Utveckla ett Kubernetes-program för Azure SQL Database
Gäller för:![]() Azure SQL Database
Azure SQL Database
I den här självstudien får du lära dig hur du utvecklar ett modernt program med hjälp av Python, Docker Containers, Kubernetes och Azure SQL Database.
Modern programutveckling har flera utmaningar. Från att välja en "stack" av klientdelen via datalagring och bearbetning från flera konkurrerande standarder, genom att säkerställa de högsta nivåerna av säkerhet och prestanda, krävs utvecklare för att säkerställa att programmet skalar och fungerar bra och kan stödjas på flera plattformar. För det sista kravet är det nu de rigueur i programutvecklingen att paketera programmet i containertekniker som Docker och distribuera flera containrar till Kubernetes-plattformen.
I det här exemplet utforskar vi med Python, Docker Containers och Kubernetes – alla körs på Microsoft Azure-plattformen. Att använda Kubernetes innebär att du också har flexibiliteten att använda lokala miljöer eller till och med andra moln för en sömlös och konsekvent distribution av ditt program och möjliggör multimolnsdistributioner för ännu högre återhämtning. Vi använder även Microsoft Azure SQL Database för en tjänstbaserad, skalbar, mycket elastisk och säker miljö för datalagring och bearbetning. I många fall använder andra program ofta redan Microsoft Azure SQL Database, och det här exempelprogrammet kan användas för att ytterligare använda och utöka dessa data.
Det här exemplet är ganska omfattande i omfånget, men använder det enklaste programmet, databasen och distributionen för att illustrera processen. Du kan anpassa det här exemplet så att det blir mycket mer robust, även om du använder de senaste teknikerna för returnerade data. Det är ett användbart inlärningsverktyg för att skapa ett mönster för andra program.
Använd Python, Docker Containers, Kubernetes och AdventureWorksLT-exempeldatabasen i ett praktiskt exempel
Företaget AdventureWorks (fiktiv) använder en databas som lagrar data om försäljning och marknadsföring, produkter, kunder och tillverkning. Den innehåller även vyer och lagrade procedurer som kopplar information om produkterna, till exempel produktnamn, kategori, pris och en kort beskrivning.
AdventureWorks-utvecklingsteamet vill skapa ett konceptbevis (PoC) som returnerar data från en vy i AdventureWorksLT databasen och gör dem tillgängliga som ett REST-API. Med hjälp av denna PoC skapar utvecklingsteamet ett mer skalbart och flermolnklart program för säljteamet. De har valt Microsoft Azure-plattformen för alla aspekter av distributionen. PoC använder följande element:
- Ett Python-program som använder Flask-paketet för huvudlös webbdistribution.
- Docker-containrar för kod- och miljöisolering, lagrade i ett privat register så att hela företaget kan återanvända programcontainrar i framtida projekt, vilket sparar tid och pengar.
- Kubernetes för enkel distribution och skalning och för att undvika plattformslåsning.
- Microsoft Azure SQL Database för val av storlek, prestanda, skalning, automatisk hantering och säkerhetskopiering, utöver lagring och bearbetning av relationsdata på högsta säkerhetsnivå.
I den här artikeln förklarar vi processen för att skapa hela proof-of-concept-projektet. De allmänna stegen för att skapa programmet är:
- Konfigurera förutsättningar
- Skapa programmet
- Skapa en Docker-container för att distribuera programmet och testa
- Skapa ett ACS-register (Azure Container Service) och läs in containern i ACS-registret
- Skapa Azure Kubernetes Service-miljön (AKS)
- Distribuera programcontainern från ACS-registret till AKS
- Testa programmet
- Rensa
Förutsättningar
I den här artikeln finns det flera värden som du bör ersätta. Se till att du konsekvent ersätter dessa värden för varje steg. Du kanske vill öppna en textredigerare och släppa dessa värden i för att ange rätt värden när du arbetar med proof-of-concept-projektet:
ReplaceWith_AzureSubscriptionName: Ersätt det här värdet med namnet på det Azure-prenumerationsnamn du har.ReplaceWith_PoCResourceGroupName: Ersätt det här värdet med namnet på den resursgrupp som du vill skapa.ReplaceWith_AzureSQLDBServerName: Ersätt det här värdet med namnet på den logiska Azure SQL Database-server som du skapar med hjälp av Azure-portalen.ReplaceWith_AzureSQLDBSQLServerLoginName: Ersätt det här värdet med värdet för det SQL Server-användarnamn som du skapar i Azure-portalen.ReplaceWith_AzureSQLDBSQLServerLoginPassword: Ersätt det här värdet med värdet för det SQL Server-användarlösenord som du skapar i Azure-portalen.ReplaceWith_AzureSQLDBDatabaseName: Ersätt det här värdet med namnet på den Azure SQL Database som du skapar med hjälp av Azure-portalen.ReplaceWith_AzureContainerRegistryName: Ersätt det här värdet med namnet på det Azure Container Registry som du vill skapa.ReplaceWith_AzureKubernetesServiceName: Ersätt det här värdet med namnet på den Azure Kubernetes-tjänst som du vill skapa.
