Funktioner för flera modeller i Azure SQL Database och SQL Managed Instance
Gäller för:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Med databaser med flera modeller kan du lagra och arbeta med data i flera format, till exempel relationsdata, diagram, JSON- eller XML-dokument, rumsliga data och nyckel/värde-par.
Azure SQL-serien med produkter använder en relationsmodell som ger bästa prestanda för en mängd olika allmänna program. Azure SQL-produkter som Azure SQL Database och SQL Managed Instance är dock inte begränsade till relationsdata. De gör att du kan använda icke-relationsformat som är tätt integrerade i relationsmodellen.
Överväg att använda funktionerna för flera modeller i Azure SQL i följande fall:
- Du har viss information eller strukturer som passar bättre för NoSQL-modeller och du vill inte använda en separat NoSQL-databas.
- En majoritet av dina data är lämpliga för en relationsmodell och du måste modellera vissa delar av dina data i NoSQL-stil.
- Du vill använda transact-SQL-språket för att fråga och analysera både relations- och NoSQL-data och sedan integrera dessa data med verktyg och program som kan använda SQL-språket.
- Du vill använda databasfunktioner som minnesintern teknik för att förbättra prestanda för din analys eller bearbetningen av dina NoSQL-datastrukturer. Du kan använda transaktionsreplikering eller läsbara repliker för att skapa kopior av dina data och avlasta vissa analysarbetsbelastningar från den primära databasen.
I följande avsnitt beskrivs de viktigaste funktionerna för flera modeller i Azure SQL.
Kommentar
Du kan använda JSONPath-uttryck, XQuery/XPath-uttryck, rumsliga funktioner och diagramfrågeuttryck i samma Transact-SQL-fråga för att få åtkomst till alla data som du har lagrat i databasen. Alla verktyg eller programmeringsspråk som kan köra Transact-SQL-frågor kan också använda det frågegränssnittet för att komma åt data med flera modeller. Det här är den viktigaste skillnaden från databaser med flera modeller, till exempel Azure Cosmos DB, som tillhandahåller specialiserade API:er för datamodeller.
Diagramfunktioner
Azure SQL-produkter erbjuder grafdatabasfunktioner för att modellera många-till-många-relationer i en databas. Ett diagram är en samling noder (eller hörn) och kanter (eller relationer). En nod representerar en entitet (till exempel en person eller en organisation). En kant representerar en relation mellan de två noder som den ansluter (till exempel gillar eller vänner).
Här är några funktioner som gör en grafdatabas unik:
- Kanter är förstklassiga entiteter i en grafdatabas. De kan ha attribut eller egenskaper associerade med dem.
- En enda kant kan flexibelt ansluta flera noder i en grafdatabas.
- Du kan enkelt uttrycka mönstermatchning och navigeringsfrågor med flera hopp.
- Du kan enkelt uttrycka transitiv stängning och polymorfa frågor.
Diagramrelationer och diagramfrågefunktioner är integrerade i Transact-SQL och får fördelarna med att använda SQL Server-databasmotorn som det grundläggande databashanteringssystemet. Graph-funktioner använder transact-SQL-standardfrågor som utökats med grafoperatorn MATCH för att köra frågor mot grafdata.
En relationsdatabas kan uppnå allt som en grafdatabas kan. En grafdatabas kan dock göra det enklare att uttrycka vissa frågor. Ditt beslut att välja det ena framför det andra kan baseras på följande faktorer:
- Du måste modellera hierarkiska data där en nod kan ha flera överordnade, så du kan inte använda datatypen hierarchyId.
- Ditt program har komplexa många-till-många-relationer. När programmet utvecklas läggs nya relationer till.
- Du måste analysera sammankopplade data och relationer.
- Du vill använda grafspecifika T-SQL-sökvillkor, till exempel SHORTEST_PATH.
JSON-funktioner
I Azure SQL-produkter kan du parsa och fråga efter data som representeras i JSON-format (JavaScript Object Notation) och exportera dina relationsdata som JSON-text. JSON är en viktig funktion i SQL Server-databasmotorn.
Med JSON-funktioner kan du placera JSON-dokument i tabeller, transformera relationsdata till JSON-dokument och omvandla JSON-dokument till relationsdata. Du kan använda standardspråket Transact-SQL utökat med JSON-funktioner för parsning av dokument. Du kan också använda icke-klustrade index, kolumnlagringsindex eller minnesoptimerade tabeller för att optimera dina frågor.
