Kopiera data från Amazon Redshift med Hjälp av Azure Data Factory eller Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktiviteten i Azure Data Factory- och Synapse Analytics-pipelines för att kopiera data från en Amazon Redshift. Den bygger på översiktsartikeln för kopieringsaktivitet som visar en allmän översikt över kopieringsaktiviteten.
Funktioner som stöds
Den här Amazon Redshift-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| aktiviteten Kopiera (källa/-) | (1) (2) |
| Sökningsaktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
En lista över datalager som stöds som källor eller mottagare av kopieringsaktiviteten finns i tabellen Datalager som stöds.
Mer specifikt stöder den här Amazon Redshift-anslutningsappen hämtning av data från Redshift med hjälp av fråga eller inbyggt Stöd för Redshift UNLOAD.
Anslutningsappen stöder Windows-versionerna i den här artikeln.
Dricks
Om du vill uppnå bästa prestanda vid kopiering av stora mängder data från Redshift bör du överväga att använda den inbyggda Redshift UNLOAD via Amazon S3. Mer information finns i Använda UNLOAD för att kopiera data från Amazon Redshift .
Förutsättningar
- Om du kopierar data till ett lokalt datalager med hjälp av lokalt installerad integrationskörning ger du Integration Runtime (datorns IP-adress) åtkomst till Amazon Redshift-klustret. Anvisningar finns i Auktorisera åtkomst till klustret .
- Om du kopierar data till ett Azure-datalager läser du Ip-intervall för Azure Data Center för beräknings-IP-adressen och SQL-intervallen som används av Azure-datacenter.
Komma igång
Om du vill utföra aktiviteten Kopiera med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad tjänst till Amazon Redshift med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Amazon Redshift i Azure Portal användargränssnittet.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Amazon och välj Amazon Redshift-anslutningsappen.
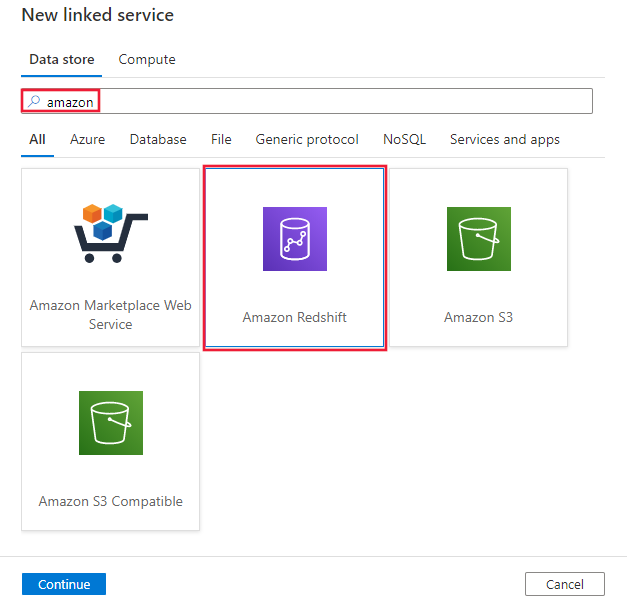
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
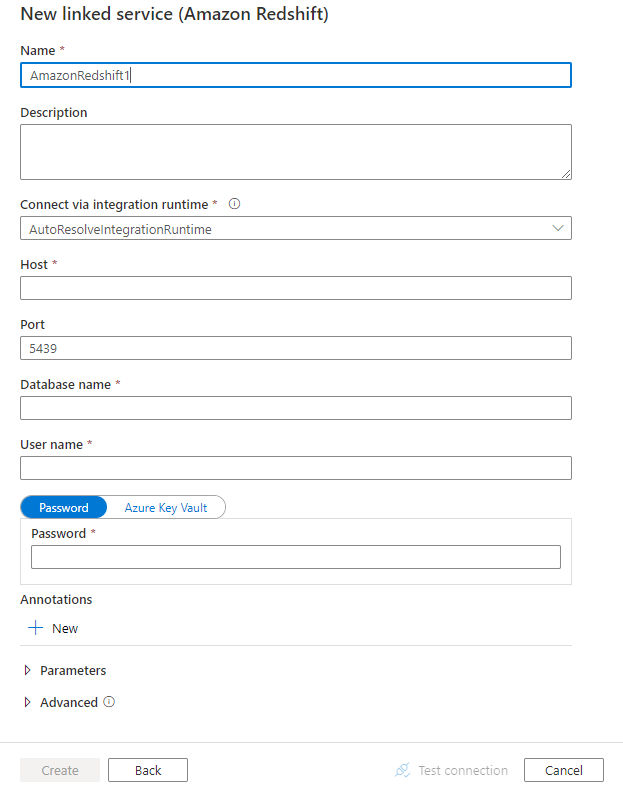
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Amazon Redshift-anslutningsappen.
Länkade tjänstegenskaper
Följande egenskaper stöds för amazon redshift-länkad tjänst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till: AmazonRedshift | Ja |
| server | IP-adress eller värdnamn för Amazon Redshift-servern. | Ja |
| port | Antalet TCP-portar som Amazon Redshift-servern använder för att lyssna efter klientanslutningar. | Nej, standardvärdet är 5439 |
| database | Namnet på Amazon Redshift-databasen. | Ja |
| användarnamn | Namn på användare som har åtkomst till databasen. | Ja |
| password | Lösenord för användarkontot. Markera det här fältet som en SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. | Ja |
| connectVia | Integration Runtime som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Exempel:
{
"name": "AmazonRedshiftLinkedService",
"properties":
{
"type": "AmazonRedshift",
"typeProperties":
{
"server": "<server name>",
"database": "<database name>",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av Amazon Redshift-datauppsättningen.
Följande egenskaper stöds för att kopiera data från Amazon Redshift:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för datauppsättningen måste anges till: AmazonRedshiftTable | Ja |
| schema | Namnet på schemat. | Nej (om "fråga" i aktivitetskällan har angetts) |
| table | Tabellens namn. | Nej (om "fråga" i aktivitetskällan har angetts) |
| tableName | Namnet på tabellen med schemat. Den här egenskapen stöds för bakåtkompatibilitet. Använd schema och table för ny arbetsbelastning. |
Nej (om "fråga" i aktivitetskällan har angetts) |
Exempel
{
"name": "AmazonRedshiftDataset",
"properties":
{
"type": "AmazonRedshiftTable",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "<Amazon Redshift linked service name>",
"type": "LinkedServiceReference"
}
}
}
Om du använder RelationalTable en typ av datauppsättning stöds den fortfarande i sin form, medan du rekommenderas att använda den nya framöver.
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Amazon Redshift-källan.
Amazon Redshift som källa
Om du vill kopiera data från Amazon Redshift anger du källtypen i kopieringsaktiviteten till AmazonRedshiftSource. Följande egenskaper stöds i avsnittet kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till: AmazonRedshiftSource | Ja |
| query | Använd den anpassade frågan för att läsa data. Till exempel: välj * från MyTable. | Nej (om "tableName" i datauppsättningen har angetts) |
| redshiftUnloadSettings | Egenskapsgrupp när du använder Amazon Redshift UNLOAD. | Nej |
| s3LinkedServiceName | Refererar till en Amazon S3 som ska användas som interimslager genom att ange ett länkat tjänstnamn av typen "AmazonS3". | Ja om du använder LASTA AV |
| bucketName | Ange S3-bucketen för att lagra interimsdata. Om den inte tillhandahålls genererar tjänsten den automatiskt. | Ja om du använder LASTA AV |
Exempel: Amazon Redshift-källa i kopieringsaktivitet med HJÄLP av UNLOAD
"source": {
"type": "AmazonRedshiftSource",
"query": "<SQL query>",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "<Amazon S3 linked service>",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
}
Lär dig mer om hur du använder UNLOAD för att kopiera data från Amazon Redshift effektivt från nästa avsnitt.
Använda UNLOAD för att kopiera data från Amazon Redshift
UNLOAD är en mekanism som tillhandahålls av Amazon Redshift, som kan ta bort resultatet av en fråga till en eller flera filer på Amazon Simple Storage Service (Amazon S3). Det är det sätt som rekommenderas av Amazon för att kopiera stora datamängder från Redshift.
Exempel: kopiera data från Amazon Redshift till Azure Synapse Analytics med hjälp av UNLOAD, mellanlagrad kopia och PolyBase
I det här exempelanvändningsfallet tar kopieringsaktiviteten bort data från Amazon Redshift till Amazon S3 enligt konfigurationen i "redshiftUnloadSettings" och kopierar sedan data från Amazon S3 till Azure Blob enligt vad som anges i "stagingSettings" och använder slutligen PolyBase för att läsa in data till Azure Synapse Analytics. Allt mellanliggande format hanteras korrekt av kopieringsaktiviteten.

"activities":[
{
"name": "CopyFromAmazonRedshiftToSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "AmazonRedshiftDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRedshiftSource",
"query": "select * from MyTable",
"redshiftUnloadSettings": {
"s3LinkedServiceName": {
"referenceName": "AmazonS3LinkedService",
"type": "LinkedServiceReference"
},
"bucketName": "bucketForUnload"
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": "AzureStorageLinkedService",
"path": "adfstagingcopydata"
},
"dataIntegrationUnits": 32
}
}
]
Datatypsmappning för Amazon Redshift
När du kopierar data från Amazon Redshift används följande mappningar från Amazon Redshift-datatyper till mellanliggande datatyper som används internt i tjänsten. Se Schema- och datatypmappningar för att lära dig mer om hur kopieringsaktivitet mappar källschemat och datatypen till mottagaren.
| Amazon Redshift-datatyp | Datatyp för interimstjänst |
|---|---|
| BIGINT | Int64 |
| BOOLESK | String |
| CHAR | String |
| DATUM | Datum/tid |
| DECIMAL | Decimal |
| DUBBEL PRECISION | Dubbel |
| INTEGER | Int32 |
| REAL | Enstaka |
| SMALLINT | Int16 |
| SMS | String |
| TIMESTAMP | Datum/tid |
| VARCHAR | String |
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i datalager som stöds.