Utvecklarna på AdventureWorks använder en blandning av Windows-, Linux- och Apple-system för utveckling, så de använder Visual Studio Code som miljö och git för källkontrollen, som båda kör plattformsoberoende.
För PoC kräver teamet följande krav:
Python, pip och paket – Utvecklingsteamet väljer programmeringsspråket Python som standard för det här webbaserade programmet. För närvarande använder de version 3.9, men alla versioner som stöder de PoC-paket som krävs är acceptabla.
- Du kan ladda ned Python version 3.9 från python.org.
Teamet använder paketet
pyodbcför databasåtkomst.- Du kan installera pyodbc-paketet med pip-kommandon.
- Du kan också behöva microsoft ODBC-drivrutinsprogramvaran om du inte redan har installerat den.
Teamet använder paketet
ConfigParserför att styra och ställa in konfigurationsvariabler.Teamet använder Flask-paketet för ett webbgränssnitt för programmet.
Därefter installerade teamet Azure CLI-verktyget, som enkelt identifierades med
azsyntax. Det här plattformsoberoende verktyget tillåter en kommandorads- och skriptmetod för PoC, så att de kan upprepa stegen när de gör ändringar och förbättringar.När Azure CLI har konfigurerats loggar teamet in på sin Azure-prenumeration och anger det prenumerationsnamn som de använde för PoC. De såg sedan till att Azure SQL Database-servern och databasen är tillgänglig för prenumerationen:
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameEn Microsoft Azure-resursgrupp är en logisk container som innehåller relaterade resurser för en Azure-lösning. I allmänhet läggs resurser som delar samma livscykel till i samma resursgrupp så att du enkelt kan distribuera, uppdatera och ta bort dem som en grupp. Resursgruppen lagrar metadata om resurserna och du kan ange en plats för resursgruppen.
Resursgrupper kan skapas och hanteras med hjälp av Azure-portalen eller Azure CLI. De kan också användas för att gruppera relaterade resurser för ett program och dela upp dem i grupper för produktion och icke-produktion, eller någon annan organisationsstruktur som du föredrar.

I följande kodfragment kan du se kommandot
azsom används för att skapa en resursgrupp. I vårt exempel använder vi regionen Eastusi Azure.az group create --name ReplaceWith_PoCResourceGroupName --location eastusUtvecklingsteamet skapar en Azure SQL Database med exempeldatabasen
AdventureWorksLTinstallerad med hjälp av en SQL-autentiserad inloggning.AdventureWorks har standardiserats på Microsoft SQL Server Relational Database Management System-plattformen och utvecklingsteamet vill använda en hanterad tjänst för databasen i stället för att installera lokalt. Med Hjälp av Azure SQL Database kan den här hanterade tjänsten vara helt kodkompatibel oavsett var de kör SQL Server-motorn: lokalt, i en container, i Linux eller Windows, eller till och med i en IoT-miljö (Internet of Things).
När de skapades använde de Azure-hanteringsportalen för att ange brandväggen för programmet till den lokala utvecklingsdatorn och ändrade standardvärdet som du ser här för att aktivera Tillåt alla Azure-tjänster och även hämtat autentiseringsuppgifterna för anslutningen.
