Hyperskala tjänstnivå
Gäller för:![]() Azure SQL Database
Azure SQL Database
Azure SQL Database baseras på SQL Server Database Engine-arkitekturen som justeras för molnmiljön för att säkerställa hög tillgänglighet även i händelse av infrastrukturfel. Det finns tre alternativ på tjänstnivå i köpmodellen för virtuella kärnor för Azure SQL Database:
- Generell användning
- Affärskritisk
- Hyperskala
Tjänstnivån Hyperskala är lämplig för alla arbetsbelastningstyper. Dess molnbaserade arkitektur ger oberoende skalbar beräkning och lagring för att stödja den bredaste variationen av traditionella och moderna program. Beräknings- och lagringsresurser i Hyperskala överskrider avsevärt de resurser som är tillgängliga på nivåerna Generell användning och Affärskritisk.
Kommentar
- Mer information om tjänstnivåerna Generell användning och Affärskritisk i den vCore-baserade inköpsmodellen finns i Allmänt syfte och Affärskritisk tjänstnivåer. En jämförelse av den VCore-baserade inköpsmodellen med den DTU-baserade köpmodellen finns i Jämföra virtuella kärnor och DTU-baserade köpmodeller för Azure SQL Database.
- Tjänstnivån Hyperskala är för närvarande endast tillgänglig för Azure SQL Database och inte för Azure SQL Managed Instance.
Vilka är hyperskala-funktionerna?
Tjänstnivån Hyperskala i Azure SQL Database innehåller följande ytterligare funktioner:
- Snabb uppskalning – du kan i konstant tid skala upp dina beräkningsresurser för att hantera tunga arbetsbelastningar vid behov och sedan skala ned beräkningsresurserna igen när de inte behövs.
- Snabb utskalning – du kan etablera en eller flera skrivskyddade repliker för avlastning av läsarbetsbelastningen och för användning som frekventa väntelägen.
- Automatisk uppskalning, nedskalning och fakturering för beräkning baserat på användning med serverlös beräkning.
- Optimerat pris/prestanda för en grupp Hyperskala-databaser med varierande resurskrav med elastiska pooler (i förhandsversion).
- Automatisk skalning av lagring med stöd för upp till 100 TB databas eller elastisk poolstorlek.
- Högre övergripande prestanda på grund av högre dataflöde för transaktionsloggar och snabbare transaktionsincheckningstider oavsett datavolymer.
- Snabba säkerhetskopieringar av databaser (baserat på ögonblicksbilder av filer) oavsett storlek utan I/O-påverkan på beräkningsresurser.
- Snabb databasåterställning eller kopior (baserat på ögonblicksbilder av filer) på några minuter i stället för timmar eller dagar.
Tjänstnivån Hyperskala tar bort många av de praktiska gränser som traditionellt sett setts i molndatabaser. Om de flesta andra databaser begränsas av de resurser som är tillgängliga i en enda nod har databaser på tjänstnivån Hyperskala inga sådana gränser. Med sin flexibla lagringsarkitektur växer lagringen efter behov. Faktum är att Hyperskala-databaser inte skapas med en definierad maxstorlek. En Hyperskala-databas växer efter behov – och du debiteras endast för den allokerade lagringskapaciteten. För läsintensiva arbetsbelastningar ger tjänstnivån Hyperskala snabb utskalning genom att etablera ytterligare repliker efter behov för avlastning av läsarbetsbelastningar.
Dessutom är den tid som krävs för att skapa databassäkerhetskopior eller för att skala upp eller ned inte längre knuten till datavolymen i databasen. Hyperskala-databaser säkerhetskopieras nästan omedelbart. Du kan också skala en databas i tiotals terabyte upp eller ned inom några minuter på den etablerade beräkningsnivån eller använda serverlös för att skala beräkning automatiskt. Den här funktionen befriar dig från problem med att bli inrutad av dina första konfigurationsalternativ.
Mer information om beräkningsstorlekarna för tjänstnivån Hyperskala finns i Egenskaper för tjänstnivå.
Vem bör överväga tjänstnivån Hyperskala
Tjänstnivån Hyperskala är avsedd för alla kunder som behöver högre prestanda och tillgänglighet, snabb säkerhetskopiering och återställning samt/eller snabb skalbarhet för lagring och beräkning. Detta inkluderar kunder som flyttar till molnet för att modernisera sina program samt kunder som redan använder andra tjänstnivåer i Azure SQL Database. Tjänstnivån Hyperskala stöder ett brett utbud av databasarbetsbelastningar, från ren OLTP till ren analys. Den är optimerad för OLTP- och HTAP-arbetsbelastningar (hybridtransaktions- och analysbearbetning).
Kommentar
Elastiska pooler för Hyperskala är för närvarande i förhandsversion.
Prismodell för hyperskala
Kommentar
Förenklad prissättning för Azure SQL Database Hyperscale har kommit! Granska den nya prisnivån för Azure SQL Database Hyperscale-meddelande och information om prisändringar finns i Azure SQL Database Hyperscale – lägre, förenklad prissättning!.
Tjänstnivån Hyperskala är endast tillgänglig i modellen med virtuella kärnor. För att anpassa till den nya arkitekturen skiljer sig prismodellen något från tjänstnivåerna Generell användning eller Affärskritisk:
Etablerad beräkning:
Priset för beräkningsenheter i Hyperskala är per replik. Användare kan anpassa det totala antalet sekundära repliker med hög tillgänglighet från 0 till 4, beroende på tillgänglighets- och skalbarhetskrav, och skapa upp till 30 namngivna repliker för att stödja en mängd olika lässkalningsarbetsbelastningar.
Serverlös beräkning:
Serverlös beräkningsfakturering baseras på användning. Mer information finns i Serverlös beräkningsnivå för Azure SQL Database.
Lagring:
Du behöver inte ange den maximala datastorleken när du konfigurerar en Hyperskala-databas. På hyperskalenivå debiteras du för lagring av databasen baserat på faktisk allokering. Lagring allokeras automatiskt mellan 10 GB och 100 TB och växer i steg om 10 GB efter behov.
Mer information om prissättning för Hyperskala finns i Prissättning för Azure SQL Database
Jämför resursgränser
De vCore-baserade tjänstnivåerna är differentierade baserat på databastillgänglighet, lagringstyp, prestanda och maximal lagringsstorlek. Dessa skillnader beskrivs i följande tabell:
| ㅤ | Generell användning | Affärskritisk | Hyperskala |
|---|---|---|---|
| Bäst för | Erbjuder budgetorienterade alternativ för balanserad beräkning och lagring. | OLTP-program med hög transaktionshastighet och låg I/O-svarstid. Ger hög motståndskraft mot fel och snabba redundansväxlingar med hjälp av flera repliker med frekvent vänteläge. | Det bredaste utbudet av arbetsbelastningar. Lagringsstorlek för automatisk skalning upp till 100 TB, snabb lodrät och vågrät beräkningsskalning, snabb databasåterställning. |
| Beräkningsstorlek | 2 till 128 virtuella kärnor | 2 till 128 virtuella kärnor | 2 till 128 virtuella kärnor 1 |
| Lagringstyp | Premium-fjärrlagring (per instans) | Supersnabb lokal SSD-lagring (per instans) | Frikopplad lagring med lokal SSD-cache (per beräkningsreplik) |
| Lagringsstorlek1 | 1 GB – 4 TB | 1 GB – 4 TB | 10 GB – 100 TB |
| IOPS | 320 IOPS per virtuell kärna med maximalt 16 000 IOPS | 4 000 IOPS per virtuell kärna med maximalt 327 680 IOPS | 327 680 IOPS med maximal lokal SSD Hyperskala är en arkitektur med flera nivåer med cachelagring på flera nivåer. Effektiv IOPS beror på arbetsbelastningen. |
| Minne/virtuell kärna | 5,1 GB | 5,1 GB | 5,1 GB eller 10,2 GB |
| Tillgänglighet | En replik, ingen utskalning, zonredundant HA | Tre repliker, en läsbar skalbar, zonredundant HA | Flera repliker, upp till fyra läsbara skalbara, zonredundanta HA |
| Säkerhetskopior | Ett val av lokalt redundant lagring (LRS), zonredundant (ZRS) eller geo-redundant lagring (GRS) Kvarhållning på 1–35 dagar (sju dagar som standard) med upp till 10 års långsiktig kvarhållning tillgänglig |
Ett val av lokalt redundant lagring (LRS), zonredundant (ZRS) eller geo-redundant lagring (GRS) Kvarhållning på 1–35 dagar (sju dagar som standard) med upp till 10 års långsiktig kvarhållning tillgänglig |
Ett val av lokalt redundant lagring (LRS), zonredundant (ZRS) eller geo-redundant lagring (GRS) Kvarhållning på 1–35 dagar (sju dagar som standard) med upp till 10 års långsiktig kvarhållning tillgänglig |
| Priser/fakturering | vCore, reserverad lagring och lagring av säkerhetskopior debiteras. IOPS debiteras inte. |
vCore, reserverad lagring och lagring av säkerhetskopior debiteras. IOPS debiteras inte. |
virtuella kärnor för varje replik, allokerad datalagring och lagring av säkerhetskopior debiteras. IOPS debiteras inte. |
| Rabattmodeller | Reserverade instanser Azure Hybrid-förmån (inte tillgängligt för dev/test-prenumerationer) Enterprise - och Betala per användning Dev/Test-prenumerationer |
Reserverade instanser Azure Hybrid-förmån (inte tillgängligt för dev/test-prenumerationer) Enterprise - och Betala per användning Dev/Test-prenumerationer |
Reserverade instanser Azure Hybrid-förmån (inte tillgängligt för dev/test-prenumerationer) 2 Enterprise - och Betala per användning Dev/Test-prenumerationer |
1Översikt över elastiska hyperskalapooler i Azure SQL Database är för närvarande i förhandsversion.
2 Förenklad prissättning för SQL Database Hyperscale kommer snart. Mer information finns i prissättningsbloggen för Hyperskala.
Beräkningsresurser
| Konfiguration av maskinvara | Processor | Minne |
|---|---|---|
| Standardserie (Gen5) | Etablerad beräkning - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)1, Intel® 8272CL (Cascade Lake) 2,5 GHz1, Intel® Xeon Platinum 8370C (Ice Lake)1, AMD EPYC 7763v (Milano) processorer – Etablera upp till 80 virtuella kärnor (hypertrådad) Serverlös databearbetning - Intel® E5-2673 v4 (Broadwell) 2,3 GHz, Intel® SP-8160 (Skylake)1, Intel® 8272CL (Cascade Lake) 2,5 GHz1, Intel Xeon® Platinum 8370C (Ice Lake)1, AMD EPYC 7763v (Milano) processorer – Skala upp till 80 virtuella kärnor automatiskt (hypertrådad) – Förhållandet mellan minne och virtuell kärna anpassas dynamiskt till minnes- och CPU-användning baserat på efterfrågan på arbetsbelastningar och kan vara så högt som 24 GB per virtuell kärna. Vid en viss tidpunkt kan till exempel en arbetsbelastning använda och faktureras för 240 GB minne och endast 10 virtuella kärnor. |
Etablerad beräkning - 5,1 GB per virtuell kärna – Etablera upp till 625 GB Serverlös databearbetning – Skala upp till 24 GB per virtuell kärna automatiskt – Skala upp till högst 240 GB automatiskt |
| Premium-serien | - Intel® Xeon Platinum 8370C (Ice Lake), AMD EPYC 7763v (Milano) processorer – Etablera upp till 128 virtuella kärnor (hypertrådad) |
- 5,1 GB per virtuell kärna |
| Minnesoptimerad i Premium-serien | - Intel® Xeon Platinum 8370C (Ice Lake), AMD EPYC 7763v (Milano) processorer – Etablera upp till 80 virtuella kärnor (hypertrådad) |
- 10,2 GB per virtuell kärna |
1 I vyn sys.dm_user_db_resource_governance dynamisk hantering visas maskinvarugenerering för databaser med Intel® SP-8160-processorer (Skylake) som Gen6, maskinvarugenerering för databaser med Intel® 8272CL (Cascade Lake) visas som Gen7 och maskinvarugenerering för databaser som använder Intel Xeon® Platinum 8370C (Ice Lake) eller AMD® EPYC® 7763v (Milano) visas som Gen8. För en viss beräkningsstorlek och maskinvarukonfiguration är resursgränserna desamma oavsett cpu-typ. Mer information finns i resursgränser för enskilda databaser och elastiska pooler.
