Träna ML-modeller med Mosaic AutoML-användargränssnittet
Den här artikeln visar hur du tränar en maskininlärningsmodell med Hjälp av AutoML och Ai-användargränssnittet för Databricks Mosaic. AutoML-användargränssnittet vägleder dig genom att träna en klassificerings-, regressions- eller prognosmodell på en datauppsättning.
Se Krav för AutoML-experiment.
Öppna AutoML-användargränssnittet
Så här kommer du åt AutoML-användargränssnittet:
I sidofältet väljer du Nytt > AutoML-experiment.
Du kan också skapa ett nytt AutoML-experiment från sidan Experiment.
Sidan Konfigurera AutoML-experiment visas. På den här sidan konfigurerar du AutoML-processen, anger datamängden, problemtypen, mål- eller etikettkolumnen för att förutsäga, mått som ska användas för att utvärdera och bedöma experimentkörningar och stoppa villkor.
Konfigurera ett klassificerings- eller regressionsproblem
Du kan konfigurera ett klassificerings- eller regressionsproblem med hjälp av AutoML-användargränssnittet med följande steg:
I fältet Beräkning väljer du ett kluster som kör Databricks Runtime ML.
I listrutan ML-problemtyp väljer du Regression eller Klassificering. Om du försöker förutsäga ett kontinuerligt numeriskt värde för varje observation, till exempel årsinkomst, väljer du regression. Om du försöker tilldela varje observation till en av en diskret uppsättning klasser, till exempel god kreditrisk eller dålig kreditrisk, väljer du klassificering.
Under Datauppsättning väljer du Bläddra.
Gå till den tabell som du vill använda och klicka på Välj. Tabellschemat visas.
- I Databricks Runtime 10.3 ML och senare kan du ange vilka kolumner AutoML ska använda för träning. Du kan inte ta bort den kolumn som valts som förutsägelsemål eller tidskolumn för att dela upp data.
- I Databricks Runtime 10.4 LTS ML och senare kan du ange hur nullvärden ska imputeras genom att välja från listrutan Impute med . Som standard väljer AutoML en imputationsmetod baserat på kolumntyp och innehåll.
Kommentar
Om du anger en imputationsmetod som inte är standard utför AutoML inte semantisk typidentifiering.
Klicka i fältet Förutsägelsemål . En listruta visas med de kolumner som visas i schemat. Välj den kolumn som du vill att modellen ska förutsäga.
Fältet Experimentnamn visar standardnamnet. Om du vill ändra det skriver du det nya namnet i fältet.
Du kan även:
- Ange ytterligare konfigurationsalternativ.
- Använd befintliga funktionstabeller i Funktionsarkiv för att utöka den ursprungliga indatauppsättningen.
Konfigurera prognosproblem
Du kan konfigurera ett prognosproblem med autoML-användargränssnittet med följande steg:
I fältet Beräkning väljer du ett kluster som kör Databricks Runtime 10.0 ML eller senare.
I listrutan ML-problemtyp väljer du Prognostisering.
Under Datauppsättning klickar du på Bläddra. Gå till den tabell som du vill använda och klicka på Välj. Tabellschemat visas.
Klicka i fältet Förutsägelsemål . En nedrullningsbara meny visas med de kolumner som visas i schemat. Välj den kolumn som du vill att modellen ska förutsäga.
Klicka i kolumnfältet Tid. En listruta visas som visar de datauppsättningskolumner som är av typen
timestampellerdate. Välj kolumnen som innehåller tidsperioderna för tidsserierna.För prognostisering i flera serier väljer du de kolumner som identifierar de enskilda tidsserierna i listrutan Tidsserieidentifierare . AutoML grupperar data efter dessa kolumner som olika tidsserier och tränar en modell för varje serie separat. Om du lämnar det här fältet tomt förutsätter AutoML att datamängden innehåller en enda tidsserie.
I fälten Prognoshorisont och frekvens anger du det antal tidsperioder i framtiden som AutoML ska beräkna prognostiserade värden för. I den vänstra rutan anger du det heltalsantal perioder som ska prognostiseras. I den högra rutan väljer du enheterna.
Kommentar
Om du vill använda Auto-ARIMA måste tidsserierna ha en regelbunden frekvens där intervallet mellan två punkter måste vara detsamma under hela tidsserien. Frekvensen måste matcha den frekvensenhet som anges i API-anropet eller i AutoML-användargränssnittet. AutoML hanterar saknade tidssteg genom att fylla i dessa värden med föregående värde.
