Felsöka insamling av Prometheus-mått i Azure Monitor
Följ stegen i den här artikeln för att fastställa orsaken till att Prometheus-mått inte samlas in som förväntat i Azure Monitor.
Replikpodden skrapar mått från kube-state-metrics, anpassade skrapmål i konfigurationskartan ama-metrics-prometheus-config och anpassade skrapmål som definierats i anpassade resurser. DaemonSet-poddar skrapar mått från följande mål på respektive nod: kubelet, cAdvisor, node-exporteroch anpassade skrapmål i konfigurationskartan ama-metrics-prometheus-config-node . Den podd som du vill visa loggarna och Prometheus-användargränssnittet för beror på vilket skrapmål du undersöker.
Felsöka med PowerShell-skript
Om du stöter på ett fel när du försöker aktivera övervakning för AKS-klustret följer du de här anvisningarna för att köra felsökningsskriptet. Det här skriptet är utformat för att utföra en grundläggande diagnos för eventuella konfigurationsproblem i klustret och du kan bifoga de genererade filerna samtidigt som du skapar en supportbegäran för snabbare lösning för ditt supportärende.
Begränsning av mått
Azure Monitor Managed Service for Prometheus har standardgränser och kvoter för inmatning. När du når inmatningsgränserna kan begränsning ske. Du kan begära en ökning av dessa gränser. Information om Prometheus-måttgränser finns i Tjänstbegränsningar för Azure Monitor.
I Azure Portal navigerar du till din Azure Monitor-arbetsyta. Gå till Metricsoch välj måtten Active Time Series % Utilization och Events Per Minute Received % Utilization. Kontrollera att båda är under 100 %.
Mer information om övervakning och aviseringar om dina inmatningsmått finns i Övervaka inmatning av Azure Monitor-arbetsytemått.
Tillfälliga luckor i insamling av måttdata
Under noduppdateringar kan du se ett mellanrum på 1 till 2 minuter i måttdata för mått som samlats in från vår insamlare på klusternivå. Det här gapet beror på att noden den körs på uppdateras som en del av en normal uppdateringsprocess. Det påverkar klusteromfattande mål som Kubetillståndsmått och anpassade programmål som anges. Det inträffar när klustret uppdateras manuellt eller via autouppdate. Det här beteendet förväntas och inträffar på grund av den nod som körs när den uppdateras. Ingen av våra rekommenderade aviseringsregler påverkas av det här beteendet.
Poddstatus
Kontrollera poddstatusen med följande kommando:
kubectl get pods -n kube-system | grep ama-metrics
När tjänsten körs korrekt returneras följande lista över poddar i formatet ama-metrics-xxxxxxxxxx-xxxxx :
ama-metrics-operator-targets-*ama-metrics-ksm-*ama-metrics-node-*podd för varje nod i klustret.
Varje poddtillstånd ska vara Running och ha lika många omstarter som antalet konfigurationsmappsändringar som har tillämpats. Podden ama-metrics-operator-targets-* kan ha en extra omstart i början och detta förväntas:

Om varje poddtillstånd bara är Running en eller flera poddar har startats om kör du följande kommando:
kubectl describe pod <ama-metrics pod name> -n kube-system
- Det här kommandot anger orsaken till omstarterna. Poddomstarter förväntas om configmap-ändringar har gjorts. Om orsaken till omstarten är
OOMKilledkan podden inte hänga med i måttvolymen. Se skalningsrekommendationerna för måttvolymen.
Om poddarna körs som förväntat är containerloggarna nästa plats att kontrollera.
Sök efter ommärkningskonfigurationer
Om mått saknas kan du också kontrollera om du har ommärkningskonfigurationer. Med ommärkningskonfigurationer ska du se till att ommärkningen inte filtrerar bort målen och att etiketterna som har konfigurerats korrekt matchar målen. Mer information finns i dokumentationen om Konfiguration av Prometheus relabel.
Containerloggar
Visa containerloggarna med följande kommando:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
Vid start skrivs eventuella initiala fel ut i rött, medan varningar skrivs ut i gult. (För att visa de färgade loggarna krävs minst PowerShell version 7 eller en Linux-distribution.)
- Kontrollera om det finns ett problem med att hämta autentiseringstoken:
- Meddelandet Ingen konfiguration för AKS-resursen loggas var femte minut.
- Podden startas om var 15:e minut för att försöka igen med felet: Det finns ingen konfiguration för AKS-resursen.
- I så fall kontrollerar du att datainsamlingsregeln och slutpunkten för datainsamling finns i resursgruppen.
- Kontrollera också att Azure Monitor-arbetsytan finns.
- Kontrollera att du inte har något privat AKS-kluster och att det inte är länkat till ett Azure Monitor Private Link-omfång för någon annan tjänst. Det här scenariot stöds för närvarande inte.
Konfigurationsbearbetning
Visa containerloggarna med följande kommando:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- Kontrollera att det inte finns några fel med parsning av Prometheus-konfigurationen, sammanslagning med alla standardmål för skrapning aktiverat och validering av den fullständiga konfigurationen.
- Om du inkluderade en anpassad Prometheus-konfiguration kontrollerar du att den identifieras i loggarna. Om inte:
- Kontrollera att konfigurationskartan har rätt namn:
ama-metrics-prometheus-configikube-systemnamnområdet. - Kontrollera att prometheus-konfigurationen i konfigurationsmappen finns under ett avsnitt som heter
prometheus-configunderdataså här:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- Kontrollera att konfigurationskartan har rätt namn:
- Om du skapade anpassade resurser bör du ha sett några valideringsfel när podd-/tjänstövervakare skapades. Om du fortfarande inte ser måtten från målen kontrollerar du att loggarna inte visar några fel.
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- Kontrollera att det inte finns några fel när
MetricsExtensiondet gäller autentisering med Azure Monitor-arbetsytan. - Kontrollera att det inte finns några fel från
OpenTelemetry collectorom att skrapa målen.
Kör följande kommando:
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- Det här kommandot visar ett fel om det finns ett problem med att autentisera med Azure Monitor-arbetsytan. Exemplet nedan visar loggar utan problem:


Om det inte finns några fel i loggarna kan Prometheus-gränssnittet användas för felsökning för att verifiera den förväntade konfigurationen och målen som skrapas.
Prometheus-gränssnitt
Varje ama-metrics-* podd har Användargränssnittet för Prometheus-agentläget tillgängligt på port 9090.
Anpassade konfigurations- och anpassade resurser-mål skrapas av ama-metrics-* podden och nodmålen av ama-metrics-node-* podden.
Port-forward till antingen replikpodden eller någon av daemonuppsättningspoddarna för att kontrollera slutpunkterna för konfiguration, tjänstidentifiering och mål enligt beskrivningen här för att kontrollera att de anpassade konfigurationerna är korrekta, de avsedda målen har identifierats för varje jobb och det finns inga fel med att skrapa specifika mål.
Kör kommandot kubectl port-forward <ama-metrics pod> -n kube-system 9090.
Öppna en webbläsare till adressen
127.0.0.1:9090/config. Det här användargränssnittet har den fullständiga skrapkonfigurationen. Kontrollera att alla jobb ingår i konfigurationen.
Gå till
127.0.0.1:9090/service-discoveryför att visa de mål som identifieras av det angivna tjänstidentifieringsobjektet och vad relabel_configs har filtrerat målen som ska vara. När du till exempel saknar mått från en viss podd kan du se om podden har identifierats och vad dess URI är. Du kan sedan använda den här URI:n när du tittar på målen för att se om det finns några skrapfel.
Gå till
127.0.0.1:9090/targetsför att visa alla jobb, senaste gången slutpunkten för jobbet skrapades och eventuella fel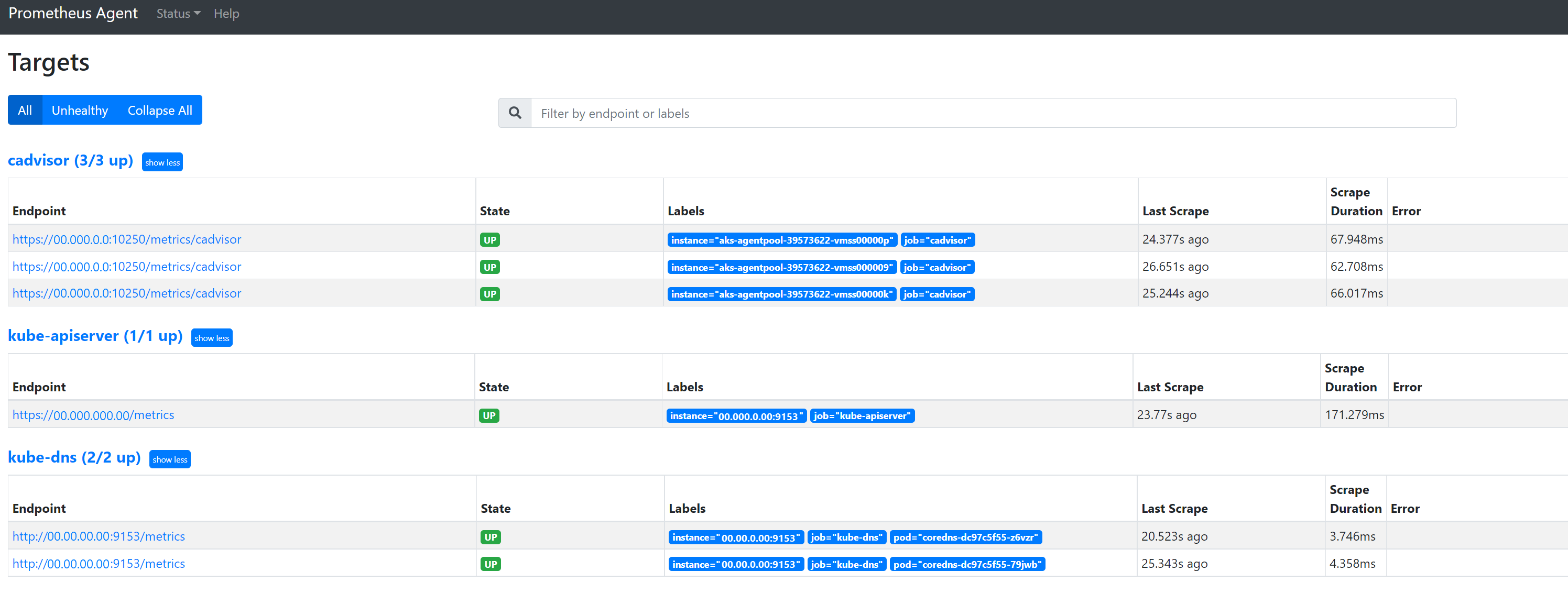



Anpassade resurser
- Om du inkluderade anpassade resurser kontrollerar du att de visas under konfiguration, tjänstidentifiering och mål.
Konfiguration

Tjänsteidentifiering

Mål

Om det inte finns några problem och de avsedda målen skrapas kan du visa de exakta mått som skrapas genom att aktivera felsökningsläget.
Felsökningsläge
Varning
Det här läget kan påverka prestanda och bör endast aktiveras under en kort tid för felsökning.
Måtttillägget kan konfigureras att köras i felsökningsläge genom att ändra konfigurationsmappsinställningen enabled under debug-mode till genom att true följa anvisningarna här.
När det här är aktiverat finns alla Prometheus-mått som skrapas på port 9091. Kör följande kommando:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
Gå till 127.0.0.1:9091/metrics i en webbläsare för att se om måtten har skrapats av OpenTelemetry Collector. Det här användargränssnittet kan nås för varje ama-metrics-* podd. Om måtten inte finns där kan det uppstå ett problem med mått- eller etikettnamnslängderna eller antalet etiketter. Kontrollera också om inmatningskvoten överskrids för Prometheus-mått enligt beskrivningen i den här artikeln.
