Vad är arkitekturen i medallion lakehouse?
Arkitekturen medallion beskriver en serie datalager som anger kvaliteten på data som lagras i lakehouse. Azure Databricks rekommenderar att du använder en metod med flera lager för att skapa en enda sanningskälla för företagets dataprodukter.
Den här arkitekturen garanterar atomitet, konsekvens, isolering och hållbarhet när data passerar genom flera lager av valideringar och transformeringar innan de lagras i en layout som är optimerad för effektiv analys. Termerna brons (rå), silver (validerad) och guld (berikad) beskriver kvaliteten på data i vart och ett av dessa lager.
Medallion-arkitektur som ett mönster för datadesign
En medaljongarkitektur är ett datadesignmönster som används för att organisera data logiskt. Dess mål är att stegvis och progressivt förbättra strukturen och kvaliteten på data när de flödar genom varje skikt i arkitekturen (från Brons ⇒ Silver ⇒ Guldskikttabeller). Medallion-arkitekturer kallas ibland även för arkitekturer med flera hopp.
Genom att gå vidare med data genom dessa lager kan organisationer stegvis förbättra datakvaliteten och tillförlitligheten, vilket gör den mer lämplig för business intelligence- och maskininlärningsprogram.
Att följa medaljongarkitekturen är en rekommenderad metod, men inte ett krav.
| Fråga | Brons | Silver | Guld |
|---|---|---|---|
| Vad händer i det här lagret? | Rådatainmatning | Datarensning och validering | Dimensionsmodellering och sammansättning |
| Vem är den avsedda användaren? | – Datatekniker – Dataåtgärder – Efterlevnads- och granskningsteam |
– Datatekniker – Dataanalytiker (använd Silver-lagret för en mer förfinad datamängd som fortfarande behåller detaljerad information som krävs för djupgående analys) – Dataforskare (skapa modeller och utföra avancerad analys) |
- Affärsanalytiker och BI-utvecklare – Dataforskare och maskininlärningstekniker (ML) - Chefer och beslutsfattare – Operativa team |
Exempel på medaljongarkitektur
Det här exemplet på en medaljongarkitektur visar brons-, silver- och guldskikt för användning av ett affärsdriftsteam. Varje lager lagras i ett annat schema i ops-katalogen.
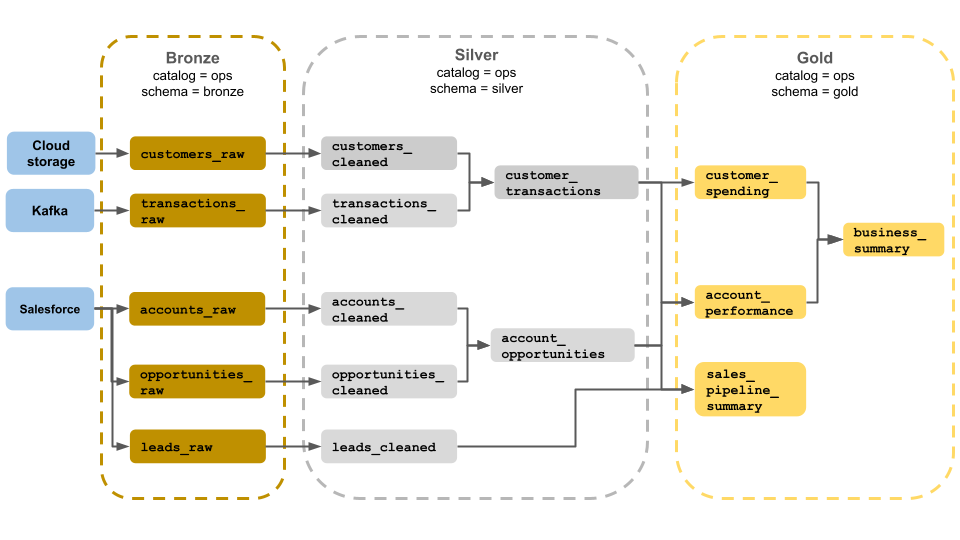
- Bronsskikt (
ops.bronze): Matar in rådata från molnlagring, Kafka och Salesforce. Ingen datarensning eller verifiering utförs här. - Silverskikt (
ops.silver): Datarensning och validering utförs i det här lagret.- Data om kunder och transaktioner rensas genom att null-värden tas bort och ogiltiga poster tas bort. Dessa datauppsättningar är anslutna till en ny datauppsättning med namnet
customer_transactions. Dataexperter kan använda den här datamängden för förutsägelseanalys. - På samma sätt kopplas konton och affärsmöjlighetsdatauppsättningar från Salesforce till att skapa
account_opportunities, vilket utökas med kontoinformation. - Data
leads_rawrensas i en datauppsättning med namnetleads_cleaned.