JSON är ett populärt dataformat för utbyte av data i moderna webb- och mobilprogram. JSON används också för att lagra halvstrukturerade data i loggfiler eller i NoSQL-databaser. Många REST-webbtjänster returnerar resultat som är formaterade som JSON-text eller accepterar data som är formaterade som JSON.
De flesta Azure-tjänster har REST-slutpunkter som returnerar eller använder JSON. Dessa tjänster omfattar Azure Cognitive Search, Azure Storage och Azure Cosmos DB.
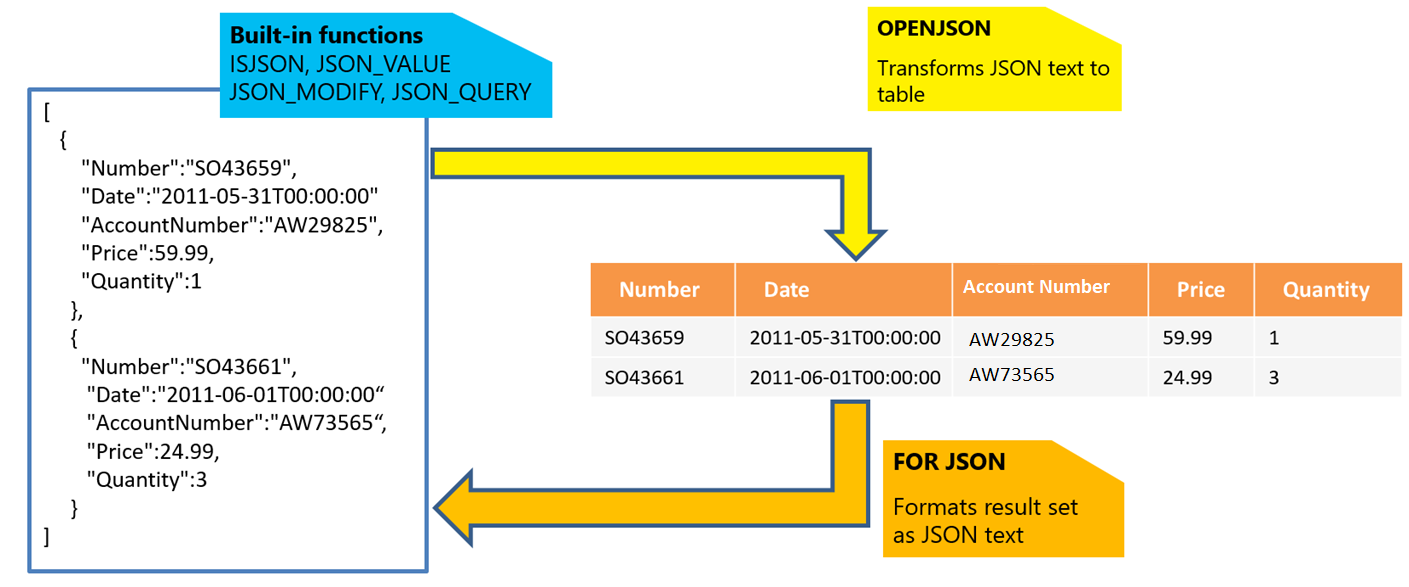
Om du har JSON-text kan du extrahera data från JSON eller kontrollera att JSON är korrekt formaterat med hjälp av de inbyggda funktionerna JSON_VALUE, JSON_QUERY och ISJSON. De andra funktionerna är:
- JSON_MODIFY: Låter dig uppdatera värden i JSON-text.
- OPENJSON: Kan omvandla en matris med JSON-objekt till en uppsättning rader för mer avancerade frågor och analyser. Alla SQL-frågor kan köras på den returnerade resultatuppsättningen.
- FÖR JSON: Låter dig formatera data som lagras i dina relationstabeller som JSON-text.
Mer information finns i Så här arbetar du med JSON-data.
Du kan använda dokumentmodeller i stället för relationsmodeller i vissa specifika scenarier:
- Hög normalisering av schemat medför inte några större fördelar eftersom du kommer åt alla fält i objekten samtidigt, eller så uppdaterar du aldrig normaliserade delar av objekten. Den normaliserade modellen ökar dock komplexiteten för dina frågor eftersom du behöver ansluta ett stort antal tabeller för att hämta data.
- Du arbetar med program som internt använder JSON-dokument för kommunikations- eller datamodeller, och du vill inte introducera fler lager som omvandlar relationsdata till JSON och vice versa.
- Du måste förenkla datamodellen genom att avnormalisera underordnade tabeller eller entity-object-value-mönster.
- Du måste läsa in eller exportera data som lagras i JSON-format utan ytterligare ett verktyg som parsar data.
XML-funktioner
Med XML-funktioner kan du lagra och indexera XML-data i databasen och använda interna XQuery/XPath-åtgärder för att arbeta med XML-data. Azure SQL-produkter har en specialiserad, inbyggd XML-datatyp och frågefunktioner som bearbetar XML-data.
SQL Server-databasmotorn är en kraftfull plattform för att utveckla program för att hantera halvstrukturerade data. Stöd för XML är integrerat i alla komponenter i databasmotorn och omfattar:
- Möjligheten att lagra XML-värden internt i en XML-datatypskolumn som kan skrivas enligt en samling XML-scheman eller lämnas otypade. Du kan indexera XML-kolumnen.
- Möjligheten att ange en XQuery-fråga mot XML-data som lagras i kolumner och variabler av XML-typen. Du kan använda XQuery-funktioner i alla Transact-SQL-frågor som har åtkomst till en datamodell som du använder i databasen.
- Automatisk indexering av alla element i XML-dokument med hjälp av det primära XML-indexet. Eller så kan du ange de exakta sökvägar som ska indexeras med hjälp av det sekundära XML-indexet.
OPENROWSET, vilket möjliggör massinläsning av XML-data.- Möjligheten att omvandla relationsdata till XML-format.
Du kan använda dokumentmodeller i stället för relationsmodeller i vissa specifika scenarier:
- Hög normalisering av schemat medför inte några större fördelar eftersom du kommer åt alla fält i objekten samtidigt, eller så uppdaterar du aldrig normaliserade delar av objekten. Den normaliserade modellen ökar dock komplexiteten för dina frågor eftersom du behöver ansluta ett stort antal tabeller för att hämta data.
- Du arbetar med program som internt använder XML-dokument för kommunikations- eller datamodeller, och du vill inte introducera fler lager som omvandlar relationsdata till JSON och vice versa.
- Du måste förenkla datamodellen genom att avnormalisera underordnade tabeller eller entity-object-value-mönster.
- Du måste läsa in eller exportera data som lagras i XML-format utan ytterligare ett verktyg som parsar data.
Rumsliga funktioner
Rumsliga data representerar information om objektens fysiska plats och form. Dessa objekt kan vara punktplatser eller mer komplexa objekt som länder/regioner, vägar eller sjöar.
Azure SQL har stöd för två spatiala datatyper:
- Geometritypen representerar data i ett euklidiskt (platt) koordinatsystem.
- Geografitypen representerar data i ett jorden runt koordinatsystem.
Med rumsliga funktioner i Azure SQL kan du lagra geometriska och geografiska data. Du kan använda rumsliga objekt i Azure SQL för att parsa och fråga efter data som representeras i JSON-format och exportera dina relationsdata som JSON-text. Dessa rumsliga objekt är Point, LineString och Polygon. Azure SQL tillhandahåller också specialiserade rumsliga index som du kan använda för att förbättra prestandan för dina rumsliga frågor.
Rumsligt stöd är en viktig funktion i SQL Server-databasmotorn.
Nyckel/värde-par
Azure SQL-produkter har inte särskilda typer eller strukturer som stöder nyckel/värde-par, eftersom nyckel/värde-strukturer kan representeras internt som standardrelationstabeller:
CREATE TABLE Collection (
Id int identity primary key,
Data nvarchar(max)
)
Du kan anpassa den här nyckel/värde-strukturen så att den passar dina behov utan några begränsningar. Värdet kan till exempel vara ett XML-dokument i stället för nvarchar(max) typen . Om värdet är ett JSON-dokument kan du använda en CHECK begränsning som verifierar giltigheten för JSON-innehåll. Du kan placera valfritt antal värden som är relaterade till en nyckel i de ytterligare kolumnerna. Som exempel:
- Lägg till beräknade kolumner och index för att förenkla och optimera dataåtkomsten.
- Definiera tabellen som en minnesoptimerad tabell med endast schema för att få bättre prestanda.
Ett exempel på hur en relationsmodell effektivt kan användas som en nyckel/värde-parlösning i praktiken finns i How bwin is using SQL Server 2016 In-Memory OLTP to achieve unprecedented performance and scale . I den här fallstudien använde bwin en relationsmodell för sin ASP.NET cachelagringslösning för att uppnå 1,2 miljoner batchar per sekund.
Nästa steg
Funktioner för flera modeller är grundläggande SQL Server-databasmotorfunktioner som delas mellan Azure SQL-produkter. Mer information om dessa funktioner finns i följande artiklar: