Kopiera data från Cassandra med Hjälp av Azure Data Factory eller Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Den här artikeln beskriver hur du använder kopieringsaktiviteten i en Azure Data Factory- eller Synapse Analytics-pipeline för att kopiera data från en Cassandra-databas. Den bygger på översiktsartikeln för kopieringsaktivitet som visar en allmän översikt över kopieringsaktiviteten.
Funktioner som stöds
Den här Cassandra-anslutningsappen stöds för följande funktioner:
| Funktioner som stöds | IR |
|---|---|
| Kopieringsaktivitet (källa/-) | (1) (2) |
| Sökningsaktivitet | (1) (2) |
(1) Azure Integration Runtime (2) Lokalt installerad integrationskörning
En lista över datalager som stöds som källor/mottagare finns i tabellen Datalager som stöds.
Mer specifikt stöder den här Cassandra-anslutningsappen:
- Cassandra-versionerna 2.x och 3.x.
- Kopiera data med grundläggande eller anonym autentisering.
Kommentar
För aktivitet som körs på lokalt installerad integrationskörning stöds Cassandra 3.x sedan IR version 3.7 och senare.
Förutsättningar
Om ditt datalager finns i ett lokalt nätverk, ett virtuellt Azure-nätverk eller Amazon Virtual Private Cloud måste du konfigurera en lokalt installerad integrationskörning för att ansluta till det.
Om ditt datalager är en hanterad molndatatjänst kan du använda Azure Integration Runtime. Om åtkomsten är begränsad till IP-adresser som är godkända i brandväggsreglerna kan du lägga till Azure Integration Runtime-IP-adresser i listan över tillåtna.
Du kan också använda funktionen för integrering av hanterade virtuella nätverk i Azure Data Factory för att få åtkomst till det lokala nätverket utan att installera och konfigurera en lokalt installerad integrationskörning.
Mer information om de nätverkssäkerhetsmekanismer och alternativ som stöds av Data Factory finns i Strategier för dataåtkomst.
Integration Runtime har en inbyggd Cassandra-drivrutin. Därför behöver du inte installera någon drivrutin manuellt när du kopierar data från/till Cassandra.
Komma igång
Om du vill utföra kopieringsaktiviteten med en pipeline kan du använda något av följande verktyg eller SDK:er:
- Verktyget Kopiera data
- Azure-portalen
- The .NET SDK
- The Python SDK
- Azure PowerShell
- REST-API:et
- Azure Resource Manager-mallen
Skapa en länkad tjänst till Cassandra med hjälp av användargränssnittet
Använd följande steg för att skapa en länkad tjänst till Cassandra i azure-portalens användargränssnitt.
Bläddra till fliken Hantera i Din Azure Data Factory- eller Synapse-arbetsyta och välj Länkade tjänster och klicka sedan på Ny:
Sök efter Cassandra och välj Cassandra-anslutningsappen.
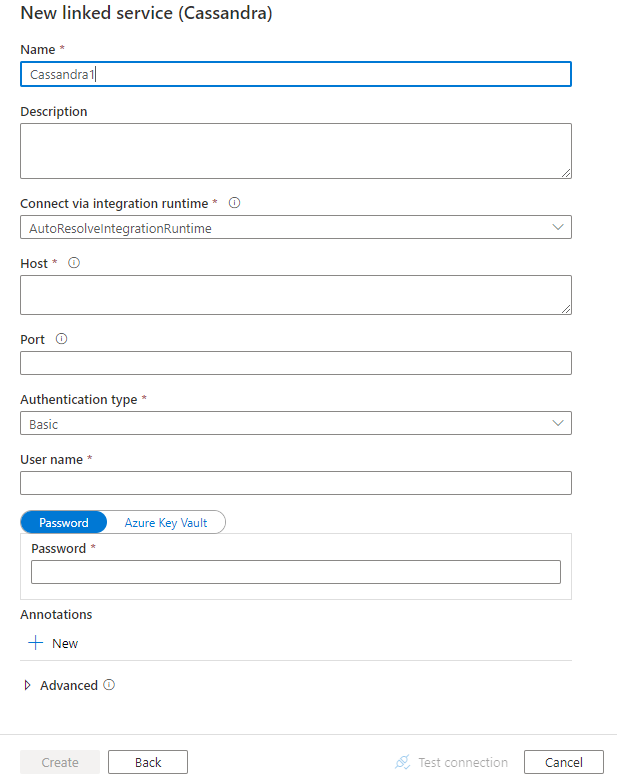
Konfigurera tjänstinformationen, testa anslutningen och skapa den nya länkade tjänsten.
Konfigurationsinformation för anslutningsprogram
Följande avsnitt innehåller information om egenskaper som används för att definiera Data Factory-entiteter som är specifika för Cassandra-anslutningsprogrammet.
Länkade tjänstegenskaper
Följande egenskaper stöds för den länkade Cassandra-tjänsten:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen måste anges till: Cassandra | Ja |
| värd | En eller flera IP-adresser eller värdnamn för Cassandra-servrar. Ange en kommaavgränsad lista med IP-adresser eller värdnamn för att ansluta till alla servrar samtidigt. |
Ja |
| port | TCP-porten som Cassandra-servern använder för att lyssna efter klientanslutningar. | Nej (standard är 9042) |
| authenticationType | Typ av autentisering som används för att ansluta till Cassandra-databasen. Tillåtna värden är: Grundläggande och Anonym. |
Ja |
| användarnamn | Ange användarnamn för användarkontot. | Ja, om authenticationType är inställt på Basic. |
| password | Ange lösenord för användarkontot. Markera det här fältet som en SecureString för att lagra det på ett säkert sätt eller referera till en hemlighet som lagras i Azure Key Vault. | Ja, om authenticationType är inställt på Basic. |
| connectVia | Integration Runtime som ska användas för att ansluta till datalagret. Läs mer i avsnittet Förutsättningar . Om den inte anges använder den standardkörningen för Azure-integrering. | Nej |
Kommentar
För närvarande stöds inte anslutning till Cassandra med TLS.
Exempel:
{
"name": "CassandraLinkedService",
"properties": {
"type": "Cassandra",
"typeProperties": {
"host": "<host>",
"authenticationType": "Basic",
"username": "<username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Egenskaper för datauppsättning
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera datauppsättningar finns i artikeln datauppsättningar . Det här avsnittet innehåller en lista över egenskaper som stöds av Cassandra-datamängden.
Om du vill kopiera data från Cassandra anger du datamängdens typegenskap till CassandraTable. Följande egenskaper stöds:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Datamängdens typegenskap måste anges till: CassandraTable | Ja |
| keyspace | Namn på nyckelområdet eller schemat i Cassandra-databasen. | Nej (om "fråga" för "CassandraSource" har angetts) |
| tableName | Namnet på tabellen i Cassandra-databasen. | Nej (om "fråga" för "CassandraSource" har angetts) |
Exempel:
{
"name": "CassandraDataset",
"properties": {
"type": "CassandraTable",
"typeProperties": {
"keySpace": "<keyspace name>",
"tableName": "<table name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<Cassandra linked service name>",
"type": "LinkedServiceReference"
}
}
}
Kopiera egenskaper för aktivitet
En fullständig lista över avsnitt och egenskaper som är tillgängliga för att definiera aktiviteter finns i artikeln Pipelines . Det här avsnittet innehåller en lista över egenskaper som stöds av Cassandra-källan.
Cassandra som källa
Om du vill kopiera data från Cassandra anger du källtypen i kopieringsaktiviteten till CassandraSource. Följande egenskaper stöds i avsnittet kopieringsaktivitetskälla:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| type | Typegenskapen för kopieringsaktivitetskällan måste anges till: CassandraSource | Ja |
| query | Använd den anpassade frågan för att läsa data. SQL-92-fråga eller CQL-fråga. Se CQL-referens. När du använder SQL-fråga anger du namn på nyckelområde.tabell för att representera den tabell som du vill fråga efter. |
Nej (om "tableName" och "keyspace" i datauppsättningen har angetts). |
| consistencyLevel | Konsekvensnivån anger hur många repliker som måste svara på en läsbegäran innan data returneras till klientprogrammet. Cassandra kontrollerar det angivna antalet repliker efter data för att uppfylla läsbegäran. Mer information finns i Konfigurera datakonsekvens . Tillåtna värden är: ONE, TWO, THREE, QUORUM, ALL, LOCAL_QUORUM, EACH_QUORUM och LOCAL_ONE. |
Nej (standard är ONE) |
Exempel:
"activities":[
{
"name": "CopyFromCassandra",
"type": "Copy",
"inputs": [
{
"referenceName": "<Cassandra input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "CassandraSource",
"query": "select id, firstname, lastname from mykeyspace.mytable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Datatypsmappning för Cassandra
När du kopierar data från Cassandra används följande mappningar från Cassandra-datatyper till mellanliggande datatyper som används internt i tjänsten. Se Schema- och datatypmappningar för att lära dig mer om hur kopieringsaktivitet mappar källschemat och datatypen till mottagaren.
| Cassandra-datatyp | Datatyp för interimstjänst |
|---|---|
| ASCII | String |
| BIGINT | Int64 |
| BLOB | Byte[] |
| BOOLESK | Booleskt |
| DECIMAL | Decimal |
| DOUBLE | Dubbel |
| FLYTA | Enstaka |
| INET | String |
| INT | Int32 |
| SMS | String |
| TIMESTAMP | Datum/tid |
| TIMEUUID | GUID |
| UUID | GUID |
| VARCHAR | String |
| VARINT | Decimal |
Kommentar
För samlingstyper (mappning, uppsättning, lista osv.), se Avsnittet Arbeta med Cassandra-samlingstyper med hjälp av virtuell tabell .
Användardefinierade typer stöds inte.
Längden på längderna binär kolumn och strängkolumn får inte vara större än 4 000.
Arbeta med samlingar med hjälp av virtuell tabell
Tjänsten använder en inbyggd ODBC-drivrutin för att ansluta till och kopiera data från Cassandra-databasen. För samlingstyper som mappning, uppsättning och listanormaliserar drivrutinen data till motsvarande virtuella tabeller. Mer specifikt, om en tabell innehåller några samlingskolumner, genererar drivrutinen följande virtuella tabeller:
- En bastabell som innehåller samma data som den verkliga tabellen förutom samlingskolumnerna. Bastabellen använder samma namn som den verkliga tabellen som den representerar.
- En virtuell tabell för varje samlingskolumn, som expanderar kapslade data. De virtuella tabeller som representerar samlingar namnges med namnet på den verkliga tabellen, en avgränsare "vt" och namnet på kolumnen.
Virtuella tabeller refererar till data i den verkliga tabellen, vilket gör det möjligt för drivrutinen att komma åt de normaliserade data. Mer information finns i avsnittet Exempel. Du kan komma åt innehållet i Cassandra-samlingar genom att fråga och ansluta till de virtuella tabellerna.
Exempel
Följande "ExampleTable" är till exempel en Cassandra-databastabell som innehåller en primärnyckelkolumn med heltal med namnet "pk_int", en textkolumn med namnet value, en listkolumn, en kartkolumn och en uppsättningskolumn (med namnet "StringSet").
| pk_int | Värde | List | Mappning | StringSet |
|---|---|---|---|---|
| 1 | "exempelvärde 1" | ["1", "2", "3"] | {"S1": "a", "S2": "b"} | {"A", "B", "C"} |
| 3 | "exempelvärde 3" | ["100", "101", "102", "105"] | {"S1": "t"} | {"A", "E"} |
Drivrutinen skulle generera flera virtuella tabeller för att representera den här enskilda tabellen. Sekundärnyckelkolumnerna i de virtuella tabellerna refererar till primärnyckelkolumnerna i den verkliga tabellen och anger vilken verklig tabellrad den virtuella tabellraden motsvarar.
Den första virtuella tabellen är bastabellen med namnet "ExampleTable" visas i följande tabell:
| pk_int | Värde |
|---|---|
| 1 | "exempelvärde 1" |
| 3 | "exempelvärde 3" |
Bastabellen innehåller samma data som den ursprungliga databastabellen förutom samlingarna, som utelämnas från den här tabellen och expanderas i andra virtuella tabeller.
Följande tabeller visar de virtuella tabeller somnormaliserar data från kolumnerna List, Map och StringSet. Kolumnerna med namn som slutar med "_index" eller "_key" anger positionen för data i den ursprungliga listan eller kartan. Kolumnerna med namn som slutar med "_value" innehåller expanderade data från samlingen.
Tabell "ExampleTable_vt_List":
| pk_int | List_index | List_value |
|---|---|---|
| 1 | 0 | 1 |
| 1 | 1 | 2 |
| 1 | 2 | 3 |
| 3 | 0 | 100 |
| 3 | 1 | 101 |
| 3 | 2 | 102 |
| 3 | 3 | 103 |
Tabell "ExampleTable_vt_Map":
| pk_int | Map_key | Map_value |
|---|---|---|
| 1 | S1 | A |
| 1 | S2 | b |
| 3 | S1 | d |
Tabell "ExampleTable_vt_StringSet":
| pk_int | StringSet_value |
|---|---|
| 1 | A |
| 1 | F |
| 1 | C |
| 3 | A |
| 3 | E |
Egenskaper för uppslagsaktivitet
Mer information om egenskaperna finns i Sökningsaktivitet.
Relaterat innehåll
En lista över datalager som stöds som källor och mottagare av kopieringsaktiviteten finns i datalager som stöds.