Dataprogram (källjusterade)
Om du har valt att inte implementera en dataagnostikmotor för att mata in data en gång från driftkällor, eller om komplexa anslutningar inte underlättas i din dataagnostikmotor, bör du skapa ett dataprogram som är källjusterat. Den bör följa samma flöde som en dataagnostikmotor skulle göra när data matas in från externa datakällor.
Översikt
Din programresursgrupp ansvarar endast för datainmatning och berikning från externa källor, till exempel telemetri, ekonomi eller CRM. Det här lagret kan användas i realtid, batch och mikrobatch.
I det här avsnittet beskrivs infrastrukturen som distribueras för varje dataprograms (källanpassad) resursgrupp i din datalandningszon.
Tips
För datanät kan du välja att distribuera en av dessa per källa eller en per domän. Principerna för datastandardisering, datakvalitet och data härkomst måste fortfarande följas. Dataplattformsteam kan utveckla kodfragment med standardkod och uppmana dem att uppnå detta.
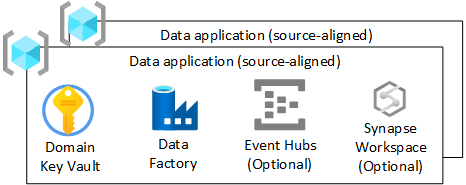
För varje dataprogram (källjusterad) resursgrupp i din datalandningszon bör du skapa:
- En Azure-Key Vault
- En Azure Data Factory för att köra utvecklade tekniska pipelines som omvandlar data från rådata till berikade
- Ett huvudnamn för tjänsten som används av dataprogrammet (källjusterat) för att distribuera inmatningsjobb till Azure Databricks (endast om du använder Azure Databricks)
Du kan också skapa instanser av andra tjänster, till exempel Azure Event Hubs, Azure IoT Hub, Azure Stream Analytics och Azure Machine Learning.
Anteckning
Du måste använda en Spark-motor som Azure Synapse Spark eller Azure Databricks för att framtvinga Delta Lake-standarden.
Om du bestämmer dig för att använda Azure Databricks rekommenderar vi att du distribuerar Azure Data Factory i stället för att Azure Synapse Analytics-arbetsyta för att minska ytan till endast nödvändiga funktioner.
Men om du behöver ett heltäckande utvecklingsområde med pipelines och spark använder du Azure Synapse Analytics. Tillämpa en princip för att endast tillåta användning av Spark och pipelines så att du undviker att skapa silor i en Azure Synapse SQL-pool.
Azure Key Vault
Använd Azure Key Vault-funktioner för att lagra hemligheter i Azure när det är möjligt.
Varje dataprogram (källjusterad) resursgrupp eller datadomän (om nät) har en Azure-Key Vault. Detta säkerställer att krypteringsnyckeln, hemligheten och certifikathärledning uppfyller kraven i din miljö. Detta möjliggör bättre uppdelning av administrativa uppgifter och minskar också risken för att nycklar, integreringar och hemligheter blandas i olika klassificeringar.
Alla nycklar som är relaterade till ditt dataprogram (källjusterat) ska finnas i din Azure-Key Vault.
Viktigt
Nyckelvalv för dataprogram (källjusterade) bör följa modellen med lägsta behörighet och bör undvika både transaktionsskalningsgränser och hemlighetsdelning mellan miljöer.
Azure Data Factory
Distribuera en Azure Data Factory så att pipelines som skrivits av ditt dataprogramteam kan ta data från rådata till berikade med hjälp av utvecklade pipelines. Använd mappning av dataflöden för transformeringar och bryt ut för att använda Azure Databricks-arbetsytan (inmatning) eller Azure Synapse Spark för komplexa omvandlingar.
Du bör ansluta Azure Data Factory till DevOps-instansen av din dataapps (källjusterade) lagringsplats. Den här anslutningen tillåter CI/CD-distributioner.
Event Hubs
Om ditt dataprogram (källjusterat) har ett krav på att strömma data i, kan du distribuera underordnade Event Hubs i din dataprogramresursgrupp (källjusterad).