I Databricks Runtime 11.3 LTS ML och senare kan du spara förutsägelseresultat. Det gör du genom att ange en databas i fältet Utdatadatabas . Klicka på Bläddra och välj en databas i dialogrutan. AutoML skriver förutsägelseresultatet till en tabell i den här databasen.
Fältet Experimentnamn visar standardnamnet. Om du vill ändra det skriver du det nya namnet i fältet.
Du kan även:
- Ange ytterligare konfigurationsalternativ.
- Använd befintliga funktionstabeller i Funktionsarkiv för att utöka den ursprungliga indatauppsättningen.
Använda befintliga funktionstabeller från Databricks Feature Store
I Databricks Runtime 11.3 LTS ML och senare kan du använda funktionstabeller i Databricks Feature Store för att utöka datauppsättningen för indataträning för dina klassificerings- och regressionsproblem.
I Databricks Runtime 12.2 LTS ML och senare kan du använda funktionstabeller i Databricks Feature Store för att utöka datauppsättningen för indataträning för alla dina AutoML-problem: klassificering, regression och prognostisering.
Information om hur du skapar en funktionstabell finns i Skapa en funktionstabell i Unity Catalog eller Skapa en funktionstabell i Databricks Feature Store.
När du har konfigurerat AutoML-experimentet kan du välja en funktionstabell med hjälp av följande steg:
Klicka på Anslut funktioner (valfritt).
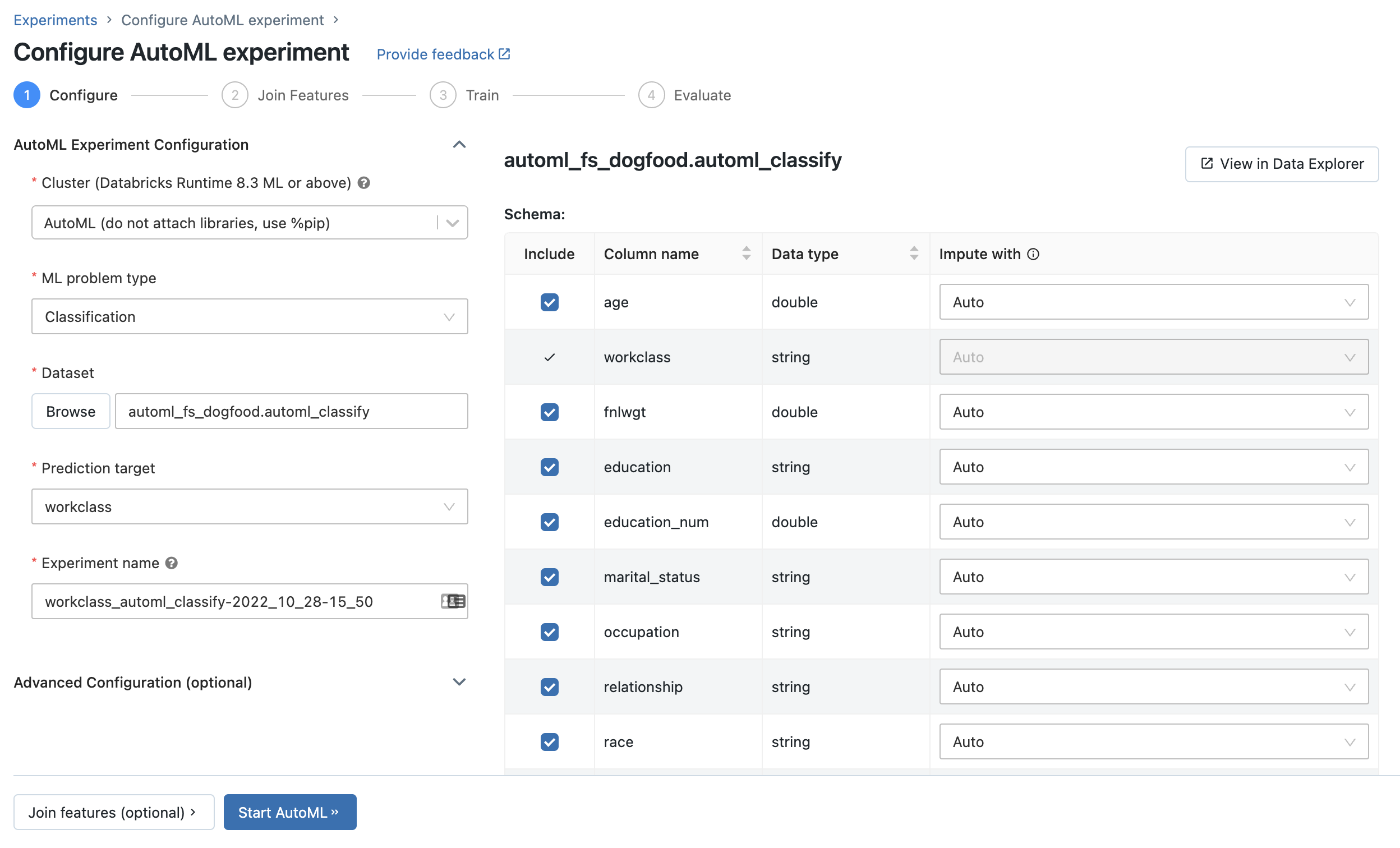
På sidan Anslut till ytterligare funktioner väljer du en funktionstabell i fältet Funktionstabell.