- Data om kunder och transaktioner rensas genom att null-värden tas bort och ogiltiga poster tas bort. Dessa datauppsättningar är anslutna till en ny datauppsättning med namnet
- Guldskikt (
ops.gold): Det här lagret är utformat för företagsanvändare. Den innehåller färre datamängder än silver och guld.customer_spending: Genomsnittliga och totala utgifter för varje kund.account_performance: Dagliga prestanda för varje konto.sales_pipeline_summary: Information om försäljningspipelinen från slutpunkt till slutpunkt.business_summary: Mycket aggregerad information för den verkställande personalen.
Mata in rådata till bronsskiktet
Bronsskiktet innehåller råa, ovaliderade data. Data som matas in i bronsskiktet har vanligtvis följande egenskaper:
- Innehåller och underhåller datakällans råtillstånd i sina ursprungliga format.
- Läggs till stegvis och växer med tiden.
- Är avsedd för förbrukning av arbetsbelastningar som berikar data för silvertabeller, inte för åtkomst av analytiker och dataforskare.
- Fungerar som en enda sanningskälla och bevarar datans återgivning.
- Möjliggör upparbetning och granskning genom att behålla alla historiska data.
- Kan vara valfri kombination av strömnings- och batchtransaktioner från källor, inklusive molnobjektlagring (till exempel S3, GCS, ADLS), meddelandebussar (till exempel Kafka, Kinesis osv.) och federerade system (till exempel Lakehouse Federation).
Begränsa rensning eller validering av data
Minimal dataverifiering utförs i bronsskiktet. För att säkerställa mot borttagna data rekommenderar Azure Databricks att du lagrar de flesta fält som sträng, VARIANT eller binärt för att skydda mot oväntade schemaändringar. Metadatakolumner kan läggas till, till exempel härkomsten eller datakällan (till exempel _metadata.file_name ).
Verifiera och deduplicera data i silverskiktet
Datarensning och validering utförs i silverlager.
Skapa silvertabeller från bronsskiktet
Om du vill skapa silverskiktet läser du data från en eller flera brons- eller silvertabeller och skriver data till silvertabeller.
Azure Databricks rekommenderar inte att du skriver till silvertabeller direkt från inmatning. Om du skriver direkt från inmatningen kommer du att introducera fel på grund av schemaändringar eller skadade poster i datakällor. Förutsatt att alla källor endast är tillägg konfigurerar du de flesta läsningar från brons som direktuppspelningsläsningar. Batchläsningar bör reserveras för små datamängder (till exempel små dimensionstabeller).
Silverskiktet representerar verifierade, rensade och berikade versioner av data. Silverskiktet:
- Bör alltid innehålla minst en validerad, icke-aggregerad representation av varje post. Om aggregerade representationer driver många underordnade arbetsbelastningar kan dessa representationer finnas i silverskiktet, men vanligtvis är de i guldskiktet.
- Här utför du datarensning, deduplicering och normalisering.
- Förbättrar datakvaliteten genom att korrigera fel och inkonsekvenser.
- Strukturerar data till ett mer förbrukningsbart format för nedströmsbearbetning.
Framtvinga datakvalitet
Följande åtgärder utförs i silvertabeller:
- Schematillämpning
- Hantering av null- och saknade värden
- Datadeduplicering
- Lösning på problem med oordnade och försenade data
- Kontroller och tillämpning av datakvalitet
- Schemautveckling
- Typgjutning
- Kopplingar
Starta modelleringsdata
Det är vanligt att börja utföra datamodellering i silverskiktet, inklusive att välja hur du ska representera kraftigt kapslade eller halvstrukturerade data:
- Använd
VARIANTdatatyp. - Använd
JSONsträngar. - Skapa structs, kartor och matriser.
- Platta ut schema eller normalisera data till flera tabeller.
Power Analytics med guldskiktet
Det guldfärgade lagret representerar mycket förfinade vyer av data som driver nedströmsanalys, instrumentpaneler, ML och program. Guldlagerdata är ofta mycket aggregerade och filtrerade för specifika tidsperioder eller geografiska regioner. Den innehåller semantiskt meningsfulla datauppsättningar som mappar till affärsfunktioner och behov.
Guldskiktet:
- Består av aggregerade data som är skräddarsydda för analys och rapportering.
- Överensstämmer med affärslogik och krav.
- Är optimerad för prestanda i frågor och instrumentpaneler.
Anpassa till affärslogik och krav
Det guldfärgade lagret är där du ska modellera dina data för rapportering och analys med hjälp av en dimensionsmodell genom att upprätta relationer och definiera mått. Analytiker med åtkomst till data i guld bör kunna hitta domänspecifika data och svara på frågor.
Eftersom guldskiktet modellerar en affärsdomän skapar vissa kunder flera guldskikt för att uppfylla olika affärsbehov, till exempel HR, ekonomi och IT.
Skapa aggregeringar som är skräddarsydda för analys och rapportering
Organisationer behöver ofta skapa aggregerade funktioner för mått som medelvärden, antal, max och minimum. Om ditt företag till exempel behöver svara på frågor om den totala veckoförsäljningen kan du skapa en materialiserad vy med namnet weekly_sales som föraggregerar dessa data så att analytiker och andra inte behöver återskapa ofta använda materialiserade vyer.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimera för prestanda i frågor och instrumentpaneler
Det är bra att optimera tabeller med guldlager för prestanda eftersom dessa datauppsättningar ofta efterfrågas. Stora mängder historiska data används vanligtvis i sliver-lagret och materialiseras inte i guldskiktet.
Kontrollera kostnaderna genom att justera datainmatningsfrekvensen
Kontrollera kostnaderna genom att bestämma hur ofta data ska matas in.
| Datainmatningsfrekvens | Kostnad | Svarstid | Deklarativa exempel | Procedurexempel |
|---|---|---|---|---|
| Kontinuerlig inkrementell inmatning | Högre | Lower | – Strömmande tabell som använder spark.readStream för att mata in från molnlagring eller meddelandebuss.– Delta Live Tables-pipelinen som uppdaterar den här strömningstabellen körs kontinuerligt. – Strukturerad strömningskod som använder spark.readStream i en notebook-fil för att mata in från molnlagring eller meddelandebuss till en Delta-tabell.– Anteckningsboken dirigeras med hjälp av ett Azure Databricks-jobb med en kontinuerlig jobbutlösare. |
|
| Utlöst inkrementell inmatning | Lower | Högre | – Strömmande tabell som matas in från molnlagring eller meddelandebuss med .spark.readStream– Pipelinen som uppdaterar den här strömningstabellen utlöses av jobbets schemalagda utlösare eller en utlösare för filinkomst. – Strukturerad direktuppspelningskod i en notebook-fil med en Trigger.Available utlösare.– Den här notebook-filen utlöses av jobbets schemalagda utlösare eller en utlösare för filinkomst. |
|
| Batchinmatning med manuell inkrementell inmatning | Lower | Högsta, på grund av ovanliga körningar. | – Inmatning av strömmande tabell från molnlagring med hjälp av spark.read.– Använder inte strukturerad direktuppspelning. Använd i stället primitiver som partitionsöverskrivning för att uppdatera en hel partition samtidigt. – Kräver omfattande uppströmsarkitektur för att konfigurera inkrementell bearbetning, vilket möjliggör en kostnad som liknar structured streaming reads/writes. – Kräver också partitionering av källdata efter ett datetime fält och sedan bearbetning av alla poster från partitionen till målet. |