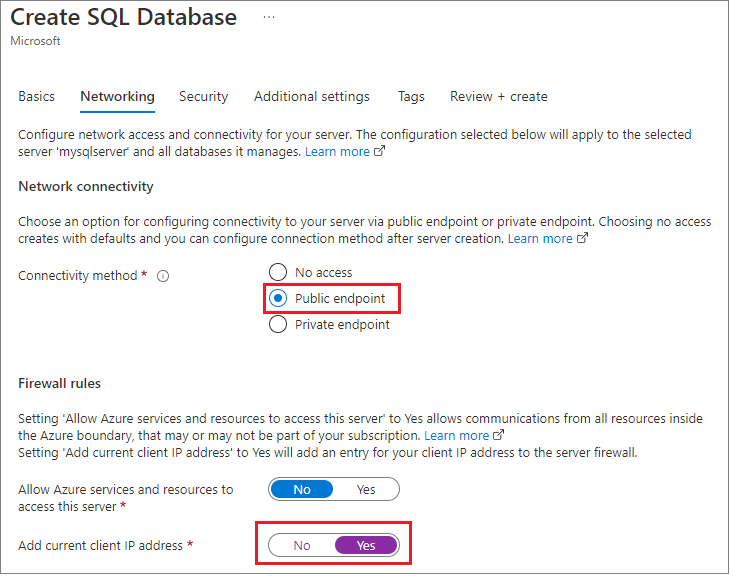
Med den här metoden kan databasen vara tillgänglig i en annan region eller till och med en annan prenumeration.
Teamet har konfigurerat en SQL-autentiserad inloggning för testning, men kommer att gå tillbaka till det här beslutet i en säkerhetsgranskning.
Teamet använde exempeldatabasen
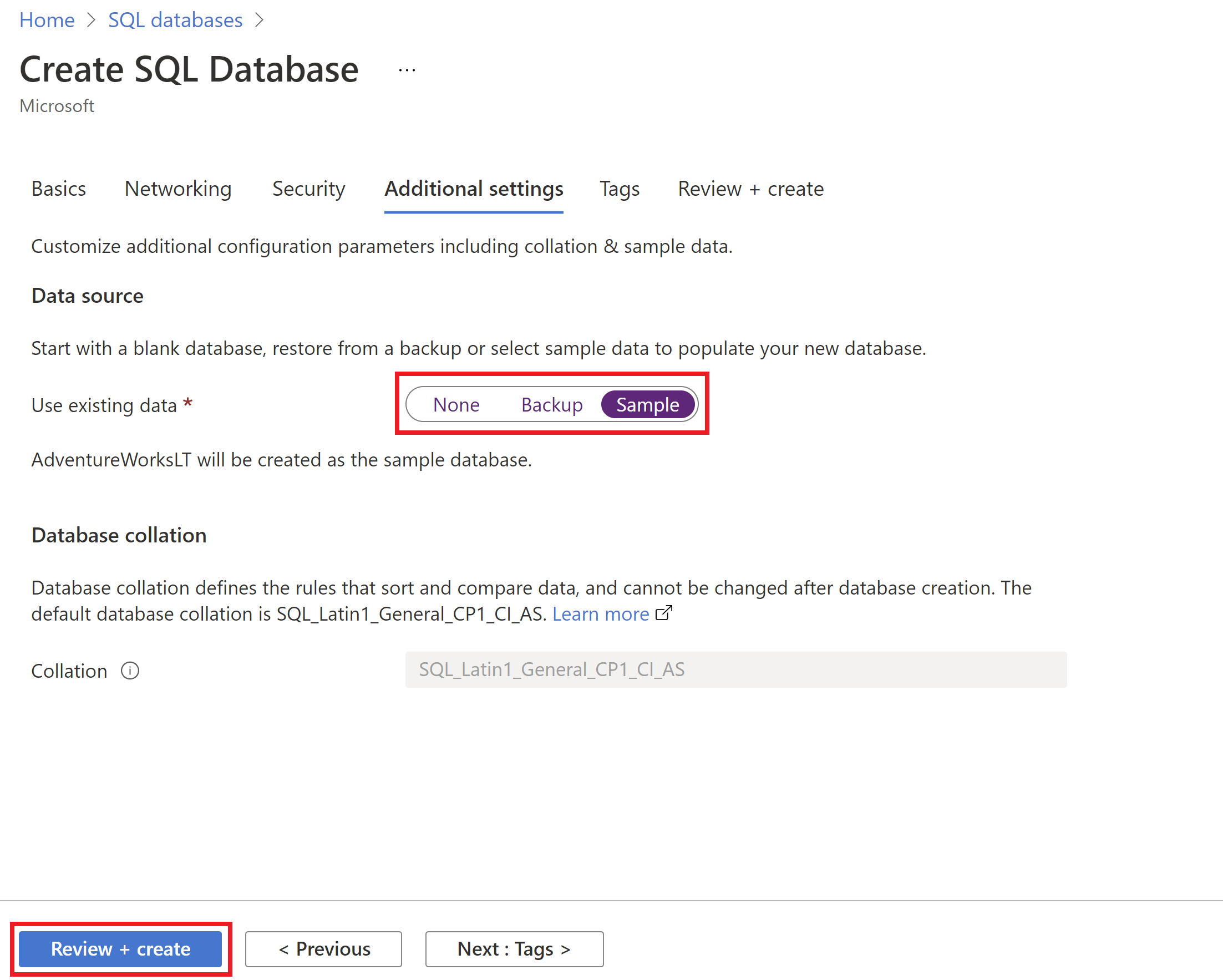
AdventureWorksLTför PoC med samma PoC-resursgrupp. Oroa dig inte, i slutet av den här självstudien rensar vi alla resurser i den nya PoC-resursgruppen.Du kan använda Azure-portalen för att distribuera Azure SQL Database. När du skapar Azure SQL Database går du till fliken Ytterligare inställningar och väljer Exempel för alternativet Använd befintliga data.
Slutligen, på fliken Taggar i den nya Azure SQL Database, tillhandahöll utvecklingsteamet taggar metadata för den här Azure-resursen, till exempel Ägare eller ServiceClass eller WorkloadName.

Skapa programmet
Därefter skapade utvecklingsteamet ett enkelt Python-program som öppnar en anslutning till Azure SQL Database och returnerar en lista över produkter. Den här koden ersätts med mer komplexa funktioner och kan även innehålla fler än ett program som distribueras till Kubernetes Pods i produktion för en robust, manifestdriven metod för programlösningar.
Teamet skapade en enkel textfil med namnet
.envför att lagra variabler för serveranslutningarna och annan information. Med hjälp avpython-dotenvbiblioteket kan de sedan separera variablerna från Python Code. Det här är en vanlig metod för att hålla hemligheter och annan information borta från själva koden.SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseNameVarning
För tydlighetens skull och enkelhet använder det här programmet en konfigurationsfil som läses från Python. Eftersom koden distribueras med containern kanske anslutningsinformationen kan härledas från innehållet. Du bör noga överväga de olika metoderna för att arbeta med säkerhet, anslutningar och hemligheter och fastställa den bästa nivån och mekanismen som du bör använda för vårt program. Välj alltid den högsta säkerhetsnivån och till och med flera nivåer för att säkerställa att ditt program är säkert. Du har flera alternativ för att arbeta med hemlig information, till exempel anslutningssträng och liknande, och följande lista visar några av dessa alternativ.
Mer information finns i Säkerhet för Azure SQL Database.
- En annan metod för att arbeta med hemligheter i Python är att använda python-secrets-biblioteket.
- Granska Docker-säkerhet och -hemligheter.
- Granska Kubernetes-hemligheter.
- Du kan också lära dig mer om Microsoft Entra-autentisering (tidigare Azure Active Directory).
Teamet skrev sedan PoC-programmet och kallade det
app.py.Följande skript utför följande steg:
- Konfigurera biblioteken för konfigurationen och baswebbgränssnitten.
- Läs in variablerna från
.envfilen. - Skapa Flask-RESTful-programmet.
- Gå till Anslutningsinformation för Azure SQL Database med hjälp av filvärdena
config.ini. - Skapa en anslutning till Azure SQL Database med hjälp av filvärdena
config.ini. - Anslut till Azure SQL Database med hjälp av
pyodbcpaketet. - Skapa SQL-frågan som ska köras mot databasen.
- Skapa klassen som ska användas för att returnera data från API:et.
- Ange API-slutpunkten till
Productsklassen. - Starta slutligen appen på flaskport 5000 som standard.
# Set up the libraries for the configuration and base web interfaces from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api import pyodbc # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the config.ini file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection to Azure SQL Database using the config.ini file values ServerName = config.get('Connection', 'SQL_SERVER_ENDPOINT') DatabaseName = config.get('Connection', 'SQL_SERVER_DATABASE') UserName = config.get('Connection', 'SQL_SERVER_USERNAME') PasswordValue = config.get('Connection', 'SQL_SERVER_PASSWORD') # Connect to Azure SQL Database using the pyodbc package # Note: You may need to install the ODBC driver if it is not already there. You can find that at: # https://video2.skills-academy.com/sql/connect/odbc/download-odbc-driver-for-sql-server connection = pyodbc.connect(f'Driver=ODBC Driver 17 for SQL Server;Server={ServerName};Database={DatabaseName};uid={UserName};pwd={PasswordValue}') # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)De har kontrollerat att programmet körs lokalt och returnerar en sida till
http://localhost:5000/products.
Viktigt!
När du skapar produktionsprogram ska du inte använda administratörskontot för att komma åt databasen. Mer information finns i mer information om hur du konfigurerar ett konto för ditt program. Koden i den här artikeln är förenklad så att du snabbt kan komma igång med program med Hjälp av Python och Kubernetes i Azure.
Mer realistiskt kan du använda en innesluten databasanvändare med skrivskyddade behörigheter, eller en inloggnings- eller innesluten databasanvändare som är ansluten till en användartilldelad hanterad identitet med skrivskyddade behörigheter.
Mer information finns i ett fullständigt exempel på hur du skapar API med Python och Azure SQL Database.

Distribuera programmet till en Docker-container
En container är ett reserverat, skyddat utrymme i ett databehandlingssystem som tillhandahåller isolering och inkapsling. Om du vill skapa en container använder du en manifestfil, som helt enkelt är en textfil som beskriver de binärfiler och den kod som du vill innehålla. Med hjälp av en Container Runtime (till exempel Docker) kan du sedan skapa en binär avbildning som innehåller alla filer som du vill köra och referera till. Därifrån kan du "köra" den binära avbildningen och det kallas för en container, som du kan referera till som om det vore ett fullständigt databehandlingssystem. Det är ett mindre, enklare sätt att abstrahera programkörningar och miljö än att använda en fullständig virtuell dator. Mer information finns i Containrar och Docker.
Teamet började med en DockerFile (manifestet) som lagrar elementen i det teamet vill använda. De börjar med en python-basavbildning som redan har biblioteken pyodbc installerade och kör sedan alla kommandon som krävs för att innehålla programmet och konfigurationsfilen i föregående steg.
Följande Dockerfile har följande steg:
- Börja med en container binärfil som redan har Python och
pyodbcinstallerat. - Skapa en arbetskatalog för programmet.
- Kopiera all kod från den aktuella katalogen till
WORKDIR. - Installera de bibliotek som krävs.
- När containern startar kör du programmet och öppnar alla TCP/IP-portar.
# syntax=docker/dockerfile:1
# Start with a Container binary that already has Python and pyodbc installed
FROM laudio/pyodbc
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
Med den filen på plats släppte teamet till en kommandotolk i kodningskatalogen och körde följande kod för att skapa den binära avbildningen från manifestet och sedan ett annat kommando för att starta containern:
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
Återigen testar http://localhost:5000/products teamet länken för att säkerställa att containern kan komma åt databasen, och de ser följande retur:

Distribuera avbildningen till ett Docker-register
Containern fungerar nu, men är bara tillgänglig på utvecklarens dator. Utvecklingsteamet vill göra programmet Image tillgängligt för resten av företaget och sedan vidare till Kubernetes för produktionsdistribution.
Lagringsområdet för Container Images kallas för en lagringsplats och det kan finnas både offentliga och privata lagringsplatser för containeravbildningar. I själva verket använde AdvenureWorks en offentlig avbildning för Python-miljön i sin Dockerfile.
Teamet vill styra åtkomsten till avbildningen och i stället för att lägga ut den på webben bestämmer de sig för att själva vara värdar för den, men i Microsoft Azure där de har fullständig kontroll över säkerhet och åtkomst. Du kan läsa mer om Microsoft Azure Container Registry här.
När utvecklingsteamet återgår till kommandoraden använder az CLI de för att lägga till en containerregistertjänst, aktivera ett administrationskonto, ställa in det på anonyma "pulls" under testfasen och ange en inloggningskontext till registret:
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
Den här kontexten används i efterföljande steg.
Tagga den lokala Docker-avbildningen för att förbereda den för uppladdning
Nästa steg är att skicka det lokala programmet Container Image till Tjänsten Azure Container Registry (ACR) så att den är tillgänglig i molnet.
- I följande exempelskript använder teamet Docker-kommandona för att lista avbildningarna på datorn.
- De använder
az CLIverktyget för att visa bilder i ACR-tjänsten. - De använder Docker-kommandot för att "tagga" avbildningen med målnamnet för den ACR som de skapade i föregående steg och för att ange ett versionsnummer för rätt DevOps.
- Slutligen listar de den lokala avbildningsinformationen igen för att säkerställa att taggen tillämpas korrekt.
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
När koden är skriven och testad kan Dockerfile, avbildningen och containern köras och testas, ACR-tjänsten konfigureras och alla taggar som tillämpas kan teamet ladda upp avbildningen till ACR-tjänsten.
De använder kommandot Docker "push" för att skicka filen och sedan az CLI verktyget för att säkerställa att avbildningen har lästs in:
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
Distribuera till Kubernetes
Teamet kan helt enkelt köra containrar och distribuera programmet till lokala och molnbaserade miljöer. De vill dock lägga till flera kopior av programmet för skalning och tillgänglighet, lägga till andra containrar som utför olika uppgifter och lägga till övervakning och instrumentering i hela lösningen.
För att gruppera containrar i en fullständig lösning bestämde sig teamet för att använda Kubernetes. Kubernetes körs lokalt och på alla större molnplattformar. Microsoft Azure har en fullständig hanterad miljö för Kubernetes, kallad Azure Kubernetes Service (AKS). Läs mer om AKS med utbildningsvägen Introduktion till Kubernetes på Azure.
Med hjälp av az CLI verktyget lägger teamet till AKS i samma resursgrupp som de skapade tidigare. Med ett enda az kommando utför utvecklingsteamet följande steg:
- Lägg till två "noder" eller beräkningsmiljöer för återhämtning i testfasen
- Generera SSH-nycklar automatiskt för åtkomst till miljön
- Bifoga ACR-tjänsten som de skapade i föregående steg så att AKS-klustret kan hitta de avbildningar som de vill använda för distributionen
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
Kubernetes använder ett kommandoradsverktyg för att komma åt och styra ett kluster med namnet kubectl. Teamet använder az CLI verktyget för att ladda ned kubectl verktyget och installera det:
az aks install-cli
Eftersom de har en anslutning till AKS just nu kan de be den att skicka SSH-nycklarna för anslutning som ska användas när de kör kubectl verktyget:
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
Dessa nycklar lagras i en fil med namnet .config i användarens katalog. Med den säkerhetskontextuppsättningen använder kubectl get nodes teamet för att visa noderna i klustret:
kubectl get nodes
Nu använder az CLI teamet verktyget för att lista avbildningarna i ACR-tjänsten:
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
Nu kan de skapa manifestet som Kubernetes använder för att styra distributionen. Det här är en textfil som lagras i yaml-format. Här är den kommenterade texten i flask2sql.yaml filen:
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCIP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
Med den flask2sql.yaml definierade filen kan teamet distribuera programmet till det AKS-kluster som körs. Det är gjort med kubectl apply kommandot, som som du minns fortfarande har en säkerhetskontext till klustret. kubectl get service Sedan skickas kommandot för att titta på klustret när det skapas.
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
Efter en liten stund returnerar kommandot "watch" en extern IP-adress. Då trycker teamet på CTRL-C för att bryta klockkommandot och registrerar lastbalanserarens externa IP-adress.
Testa programmet
Med den IP-adress (slutpunkt) som de fick i det senaste steget kontrollerar teamet att de har samma utdata som det lokala programmet och Docker-containern:
Rensa
När programmet har skapats, redigerats, dokumenterats och testats kan teamet nu "riva ner" programmet. Genom att behålla allt i en enskild resursgrupp i Microsoft Azure är det enkelt att ta bort PoC-resursgruppen med hjälp av az CLI verktyget:
az group delete -n ReplaceWith_PoCResourceGroupName -y
Kommentar
Om du har skapat din Azure SQL Database i en annan resursgrupp och du inte längre behöver den kan du ta bort den med Hjälp av Azure-portalen.
Teammedlemmen som leder PoC-projektet använder Microsoft Windows som arbetsstation och vill behålla hemlighetsfilen från Kubernetes men ta bort den från systemet som aktiv plats. De kan helt enkelt kopiera filen till en config.old textfil och sedan ta bort den:
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config