Måttnamn, etikettnamn och etikettvärden
Måttskrapning har för närvarande begränsningarna i följande tabell:
| Property | Gräns |
|---|---|
| Namnlängd för etikett | Mindre än eller lika med 511 tecken. När den här gränsen överskrids för alla tidsserier i ett jobb misslyckas hela skrapjobbet och måtten tas bort från jobbet före inmatning. Du kan se up=0 för det jobbet och även mål-Ux visar orsaken till up=0. |
| Längd på etikettvärde | Mindre än eller lika med 1 023 tecken. När den här gränsen överskrids för en tidsserie i ett jobb misslyckas hela skrapet och måtten tas bort från jobbet före inmatning. Du kan se up=0 för det jobbet och även mål-Ux visar orsaken till up=0. |
| Antal etiketter per tidsserie | Mindre än eller lika med 63. När den här gränsen överskrids för alla tidsserier i ett jobb misslyckas hela skrapjobbet och måtten tas bort från jobbet före inmatning. Du kan se up=0 för det jobbet och även mål-Ux visar orsaken till up=0. |
| Längd på måttnamn | Mindre än eller lika med 511 tecken. När den här gränsen överskrids för alla tidsserier i ett jobb tas bara den specifika serien bort. MetricextensionConsoleDebugLog har spårningar för det borttagna måttet. |
| Etikettnamn med olika höljen | Två etiketter i samma måttexempel, med olika höljen, behandlas som dubbletter av etiketter och tas bort när de matas in. Till exempel tas tidsserien my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} bort på grund av duplicerade etiketter sedan dess ExampleLabel och examplelabel visas som samma etikettnamn. |
Kontrollera inmatningskvoten på Azure Monitor-arbetsytan
Om du ser att mått saknas kan du först kontrollera om inmatningsgränserna överskrids för din Azure Monitor-arbetsyta. I Azure Portal kan du kontrollera den aktuella användningen för valfri Azure Monitor-arbetsyta. Du kan se aktuella användningsstatistik under Metrics menyn för Azure Monitor-arbetsytan. Följande användningsmått är tillgängliga som standardmått för varje Azure Monitor-arbetsyta.
- Active Time Series – antalet unika tidsserier som nyligen matats in i arbetsytan under de senaste 12 timmarna
- Aktiv tidsseriegräns – Gränsen för antalet unika tidsserier som aktivt kan matas in på arbetsytan
- Aktiv tidsserie % användning – procentandelen av aktuella aktiva tidsserier som används
- Händelser per minut som matas in – Antalet händelser (exempel) per minut som nyligen tagits emot
- Gräns för inmatade händelser per minut – Det maximala antalet händelser per minut som kan matas in innan begränsningen begränsas
- Händelser per minut inmatad % användning – Procentandelen av den aktuella måttinmatningshastighetsgränsen som används
För att undvika måttinmatningsbegränsning kan du övervaka och konfigurera en avisering om inmatningsgränserna. Se Övervaka inmatningsgränser.
Se tjänstkvoter och gränser för standardkvoter och se vad som kan ökas baserat på din användning. Du kan begära kvotökning för Azure Monitor-arbetsytor med hjälp av Support Request menyn för Azure Monitor-arbetsytan. Se till att du inkluderar ID, internt ID och Plats/region för Azure Monitor-arbetsytan i supportbegäran, som du hittar på menyn Egenskaper för Azure Monitor-arbetsytan i Azure Portal.
Det gick inte att skapa Azure Monitor-arbetsytan på grund av utvärdering av Azure Policy
Om det inte går att skapa Azure Monitor-arbetsytan med ett felmeddelande om att resursen "resource-name-xyz" inte tilläts av principen kan det finnas en Azure-princip som förhindrar att resursen skapas. Om det finns en princip som tillämpar en namngivningskonvention för dina Azure-resurser eller resursgrupper måste du skapa ett undantag för namngivningskonventionen för att skapa en Azure Monitor-arbetsyta.
När du skapar en Azure Monitor-arbetsyta skapas som standard en datainsamlingsregel och en datainsamlingsslutpunkt i formuläret "azure-monitor-workspace-name" automatiskt i en resursgrupp i formuläret "MA_azure-monitor-workspace-name_location_managed". För närvarande finns det inget sätt att ändra namnen på dessa resurser, och du behöver ange ett undantag för Azure Policy för att undanta ovanstående resurser från principutvärdering. Se Azure Policy-undantagsstruktur.