För varje primärnyckel i funktionstabellen väljer du motsvarande uppslagsnyckel. Uppslagsnyckeln ska vara en kolumn i träningsdatauppsättningen som du angav för AutoML-experimentet.
För tidsseriefunktionstabeller väljer du motsvarande tidsstämpelsökningsnyckel. På samma sätt bör tidsstämpelns uppslagsnyckel vara en kolumn i träningsdatauppsättningen som du angav för AutoML-experimentet.
Om du vill lägga till fler funktionstabeller klickar du på Lägg till en annan tabell och upprepar stegen ovan.
Avancerade konfigurationer
Öppna avsnittet Avancerad konfiguration (valfritt) för att få åtkomst till dessa parametrar.
- Utvärderingsmåttet är det primära måttet som används för att bedöma körningarna.
- I Databricks Runtime 10.4 LTS ML och senare kan du undanta träningsramverk från övervägande. Som standard tränar AutoML modeller med ramverk som anges under AutoML-algoritmer.
- Du kan redigera stoppvillkoren. Standardvillkor för stopp är:
- Stoppa efter 120 minuter för prognostiseringsexperiment.
- I Databricks Runtime 10.4 LTS ML och nedan ska du för klassificerings- och regressionsexperiment stoppa efter 60 minuter eller efter att ha slutfört 200 utvärderingsversioner, beroende på vilket som inträffar först. För Databricks Runtime 11.0 ML och senare används inte antalet utvärderingsversioner som ett stoppvillkor.
- I Databricks Runtime 10.4 LTS ML och senare, för klassificerings- och regressionsexperiment, innehåller AutoML tidig stoppning. den stoppar tränings- och justeringsmodeller om valideringsmåttet inte längre förbättras.
- I Databricks Runtime 10.4 LTS ML och senare kan du välja en tidskolumn för att dela upp data för träning, validering och testning i kronologisk ordning (gäller endast klassificering och regression).
- Databricks rekommenderar att du inte fyller i fältet Datakatalog . Detta utlöser standardbeteendet för säker lagring av datamängden som en MLflow-artefakt. En DBFS-sökväg kan anges, men i det här fallet ärver datauppsättningen inte AutoML-experimentets åtkomstbehörigheter.
Kör experimentet och övervaka resultaten
Starta AutoML-experimentet genom att klicka på Starta AutoML. Experimentet börjar köras och autoML-träningssidan visas. Om du vill uppdatera tabellen körningar klickar du på  .
.
Från den här sidan kan du:
- Stoppa experimentet när som helst.
- Öppna notebook-filen för datautforskning.
- Övervaka körningar.
- Navigera till körningssidan för alla körningar.
Med Databricks Runtime 10.1 ML och senare visar AutoML varningar för potentiella problem med datauppsättningen, till exempel kolumntyper som inte stöds eller kolumner med hög kardinalitet.
Kommentar
Databricks gör sitt bästa för att indikera potentiella fel eller problem. Detta kanske dock inte är omfattande och kanske inte fångar upp de problem eller fel som du kanske söker efter.
Om du vill se varningar för datamängden klickar du på fliken Varningar på träningssidan eller på experimentsidan när experimentet har slutförts.
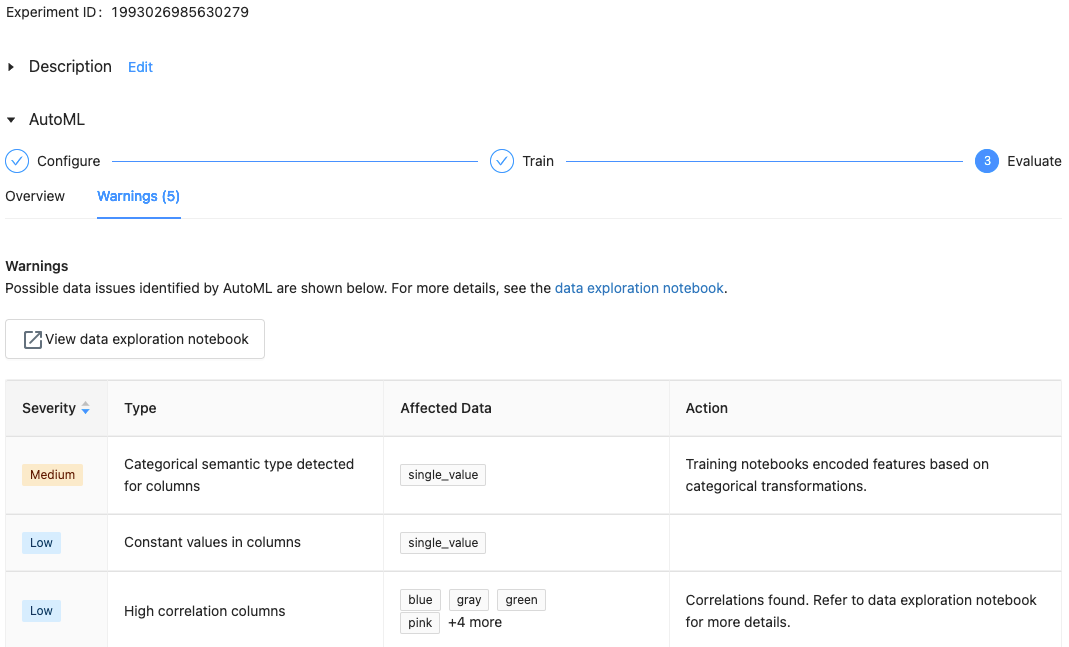
När experimentet är klart kan du:
- Registrera och distribuera en av modellerna med MLflow.
- Välj Visa anteckningsbok för bästa modell för att granska och redigera anteckningsboken som skapade den bästa modellen.
- Välj Visa anteckningsbok för datautforskning för att öppna notebook-filen för datautforskning.
- Sök, filtrera och sortera körningarna i tabellen körningar.
- Se information om alla körningar:
- Du hittar den genererade notebook-filen som innehåller källkod för en utvärderingskörning genom att klicka på MLflow-körningen. Anteckningsboken sparas i avsnittet Artefakter på körningssidan. Du kan ladda ned den här notebook-filen och importera den till arbetsytan om du har aktiverat nedladdning av artefakter av arbetsyteadministratörerna.
- Om du vill visa körningsresultatet klickar du i kolumnen Modeller eller kolumnen Starttid . Körningssidan visas med information om utvärderingskörningen (till exempel parametrar, mått och taggar) och artefakter som skapats av körningen, inklusive modellen. Den här sidan innehåller även kodfragment som du kan använda för att göra förutsägelser med modellen.
Om du vill återgå till autoML-experimentet senare hittar du det i tabellen på sidan Experiment. Resultatet av varje AutoML-experiment, inklusive datautforsknings- och träningsanteckningsböckerna, lagras i en databricks_automl mapp i hemmappen för den användare som körde experimentet.
Registrera och distribuera en modell
Du kan registrera och distribuera din modell med AutoML-användargränssnittet:
- Välj länken i kolumnen Modeller för modellen som ska registreras. När en körning är klar är den översta raden den bästa modellen (baserat på det primära måttet).
- Välj
 för att registrera modellen i modellregistret.
för att registrera modellen i modellregistret. - Välj
 Modeller i sidofältet för att navigera till modellregistret.
Modeller i sidofältet för att navigera till modellregistret. - Välj namnet på din modell i modelltabellen.
- Från den registrerade modellsidan kan du hantera modellen med modellservering.
Ingen modul med namnet 'pandas.core.indexes.numeric
När du betjänar en modell som skapats med AutoML med modellservering kan du få felet: No module named 'pandas.core.indexes.numeric.
Detta beror på en inkompatibel pandas version mellan AutoML och modellen som betjänar slutpunktsmiljön. Du kan lösa det här felet genom att köra skriptet add-pandas-dependency.py. Skriptet redigerar requirements.txt och conda.yaml för din loggade modell så att den innehåller rätt pandas beroendeversion: pandas==1.5.3
- Ändra skriptet så att det
run_idinkluderar MLflow-körningen där din modell loggades. - Omregistrera modellen till MLflow-modellregistret.
- Prova att hantera den nya versionen av MLflow-modellen.