Haveriberedskap och geo-distribution i Azure Durable Functions
Microsoft strävar efter att säkerställa att Azure-tjänster alltid är tillgängliga. Oplanerade tjänststopp kan dock inträffa. Om programmet kräver återhämtning rekommenderar Microsoft att du konfigurerar appen för geo-redundans. Dessutom bör kunderna ha en haveriberedskapsplan för hantering av ett regionalt tjänststopp. En viktig del av en haveriberedskapsplan är att förbereda redundansväxling till den sekundära repliken av din app och lagring i händelse av att den primära repliken blir otillgänglig.
I Durable Functions behålls alla tillstånd i Azure Storage som standard. En aktivitetshubb är en logisk container för Azure Storage-resurser som används för orkestreringar och entiteter. Orkestrerings-, aktivitets- och entitetsfunktioner kan bara interagera med varandra när de tillhör samma aktivitetshubb. Det här dokumentet refererar till aktivitetshubbar när du beskriver scenarier för att hålla dessa Azure Storage-resurser högtillgängliga.
Anteckning
Vägledningen i den här artikeln förutsätter att du använder Azure Storage-standardprovidern för att lagra Durable Functions körningstillstånd. Det går dock att konfigurera alternativa lagringsproviders som lagrar tillstånd någon annanstans, till exempel en SQL Server databas. Olika strategier för haveriberedskap och geo-distribution kan krävas för de alternativa lagringsprovidrar. Mer information om alternativa lagringsproviders finns i dokumentationen om Durable Functions lagringsproviders.
Orkestreringar och entiteter kan utlösas med hjälp av klientfunktioner som själva utlöses via HTTP eller någon av de andra Azure Functions utlösartyper som stöds. De kan också utlösas med hjälp av inbyggda HTTP-API:er. För enkelhetens skull fokuserar den här artikeln på scenarier som involverar Azure Storage- och HTTP-baserade funktionsutlösare och alternativ för att öka tillgängligheten och minimera stilleståndstiden under haveriberedskapsaktiviteter. Andra utlösartyper, till exempel Service Bus- eller Azure Cosmos DB-utlösare, omfattas inte uttryckligen.
Följande scenarier baseras på Active-Passive konfigurationer, eftersom de styrs av användningen av Azure Storage. Det här mönstret består av att distribuera en reservfunktionsapp (passiv) till en annan region. Traffic Manager övervakar den primära (aktiva) funktionsappen för HTTP-tillgänglighet. Den redundansväxlar till funktionsappen för säkerhetskopiering om den primära misslyckas. Mer information finns i Azure Traffic Manager:s priority Traffic-Routing-metod.
Anteckning
- Den föreslagna Active-Passive konfigurationen säkerställer att en klient alltid kan utlösa nya orkestreringar via HTTP. Men till följd av att två funktionsappar delar samma aktivitetshubb i lagringen distribueras vissa lagringstransaktioner i bakgrunden mellan dem. Den här konfigurationen medför därför vissa extra utgående kostnader för den sekundära funktionsappen.
- Det underliggande lagringskontot och aktivitetshubben skapas i den primära regionen och delas av båda funktionsapparna.
- Alla funktionsappar som är redundant distribuerade måste dela samma funktionsåtkomstnycklar om de aktiveras via HTTP. Functions Runtime exponerar ett hanterings-API som gör det möjligt för konsumenter att programmatiskt lägga till, ta bort och uppdatera funktionsnycklar. Nyckelhantering är också möjligt med hjälp av Api:er för Azure Resource Manager.
Scenario 1 – Belastningsutjämning av beräkning med delad lagring
Om beräkningsinfrastrukturen i Azure misslyckas kan funktionsappen bli otillgänglig. För att minimera risken för sådana driftstopp använder det här scenariot två funktionsappar som distribueras till olika regioner. Traffic Manager har konfigurerats för att identifiera problem i den primära funktionsappen och automatiskt omdirigera trafik till funktionsappen i den sekundära regionen. Den här funktionsappen delar samma Azure Storage-konto och Aktivitetshubb. Funktionsapparnas tillstånd går därför inte förlorat och arbetet kan återupptas normalt. När hälsotillståndet har återställts till den primära regionen börjar Azure Traffic Manager dirigera begäranden till funktionsappen automatiskt.
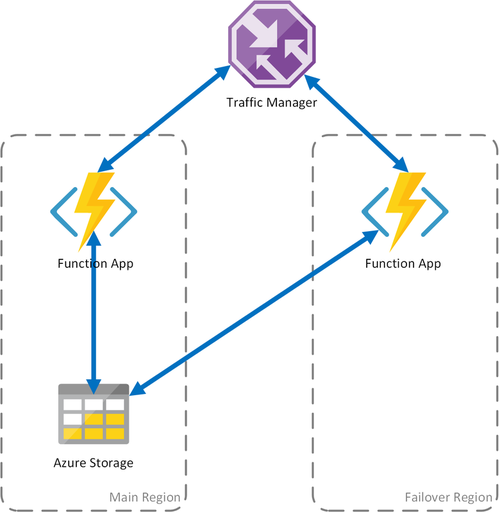
Det finns flera fördelar med att använda det här distributionsscenariot:
- Om beräkningsinfrastrukturen misslyckas kan arbetet återupptas i redundansregionen utan dataförlust.
- Traffic Manager tar automatiskt hand om den automatiska redundansväxlingen till den felfria funktionsappen.
- Traffic Manager återupprättar automatiskt trafik till den primära funktionsappen efter att avbrottet har korrigerats.
Men om du använder det här scenariot bör du tänka på följande:
- Om funktionsappen distribueras med hjälp av en dedikerad App Service plan ökar kostnaderna om du replikerar beräkningsinfrastrukturen i redundanscentret.
- Det här scenariot omfattar avbrott i beräkningsinfrastrukturen, men lagringskontot fortsätter att vara den enda felpunkten för funktionsappen. Om ett lagringsavbrott inträffar drabbas programmet av stilleståndstid.
- Om funktionsappen redundas ökar svarstiden eftersom den får åtkomst till sitt lagringskonto mellan regioner.
- Åtkomst till lagringstjänsten från en annan region där den finns medför högre kostnader på grund av utgående nätverkstrafik.
- Det här scenariot beror på Traffic Manager. Med tanke på hur Traffic Manager fungerar kan det ta en stund innan ett klientprogram som använder en durable funktion måste fråga funktionsappens adress från Traffic Manager igen.
Anteckning
Från och med v2.3.0 i Durable Functions-tillägget kan två funktionsappar köras på ett säkert sätt samtidigt med samma lagringskonto och konfiguration av aktivitetshubben. Den första appen som ska startas hämtar ett bloblån på programnivå som förhindrar att andra appar stjäl meddelanden från aktivitetshubbens köer. Om den första appen slutar att köras upphör lånet att gälla och kan hämtas av en andra app, som sedan fortsätter att bearbeta meddelanden från aktivitetshubben.
Före v2.3.0 bearbetar funktionsappar som är konfigurerade för att använda samma lagringskonto meddelanden och uppdaterar lagringsartefakter samtidigt, vilket resulterar i mycket högre övergripande svarstider och utgående kostnader. Om de primära apparna och replikapparna någonsin har olika kod distribuerad till dem, även tillfälligt, kan orkestreringarna också misslyckas med att köras korrekt på grund av orkestreringsfunktionens inkonsekvenser mellan de två apparna. Därför rekommenderar vi att alla appar som kräver geo-distribution för haveriberedskap använder v2.3.0 eller senare av durable-tillägget.
Scenario 2 – Belastningsutjämning av beräkning med regional lagring
Föregående scenario omfattar endast fall av fel i beräkningsinfrastrukturen. Om lagringstjänsten misslyckas leder det till ett avbrott i funktionsappen. För att säkerställa kontinuerlig drift av varaktiga funktioner använder det här scenariot ett lokalt lagringskonto i varje region som funktionsapparna distribueras till.
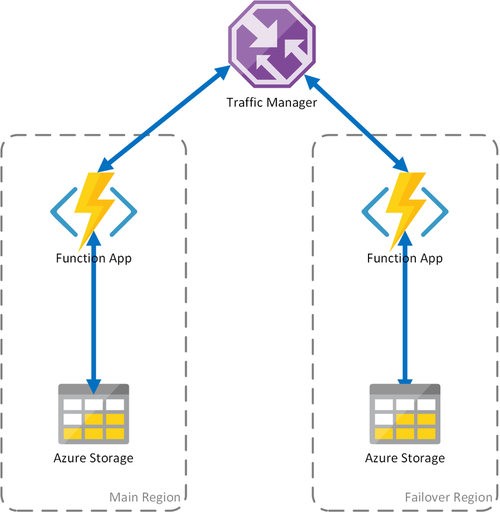
Den här metoden lägger till förbättringar i föregående scenario:
- Om funktionsappen misslyckas tar Traffic Manager hand om redundansväxling till den sekundära regionen. Men eftersom funktionsappen förlitar sig på sitt eget lagringskonto fortsätter de varaktiga funktionerna att fungera.
- Under en redundansväxling finns det ingen ytterligare svarstid i redundansregionen eftersom funktionsappen och lagringskontot samplaceras.
- Fel i lagringsskiktet orsakar fel i de hållbara funktionerna, vilket i sin tur utlöser en omdirigering till redundansregionen. Eftersom funktionsappen och lagringen är isolerade per region fortsätter de varaktiga funktionerna att fungera.
Viktiga överväganden för det här scenariot:
- Om funktionsappen distribueras med hjälp av en dedikerad App Service plan ökar kostnaderna om du replikerar beräkningsinfrastrukturen i redundanscentret.
- Det aktuella tillståndet redundas inte, vilket innebär att befintliga orkestreringar och entiteter i praktiken pausas och inte är tillgängliga förrän den primära regionen återställs.
För att sammanfatta är kompromissen mellan det första och andra scenariot att svarstiden bevaras och att utgående kostnader minimeras, men befintliga orkestreringar och entiteter är inte tillgängliga under stilleståndstiden. Om dessa kompromisser är godtagbara beror på kraven för programmet.
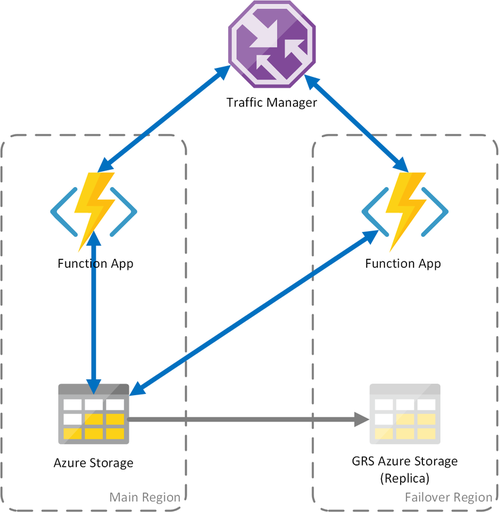
Scenario 3 – Belastningsutjämningsberäkning med delad GRS-lagring
Det här scenariot är en ändring i det första scenariot som implementerar ett delat lagringskonto. Den största skillnaden är att lagringskontot skapas med geo-replikering aktiverat. Funktionellt ger det här scenariot samma fördelar som scenario 1, men det ger ytterligare fördelar med dataåterställning:
- Geo-redundant lagring (GRS) och GRS med läsåtkomst (RA-GRS) maximerar tillgängligheten för ditt lagringskonto.
- Om lagringstjänsten har ett regionalt avbrott kan du initiera en redundansväxling till den sekundära repliken manuellt. I extrema fall där en region går förlorad på grund av en betydande katastrof kan Microsoft initiera en regional redundansväxling. I det här fallet krävs ingen åtgärd från din sida.
- När en redundansväxling inträffar bevaras tillståndet för de varaktiga funktionerna fram till den senaste replikeringen av lagringskontot, vilket vanligtvis inträffar med några minuters mellanrum.
Precis som med de andra scenarierna finns det viktiga saker att tänka på:
- En redundansväxling till repliken kan ta lite tid. Tills redundansväxlingen har slutförts och Dns-posterna för Azure Storage har uppdaterats drabbas funktionsappen av ett avbrott.
- Det finns en ökad kostnad för att använda geo-replikerade lagringskonton.
- GRS-replikering kopierar dina data asynkront. Några av de senaste transaktionerna kan gå förlorade på grund av replikeringsprocessens svarstid.
Anteckning
Enligt beskrivningen i scenario 1 rekommenderar vi starkt att funktionsappar som distribueras med den här strategin använder v2.3.0 eller senare av Durable Functions-tillägget.
Mer information finns i dokumentationen om haveriberedskap och redundansväxling av lagringskonto i Azure Storage .