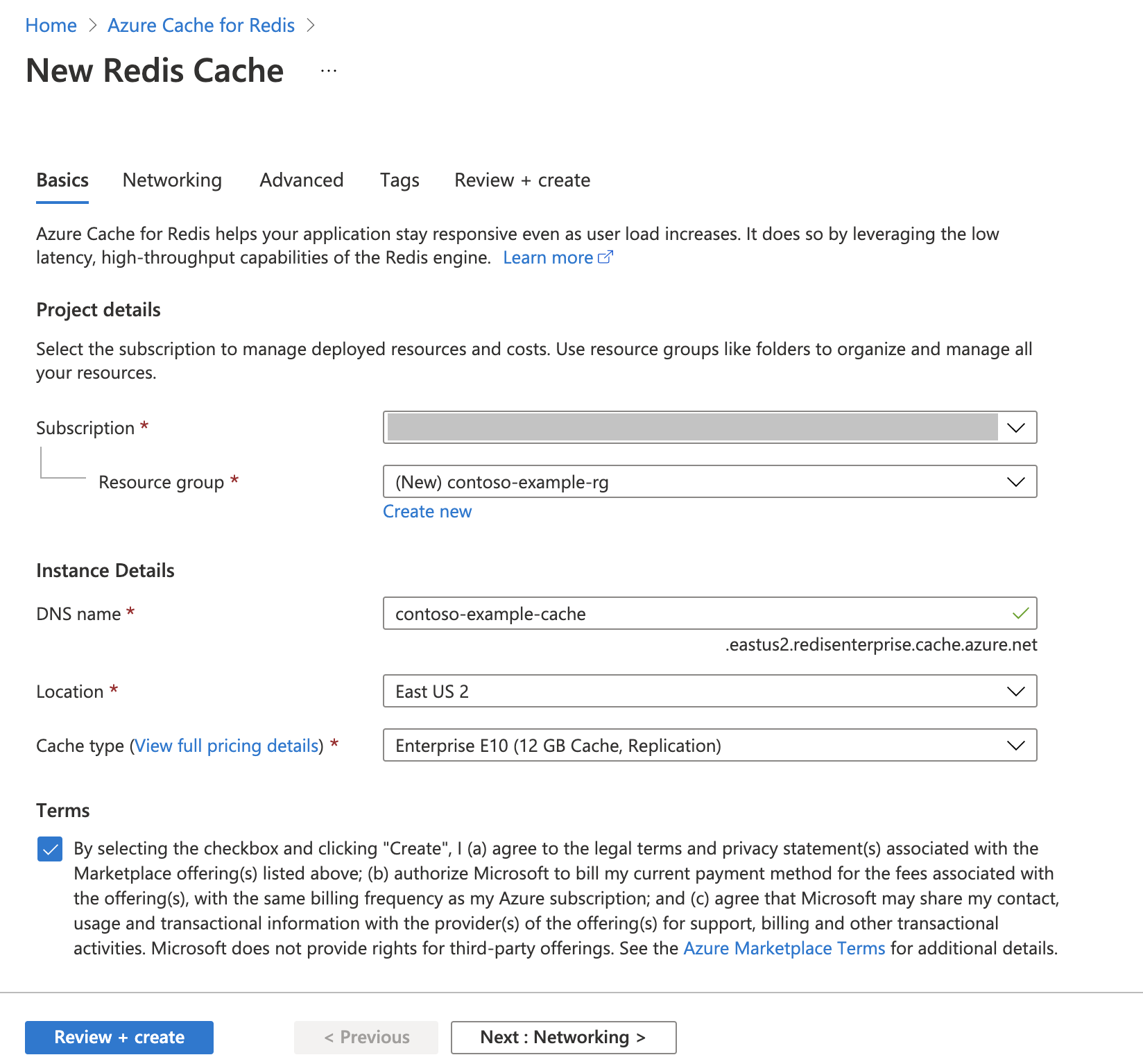
Skapa en Azure Cache for Redis-instans
Följ snabbstarten : Skapa en Redis Enterprise-cacheguide . På sidan Avancerat kontrollerar du att du har lagt till RediSearch-modulen och valt enterprise-klusterprincipen. Alla andra inställningar kan matcha standardvärdet som beskrivs i snabbstarten.
Det tar några minuter innan cacheminnet skapas. Du kan gå vidare till nästa steg under tiden.
Konfigurera utvecklingsmiljön
Skapa en mapp på den lokala datorn med namnet redis-vector på den plats där du vanligtvis sparar dina projekt.
Skapa en ny Python-fil (tutorial.py) eller Jupyter Notebook (tutorial.ipynb) i mappen.
Installera nödvändiga Python-paket:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Ladda ned datauppsättningen
I en webbläsare navigerar du till https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Logga in eller registrera dig med Kaggle. Registrering krävs för att ladda ned filen.
Välj länken Ladda ned på Kaggle för att ladda ned filen archive.zip.
Extrahera archive.zip-filen och flytta wiki_movie_plots_deduped.csv till mappen redis-vector.
Importera bibliotek och konfigurera anslutningsinformation
Om du vill göra ett anrop mot Azure OpenAI behöver du en slutpunkt och en nyckel. Du behöver också en slutpunkt och en nyckel för att ansluta till Azure Cache for Redis.
Gå till din Azure OpenAI-resurs i Azure Portal.
Leta upp slutpunkt och nycklar i avsnittet Resurshantering . Kopiera slutpunkten och åtkomstnyckeln eftersom du behöver båda för att autentisera dina API-anrop. En exempelslutpunkt är:
https://docs-test-001.openai.azure.com. Du kan använda antingenKEY1ellerKEY2.Gå till översiktssidan för din Azure Cache for Redis-resurs i Azure Portal. Kopiera slutpunkten.
Leta upp åtkomstnycklar i avsnittet Inställningar . Kopiera din åtkomstnyckel. Du kan använda antingen
PrimaryellerSecondary.Lägg till följande kod i en ny kodcell:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Uppdatera värdet
API_KEYför ochRESOURCE_ENDPOINTmed nyckel- och slutpunktsvärdena från Azure OpenAI-distributionen.DEPLOYMENT_NAMEska anges till namnet på distributionentext-embedding-ada-002 (Version 2)med hjälp av inbäddningsmodellen ochMODEL_NAMEska vara den specifika inbäddningsmodell som används.Uppdatera
REDIS_ENDPOINTochREDIS_PASSWORDmed slutpunkten och nyckelvärdet från din Azure Cache for Redis-instans.Viktigt!
Vi rekommenderar starkt att du använder miljövariabler eller en hemlig chef som Azure Key Vault för att skicka in information om API-nyckeln, slutpunkten och distributionsnamnet. Dessa variabler anges i klartext här för enkelhetens skull.
Kör kodcell 2.
Importera datamängd till Pandas och bearbeta data
Därefter läser du csv-filen i en Pandas DataFrame.
Lägg till följande kod i en ny kodcell:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfKör kodcell 3. Du bör se följande utdata:

Bearbeta sedan data genom att lägga till ett
idindex, ta bort blanksteg från kolumnrubrikerna och filtrera filmerna så att de endast tar filmer som gjorts efter 1970 och från engelsktalande länder. Det här filtreringssteget minskar antalet filmer i datamängden, vilket minskar kostnaden och tiden som krävs för att generera inbäddningar. Du kan ändra eller ta bort filterparametrarna baserat på dina inställningar.Om du vill filtrera data lägger du till följande kod i en ny kodcell:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfKör kodcell 4. Du bör se följande resultat:

Skapa en funktion för att rensa data genom att ta bort blanksteg och skiljetecken och sedan använda dem mot dataramen som innehåller diagrammet.
Lägg till följande kod i en ny kodcell och kör den:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Ta slutligen bort poster som innehåller diagrambeskrivningar som är för långa för inbäddningsmodellen. (Med andra ord kräver de fler token än 8192-tokengränsen.) och beräkna sedan antalet token som krävs för att generera inbäddningar. Detta påverkar även prissättningen för inbäddningsgenerering.
Lägg till följande kod i en ny kodcell:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Kör kodcell 6. Du bör se dessa utdata:
Number of movies: 11125 Number of tokens required:7044844Viktigt!
Se prissättningen för Azure OpenAI Service för att caculera kostnaden för att generera inbäddningar baserat på antalet token som krävs.


Läs in DataFrame i LangChain
Läs in DataFrame i LangChain med hjälp av DataFrameLoader klassen . När data finns i LangChain-dokument är det mycket enklare att använda LangChain-bibliotek för att generera inbäddningar och genomföra likhetssökningar. Ange Plot som page_content_column så att inbäddningar genereras i den här kolumnen.
Lägg till följande kod i en ny kodcell och kör den:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Generera inbäddningar och läs in dem i Redis
Nu när data har filtrerats och lästs in i LangChain skapar du inbäddningar så att du kan fråga efter diagrammet för varje film. Följande kod konfigurerar Azure OpenAI, genererar inbäddningar och läser in inbäddningsvektorerna i Azure Cache for Redis.
Lägg till följande kod som en ny kodcell:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Kör kodcell 8. Det kan ta över 30 minuter att slutföra. En
redis_schema.yamlfil genereras också. Den här filen är användbar om du vill ansluta till ditt index i Azure Cache for Redis-instansen utan att återskapa inbäddningar.
Viktigt!
Hur snabbt inbäddningar genereras beror på vilken kvot som är tillgänglig för Azure OpenAI-modellen. Med en kvot på 240 000 token per minut tar det cirka 30 minuter att bearbeta 7M-token i datauppsättningen.
Köra vektorsökningsfrågor
Nu när din datauppsättning, Azure OpenAI-tjänst-API och Redis-instans har konfigurerats kan du söka med hjälp av vektorer. I det här exemplet returneras de 10 främsta resultaten för en viss fråga.
Lägg till följande kod i Python-kodfilen:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Kör kodcell 9. Du bör se följande utdata:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Likhetspoängen returneras tillsammans med ordningstalet för filmer efter likhet. Observera att mer specifika frågor har likhetspoäng som minskar snabbare i listan.
Hybridsökningar
Eftersom RediSearch också har omfattande sökfunktioner utöver vektorsökning är det möjligt att filtrera resultat efter metadata i datauppsättningen, till exempel filmgenre, rollbesättning, utgivningsår eller regissör. I det här fallet filtrerar du baserat på genren
comedy.Lägg till följande kod i en ny kodcell:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Kör kodcell 10. Du bör se följande utdata:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Med Azure Cache for Redis och Azure OpenAI Service kan du använda inbäddningar och vektorsökning för att lägga till kraftfulla sökfunktioner i ditt program.
Rensa resurser
Om du vill fortsätta att använda de resurser som du skapade i den här artikeln behåller du resursgruppen.
Annars kan du ta bort den Azure-resursgrupp som du skapade om du är klar med resurserna för att undvika kostnader som är relaterade till resurserna.
Varning
Att ta bort en resursgrupp kan inte ångras. När du tar bort en resursgrupp tas alla resurser i resursgruppen bort permanent. Kontrollera att du inte av misstag tar bort fel resursgrupp eller resurser. Om du har skapat resurserna i en befintlig resursgrupp som har resurser som du vill behålla kan du ta bort varje resurs individuellt i stället för att ta bort resursgruppen.
Ta bort en resursgrupp
Logga in på Azure-portalen och välj Resursgrupper.
Välj den resursgrupp som ska tas bort.
Om det finns många resursgrupper anger du namnet på den resursgrupp som du skapade för att slutföra den här artikeln i Filtrera efter valfritt fält. I listan med sökresultat väljer du resursgruppen.
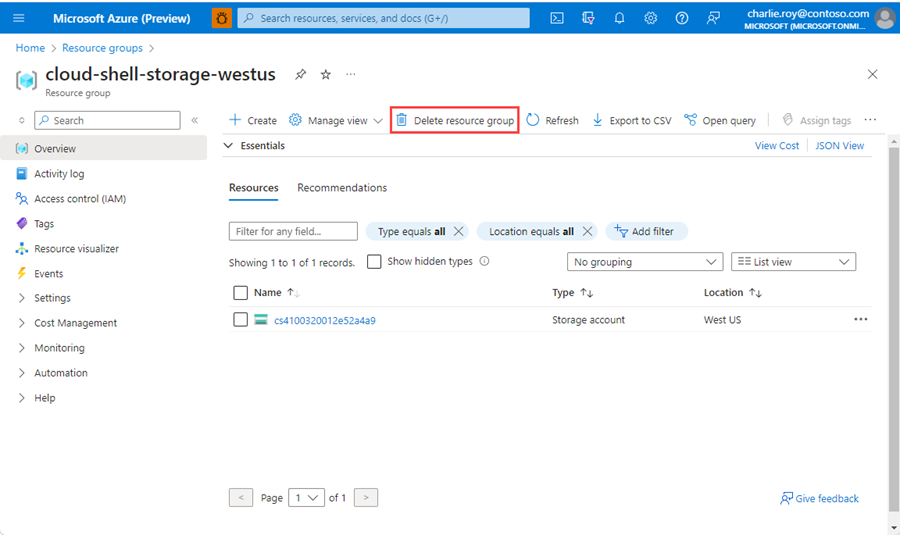
Välj Ta bort resursgrupp.
I fönstret Ta bort en resursgrupp anger du namnet på resursgruppen som ska bekräftas och väljer sedan Ta bort.
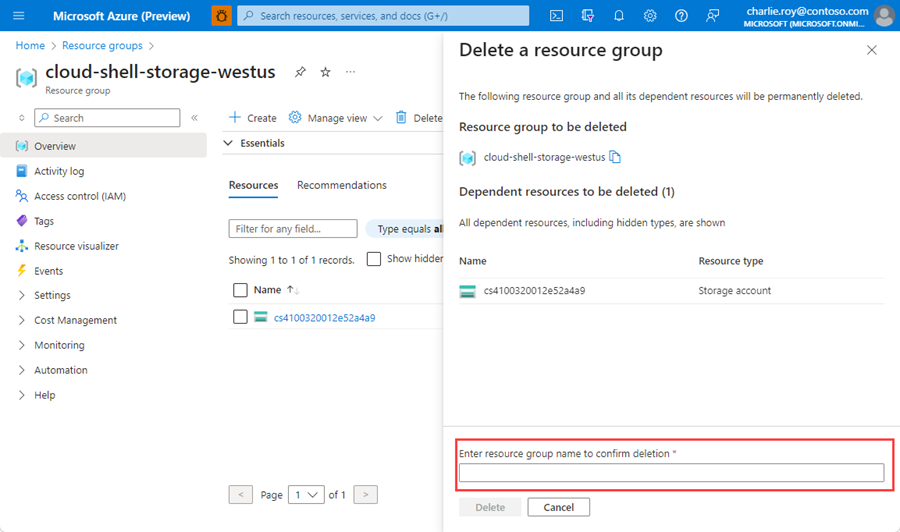
Inom en liten stund tas resursgruppen och alla dess resurser bort.
Relaterat innehåll
- Mer information om Azure Cache for Redis
- Läs mer om sökfunktioner för Azure Cache for Redis-vektor
- Läs mer om inbäddningar som genereras av Azure OpenAI Service
- Läs mer om cosinélikhet
- Läs hur du skapar en AI-baserad app med OpenAI och Redis
- Skapa en Q&A-app med semantiska svar