Mata in data från Apache Kafka till Azure Data Explorer
Apache Kafka är en distribuerad strömningsplattform för att skapa strömmande datapipelines i realtid som på ett tillförlitligt sätt flyttar data mellan system eller program. Kafka Connect är ett verktyg för skalbar och tillförlitlig dataströmning mellan Apache Kafka och andra datasystem. Kusto Kafka-mottagaren fungerar som anslutningsapp från Kafka och kräver inte att kod används. Ladda ned mottagaranslutningsappens jar-fil från Git-lagringsplatsen eller Confluent Connector Hub.
Den här artikeln visar hur du matar in data med Kafka med hjälp av en fristående Docker-konfiguration för att förenkla konfigurationen av Kafka-klustret och Kafka-anslutningsklustret.
Mer information finns i Git-lagringsplatsen för anslutningsappen och versionsinformationen.
Förutsättningar
- En Azure-prenumeration. Skapa ett kostnadsfritt Azure-konto.
- Ett Azure Data Explorer-kluster och -databas med standardprinciper för cachelagring och kvarhållning eller en KQL-databas i Microsoft Fabric.
- Azure CLI.
- Docker och Docker Compose.
Skapa ett huvudnamn för Microsoft Entra-tjänsten
Tjänstens huvudnamn för Microsoft Entra kan skapas via Azure Portal eller programmatiskt, som i följande exempel.
Tjänstens huvudnamn är den identitet som används av anslutningsappen för att skriva data i tabellen i Kusto. Senare beviljar du behörigheter för tjänstens huvudnamn för åtkomst till Kusto-resurser.
Logga in på din Azure-prenumeration via Azure CLI. Autentisera sedan i webbläsaren.
az loginVälj den prenumeration som ska vara värd för huvudkontot. Det här steget krävs när du har flera prenumerationer.
az account set --subscription YOUR_SUBSCRIPTION_GUIDSkapa tjänstens huvudnamn. I det här exemplet kallas
my-service-principaltjänstens huvudnamn .az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Från de returnerade JSON-data kopierar du
appId,passwordochtenantför framtida användning.{ "appId": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "displayName": "my-service-principal", "name": "my-service-principal", "password": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "tenant": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn" }
Du har skapat ditt Microsoft Entra-program och tjänstens huvudnamn.
Skapa en måltabell
Från frågemiljön skapar du en tabell med namnet
Stormsmed följande kommando:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Skapa motsvarande tabellmappning
Storms_CSV_Mappingför inmatade data med följande kommando:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Skapa en inmatningsbatchprincip i tabellen för konfigurerbar köad svarstid för inmatning.
Tips
Inmatningsbatchprincipen är en prestandaoptimerare och innehåller tre parametrar. Det första villkoret som uppfylls utlöser inmatning i tabellen Azure Data Explorer.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Använd tjänstens huvudnamn från Skapa ett Microsoft Entra för tjänstens huvudnamn för att bevilja behörighet att arbeta med databasen.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
Köra labbet
Följande labb är utformat för att ge dig erfarenhet av att börja skapa data, konfigurera Kafka-anslutningsappen och strömma dessa data till Azure Data Explorer med anslutningsappen. Du kan sedan titta på inmatade data.
Klona git-lagringsplatsen
Klona labbets git-lagringsplats.
Skapa en lokal katalog på datorn.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holKlona lagringsplatsen.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
Innehållet i den klonade lagringsplatsen
Kör följande kommando för att visa innehållet i den klonade lagringsplatsen:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
Resultatet av den här sökningen är:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Granska filerna på den klonade lagringsplatsen
I följande avsnitt förklaras de viktiga delarna av filerna i filträdet ovan.
adx-sink-config.json
Den här filen innehåller kusto-mottagaregenskaper där du uppdaterar specifik konfigurationsinformation:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Ersätt värdena för följande attribut enligt konfigurationen av Azure Data Explorer: , , , kusto.tables.topics.mapping (databasnamnet), kusto.ingestion.urloch kusto.query.url. aad.auth.appkeyaad.auth.appidaad.auth.authority
Anslutningsprogram – Dockerfile
Den här filen har kommandon för att generera docker-avbildningen för anslutningsinstansen. Den innehåller nedladdningen av anslutningsappen från git-lagringsplatsens versionskatalog.
Katalogen Storm-events-producer
Den här katalogen har ett Go-program som läser en lokal "StormEvents.csv"-fil och publicerar data till ett Kafka-ämne.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
Starta containrarna
Starta containrarna i en terminal:
docker-compose upProducentprogrammet börjar skicka händelser till ämnet
storm-events. Du bör se loggar som liknar följande loggar:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....Kontrollera loggarna genom att köra följande kommando i en separat terminal:
docker-compose logs -f | grep kusto-connect
Starta anslutningsappen
Använd ett Kafka Connect REST-anrop för att starta anslutningsappen.
Starta mottagaraktiviteten i en separat terminal med följande kommando:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsKontrollera statusen genom att köra följande kommando i en separat terminal:
curl http://localhost:8083/connectors/storm/status
Anslutningsappen börjar köa inmatningsprocesser till Azure Data Explorer.
Anteckning
Om du har problem med logganslutningsappen skapar du ett problem.
Fråga och granska data
Bekräfta datainmatning
Vänta tills data tas emot i
Stormstabellen. Kontrollera antalet rader för att bekräfta dataöverföringen:Storms | countBekräfta att det inte finns några fel i inmatningsprocessen:
.show ingestion failuresNär du ser data kan du prova några frågor.
Fråga efter data
Om du vill se alla poster kör du följande fråga:
StormsAnvänd
whereochprojectför att filtrera specifika data:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdAnvänd operatorn
summarize:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart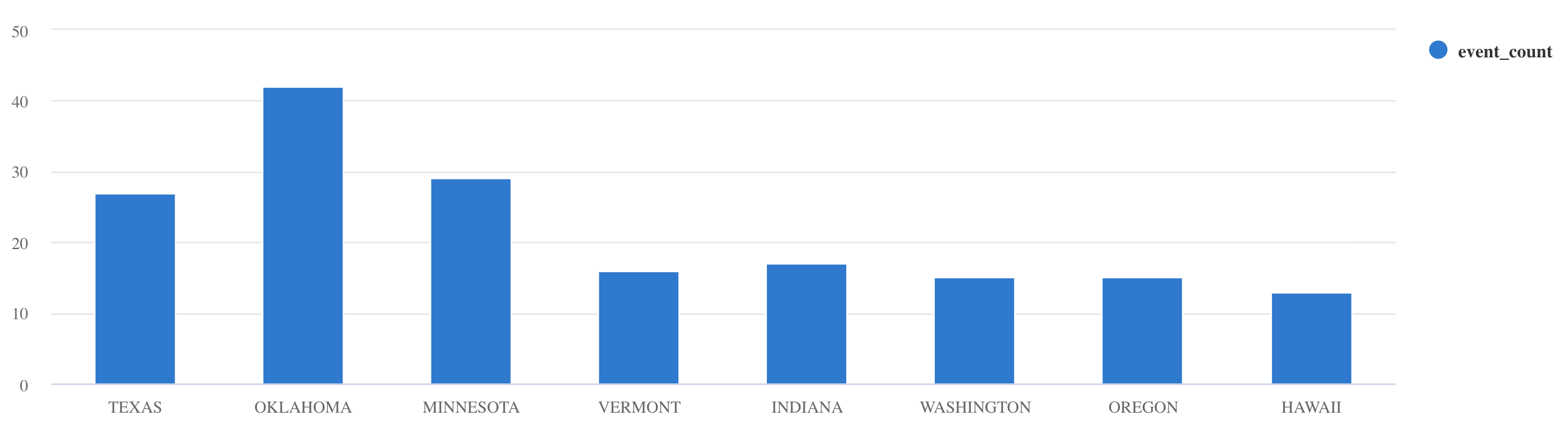
Fler frågeexempel och vägledning finns i Skriva frågor i KQL och Kusto-frågespråk dokumentation.
Återställ
Gör följande för att återställa:
- Stoppa containrarna (
docker-compose down -v) - Ta bort (
drop table Storms) -
StormsÅterskapa tabellen - Återskapa tabellmappning
- Starta om containrar (
docker-compose up)
Rensa resurser
Om du vill ta bort Azure Data Explorer-resurserna använder du az cluster delete eller az Kusto database delete:
az kusto cluster delete -n <cluster name> -g <resource group name>
az kusto database delete -n <database name> --cluster-name <cluster name> -g <resource group name>
Justera Kafka-mottagarens anslutning
Justera Kafka Sink-anslutningsappen så att den fungerar med inmatningsbatchprincipen:
- Justera storleksgränsen för Kafka-mottagare
flush.size.bytesfrån 1 MB och öka med steg om 10 MB eller 100 MB. - När du använder Kafka-mottagare aggregeras data två gånger. Data på anslutningsappens sida aggregeras enligt inställningarna för tömning och på Azure Data Explorer-tjänstsidan enligt batchbearbetningsprincipen. Om batchbearbetningstiden är för kort och inga data kan matas in av både anslutningsappen och tjänsten, måste batchbearbetningstiden ökas. Ange batchstorleken till 1 GB och öka eller minska med 100 MB efter behov. Om tömningsstorleken till exempel är 1 MB och batchprincipens storlek är 100 MB, matas en batch på 100 MB in av Anslutningsappen för Kafka-mottagare när en batch på 100 MB har aggregerats av Azure Data Explorer-tjänsten. Om batchprinciptiden är 20 sekunder och Kafka Sink-anslutningen töms 50 MB under en 20-sekundersperiod matar tjänsten in en batch på 50 MB.
- Du kan skala genom att lägga till instanser och Kafka-partitioner. Öka
tasks.maxtill antalet partitioner. Skapa en partition om du har tillräckligt med data för att skapa en blob storleken påflush.size.bytesinställningen. Om blobben är mindre bearbetas batchen när den når tidsgränsen, så partitionen får inte tillräckligt med dataflöde. Ett stort antal partitioner innebär mer bearbetningskostnader.
Relaterat innehåll
- Läs mer om arkitektur för stordata.
- Lär dig hur du matar in JSON-formaterade exempeldata i Azure Data Explorer.
- För ytterligare Kafka-labb: