Dataflöde aktivitet i Azure Data Factory och Azure Synapse Analytics
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Använd aktiviteten Dataflöde för att transformera och flytta data via mappning av dataflöden. Om du inte har använt dataflöden tidigare kan du läsa Mappa Dataflöde översikt
Skapa en Dataflöde aktivitet med användargränssnittet
Utför följande steg för att använda en Dataflöde aktivitet i en pipeline:
Sök efter Dataflöde i fönstret Pipelineaktiviteter och dra en Dataflöde aktivitet till pipelinearbetsytan.
Välj den nya Dataflöde aktiviteten på arbetsytan om den inte redan är markerad och fliken Inställningar för att redigera dess information.
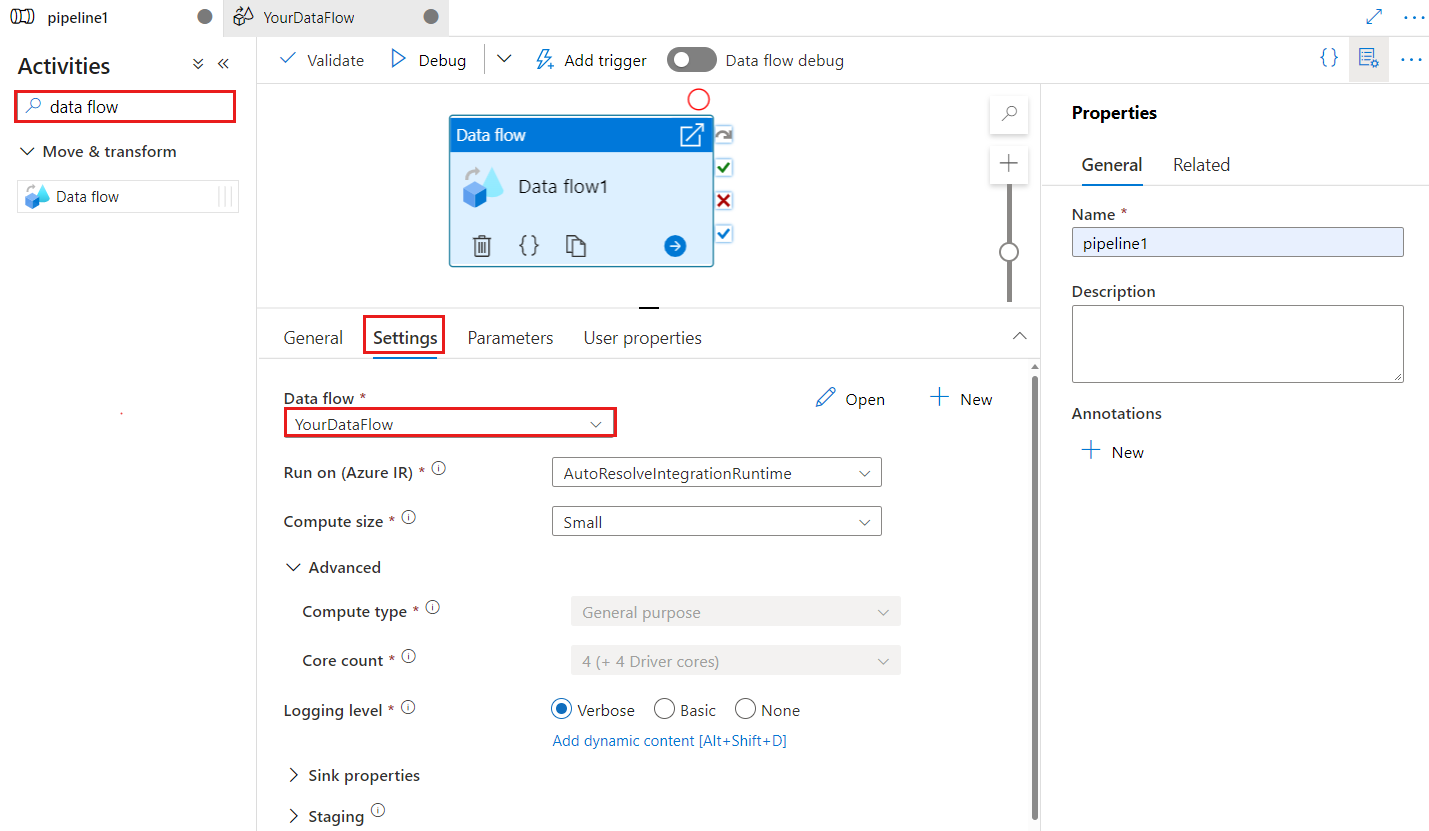
Kontrollpunktsnyckeln används för att ange kontrollpunkten när dataflödet används för ändrad datainsamling. Du kan skriva över den. Dataflödesaktiviteter använder ett guid-värde som kontrollpunktsnyckel i stället för "pipelinenamn + aktivitetsnamn" så att de alltid kan fortsätta spåra kundens status för ändringsdatainsamling även om det finns några namnbytesåtgärder. All befintlig dataflödesaktivitet använder den gamla mönsternyckeln för bakåtkompatibilitet. Alternativet Kontrollpunktsnyckel när du har publicerat en ny dataflödesaktivitet med aktiverad dataflödesresurs med ändringsdatainsamling visas enligt nedan.
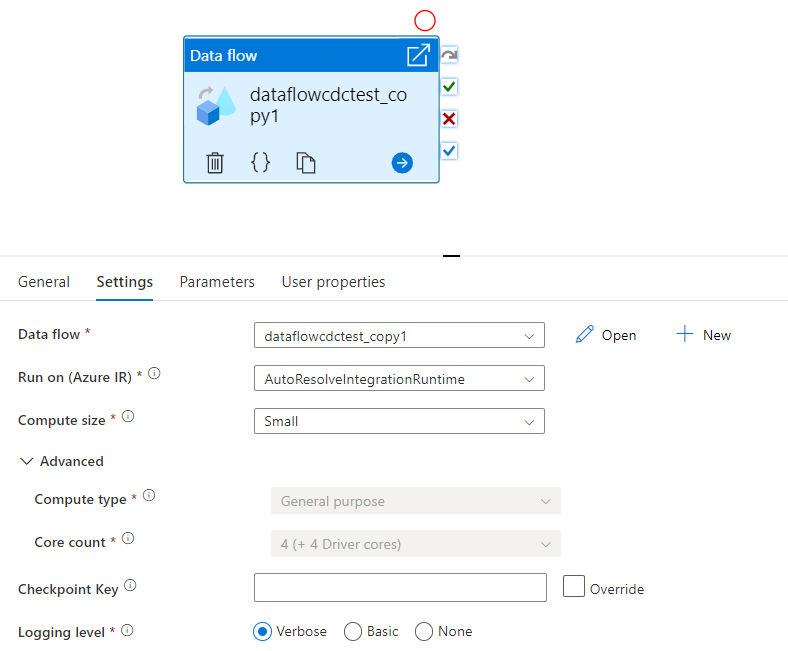
Välj ett befintligt dataflöde eller skapa ett nytt med knappen Nytt. Välj andra alternativ efter behov för att slutföra konfigurationen.
Syntax
{
"name": "MyDataFlowActivity",
"type": "ExecuteDataFlow",
"typeProperties": {
"dataflow": {
"referenceName": "MyDataFlow",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine",
"runConcurrently": true,
"continueOnError": true,
"staging": {
"linkedService": {
"referenceName": "MyStagingLinkedService",
"type": "LinkedServiceReference"
},
"folderPath": "my-container/my-folder"
},
"integrationRuntime": {
"referenceName": "MyDataFlowIntegrationRuntime",
"type": "IntegrationRuntimeReference"
}
}
Typegenskaper
| Property | beskrivning | Tillåtna värden | Obligatoriskt |
|---|---|---|---|
| dataflöde | Referensen till Dataflöde som körs | DataFlowReference | Ja |
| integrationRuntime | Beräkningsmiljön som dataflödet körs på. Om det inte anges används den automatiska Azure-integreringskörningen. | IntegrationRuntimeReference | Nej |
| compute.coreCount | Antalet kärnor som används i Spark-klustret. Det går bara att ange om den automatiska Azure Integration-körningen används | 8, 16, 32, 48, 80, 144, 272 | Nej |
| compute.computeType | Den typ av beräkning som används i Spark-klustret. Det går bara att ange om den automatiska Azure Integration-körningen används | "Allmänt" | Nej |
| staging.linkedService | Om du använder en Azure Synapse Analytics-källa eller mottagare anger du det lagringskonto som används för PolyBase-mellanlagring. Om Azure Storage har konfigurerats med VNet-tjänstslutpunkten måste du använda hanterad identitetsautentisering med "tillåt betrodd Microsoft-tjänst" aktiverad på lagringskontot, se Påverkan av att använda VNet-tjänstslutpunkter med Azure Storage. Lär dig också de konfigurationer som behövs för Azure Blob respektive Azure Data Lake Storage Gen2 . |
LinkedServiceReference | Endast om dataflödet läser eller skriver till en Azure Synapse Analytics |
| staging.folderPath | Om du använder en Azure Synapse Analytics-källa eller mottagare, mappsökvägen i bloblagringskontot som används för Mellanlagring av PolyBase | String | Endast om dataflödet läser eller skriver till Azure Synapse Analytics |
| traceLevel | Ange loggningsnivå för körning av dataflödesaktivitet | Fine, Coarse, None | Nej |
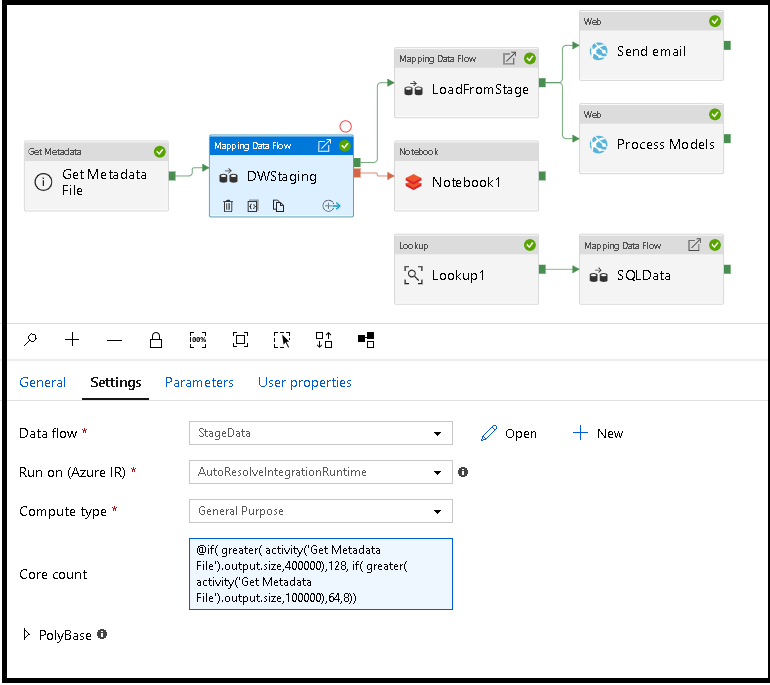
Dynamisk storlek på dataflödesberäkning vid körning
Egenskaperna Core Count och Compute Type kan ställas in dynamiskt för att justera till storleken på dina inkommande källdata vid körning. Använd pipelineaktiviteter som Sökning eller Hämta metadata för att hitta storleken på källdatauppsättningsdata. Använd sedan Lägg till dynamiskt innehåll i egenskaperna för Dataflöde aktivitet. Du kan välja små, medelstora eller stora beräkningsstorlekar. Du kan också välja "Anpassad" och konfigurera beräkningstyperna och antalet kärnor manuellt.
Här är en kort videoguide som förklarar den här tekniken
Dataflöde integrationskörning
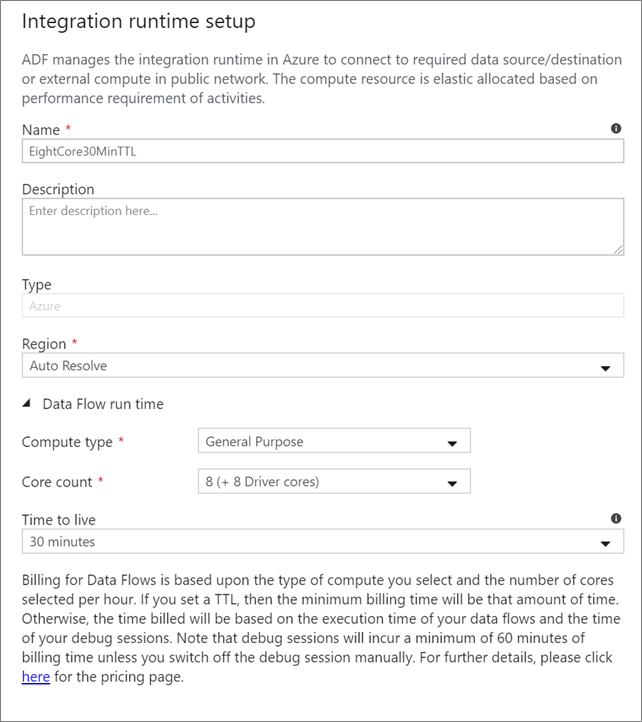
Välj vilken Integration Runtime som ska användas för körning av Dataflöde aktivitet. Som standard använder tjänsten Azure Integration Runtime med automatisk upplösning och fyra arbetskärnor. Den här IR:t har en beräkningstyp för generell användning och körs i samma region som din tjänstinstans. För operationaliserade pipelines rekommenderar vi starkt att du skapar dina egna Azure Integration Runtimes som definierar specifika regioner, beräkningstyp, kärnantal och TTL för körning av dataflödesaktivitet.
En minsta beräkningstyp av Generell användning med en konfiguration på 8+8 (totalt 16 v-kärnor) och en TTL (Time to Live) på 10 minuter är den minsta rekommendationen för de flesta produktionsarbetsbelastningar. Genom att ange en liten TTL kan Azure IR underhålla ett varmt kluster som inte medför flera minuters starttid för ett kallt kluster. Mer information finns i Azure Integration Runtime.
Viktigt!
Valet Integration Runtime i Dataflöde-aktiviteten gäller endast för utlösta körningar av din pipeline. Felsökning av din pipeline med dataflöden körs i klustret som anges i felsökningssessionen.
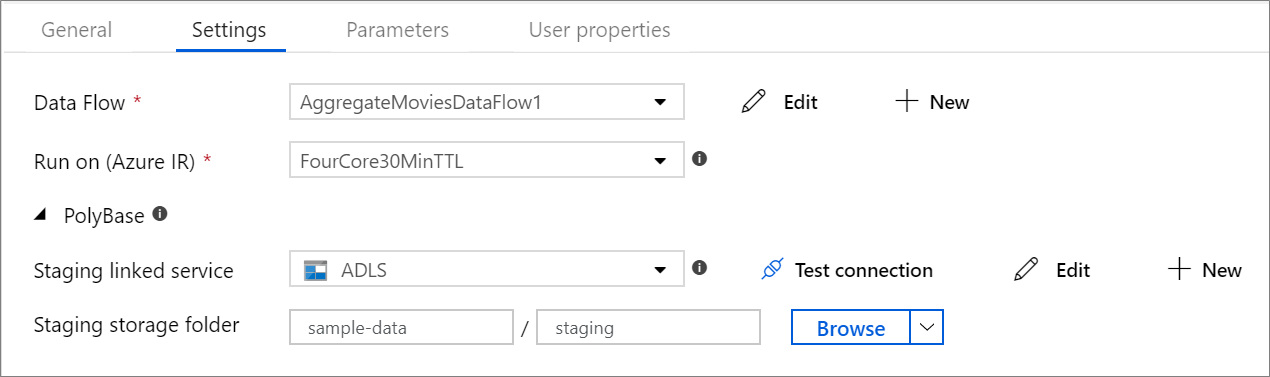
PolyBase
Om du använder en Azure Synapse Analytics som mottagare eller källa måste du välja en mellanlagringsplats för din PolyBase-batchbelastning. PolyBase möjliggör batchinläsning i bulk i stället för att läsa in data rad för rad. PolyBase minskar drastiskt inläsningstiden i Azure Synapse Analytics.
Kontrollpunktsnyckel
När du använder alternativet för ändringsinsamling för dataflödeskällor underhåller och hanterar ADF kontrollpunkten åt dig automatiskt. Standardkontrollpunktsnyckeln är en hash för dataflödesnamnet och pipelinenamnet. Om du använder ett dynamiskt mönster för dina källtabeller eller -mappar kanske du vill åsidosätta den här hashen och ange ett eget värde för kontrollpunktsnyckeln här.
Loggningsnivå
Om du inte kräver varje pipelinekörning av dina dataflödesaktiviteter för att fullständigt logga alla utförliga telemetriloggar kan du ange loggningsnivån till "Basic" eller "None". När du kör dina dataflöden i "utförligt" läge (standard) begär du att tjänsten loggar aktivitet fullt ut på varje enskild partitionsnivå under dataomvandlingen. Detta kan vara en dyr åtgärd, så att bara aktivera utförliga när du felsöker kan förbättra ditt övergripande dataflöde och pipelineprestanda. "Basic"-läget loggar endast transformeringsvaraktigheterna medan "Ingen" endast ger en sammanfattning av varaktigheter.

Egenskaper för mottagare
Med grupperingsfunktionen i dataflöden kan du både ange körningsordningen för dina mottagare och gruppera mottagare med samma gruppnummer. För att hantera grupper kan du be tjänsten att köra mottagare, i samma grupp, parallellt. Du kan också ange att mottagargruppen ska fortsätta även efter att en av mottagare påträffar ett fel.
Standardbeteendet för dataflödesmottagare är att köra varje mottagare sekventiellt, på ett seriellt sätt, och att misslyckas med dataflödet när ett fel påträffas i mottagaren. Dessutom är alla mottagare som standard samma grupp om du inte går in i dataflödesegenskaperna och anger olika prioriteter för mottagare.

Endast första raden
Det här alternativet är endast tillgängligt för dataflöden som har cachemottagare aktiverade för "Utdata till aktivitet". Utdata från det dataflöde som matas in direkt i din pipeline är begränsad till 2 MB. Om du anger "endast första raden" kan du begränsa datautdata från dataflödet när du matar in dataflödesaktivitetens utdata direkt till din pipeline.
Parameterisera Dataflöde
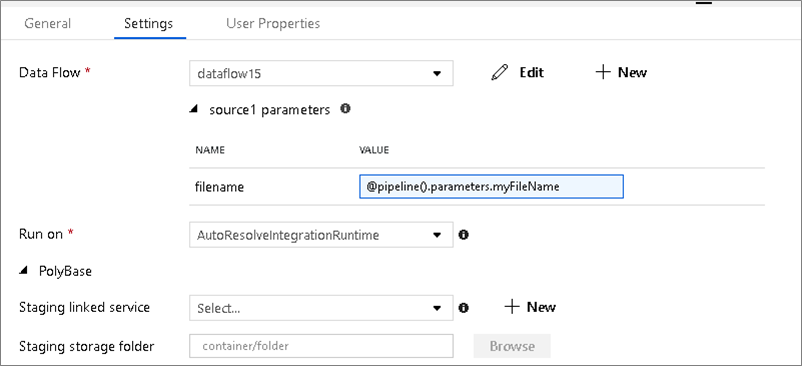
Parameteriserade datauppsättningar
Om dataflödet använder parametriserade datamängder anger du parametervärdena på fliken Inställningar .
Parameteriserade dataflöden
Om dataflödet är parametriserat anger du de dynamiska värdena för dataflödesparametrarna på fliken Parametrar . Du kan använda pipelineuttrycksspråket eller språket för dataflödesuttryck för att tilldela dynamiska eller literala parametervärden. Mer information finns i Dataflöde Parametrar.
