Kopiera data till ett Azure AI Search-index med Hjälp av Azure Data Factory eller Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktiviteten i en Azure Data Factory- eller Synapse Analytics-pipeline för att kopiera data till Azure AI Search-index. Den bygger på översiktsartikeln för kopieringsaktivitet som visar en allmän översikt över kopieringsaktiviteten.
Funktioner som stöds
Den här Azure AI Search-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR | Hanterad privat slutpunkt |
|---|---|---|
| Kopieringsaktivitet (-/mottagare) | (1) (2) | ✓ |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
Du kan kopiera data från valfritt källdatalager som stöds till sökindex. En lista över datalager som stöds som källor/mottagare av kopieringsaktiviteten finns i tabellen Datalager som stöds.
Komma igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad tjänst till Azure Search med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Azure Search i Användargränssnittet för Azure-portalen.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Sök och välj Azure Search-anslutningsappen.
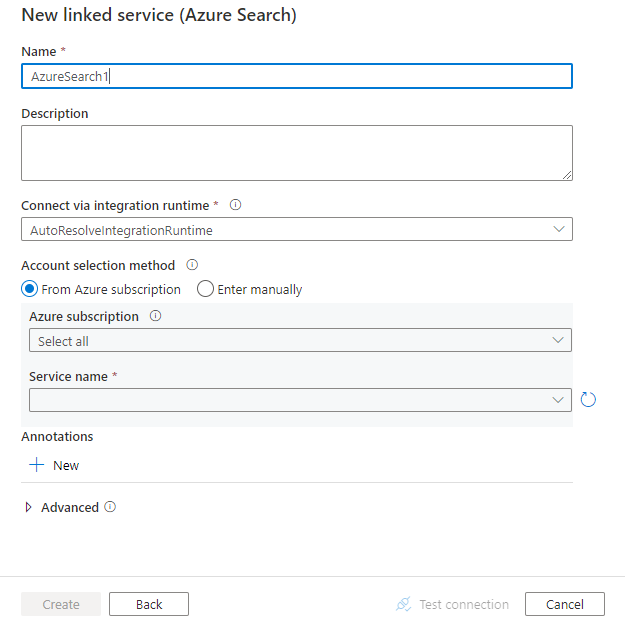
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Azure AI Search-anslutningsappen.
Länkade tjänstegenskaper
Följande egenskaper stöds för länkad Azure AI Search-tjänst:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till: AzureSearch | Ja |
| URL | URL för söktjänsten. | Ja |
| key | Administratörsnyckel för söktjänsten. Markera det här fältet som en SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. | Ja |
| connectVia | Integration Runtime som ska användas för att ansluta till datalagret. Du kan använda Azure Integration Runtime eller lokalt installerad integrationskörning (om ditt datalager finns i ett privat nätverk). Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Viktigt!
När du kopierar data från ett molndatalager till sökindex måste du i den länkade Azure AI Search-tjänsten referera till en Azure Integration Runtime med explicit region i connactVia. Ange regionen som den region där söktjänsten finns. Läs mer från Azure Integration Runtime.
Exempel:
{
"name": "AzureSearchLinkedService",
"properties": {
"type": "AzureSearch",
"typeProperties": {
"url": "https://<service>.search.windows.net",
"key": {
"type": "SecureString",
"value": "<AdminKey>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av Azure AI Search-datauppsättningen.
Följande egenskaper stöds för att kopiera data till Azure AI Search:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till: AzureSearchIndex | Ja |
| indexName | Namnet på sökindexet. Tjänsten skapar inte indexet. Indexet måste finnas i Azure AI Search. | Ja |
Exempel:
{
"name": "AzureSearchIndexDataset",
"properties": {
"type": "AzureSearchIndex",
"typeProperties" : {
"indexName": "products"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Azure AI Search linked service name>",
"type": "LinkedServiceReference"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Azure AI Search-källan.
Azure AI Search som mottagare
Om du vill kopiera data till Azure AI Search anger du källtypen i kopieringsaktiviteten till AzureSearchIndexSink. Följande egenskaper stöds i avsnittet kopieringsaktivitetsmottagare:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till: AzureSearchIndexSink | Ja |
| writeBehavior | Anger om du vill sammanfoga eller ersätta när ett dokument redan finns i indexet. Se egenskapen WriteBehavior. Tillåtna värden är: Sammanslagning (standard) och Uppladdning. |
Nej |
| writeBatchSize | Laddar upp data till sökindexet när buffertstorleken når writeBatchSize. Mer information finns i egenskapen WriteBatchSize. Tillåtna värden är: heltal 1 till 1 000; standardvärdet är 1 000. |
Nej |
| maxConcurrentConnections | Den övre gränsen för samtidiga anslutningar som upprättats till datalagret under aktivitetskörningen. Ange endast ett värde när du vill begränsa samtidiga anslutningar. | Nej |
Egenskapen WriteBehavior
AzureSearchSink upserts när du skriver data. Med andra ord uppdaterar Azure AI Search det befintliga dokumentet i stället för att utlösa ett konfliktfel om dokumentnyckeln redan finns i sökindexet.
AzureSearchSink tillhandahåller följande två upsert-beteenden (med hjälp av AzureSearch SDK):
- Sammanfoga: kombinera alla kolumner i det nya dokumentet med det befintliga. För kolumner med null-värde i det nya dokumentet bevaras värdet i det befintliga.
- Ladda upp: Det nya dokumentet ersätter det befintliga. För kolumner som inte anges i det nya dokumentet anges värdet till null oavsett om det finns ett värde som inte är null i det befintliga dokumentet eller inte.
Standardbeteendet är Sammanslagning.
Egenskapen WriteBatchSize
Azure AI-usluga pretrage har stöd för att skriva dokument som en batch. En batch kan innehålla 1 till 1 000 åtgärder. En åtgärd hanterar ett dokument för att utföra uppladdnings-/sammanslagningsåtgärden.
Exempel:
"activities":[
{
"name": "CopyToAzureSearch",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure AI Search output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureSearchIndexSink",
"writeBehavior": "Merge"
}
}
}
]
Stöd för datatyp
I följande tabell anges om en Azure AI Search-datatyp stöds eller inte.
| Datatyp för Azure AI Search | Stöds i Azure AI Search Sink |
|---|---|
| String | Y |
| Int32 | Y |
| Int64 | Y |
| Dubbel | Y |
| Booleskt | Y |
| DataTimeOffset | Y |
| Strängmatris | N |
| GeographyPoint | N |
För närvarande stöds inte andra datatyper, t.ex. ComplexType. En fullständig lista över datatyper som stöds av Azure AI Search finns i Datatyper som stöds (Azure AI Search).
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i datalager som stöds.