Serverlös stöds endast på Gen5-maskinvara (Standard-serien).
Arkitektur för distribuerade funktioner
Hyperskala separerar frågebearbetningsmotorn från de komponenter som ger långsiktig lagring och hållbarhet för data. Med den här arkitekturen kan du skala lagringskapaciteten så smidigt som det behövs (det ursprungliga målet är 100 TB) och möjligheten att skala beräkningsresurser snabbt.
Följande diagram illustrerar den funktionella Hyperskala-arkitekturen:
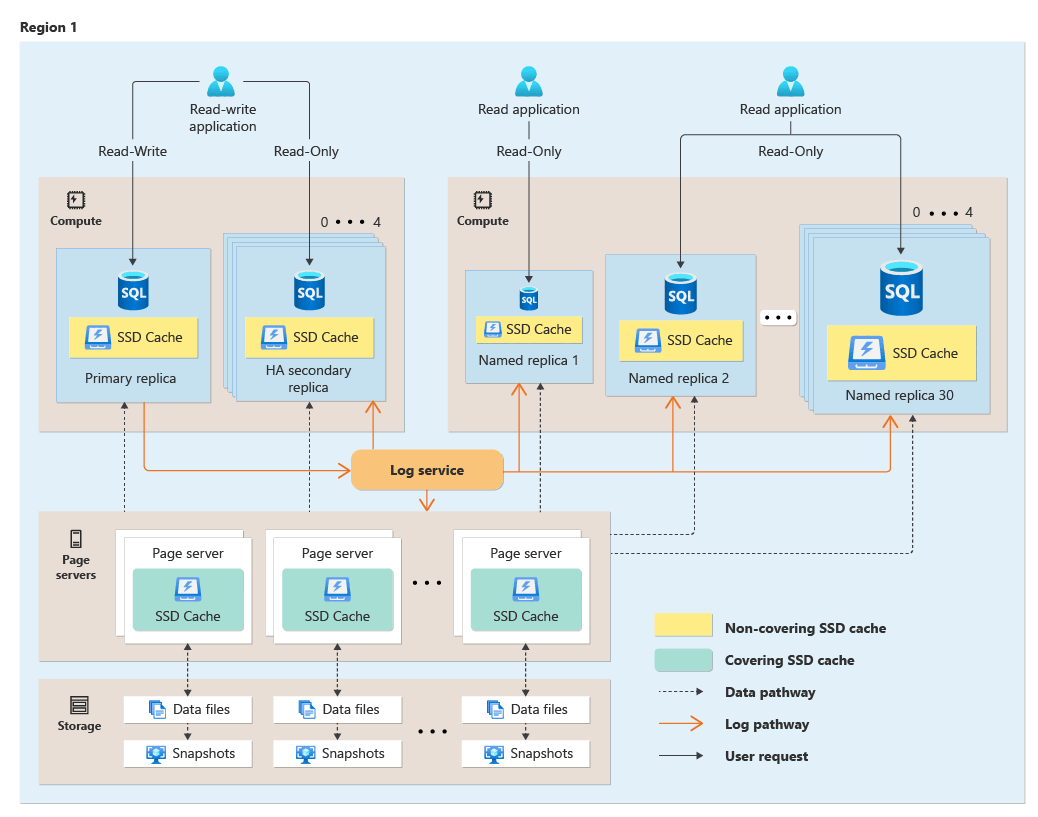
Läs mer om arkitekturen för distribuerade funktioner i Hyperskala.
Skalnings- och prestandafördelar
Med möjligheten att snabbt starta upp/ned ytterligare skrivskyddade beräkningsnoder tillåter Hyperskala-arkitekturen betydande lässkalningsfunktioner och kan även frigöra den primära beräkningsnoden för att hantera fler skrivbegäranden. Dessutom kan beräkningsnoderna skalas upp/ned snabbt på grund av arkitekturen för delad lagring i Hyperskala-arkitekturen. Skrivskyddade beräkningsnoder i Hyperskala är också tillgängliga på den serverlösa beräkningsnivån, som automatiskt skalar beräkning baserat på efterfrågan på arbetsbelastningar.
Skapa och hantera Hyperskala-databaser
Du kan skapa och hantera Hyperskala-databaser med hjälp av Azure-portalen, Transact-SQL, PowerShell och Azure CLI. Mer information finns i Snabbstart: Skapa en Hyperskala-databas.
| Åtgärd | Detaljer | Läs mer |
|---|---|---|
| Skapa en Hyperskala-databas | Hyperskala-databaser är endast tillgängliga med hjälp av den vCore-baserade köpmodellen. | Hitta exempel för att skapa en Hyperskala-databas i Snabbstart: Skapa en Hyperskala-databas i Azure SQL Database. |
| Uppgradera en befintlig databas till Hyperskala | Att migrera en befintlig databas i Azure SQL Database till Hyperskala-nivån är en storlek på dataåtgärden. | Lär dig hur du migrerar en befintlig databas till Hyperskala. |
| Omvänd migrering av en Hyperskala-databas till tjänstnivån Generell användning | Om du tidigare migrerade en befintlig Azure SQL Database till tjänstnivån Hyperskala kan du ångra migreringen av databasen till tjänstnivån Generell användning inom 45 dagar efter den ursprungliga migreringen till Hyperskala. Om du vill migrera databasen till en annan tjänstnivå, till exempel Affärskritisk, måste du först ångra migreringen till tjänstnivån Generell användning och sedan ändra tjänstnivån. |
Lär dig hur du omvänt migrerar från Hyperskala, inklusive begränsningarna för omvänd migrering. |
Databas med hög tillgänglighet i Hyperskala
Precis som i alla andra tjänstnivåer garanterar Hyperskala datahållbarhet för incheckade transaktioner oavsett tillgänglighet för beräkningsrepliker. Omfattningen av stilleståndstid på grund av att den primära repliken blir otillgänglig beror på typen av redundans (planerad eller oplanerad), om zonredundans har konfigurerats och på förekomsten av minst en replik med hög tillgänglighet. I en planerad redundansväxling (till exempel en underhållshändelse) skapar systemet antingen den nya primära repliken innan en redundansväxling initieras eller använder en befintlig replik med hög tillgänglighet som redundansmål. I en oplanerad redundansväxling (till exempel ett maskinvarufel på den primära repliken) använder systemet en replik med hög tillgänglighet som ett redundansmål om det finns en sådan, eller skapar en ny primär replik från poolen med tillgänglig beräkningskapacitet. I det senare fallet är stilleståndstiden längre på grund av extra steg som krävs för att skapa den nya primära repliken.
Du kan välja ett underhållsperiod som gör att du kan göra påverkanskänsliga underhållshändelser förutsägbara och mindre störande för din arbetsbelastning.
Mer information om serviceavtal för Hyperskala finns i SLA för Azure SQL Database.
Säkerhetskopiera och återställ
Säkerhetskopierings- och återställningsåtgärder för Hyperskala-databaser är filögonblicksbaserade. Detta gör att dessa åtgärder kan vara nästan omedelbart. Eftersom Hyperskala-arkitekturen använder lagringslagret för säkerhetskopiering och återställning minskar bearbetningsbelastningen och prestandapåverkan på beräkningsrepliker avsevärt. Läs mer i Hyperskala-säkerhetskopior och lagringsredundans.
Haveriberedskap för Hyperskala-databaser
Om du behöver återställa en Hyperskala-databas i Azure SQL Database till en annan region än den som den för närvarande finns i, som en del av en haveriberedskapsåtgärd eller detaljgranskning, omlokalisering eller någon annan anledning, är den primära metoden att göra en geo-återställning av databasen. Geo-återställning är endast tillgängligt när geo-redundant lagring (RA-GRS) har valts för lagringsredundans.
Läs mer om hur du återställer en Hyperskala-databas till en annan region.
Kända begränsningar
Det här är de aktuella begränsningarna för tjänstnivån Hyperskala. Vi arbetar aktivt med att ta bort så många av dessa begränsningar som möjligt.
| Problem | beskrivning |
|---|---|
| Återställa databasen från andra tjänstnivåer | En icke-Hyperskala-databas kan inte återställas som en Hyperskala-databas och en Hyperskala-databas kan inte återställas som en icke-Hyperskala-databas. För databaser som migreras till Hyperskala från andra Azure SQL Database-tjänstnivåer sparas säkerhetskopieringar före migreringen under kvarhållningsperioden för säkerhetskopior för källdatabasen, inklusive långsiktiga kvarhållningsprinciper. Återställning av en säkerhetskopia före migreringen inom kvarhållningsperioden för säkerhetskopian av databasen stöds via kommandoraden. Du kan återställa dessa säkerhetskopior till valfri tjänstnivå som inte är hyperskala. |
| Elastiska pooler | Elastiska pooler är nu i förhandsversion. |
| Migrering av databaser med minnesinterna OLTP-objekt | Hyperskala stöder en delmängd av Minnesinterna OLTP-objekt, inklusive minnesoptimerade tabelltyper, tabellvariabler och inbyggda kompilerade moduler. Men när några minnesinterna OLTP-objekt finns i databasen som migreras stöds inte migrering från Premium- och Affärskritisk-tjänstnivåer till Hyperskala. Om du vill migrera en sådan databas till Hyperskala måste alla minnesinterna OLTP-objekt och deras beroenden tas bort. När databasen har migrerats kan dessa objekt återskapas. Varaktiga och icke-hållbara minnesoptimerade tabeller stöds för närvarande inte i Hyperskala och måste ändras till disktabeller. |
| Krymp databas | DBCC SHRINKDATABASE, DBCC SHRINKFILE eller inställning AUTO_SHRINK till PÅ på databasnivå stöds för närvarande inte för Hyperskala-databaser. |
| Kontroll av databasintegritet | DBCC CHECKDB stöds inte för närvarande för Hyperskala-databaser. DBCC CHECKTABLE ('TableName') MED TABLOCK och DBCC CHECKFILEGROUP WITH TABLOCK kan användas som en lösning. Mer information om dataintegritetshantering i Azure SQL Database finns i Dataintegritet i Azure SQL Database . |
| Elastiska jobb | Det går inte att använda en Hyperskala-databas som jobbdatabas. Elastiska jobb kan dock rikta in sig på Hyperskala-databaser på samma sätt som andra databaser i Azure SQL Database. |
| Datasynkronisering | Det går inte att använda en Hyperskala-databas som en hubb- eller synkroniseringsmetadatadatabas. En Hyperskala-databas kan dock vara en medlemsdatabas i en datasynkroniseringstopologi. |
| Maskinvara i Premium-serien i Hyperskala-tjänstnivå | Premium-serien och minnesoptimerad premiumseriemaskinvara stöder för närvarande inte: – Zonredundans – Serverlös beräkningsnivå. |
| Regional tillgänglighet | Minnesoptimerad maskinvara i Premium-serien och Premium-serien är tillgänglig i begränsade Azure-regioner. En lista finns i Hyperskala premiumserietillgänglighet. |
Relaterat innehåll
- Vanliga frågor och svar om Hyperskala
- Jämföra virtuella kärnor och DTU-baserade köpmodeller för Azure SQL Database
- Resurshantering i Azure SQL Database
- Resursbegränsningar för enskilda databaser med hjälp av vCore-inköpsmodellen
- Jämförelse av funktioner: Azure SQL Database och Azure SQL Managed Instance
- Arkitektur för distribuerade funktioner i hyperskala
- Hantera en Hyperskala-databas