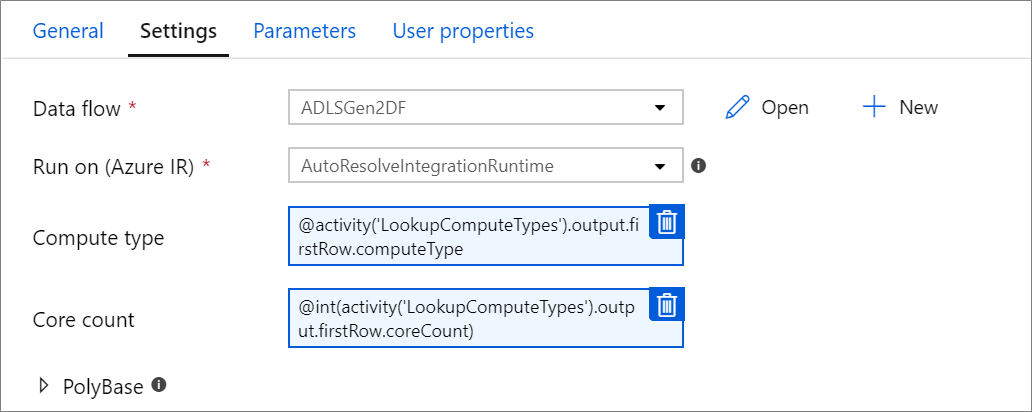
Parameteriserade beräkningsegenskaper.
Du kan parametrisera antalet kärnor eller beräkningstypen om du använder Azure Integration-körningen automatiskt och anger värden för compute.coreCount och compute.computeType.
Pipelinefelsökning av Dataflöde aktivitet
Om du vill köra en felsökningspipelinekörning med en Dataflöde aktivitet måste du aktivera felsökningsläget för dataflöden via skjutreglaget Dataflöde Felsökning i det övre fältet. Med felsökningsläget kan du köra dataflödet mot ett aktivt Spark-kluster. Mer information finns i Felsökningsläge.

Felsökningspipelinen körs mot det aktiva felsökningsklustret, inte den integrationskörningsmiljö som anges i Dataflöde aktivitetsinställningarna. Du kan välja felsökningsmiljön för beräkning när du startar felsökningsläget.
Övervaka Dataflöde aktivitet
Den Dataflöde aktiviteten har en speciell övervakningsupplevelse där du kan visa information om partitionering, fastid och data härkomst. Öppna övervakningsfönstret via glasögonikonen under Åtgärder. Mer information finns i Övervakning Dataflöde.
Använd Dataflöde aktivitetsresultat i en efterföljande aktivitet
Dataflödesaktiviteten matar ut mått om antalet rader som skrivs till varje mottagare och rader som läse från varje källa. Dessa resultat returneras i output avsnittet i aktivitetskörningsresultatet. De mått som returneras är i formatet för json nedan.
{
"runStatus": {
"metrics": {
"<your sink name1>": {
"rowsWritten": <number of rows written>,
"sinkProcessingTime": <sink processing time in ms>,
"sources": {
"<your source name1>": {
"rowsRead": <number of rows read>
},
"<your source name2>": {
"rowsRead": <number of rows read>
},
...
}
},
"<your sink name2>": {
...
},
...
}
}
}
Om du till exempel vill komma till antalet rader som skrivits till en mottagare med namnet "sink1" i en aktivitet med namnet "dataflowActivity" använder du @activity('dataflowActivity').output.runStatus.metrics.sink1.rowsWritten.
Om du vill hämta antalet rader som lästs från en källa med namnet "source1" som användes i mottagaren använder du @activity('dataflowActivity').output.runStatus.metrics.sink1.sources.source1.rowsRead.
Kommentar
Om en mottagare har noll rader skrivna visas den inte i mått. Förekomsten kan verifieras med hjälp av contains funktionen . Kontrollerar contains(activity('dataflowActivity').output.runStatus.metrics, 'sink1') till exempel om några rader har skrivits till sink1.
Relaterat innehåll
Se kontrollflödesaktiviteter som stöds: